Cloudbasierte Repositories senken die Zahl der Build-Fehler, weil sie eine einheitliche, zentrale und stark automatisierte Umgebung für die Softwareentwicklung bereitstellen. Wenn der Build-Prozess von lokalen Entwicklerrechnern in die Cloud verlegt wird, verschwinden Inkonsistenzen – das bekannte „Auf meinem Rechner funktioniert es“-Problem. Diese Systeme erzwingen standardisierte Build-Konfigurationen, verwalten Abhängigkeiten genau und nutzen strenge Zugriffskontrollen (IAM). So gelangen nur autorisierte Prozesse und geprüfte Code-Stände in die Build-Pipeline. Gleichzeitig helfen kontinuierliche Tests, Integrationskonflikte sofort sichtbar zu machen, und ausführliche Logs erleichtern die schnelle Fehlersuche.
In der heutigen schnellen Softwareentwicklung ist eine verlässliche Build-Pipeline das Rückgrat jedes guten Ingenieurteams. Mit wachsender Teamgröße und steigender Projektkomplexität stoßen klassische, lokale Ansätze schnell an ihre Grenzen. Hier setzen Cloud-Lösungen an, die nicht nur Code speichern, sondern wie intelligente Steuerzentralen arbeiten. Teams, die ihre Infrastruktur verbessern möchten, sollten auch über ihre allgemeine Datenhaltung nachdenken. Lösungen wie ein sicherer Cloud-Speicher kostenlos können dabei eine wichtige Rolle im modernen digitalen Arbeitsalltag spielen. Werden Repositories direkt mit Cloud-Build-Diensten verbunden, lassen sich Fehlerquellen systematisch ausschalten, bevor sie den Release-Zyklus stören.
Der Wechsel zu cloudbasierten Repositories wie GitHub, GitLab oder Google Cloud Source Repositories (bzw. Nachfolgern wie Secure Source Manager) ist ein wichtiger Schritt zur Fehlervermeidung. Ingenieure müssen Build-Umgebungen nicht mehr manuell aufsetzen, wo unterschiedliche Betriebssystemversionen oder lokal installierte Bibliotheken Build-Ergebnisse verfälschen. Stattdessen definiert das Team eine deklarative Konfigurationsdatei, die in der Cloud genau so ausgeführt wird. Das schafft eine verlässliche Grundlage, die für Continuous Integration und Continuous Deployment (CI/CD) notwendig ist.
Wie reduzieren cloudbasierte Repositories Build-Fehler in Ingenieurteams?
Was sind die häufigsten Ursachen für Build-Fehler?
Build-Fehler entstehen häufig dort, wo menschliche Arbeit und technische Infrastruktur zusammentreffen. Eine der wichtigsten Ursachen ist die sogenannte Konfigurationsdrift. Dabei entwickeln sich die lokalen Umgebungen der Teammitglieder langsam auseinander. Ein Entwickler nutzt zum Beispiel einen neueren Compiler, während jemand anders noch mit einer alten Bibliothek arbeitet. Wird dieser Code zusammengeführt, schlägt der Build fehl, weil die Abhängigkeiten nicht zusammenpassen. Auch fehlende oder falsch gesetzte Umgebungsvariablen sorgen regelmäßig dafür, dass automatische Prozesse scheitern.
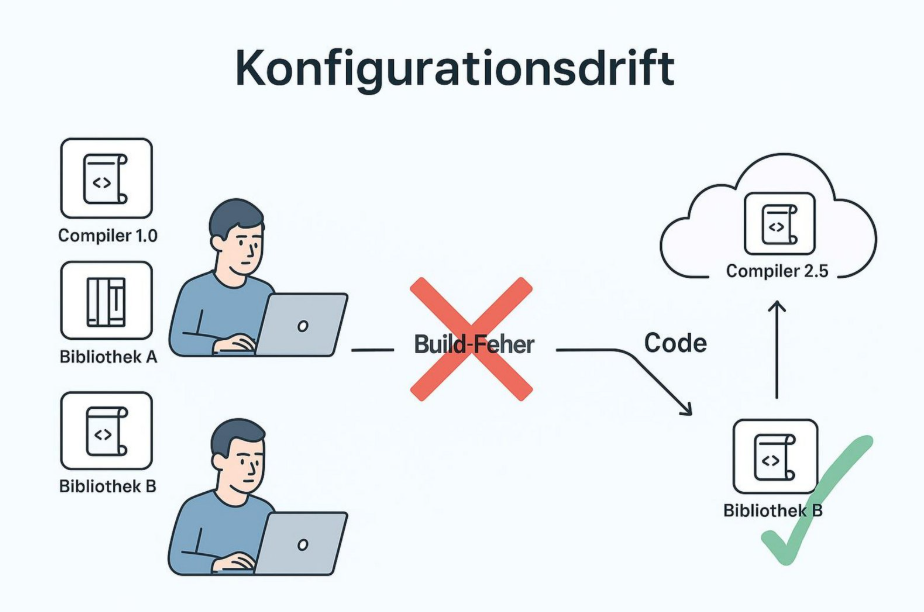
Ein weiterer wichtiger Punkt sind unklare oder falsche Berechtigungen. In komplexen Systemen greifen Build-Prozesse auf viele Ressourcen zu – von Datenbanken bis zu externen APIs. Wenn die Identitäts- und Zugriffsverwaltung (IAM) nicht passend eingerichtet ist, scheitern Builds, weil ein Dienstkonto nicht die nötigen Rechte hat, um Artefakte zu schreiben oder Logs zu speichern. Dazu kommen Race-Conditions, besonders bei parallelen Builds, wenn mehrere Prozesse gleichzeitig auf dieselbe Datei zugreifen oder sie verändern wollen. Solche Fehler treten oft nur gelegentlich auf und sind deshalb schwer zu reproduzieren.
Welche Rolle spielen Cloud-Repositories im Software-Entwicklungsprozess?
Cloud-Repositories dienen als „Single Source of Truth“ – als einziger, verlässlicher Ort für den aktuellen Stand des Quellcodes und seiner Konfiguration. Im Vergleich zu lokalen Servern bieten sie eine hochverfügbare Infrastruktur, die eng mit Build-Tools verknüpft ist. Sie sind nicht mehr nur Speicherorte, sondern aktive Bestandteile des Entwicklungsprozesses. Sobald ein Entwickler Code per „Push“ überträgt, lösen Cloud-Repositories automatisch Trigger aus, die Test- und Build-Pipelines starten. So gibt es sofort Rückmeldung: Der Entwickler sieht in wenigen Minuten, ob seine Änderung den Gesamt-Build beeinflusst.
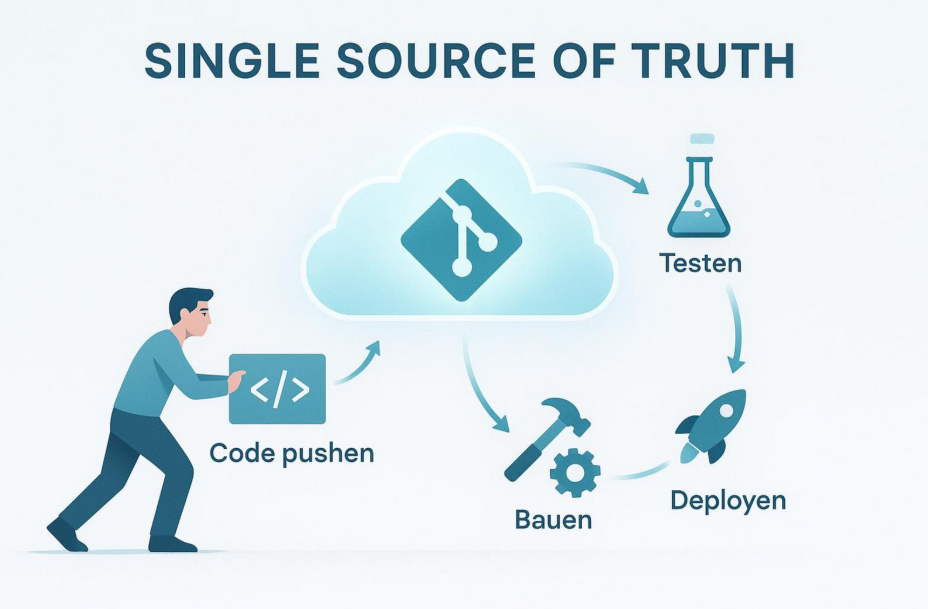
Cloud-Repositories erleichtern außerdem die Verwaltung von Metadaten und Berechtigungen bis auf Detailebene. Über Developer Connect oder ähnliche Schnittstellen lassen sich externe Tools wie GitHub oder Bitbucket direkt mit Cloud-nativen Build-Diensten verbinden. So entsteht eine durchgängige Kette der Nachvollziehbarkeit und Verantwortung. Jede Änderung, jeder Build-Versuch und jedes Ergebnis wird zentral festgehalten. Das verbessert die Zusammenarbeit in verteilten Teams spürbar und senkt die Fehlerquote durch mehr Transparenz.
Welche Vorteile bieten cloudbasierte Repositories für die Build-Stabilität?
Verbesserte Zusammenarbeit und Zugriffskontrolle
In einem cloudbasierten Repository ist Zusammenarbeit nicht an einen Standort gebunden. Teams überall auf der Welt können gleichzeitig am gleichen Code arbeiten, während das System die Zugriffsrechte konsequent durchsetzt. Mit Identity and Access Management (IAM) können Administratoren genau festlegen, wer Code lesen, pushen oder Builds auslösen darf. So lassen sich versehentliche Fehlkonfigurationen durch unbefugte Nutzer vermeiden. Versucht etwa ein Nutzer, einen Build manuell zu starten, hat aber keinen Zugriff auf die Cloud Storage-Buckets für die Logs, verweigert das System den Vorgang mit einer eindeutigen Meldung wie „AccessDenied“. Das schützt die Stabilität der Build-Pipeline.
Die zentrale Verwaltung hilft auch neuen Teammitgliedern, schnell produktiv zu werden, ohne komplizierte lokale Setups. Da Berechtigungen auf Projekt- oder Repository-Ebene vergeben werden, bleibt die Fehlerfläche klein. Rollen wie „Projektbetrachter“ oder „Cloud Build-Bearbeiter“ stellen sicher, dass jeder Prozess genau die Rechte hat, die er braucht – nicht mehr und nicht weniger. Diese klare Struktur ist die Basis für eine stabile und widerstandsfähige Entwicklungsumgebung.
Automatisierte Build- und Deployment-Prozesse
Automatisierung ist der beste Schutz vor menschlichen Fehlern. cloudbasierte Repositories erlauben es, komplexe Build-Schritte in Konfigurationsdateien (wie cloudbuild.yaml) festzuhalten. Diese Dateien werden versioniert und zusammen mit dem Code verwaltet. Wird ein Build gestartet, führt die Cloud-Infrastruktur exakt die dort beschriebenen Schritte aus. So entfallen manuelle Eingaben, und Builds lassen sich jederzeit identisch wiederholen. Ob Docker-Images geladen, Unit-Tests ausgeführt oder ein Deployment auf Cloud Run durchgeführt wird – jeder Schritt ist automatisiert und wird überwacht.
Besonders hilfreich ist die Möglichkeit, Builds an bestimmte Ereignisse zu koppeln, zum Beispiel Pull Requests oder das Erstellen von Tags. Damit kommt Code erst dann in den Hauptzweig (Main Branch), wenn er die automatisierte Qualitätsprüfung bestanden hat. Scheitert ein Build wegen eines Fehlers im Code oder einer falschen Konfiguration, wird der Prozess sofort gestoppt, bevor fehlerhafte Artefakte in Produktion gelangen. Diese „Fail-Fast“-Arbeitsweise spart Zeit und Cloud-Ressourcen.
Schnelle Fehlerdiagnose dank zentralisierter Build-Logs
Wenn ein Build scheitert, zählt jede Minute. Cloud-Plattformen stellen zentrale Logging-Systeme bereit, die über die Konsole oder Kommandozeilen-Tools (CLI) erreichbar sind. Anstatt Logs mühsam auf verschiedenen Servern zu suchen, finden Ingenieure alle relevanten Daten an einem Ort. Fehlermeldungen wie „Missing necessary permission“ oder Netzwerk-Timeouts werden ausführlich angezeigt, oft mit Hinweisen auf betroffene Dienstkonten oder Ressourcen. Das verkürzt die Suche nach der Ursache deutlich.
Mit Tools wie dem Google Cloud Log Explorer lassen sich außerdem gezielte Abfragen ausführen, um zum Beispiel zu klären, welche IAM-Identität eine Berechtigung entfernt hat, die später einen Build-Abbruch ausgelöst hat. Durch die Verknüpfung von Build-IDs mit bestimmten Commits ist klar zu sehen, welche Änderung den Fehler verursacht hat. Diese Transparenz bietet große Vorteile gegenüber verteilten, lokalen Systemen, bei denen die Fehlerquelle oft unklar bleibt.
Versionskontrolle und Rollback bei Repository-Fehlern
Fehler im Repository selbst – etwa ein versehentlich gelöschter Branch oder ein fehlerhafter Commit – lassen sich in einer Cloud-Umgebung schnell korrigieren. Jede Änderung wird historisiert, sodass jederzeit ein Rücksprung auf einen stabilen Zustand möglich ist. Cloud-Repositories bieten zusätzlich Schutzfunktionen wie „Protected Branches“, die verhindern, dass wichtige Zweige ohne Review oder erfolgreichen Build überschrieben werden. Das stabilisiert die Basis, auf der alle Builds aufsetzen.
Wenn eine neue Konfiguration in der Build-Pipeline selbst Probleme auslöst, kann das Team einfach zur vorherigen Version der Konfigurationsdatei zurückgehen. Diese Sicherheit erlaubt es Ingenieuren, Prozesse weiterzuentwickeln und neue Tools zu testen, ohne die Pipeline dauerhaft zu gefährden. Ergänzend dazu bieten verschlüsselte Dienste ein wichtiges Sicherheitsnetz, um sensible Pipeline-Geheimnisse und Architektur-Dokumente unabhängig vom Code-Repository zu sichern. Die Cloud dient hier als Schutzraum für den Code und die Abläufe, die mit ihm arbeiten.
Typische Build-Fehler und wie Cloud-Repositories sie verhindern
Fehler durch Zugriffsrechte und IAM-Berechtigungen
Ein typischer Build-Fehler ist die Meldung „AccessDenied“. Das passiert oft, wenn ein Entwickler einen Build manuell startet, das System aber keinen Zugriff auf Speicherorte wie Log-Buckets hat. Cloud-Plattformen lösen das durch klare Rollen. Damit ein Build erfolgreich laufen und protokolliert werden kann, braucht der ausführende Nutzer Rollen wie „Projektbetrachter“ und „Cloud Build-Bearbeiter“. In der Cloud-Konsole lassen sich diese Rechte schnell setzen, sodass mühsame Fehlersuche in lokalen Konfigurationen entfällt.
Builds schlagen fehl aufgrund fehlender oder falscher Servicekonten
Build-Prozesse laufen häufig über Dienstkonten. Ein verbreiteter Fehler tritt auf, wenn ein Build einen verwalteten Dienst wie Cloud Run oder App Engine bereitstellen soll, aber die Berechtigung iam.serviceAccounts.actAs fehlt. In einer Cloud-Umgebung lässt sich das durch Einrichtung des Identitätswechsels (Impersonation) lösen: Das Cloud Build-Dienstkonto wird so konfiguriert, dass es die Identität des Zieldienstkontos annehmen darf. Diese klare Struktur sorgt dafür, dass Builds nicht in unklaren Zuständen laufen und jeder Prozess mit der passenden Identität arbeitet.
Probleme mit privaten Repositories und Authentifizierung
Beim Zugriff auf private Repositories (z. B. GitHub) stoßen automatische Systeme oft auf Anmeldeprobleme. Typisch ist eine Meldung wie „fatal: could not read Username“, wenn Git-Anmeldedaten nach dem ersten Klonen entfernt werden. Cloud-Repositories lösen das, indem sie Secret Manager oder SSH-Schlüssel einbinden, die sicher in der Build-Umgebung hinterlegt sind. Anstatt Passwörter in Skripten zu verwenden, greift der Build-Prozess auf verschlüsselte Tokens zurück. Das erhöht die Sicherheit und senkt das Risiko von Authentifizierungsfehlern.
Ressourcen- oder Kontingentbeschränkungen bei Cloud Builds
Manche Builds scheitern nicht wegen des Codes, sondern wegen Begrenzungen der Infrastruktur. Meldungen wie „due to quota restrictions, cannot run builds in this region“ zeigen, dass die Limits für gleichzeitige Builds erreicht sind. Cloud-Systeme stellen hierzu Übersichtsseiten für Kontingente bereit. Teams können Erhöhungen anfragen oder Builds auf andere Regionen verteilen. Auch der Einsatz privater Pools macht es möglich, feste Ressourcen zu reservieren, damit wichtige Builds nicht in der Warteschlange hängen bleiben oder wegen Zeitüberschreitung („Expired“) abgebrochen werden.
Timeouts und Netzwerkfehler (z. B. Docker-Registry, externe Ressourcen)
Netzwerkprobleme sind oft schwer greifbar. Ein Build versucht vielleicht, ein Docker-Image aus einer externen Registry zu laden, und bricht mit „i/o timeout“ ab. cloudbasierte Ansätze bieten hier Lösungen wie Proxy-Tools (z. B. Crane), um Images zuverlässiger zu laden und in eine lokale Registry zu übertragen. Private Pools helfen außerdem dabei, Netzwerkwege zu steuern. Muss ein Build auf Ressourcen in einem privaten VPC-Netz zugreifen, verhindert eine sauber konfigurierte Peering-Verbindung Fehler wie „no route to host“.
Race-Conditions und inkonsistente Projekteigenschaften
Gerade bei parallelen Builds (z. B. mit MSBuild) entstehen Race-Conditions, wenn mehrere Prozesse gleichzeitig versuchen, dieselbe Datei zu schreiben. Die Folge sind Fehler wie „The process cannot access the file because it is being used by another process“. Cloud-Build-Systeme begegnen dem, indem sie für jeden Build-Schritt eigene, isolierte Umgebungen bereitstellen. Zusätzlich können Ingenieure mit binären Logs (binlog) prüfen, wo Eigenschaften ungleich gesetzt sind. Durch Anpassung der Projektdateien oder durch Nutzung der Option /m:1 für eine serielle Ausführung in kritischen Phasen lassen sich diese Fehler gezielt beheben.
Lösungen für Zugriffs- und Lesefehler bei Commits
Wenn ein Trigger versucht, einen Build für einen Branch zu starten, der nicht existiert oder auf den kein Zugriff besteht, erscheint häufig „Couldn’t read commit“. Cloud-Repositories verringern dieses Risiko durch enge Verbindung von Triggern und Quellcode-Verwaltung. Ingenieure können Verzeichnisnamen auf Tippfehler prüfen und die Trigger-Konfiguration exakt an die Repository-Struktur anpassen. Die grafische Oberfläche der Cloud-Konsole hilft, diese Verknüpfungen klar zu prüfen.
Häufige Herausforderungen und wie sie mit Cloud-Tools gelöst werden
Was tun bei verweigerten Berechtigungen und IAM-Problemen?
Bei verweigerten Berechtigungen ist der erste Schritt der Blick in den Log-Explorer. Cloud-Plattformen zeichnen genau auf, welcher Akteur welche Aktion versucht hat. Wurde zum Beispiel der Cloud Build-Dienst-Agent gelöscht oder hat seine Rollen verloren, lässt sich das durch Zuweisen der Rolle roles/cloudbuild.serviceAgent korrigieren. Die Cloud-Konsole bietet oft automatische Prüfungen, die fehlende Berechtigungen erkennen und passende Vorschläge liefern. So sinkt der Aufwand für „Permission-Debugging“ von Stunden auf Minuten.
Strategien bei Build-Timeouts oder abgelaufenen Builds
Ein Build mit dem Status „Expired“, der keine Logs erzeugt hat, ist besonders ärgerlich. Gründe können zu niedrige queueTtl-Werte oder erschöpfte IP-Bereiche in privaten Pools sein. Ingenieure können dem begegnen, indem sie die Timeouts in der Konfigurationsdatei erhöhen oder den IP-Bereich des Subnetzes erweitern. Cloud-Tools liefern hierzu detaillierte Metriken über die Auslastung, mit denen Teams Engpässe erkennen, bevor sie zu Build-Abbrüchen führen. Auch der Einsatz leistungsstärkerer Maschinentypen kann lange Build-Schritte verkürzen.
Lösungsansätze für Netzwerkprobleme und Zugriff auf externe Ressourcen
Für den Zugriff auf das öffentliche Internet aus einem privaten Pool werden meist externe IP-Adressen benötigt. Kann ein Build keine Verbindung zu einer externen Domain herstellen, liegt das oft an fehlendem NAT oder deaktivierten externen IPs. Cloud-Tools erlauben es, diese Einstellungen zentral zu steuern. Durch Aktivieren der passenden Optionen in der Pool-Konfiguration lässt sich die Konnektivität wiederherstellen. Zusätzlich können dedizierte Worker-Nodes eingesetzt werden, damit Netzwerk-Traffic getrennt und stabil bleibt.
Genehmigungen für ausstehende oder veraltete Builds handhaben
In Umgebungen mit manuellen Freigaben können Builds „liegen bleiben“. Ist ein Build älter als zwei Monate, lässt er sich häufig nicht mehr genehmigen oder ablehnen, was dann zu 404-Fehlern führt. Die Lösung ist hier ein neuer Build. Cloud-Systeme unterstützen, indem sie Benachrichtigungen zu offenen Genehmigungen senden. So bleibt die Pipeline im Fluss, und veraltete Code-Stände blockieren keine Produktionsbereitstellungen.
Praktische Best Practices für Ingenieurteams zur Fehlerreduktion
Transparente Analyse von Build-Logs und automatischem Monitoring
Erfolgreiche Teams arbeiten datengetrieben. Ein Dashboard für Build-Metriken zahlt sich schnell aus. Über Kennzahlen wie Fehlerraten, Build-Dauer und häufige Abbruchgründe lassen sich Muster erkennen. Schlagen Builds zum Beispiel montagmorgens häufig wegen Netzwerk-Timeouts fehl, kann das auf geplante Wartungen oder Lastspitzen hindeuten. Automatische Alarme stellen sicher, dass Ingenieure sofort eine Meldung erhalten, wenn die Erfolgsquote unter einen definierten Wert fällt.
Zusätzlich lohnt es sich, strukturierte Logs zu verwenden. Statt nur einfache Textausgaben zu erzeugen, können Build-Skripte Informationen im JSON-Format ausgeben, die der Log-Explorer leichter filtern und auswerten kann. So lassen sich Fehler in bestimmten Phasen des Builds gezielt suchen, ohne mühsam tausende Zeilen Logtext lesen zu müssen.
Regelmäßige Überprüfung und Pflege von Repository-Berechtigungen
Berechtigungen sollten nach dem Prinzip „so wenig wie möglich, so viel wie nötig“ vergeben werden (Least Privilege). Regelmäßige Audits helfen, alte Dienstkonten oder Nutzer ohne aktuelle Rolle aus kritischen Repositories zu entfernen. Da Cloud-Systeme oft ausführliche Audit-Logs führen, ist leicht nachzuvollziehen, wer wann welche Berechtigungen genutzt hat. Das erhöht die Sicherheit und senkt zugleich das Risiko von Fehlern durch ungewollte Änderungen an der Build-Konfiguration.
Etablierung von Triggern, Pull Requests und automatisierten Tests
Ein stabiler Workflow beginnt mit sauberem Code-Review. Cloud-Repositories unterstützen dies, indem sie Trigger bereitstellen, die bei jeder Pull-Anfrage einen Test-Build anstoßen. Nur wenn dieser Build erfolgreich ist, kann gemergt werden. Diese „Gatekeeper“-Funktion hilft, die Qualität im Main Branch hoch zu halten. Teams sollten außerdem automatisierte Unit- und Integrationstests fest in jeden Build integrieren. Je früher ein Fehler entdeckt wird, desto günstiger und einfacher lässt er sich beheben.
Verknüpfung von CI/CD-Systemen mit Cloud-Repositories
Eine enge Kopplung zwischen Repository und CI/CD-Tool sorgt für Geschwindigkeit. Mit Diensten wie Developer Connect können Teams ihre bevorzugten Plattformen (z. B. GitHub) mit der Cloud-Infrastruktur verbinden. Empfehlenswert ist der Einsatz von Mechanismen wie Workload Identity Federation, um auf langlebige statische Keys zu verzichten. Das verringert Sicherheitsrisiken und schaltet eine häufige Fehlerquelle bei der Verbindung externer Tools aus.
Nächste Schritte für Ingenieurteams zur Fehlerreduktion mit Cloud-Repositories
Empfohlene Maßnahmen zur schnellen Verbesserung der Build-Qualität
Für schnelle Fortschritte sollten Teams zuerst ihre Build-Umgebungen vereinheitlichen. Der Einsatz von Docker-Containern in der Cloud-Build-Pipeline stellt sicher, dass jeder Build in einer sauberen, vordefinierten Umgebung läuft. Anschließend sollten Trigger für alle wichtigen Branches eingerichtet werden. So entsteht ein Sicherheitsnetz, das Fehler beim manuellen Starten von Builds vermeidet.
Außerdem lohnt sich eine gezielte Schulung des Teams. Grundkenntnisse zu IAM-Rollen und Cloud-nativen Logging-Tools gehören heute zum Handwerkszeug moderner Ingenieure. Ein Workshop zur Fehleranalyse mit echten Build-Logs kann die Selbstständigkeit der Entwickler deutlich stärken. Zusätzlich sollten Teams regelmäßig Kontingente und Ressourcenlimits prüfen, damit das Projektwachstum nicht an infrastrukturellen Grenzen scheitert.
Zukunftsaussichten: Wie entwickeln sich cloudbasierte Repositories weiter?
Innovationen in automatisierten Build- und Fehleranalyse-Tools
Die Zukunft cloudbasierter Repositories liegt in noch enger integrierten Analyse-Funktionen. Systeme werden Fehler nicht nur melden, sondern aktiv Lösungsvorschläge machen. Scheitert ein Build etwa an einer inkompatiblen Bibliotheksversion, könnte das Tool automatisch einen Patch oder ein Update der Konfiguration vorschlagen. Grenzen zwischen Quellcode-Verwaltung, Build-Infrastruktur und Monitoring verschwimmen zunehmend zu einer einheitlichen „Developer Experience Platform“.
Auch Sicherheit rückt weiter in den Mittelpunkt. Werkzeuge zur automatischen Erkennung von Schwachstellen in Abhängigkeiten (Software Composition Analysis) werden direkt beim Push eingebunden. So gelangt unsicherer Code gar nicht erst in den Build-Prozess. Die Cloud wird damit nicht nur Ausführungsumgebung, sondern auch aktiver Wächter über Code-Qualität und -Sicherheit.
Integration künstlicher Intelligenz zur Fehlerprävention
Künstliche Intelligenz wird den Umgang mit Build-Fehlern stark verändern. KI-Modelle können historische Build-Daten auswerten und einschätzen, wie stabil neue Änderungen sein werden. Noch bevor ein Entwickler auf „Push“ klickt, könnte eine KI warnen: „Ähnliche Änderungen haben in der Vergangenheit Race-Conditions in der Testphase ausgelöst.“ Diese vorausschauende Fehlervermeidung hebt die Effizienz von Ingenieurteams auf ein neues Niveau.
Auch bei der Fehlersuche hilft KI. Statt kryptische Meldungen zu interpretieren, können Entwickler in normaler Sprache fragen: „Warum ist mein Build in der Region ‘europe-west1’ fehlgeschlagen?“ Die KI analysiert Logs, prüft IAM-Berechtigungen und liefert eine verständliche Zusammenfassung mit konkreten Schritten zur Lösung. Cloudbasierte Repositories werden so zu intelligenten Partnern im Entwicklungsprozess, die den Weg zu stabilerer, fehlerarmer Software unterstützen.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.