Machine Learning (kurz: ML, deutsch: Künstliche Intelligenz) bestimmt in zunehmendem Maße die Geschäftswelt, weil es eine verlässliche Vorhersage in vielen Bereichen bietet, die genügend und qualitativ hochwertige Daten besitzen. Das Ziel dieses Kapitels ist es, die grundlegendsten Algorithmen in Bereich von Künstliche Intelligenz zu verstehen und unterscheiden zu können. Dazu müssen wir wissen, was Künstliche Intelligenz genau tut.
Aufgaben von Machine Learning
Machine Learning macht es möglich, dass Computersysteme erlernen, wie Aufgaben gelöst werden können, ohne dass diese Lösung explizit programmiert wurde. Die Modelle werden mit Daten gefüttert und entscheiden in vielen Trainingsschritten, wie sie ihre Vorhersage weiter verbessern können, um der Realität so nahe wie möglich kommen zu können.
Die ersten dieser Systeme gab es bereits in den 1950er Jahren. Im IBM Journal of Research and Development veröffentlichte Arthur Lee Samuels schon 1959 einen Beitrag über einen selbst lernenden Algorithmus für das Spiel Dame.
Einige unserer Beiträge im Bereich Künstliche Intelligenz

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.

Was ist der Omitted Variable Bias?
Verständnis des Omitted Variable Bias: Ursachen, Konsequenzen und Prävention. Erfahren Sie, wie Sie diese Falle vermeiden.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.

Was ist die Singular Value Decomposition?
Erkenntnisse und Muster freilegen: Lernen Sie die Leistungsfähigkeit der Singular Value Decomposition (SVD) in der Datenanalyse kennen.
Warum ist Künstliche Intelligenz wieder im Trend?
Obwohl das Paper von Arthur Lee Samuels bereits vor über 60 Jahren veröffentlicht wurde, hat das Thema Machine Learning erst in den letzten Jahren wirklich an Fahrt aufgenommen. Es gibt verschiedene Gründe, warum die Entwicklung für viele Jahre weitestgehend pausiert war:
- Die Leistung von Computer Prozessoren ist deutlich gestiegen und wir sind mittlerweile in der Lage, mehr Computerleistung auf weniger Fläche zu haben.
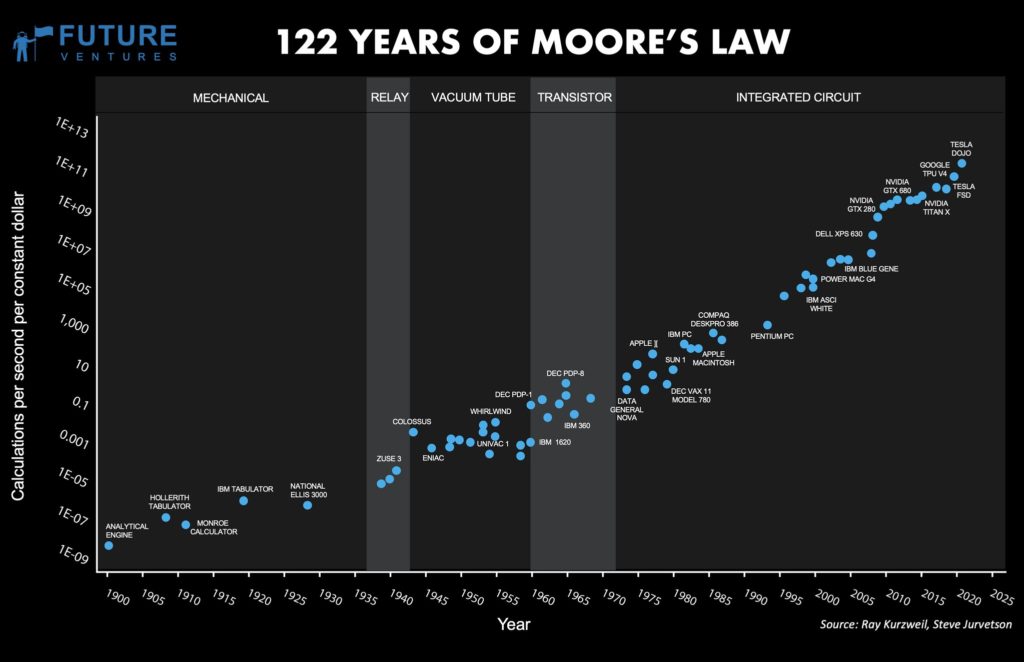
- Große Datenmengen können mittlerweile deutlich günstiger gespeichert und verwaltet werden. Hinzu kommt, dass neue Speichertechnologien es vereinfacht haben, Datensätze zu analysieren.
- Mittlerweile nutzen wir für viele Anwendungsfälle ganze Computer-Cluster auf denen rechenintensive Aufgaben aufgeteilt werden. Dadurch hat die Berechnungszeit der Modelle zusätzlich abgenommen und große Datenanalysen können in kurzer Zeit bewältigt werden.
- Durch die bereits genannten Punkte hat auch die Bereitschaft zur Datensammlung auch über Unternehmen hinaus stark zugenommen. Dadurch stehen neben Maschinen- und Unternehmensdaten auch große Mengen an Social Media Daten, Wetterdaten oder medizinischen Daten zur Verfügung.
- Die neuesten Entwicklungen sind beispielsweise über Python-Bibliotheken sehr vielen Menschen zugänglich. Darüber hinaus kann man kostenlos im Google Colab auf rechenstarke Maschinen zurückgreifen. Dadurch hat sich weltweit eine große Community gebildet, die aktiv ML anwendet und weiterentwickelt.
Was bedeutet Künstliche Intelligenz?
Der Begriff KI lässt sich nicht eindeutig definieren. Dies hängt damit zusammen, dass sich auch der Begriff Intelligenz nicht endgültig definieren lässt. Im Allgemeinen wird gerne zwischen sogenannter “Broad AI” (deutsch: Starke KI) und “Narrow AI” (deutsch: Schwacher KI) unterschieden.
Bei der Broad AI handelt es sich um Modelle und Algorithmen, die generelle Problemstellungen lösen, also lesen, rechnen, schreiben, Vorhersagen treffen etc. Ohne den einzelnen Beiträge hier vorgreifen zu wollen: Das ist heute noch nicht möglich und auch noch in weiter Ferne. Algorithmen, die sich sehr gut für alle sprachlichen Anwendungen (Übersetzen, Sprachverständnis, etc.) eignen können nicht rechnen und andersrum.
Alle Modelle, die wir zum heutigen Zeitpunkt haben, sind der Narrow AI zuzuordnen. Sie sind für ein klar definiertes Problem sehr gut geeignet und möglicherweise darin sogar besser als ein Mensch. Das klassische Beispiel dafür sind verschiedene Algorithmen für Brettspiele, in denen die Maschine bereits den Menschen geschlagen hat.
Darüber hinaus beschäftigt sich ein Teil der aktuellen Literatur nun auch damit, dass die KI Algorithmen auch ein wirkliches Verständnis entwickeln für das, was sie da tun. Bisher wurden viele Modelle vor allem darauf trainiert, statistische Korrelationen zu erkennen und abbilden zu können. Mittlerweile werden erste Algorithmen jedoch auch darauf trainiert ein Verständnis für die Daten zu entwickeln.
Zusammenfassung
Künstliche Intelligenz begegnet uns heutzutage in nahezu jedem Bereich des Lebens, ob im Beruf, beim privaten Surfen im Netz oder über E-Mails und andere Nachrichten, die perfekt auf unseren Geschmack zugeschnitten sind. Deshalb ist es durchaus hilfreich ein Grundverständnis der einzelnen Modelle und Algorithmen zu entwickeln. Dadurch kann man die Grenzen von Künstliche Intelligenz verstehen oder auch selbst für sein Unternehmen Möglichkeiten entdecken.