There are millions and billions of websites on the Internet and a correspondingly huge amount of information. Web Scraping is the process of automated website reading with the goal to be able to gain a lot of information in a short amount of time. This article shows how to realize simple web scraping projects with Python.
Brief Introduction: Source Code of a Website
In order for us to understand and apply web scraping, we also need to look at the general structure and functioning of a website. In this article, we will try to cover only the most basic elements, without which this text would otherwise be incomprehensible. On w3schools there are also detailed tutorials on HTML, CSS, and JavaScript, where you can go further in-depth.
The basic structure of any website is implemented with the help of Hypertext Markup Language (HTML). This is used, for example, to define which text sections are headings, to insert images or to define different page sections. In addition, Cascading Style Sheets (CSS) are used to design the website, i.e. to define the font and font color or to specify the spacing between text elements.
With the help of HTML and CSS, a large number of web pages can already be recreated. However, many also use JavaScript, in addition, to breathe life into the content. Generally speaking, everything you see when you click the refresh button or when you come to a new page (with a different URL) is programmed with HTML and CSS. Everything that “pops up” afterward or is opened with a button without(!) loading a completely new page is programmed with JavaScript.
If you are interested in how specific websites are built, you can view the source code of the open page in most browsers with the key combination Ctrl & Shift & i (MacBook accordingly Cmd instead of Ctrl). Otherwise, you can also right-click and then click Examine.
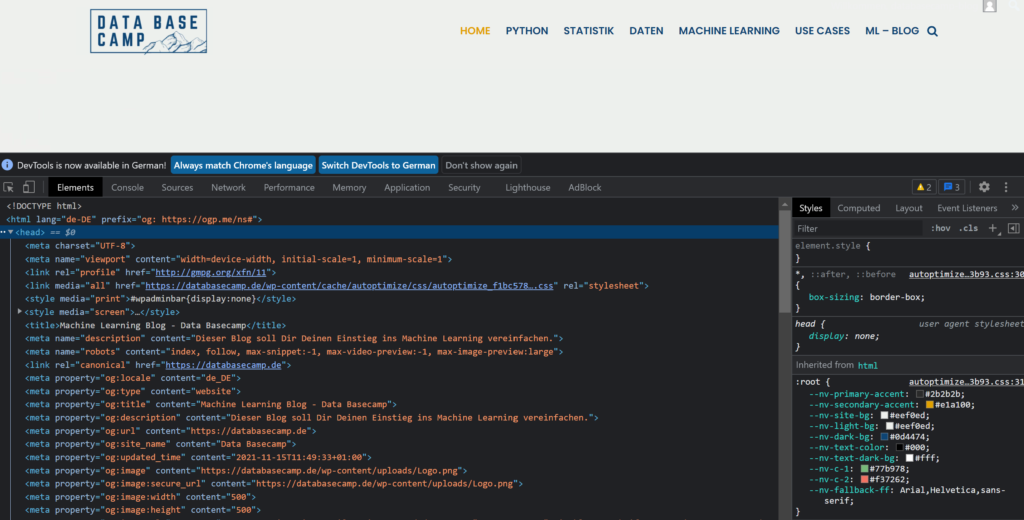
Python Libraries for Web Scraping
Python provides various libraries that can be used for web scraping. Basically, they differ in how “deeply” they can scrape information from the page. In web scraping, there are different levels of difficulty to get the desired data.
The easiest way to do this is to hide the information you want to grab in the code that gets executed when the page is initially loaded. The Python library Beautiful Soup is best suited for this, which we will also use in this example. Scrapy can be used for such applications too. It goes beyond Beautiful Soup in that it also helps with subsequent data processing and data storage.
The Selenium library is especially useful when interacting with the website must first take place in order to get the desired information at all. For example, if you have to log in first, you can open the website in Selenium and also interact with it via Python code. Beautiful Soup, for example, does not offer this feature, as it can only scrape the static elements of the website.
What do website operators think about scrapers?
For website operators, web scraping algorithms and other automated visits are comparatively easy to recognize via the web tracking tool. Simple web scrapers can be recognized, for example, by very short dwell times of less than one second or many pages accesses in a short time by one visitor. This suggests that it is not human access. The IP addresses of these visitors can then be blocked with just a few clicks. However, automated website visitors do not necessarily have to be a disadvantage for the company or website operator concerned.
The search engine Google, for example, scrapes relevant websites at regular intervals and searches them for so-called keywords and backlinks in order to update and improve the search sequence. Another example is price comparison sites, which regularly extract prices for relevant products with the help of web scrapers. An unknown online store for notebooks benefits from the wide reach of the comparison site and hopes to increase its sales as a result. These companies will gladly grant web scrapers access to their site. On the other hand, competitors can also use this method to query prices on a large scale, for example.
It’s hard to say whether web scraping on today’s web is just positive or just negative. In any case, it takes place more often than we think. In general, it is important for website operators that scrapers do not endanger the technically flawless functionality of the site and that they exclude automated visitors in their analysis so as not to draw false conclusions. Otherwise, it is decided on a case-by-case basis whether web scraping is rather harmful or useful for a site.
Example: Homepage Apple Inc.
For this example, we will scrape the Apple Inc. store to find out what product categories Apple currently offers. This simple example could be used to track categories over time and get an automated notification whenever Apple adds a new product category to its lineup. Admittedly, probably few people will really need such an evaluation, since you can find out after the Apple keynote on nearly any technology news portal, but it is an illustrative example.
The example shown was developed and tested in Python 3.7. First, we import two libraries, urllib we use for handling URLs and opening websites, and Beautifoul Soup for the actual web scraping. We store the complete code of the website in the variable “soup”, the library Beautiful Soup helps us with this.
import urllib.request
from bs4 import BeautifulSoup
url = "https://www.apple.com/store"
open_page = urllib.request.urlopen(url)
soup = BeautifulSoup(open_page, "html.parser")
print(soup)
An examination of the Apple Inc. site reveals that the names of the product categories are stored in sections with the class “rf-productnav-card-title”. These classes are assigned by the developers of the website and have to be searched for anew for each project. So before we can start building a web scraper, we need to identify the positions of the interesting information on the website. In our case, this is the described class.

In our source code of the website that we have stored in the variable “soup”, we now need to find all the elements of the class ” rf-productnav-card-title”. We do this with the command “findAll”. We can loop through these elements with a for loop and output only the text of the element in each case.
for category in soup.findAll(attrs={"class": "rf-productnav-card-title"}):
category = category.text.strip()
print(category)
# Output:
Mac
iPhone
iPad
Apple Watch
Apple TV
AirPods
HomePod Mini
iPod touch
Accessories
Apple Gift CardSo with these few lines of code, we managed to scrape information from the Apple website. Not all use cases will always be as quick to implement as this one. Of course, it can also happen that the information we are looking for is significantly more nested in the website. Furthermore, we also have to keep checking web scraping projects for functionality, as the scraped pages may change their structure, after which we have to rebuild our code. So there is no guarantee that our algorithm will still work in a few months, but must be checked and revised at regular intervals.
What are other Web Scraping techniques?
There are different types of web scraping, depending on what information you want to obtain from a website and where it is stored. The following forms are among the most common methods:
- Using HTML parsing libraries: We used this method in our example by using a Python library to extract information from the HTML structure of a website. This type of web scraping is well suited for simple web scraping tasks and when the information is already in the HTML structure of the website and no interaction, such as a button click, is required.
- Use of APIs: Depending on the type of website, it is possible that the page already provides a predefined interface, a so-called API, so that the data can be queried there in a structured manner. This type of web scraping is very suitable if the information is to be queried at regular intervals. The APIs enable easy access to the data and prevent a high load on the website through scraping.
- No-code tools for web scraping: Even non-technical users can create their web scrapers by using web scraping tools that do not require any programming code. Examples include Octoparse, Parsehub, and WebHarvy.
- Using browser automation: This technique uses tools, such as Selenium, that simulate human interaction with the website, revealing data that only comes to light when JavaScript code is executed. This scraping is useful for reading dynamic websites that are still rendering parts of the content.
- Using HTTP requests: With this type of web scraping, HTTP requests are sent directly to the website and the response is evaluated. This makes it possible to process websites that do not have a clearly defined HTML structure.
As we have seen, the choice of web scraping type depends not only on the structure of the website itself but also on the user’s previous knowledge and skills. A large number of websites can already be scraped with these tools. However, care should always be taken to ensure that permission has been obtained from the website owner and that certain standards are followed.
This is what you should take with you
- Web scraping is the automated reading of web pages to extract the desired information.
- Python offers various libraries for scraping, which are to be selected depending on the use case.
- Some understanding of the structure of websites is required to be able to program a working scraper.

What are Microservices?
Build scalable and modular applications with microservices. Enable flexible, independent services for efficient development and deployment.

What is Named Entity Recognition (NER)?
Explanation of Named Entity Recognition with examples and applications.

Sentiment Analysis with BERT and TensorFlow
Using BERT Embedding for text classification of IMDb movie ratings.

Convolutional Neural Network in TensorFlow with CIFAR10 images
Create a Convolutional Neural Network in Python with Tensorflow.
Other Articles on the Topic of Web Scraping
- If you really want to know everything about web scraping with Python, I highly recommend the book “Web Scraping with Python” by O’Reilly.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.