Die Singular Value Decomposition (SVD) ist ein mathematisches Verfahren, das sich zu einem wichtigen Werkzeug für die Datenanalyse in verschiedenen Bereichen wie Statistik, Informatik und Technik entwickelt hat. Sie wird verwendet, um die Dimensionalität großer Datensätze zu reduzieren, wichtige Merkmale zu extrahieren und versteckte Muster in den Daten aufzudecken.
In diesem Artikel erfährst Du, was die SVD ist, wie sie funktioniert und welche wichtigen Anwendungen es gibt.
Was ist die Singulärwertzerlegung?
Die Singulärwertzerlegung ist ein leistungsfähiges Verfahren zur Matrixfaktorisierung, das wertvolle Einblicke in die zugrunde liegende Struktur und die Eigenschaften einer Matrix bietet. Sie zerlegt eine Matrix in drei separate Matrizen: die linken Singulärvektoren, die Singulärwerte und die rechten Singulärvektoren. Zusammen offenbaren diese Komponenten wichtige Aspekte der ursprünglichen Matrix und bieten verschiedene Anwendungen in der Datenanalyse und darüber hinaus.
Die linken und rechten singulären Vektoren, die aus der SVD gewonnen werden, stellen die Richtungen der maximalen Variation in den Daten dar. Diese Vektoren bilden eine orthonormale Basis, die die Beziehung zwischen den Zeilen bzw. Spalten der Matrix erfasst. Sie helfen dabei, die grundlegenden Muster und Strukturen in den Daten aufzudecken, was sie für Aufgaben wie Dimensionalitätsreduktion, Merkmalsextraktion und Datenvisualisierung unerlässlich macht.
Die Singulärwerte hingegen geben die Bedeutung oder Signifikanz der einzelnen Variationsrichtungen an. Sie sind in absteigender Reihenfolge ihrer Größe angeordnet, wobei die größten Werte den einflussreichsten Richtungen entsprechen. Durch die Auswahl einer Teilmenge der größten Singulärwerte und der zugehörigen Singulärvektoren lässt sich die Dimensionalität der Daten wirksam reduzieren, wobei die wichtigsten Informationen erhalten bleiben. Diese Technik der Dimensionalitätsreduzierung wird häufig in Anwendungen wie der Datenkomprimierung, der Rauschunterdrückung und der Merkmalsauswahl eingesetzt.
Was sind die Komponenten der Singular Value Decomposition?
Bei der SVD liefert die Zerlegung einer Matrix in ihre einzelnen Komponenten wertvolle Erkenntnisse über die zugrunde liegende Struktur der Daten. Die SVD umfasst drei Hauptkomponenten: die linken Singulärvektoren, die Singulärwerte und die rechten Singulärvektoren.
Die linken singulären Vektoren stellen die Richtungen im Eingaberaum dar, die für die Erklärung der Varianz in den Daten am wichtigsten sind. Diese Vektoren bilden eine orthonormale Basis, die ein neues Koordinatensystem zur Darstellung der Daten liefert.
Die Singulärwerte quantifizieren die Bedeutung jedes linken Singulärvektors. Sie geben den Anteil der Varianz in den Daten an, der durch jeden Vektor erklärt werden kann. Die Singulärwerte sind in absteigender Reihenfolge angeordnet und ermöglichen so die Identifizierung der wichtigsten Komponenten.
Die rechten singulären Vektoren stellen die Richtungen im Ausgaberaum dar, die für die Erklärung der Varianz in den transformierten Daten am wichtigsten sind. Sie geben Aufschluss über die Beziehungen zwischen den ursprünglichen Merkmalen und den Hauptkomponenten.
Das Verständnis dieser Komponenten der SVD ist entscheidend, um sinnvolle Informationen aus den Daten zu extrahieren. Durch die Analyse der linken singulären Vektoren, der singulären Werte und der rechten singulären Vektoren können wir dominante Muster identifizieren, die Dimensionalität reduzieren und tiefere Einblicke in die zugrunde liegende Struktur der Daten gewinnen.
Wie funktioniert die SVD?
Die Singulärwertzerlegung ist ein Verfahren der Matrixfaktorisierung, bei dem eine Matrix in drei separate Matrizen zerlegt wird: U, Σ, und V^T. Diese Matrizen stellen die Schlüsselkomponenten der ursprünglichen Matrix dar und geben wertvolle Einblicke in ihre Struktur und Eigenschaften. Das Verständnis der Funktionsweise von SVD ist eine wesentliche Voraussetzung für die effektive Nutzung dieses leistungsstarken Algorithmus in verschiedenen Anwendungen.
Der Algorithmus lässt sich wie folgt zusammenfassen:
- Bei einer Eingangsmatrix A der Größe m x n findet SVD die Faktorisierung A = UΣV^T, wobei:
- U eine m x m orthogonale Matrix ist, die die linken singulären Vektoren enthält.
- Σ ist eine m x n Diagonalmatrix, die die Singulärwerte enthält.
- V^T ist die Transponierte einer n x n orthogonalen Matrix, die die rechten singulären Vektoren enthält.
- Die singulären Werte in Σ sind in absteigender Reihenfolge sortiert, was auf ihre Bedeutung für die Darstellung der Daten hinweist.
- Die singulären Vektoren in U und V^T sind orthonormal, d. h. sie stehen senkrecht zueinander und haben eine Einheitsnorm. Sie stellen die Richtungen oder Achsen dar, entlang derer die ursprüngliche Matrix A gestreckt oder transformiert wird.
- Die Singulärwerte in Σ geben Aufschluss über die Größe oder Bedeutung der einzelnen Singulärvektoren. Größere Singulärwerte weisen auf bedeutendere Beiträge zur Originalmatrix hin.
- Durch die Auswahl einer Teilmenge der wichtigsten Singulärwerte und der entsprechenden Singulärvektoren ist es möglich, die ursprüngliche Matrix A mit reduzierten Dimensionen zu approximieren. Dies ist nützlich für die Dimensionalitätsreduktion und die Datenkompression.
SVD kann zur Lösung linearer Gleichungssysteme, zur Matrixinversion und zur Berechnung von Matrix-Pseudoinversen verwendet werden.
Die Implementierung von SVD in Python kann mit verschiedenen Bibliotheken wie NumPy oder SciPy erfolgen. Diese Bibliotheken stellen effiziente Implementierungen des Algorithmus bereit und bieten zusätzliche Funktionen für die Arbeit mit den resultierenden Singulärwerten und Vektoren.
Wenn wir verstehen, wie SVD funktioniert, können wir eine Matrix in ihre grundlegenden Komponenten zerlegen und Einblicke in die zugrunde liegende Struktur der Daten gewinnen. Mit diesem Wissen können wir eine Vielzahl von Aufgaben wie Dimensionalitätsreduktion, Datenanalyse und Anwendungen des maschinellen Lernens durchführen.
Wie kann man den Algorithmus in Python implementieren?
Der Algorithmus der Singulärwertzerlegung ist eine leistungsstarke mathematische Technik, mit der eine Matrix in ihre Bestandteile zerlegt werden kann. Er wird in verschiedenen Anwendungen wie Datenkomprimierung, Dimensionalitätsreduktion und Matrixapproximation eingesetzt. In diesem Abschnitt werden wir die algorithmischen Schritte der SVD untersuchen und ihre Implementierung in Python anhand von Codeschnipseln demonstrieren.
In Python können Sie sie mit den folgenden Schritten implementieren:
- Importiere die erforderlichen Bibliotheken:

- Vorbereitung der Datenmatrix:

- Berechnung der Singular Value Decomposition in NumPy:

- Interpretation der Ergebnisse:
- Die Matrix U stellt die linken singulären Vektoren dar.
- Der Vektor S enthält die Singulärwerte.
- Die Matrix V stellt die rechten singulären Vektoren dar.
Hier ist ein Beispiel für die Implementierung des Algorithmus in Python:
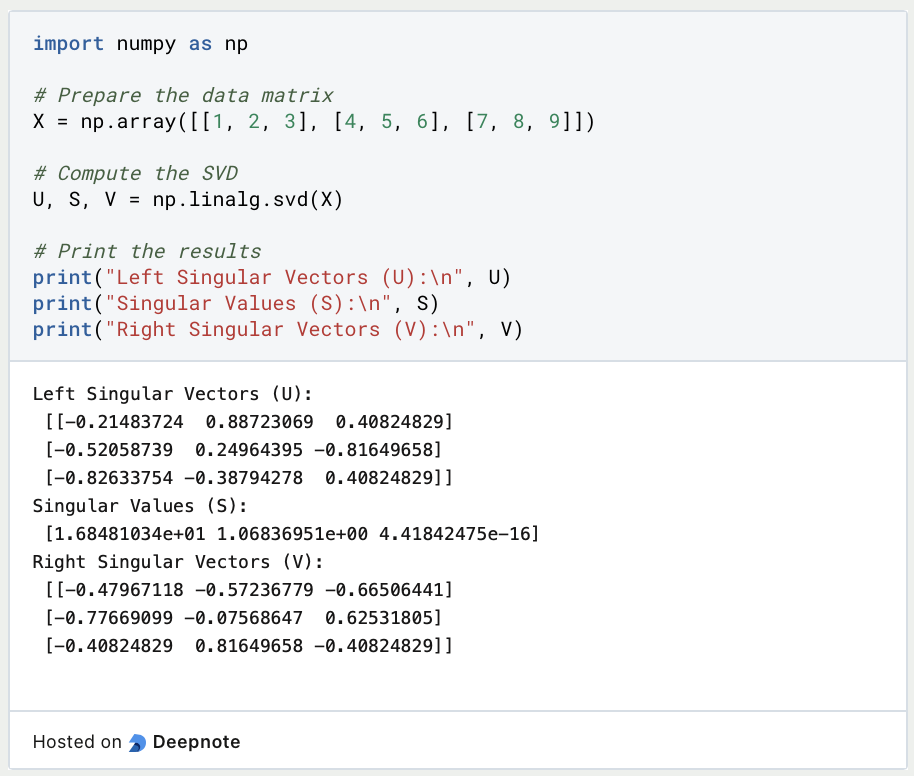
Wenn Du diesen Code ausführst, erhälst Du die linken singulären Vektoren, singulären Werte und rechten singulären Vektoren der Eingabematrix X. Diese Komponenten können weiter analysiert und für verschiedene Zwecke verwendet werden, wie z. B. Dimensionalitätsreduktion oder Matrixrekonstruktion.
Die Implementierung von SVD in Python unter Verwendung von Bibliotheken wie NumPy bietet eine bequeme und effiziente Möglichkeit, die Matrixzerlegung durchzuführen und die resultierenden Komponenten für weitere Analysen und Anwendungen zu nutzen.
Was sind die Eigenschaften und Erkenntnisse der SVD?
Die Singulärwertzerlegung bietet mehrere wichtige Eigenschaften und Erkenntnisse, die für das Verständnis und die Analyse von Daten wertvoll sind. Durch die Zerlegung einer Matrix in ihre Singulärwerte und Vektoren ermöglicht die SVD ein tieferes Verständnis der zugrunde liegenden Struktur und Beziehungen innerhalb der Daten.
Hier sind einige wichtige Eigenschaften und Erkenntnisse:
- Rang: Der Rang einer Matrix wird durch die Anzahl der von Null verschiedenen Singulärwerte in der Diagonalmatrix Σ bestimmt. Er stellt die intrinsische Dimensionalität oder die maximale Anzahl linear unabhängiger Zeilen oder Spalten in der Matrix dar. Der Rang ist nützlich für die Dimensionalitätsreduktion und die Bestimmung der wesentlichen Merkmale der Daten.
- Orthogonalität: Die linken singulären Vektoren (Spalten der Matrix U) und die rechten singulären Vektoren (Zeilen der Matrix V^T) sind orthogonal zueinander. Diese Orthogonalitätseigenschaft bedeutet, dass die singulären Vektoren verschiedene Richtungen oder Achsen darstellen, entlang derer die ursprüngliche Matrix transformiert wird.
- Hauptkomponenten: Die singulären Vektoren, die mit den größten singulären Werten assoziiert sind, erfassen die signifikanteste Variation in den Daten. Diese Vektoren, die als Hauptkomponenten bezeichnet werden, geben Aufschluss über die wichtigsten Muster und Strukturen in den Daten. Sie können zur Dimensionalitätsreduktion, Datenvisualisierung und Merkmalsauswahl verwendet werden.
- Datenkomprimierung: SVD ermöglicht die Datenkompression durch Annäherung an die ursprüngliche Matrix mithilfe einer Teilmenge von Singulärwerten und Vektoren. Durch die Auswahl der wichtigsten Komponenten ist es möglich, die Daten mit verringerten Dimensionen darzustellen, wobei eine erhebliche Menge an Informationen erhalten bleibt. Dies ist nützlich für die effiziente Speicherung und Übertragung großer Datensätze.
- Matrix-Rekonstruktion: Die SVD ermöglicht die Rekonstruktion der Originalmatrix anhand der ausgewählten Singulärwerte und Vektoren. Diese Rekonstruktion kann verwendet werden, um fehlende Werte zu ergänzen, Daten zu entrauschen oder die ursprüngliche Matrix aus ihrer Approximation mit niedrigem Rang wiederherzustellen.
- Matrixinversion und lineare Systeme: Es bietet eine bequeme Möglichkeit, die Inverse einer Matrix zu berechnen und lineare Gleichungssysteme zu lösen. Durch Manipulation der Singulärwerte und Vektoren lassen sich diese Operationen effizient durchführen.
Die Eigenschaften und Erkenntnisse von SVD finden in verschiedenen Bereichen Anwendung, darunter Datenanalyse, Bildverarbeitung, Empfehlungssysteme und Signalverarbeitung. Wenn wir diese Eigenschaften verstehen, können wir sie nutzen, um wertvolle Erkenntnisse zu gewinnen, die Dimensionalität von Daten zu reduzieren und komplexe Probleme effizient zu lösen.
Was sind die Anwendungen von SVD?
SVD hat viele Anwendungen in der Datenanalyse, darunter:
- Bildkomprimierung: SVD wird verwendet, um die Größe digitaler Bilder zu reduzieren und gleichzeitig ihre Qualität zu erhalten. Indem nur die wichtigsten Singulärwerte erhalten bleiben, kann die Größe des Bildes erheblich reduziert werden, ohne dass ein Großteil der Details verloren geht.
- Datenkompression: Die Singulärwertzerlegung kann zur Komprimierung großer Datensätze verwendet werden, so dass diese leichter gespeichert und analysiert werden können. Indem nur die wichtigsten Singulärwerte beibehalten werden, kann die Dimensionalität der Daten reduziert werden, während die meisten wichtigen Merkmale erhalten bleiben.
- Merkmalsextraktion: Sie wird verwendet, um wichtige Merkmale aus hochdimensionalen Datensätzen zu extrahieren. Indem man nur die wichtigsten singulären Vektoren und die entsprechenden singulären Werte behält, kann man die Dimensionalität der Daten reduzieren und gleichzeitig die meisten wichtigen Merkmale beibehalten.
- Empfehlungssysteme: Der Algorithmus wird verwendet, um latente Merkmale in Benutzer-Element-Matrizen zu entdecken, die zur Erstellung personalisierter Empfehlungen verwendet werden können. Indem nur die wichtigsten singulären Vektoren und die entsprechenden singulären Werte beibehalten werden, lassen sich Muster in den Daten erkennen, die für die Erstellung von Empfehlungen verwendet werden können.
Die Eigenschaften und Erkenntnisse von SVD finden in verschiedenen Bereichen Anwendung, darunter Datenanalyse, Bildverarbeitung, Empfehlungssysteme und Signalverarbeitung. Wenn wir diese Eigenschaften verstehen, können wir sie nutzen, um wertvolle Erkenntnisse zu gewinnen, die Dimensionalität von Daten zu reduzieren und komplexe Probleme effizient zu lösen.
Was sind die Erweiterungen und Variationen der SVD?
Die Singulärwertzerlegung wurde auf verschiedene Weise erweitert und modifiziert, um spezifischen Anforderungen und Herausforderungen in verschiedenen Bereichen gerecht zu werden. Einige bemerkenswerte Erweiterungen und Variationen der SVD sind:
Abgeschnittene SVD, bei der nur die obersten k Singulärwerte und die zugehörigen Singulärvektoren erhalten bleiben, was eine Verringerung der Dimensionalität und eine Annäherung an die ursprüngliche Matrix unter Beibehaltung wichtiger Informationen ermöglicht.
Randomisierte SVD, ein effizienter Näherungsalgorithmus, der zufällige Stichprobenverfahren zur Berechnung einer approximativen SVD verwendet. Er bietet schnellere Berechnungszeiten und ist für große Datensätze geeignet.
Probabilistische SVD, die probabilistische Modelle zur Schätzung der SVD einführt. Sie kombiniert Konzepte aus probabilistischen grafischen Modellen und der Matrixfaktorisierung, um fehlende Daten zu behandeln und Unsicherheiten in die Zerlegung einzubeziehen.
Nichtnegative Matrixfaktorisierung (NMF), eine Variante der SVD, die die Faktormatrizen auf nichtnegative Einträge beschränkt. Sie ist nützlich für nichtnegative Daten, wie Textdaten oder Bilddaten mit nichtnegativen Pixelwerten, und liefert interpretierbare Faktorisierungen.
Robuste Hauptkomponentenanalyse (PCA), eine Erweiterung der SVD, die Ausreißer und Datenverfälschungen behandelt, indem sie eine Matrix in dünn besetzte Komponenten mit niedrigem Rang zerlegt und die zugrunde liegende Struktur von Ausreißern oder Rauschen trennt.
Kernel PCA, eine Erweiterung der SVD auf nichtlineare Abbildungen durch Anwendung des Kernel-Tricks. Sie ermöglicht eine nichtlineare Dimensionalitätsreduktion und wird häufig beim maschinellen Lernen zur Merkmalsextraktion verwendet.
Collaborative Filtering, eine Anwendung der Matrixfaktorisierung, einschließlich SVD, für Empfehlungssysteme. Dabei werden Bewertungsmatrizen zwischen Benutzer und Artikel verwendet, um Benutzerpräferenzen vorherzusagen und personalisierte Empfehlungen zu geben.
Diese Erweiterungen und Variationen der SVD bieten erweiterte Fähigkeiten und lösen spezifische Herausforderungen in verschiedenen Bereichen, indem sie Flexibilität, Effizienz und verbesserte Interpretierbarkeit bieten. Sie erweitern das Spektrum der Anwendungen, in denen SVD und ihre Varianten effektiv eingesetzt werden können.
Was sind die Grenzen der SVD?
Die Singulärwertzerlegung ist zwar eine leistungsstarke Technik zur Analyse und Extraktion von Informationen aus Daten, aber sie hat auch bestimmte Einschränkungen und Überlegungen, die berücksichtigt werden müssen:
- Rechnerische Komplexität: SVD kann sehr rechenintensiv sein, insbesondere bei großen Matrizen. Der Zeit- und Speicherbedarf steigt mit der Größe der Matrix, was sie für extrem große Datensätze unpraktisch macht. Es wurden verschiedene Techniken, wie z. B. die randomisierte SVD, entwickelt, um dieses Problem zu entschärfen.
- Interpretierbarkeit der Komponenten: Die SVD liefert zwar eine Zerlegung der Daten in Singulärwerte und Vektoren, aber die Interpretation dieser Komponenten ist nicht immer einfach. Die singulären Vektoren lassen sich nicht direkt auf die ursprünglichen Merkmale abbilden, und ihre Bedeutung kann in komplexen Datensätzen schwer zu interpretieren sein.
- Empfindlichkeit gegenüber Rauschen: SVD ist empfindlich gegenüber Rauschen in den Daten. Ausreißer oder Messfehler können die Zerlegung erheblich beeinflussen und die Genauigkeit der Ergebnisse beeinträchtigen. Durch Vorverarbeitungstechniken wie Datenbereinigung und Normalisierung kann dieses Problem gemildert werden.
- Annäherung an den Rang: In einigen Fällen kann die Bestimmung des optimalen Rangs für die Matrixannäherung eine Herausforderung darstellen. Die Auswahl der Anzahl der beizubehaltenden Singulärwerte erfordert eine sorgfältige Abwägung und kann einen Kompromiss zwischen dem Erhalt von Informationen und der Reduzierung der Dimensionalität bedeuten.
- Datenauswertung: SVD kann verborgene Muster und Strukturen in den Daten aufdecken, aber sie liefert keine expliziten Interpretationen dieser Muster. Um die Bedeutung der zerlegten Komponenten zu verstehen, ist oft zusätzliches Fachwissen und Kontext erforderlich.
- Nicht-Eindeutigkeit: Der Algorithmus ist nicht eindeutig, da es für eine bestimmte Matrix mehrere Zerlegungen geben kann. Verschiedene Implementierungen oder Variationen des Algorithmus können zu leicht unterschiedlichen Ergebnissen führen. Es ist wichtig, diese Nicht-Eindeutigkeit zu verstehen und die Stabilität der Zerlegung zu bewerten.
- Behandlung fehlender Daten: Die SVD kann fehlende Daten nicht direkt verarbeiten. Um fehlende Werte zu behandeln, müssen zuvor Imputationstechniken angewandt werden, die zusätzliche Unsicherheit und potenzielle Verzerrungen in die Analyse einbringen können.
- Skalierbarkeit: SVD kann bei hochdimensionalen Daten Probleme mit der Skalierbarkeit haben. Der Fluch der Dimensionalität kann die Leistung und Genauigkeit der Zerlegung beeinträchtigen. Techniken zur Dimensionalitätsreduzierung, wie PCA, können eingesetzt werden, um dieses Problem zu lösen.
Das Verständnis der Grenzen von SVD hilft dabei, fundierte Entscheidungen bei der Anwendung dieser Technik auf reale Probleme zu treffen. Es ist wichtig, diese Faktoren zu berücksichtigen und zu bewerten, ob dieser Ansatz für den spezifischen Datensatz und die Analyseziele geeignet ist.
Das solltest Du mitnehmen
- Die Singulärwertzerlegung ist ein leistungsfähiges Verfahren zur Matrixfaktorisierung, das zur Dimensionalitätsreduzierung, Datenkomprimierung und Extraktion latenter Merkmale eingesetzt wird.
- Sie liefert eine kompakte Darstellung der Daten durch Zerlegung einer Matrix in drei Matrizen: U, Σ, und V.
- Die singulären Werte in Σ stellen die Bedeutung der entsprechenden singulären Vektoren in U und V dar und geben die Variabilität und Muster in den Daten wieder.
- Der Algorithmus hat ein breites Anwendungsspektrum, u. a. in den Bereichen Bildverarbeitung, Text Mining, Empfehlungssysteme und Datenanalyse.
- Er bietet Einblicke in die Struktur und die Beziehungen innerhalb der Daten und ermöglicht so ein besseres Verständnis und eine bessere Interpretation.
- Der SVD-Algorithmus hat seine Grenzen, z. B. die Komplexität der Berechnungen bei großen Datensätzen und die Herausforderungen bei der Interpretation der Komponenten.
- Um genaue und aussagekräftige Ergebnisse zu erzielen, müssen die Vorverarbeitung, die Behandlung von Rauschen und die Auswahl der Ränge sorgfältig berücksichtigt werden.
- Trotz ihrer Einschränkungen bleibt die SVD ein wertvolles Instrument für die Datenanalyse und bildet die Grundlage für andere Verfahren wie die Hauptkomponentenanalyse (PCA).
- Laufende Forschungen und Weiterentwicklungen verbessern die Algorithmen und ihre Anwendungen in verschiedenen Bereichen weiter.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.

Was ist die Poisson Regression?
Lernen Sie die Poisson-Regression kennen, ein statistisches Modell für die Analyse von Zähldaten, inkl. einem Beispiel in Python.

Was ist blockchain-based AI?
Entdecken Sie das Potenzial der blockchain-based AI in diesem aufschlussreichen Artikel über Künstliche Intelligenz und Blockchain.

Was ist Boosting im Machine Learning?
Boosting: Eine Ensemble-Technik zur Modellverbesserung. Lernen Sie in unserem Artikel Algorithmen wie AdaBoost, XGBoost, uvm. kennen.
Andere Beiträge zum Thema Singular Value Decomposition
Das Massachusetts Institute of Technology (MIT) veröffentlichte ebenfalls einen interessanten Artikel zu diesem Thema.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.