Das Convolutional Neural Network (CNN oder ConvNet) ist eine Unterform der Neural Networks und wird vor allem für Anwendungen in der Bild- und Spracherkennung genutzt. Diese Anwendungen kommen nicht von irgendwoher, da der Aufbau des Netzwerkes dem biologischen Aufbau der menschlichen Sehrinde nachempfunden ist.
Recap: Neuronale Netzwerke (Fully-Connected)
Normale Neuronale Netzwerke verarbeiten einen Input, indem sie verschiedene sogenannte Hidden Layer durchlaufen. Jede dieser Schichten ist aus Neuronen aufgebaut, die mit allen Neuronen der vorangegangenen Schicht vernetzt sind. Die Neuronen in einer Hidden Layer können nicht mit den anderen Bausteinen in der Schicht kommunizieren, sondern sind lediglich mit der vorangegangenen Schicht und der nachfolgenden Schicht verbunden. Die letzte dieser Schichten ist dann die Ausgabeschicht aus der wir die Vorhersage des Neuronalen Netzes entnehmen können.
Welche Probleme gibt es bei der Bildverarbeitung?
Wenn wir dieses Fully-Connected Neural Network für die Bildverarbeitung nutzen wollen, stellen wir schnell fest, dass es sich nicht sehr gut skalieren lässt. Für den Computer ist ein Bild in der RGB-Notation die Zusammenfassung aus drei verschiedenen Matrizen. Für jedes Pixel des Bildes wird darin beschrieben, welche Farbe dieses Pixel anzeigt. Dies tun wir, indem wir in der ersten Matrix den Rotanteil definieren, in der zweiten den Grünanteil und in der letzten dann den Blauanteil. Für ein Bild mit der Größe 3 auf 3 Pixel ergeben sich also drei verschiedene 3×3 Matrizen.
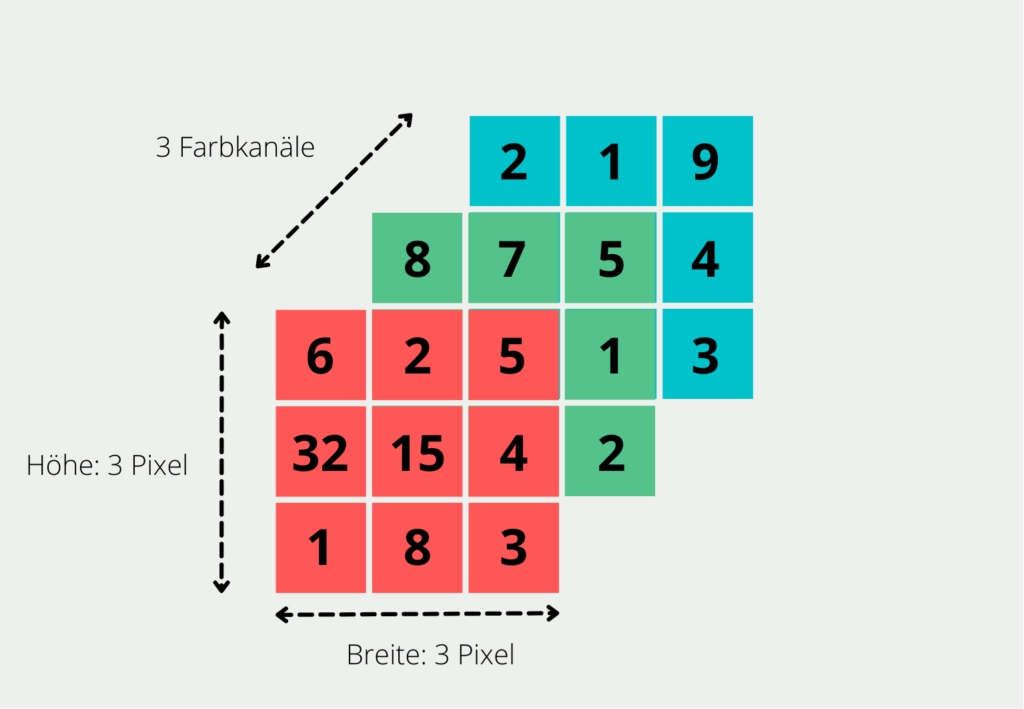
Um ein Bild zu verarbeiten, geben wir jedes einzelne Pixel als Input in das Netzwerk ein. Für ein Bild der Größe 200x200x3 (also 200 Pixel auf 200 Pixel mit 3 Farbkanälen, bspw. rot, grün und blau) müssen wir also 200 * 200 * 3= 120.000 Input Neuronen bereitstellen. Dann hat jede Matrix eine Größe von 200 auf 200 Pixel, also 200 * 200 Einträge insgesamt. Diese Matrix gibt es dann schließlich dreimal, jeweils für Rot, Blau und Grün. Das Problem entsteht dann in der ersten Hidden Layer, denn jedes der Neuronen dort hätte 120.000 Gewichte aus der Input Layer. Das heißt die Anzahl der Parameter würde sehr schnell ansteigen, wenn wir die Zahl der Neuronen in der Hidden Layer steigern.
Diese Herausforderung verschärft sich noch, wenn wir größere Bilder mit mehr Pixeln und mehr Farbkanälen verarbeiten wollen. Ein solches Netzwerk mit einer riesigen Anzahl von Parametern wird sehr wahrscheinlich ins Overfitting laufen. Dies bedeutet, dass das Modell gute Vorhersagen für den Trainingssatz liefert, aber sich nicht gut generalisieren lässt auf neue Fälle, die es noch nicht kennt. Zusätzlich würde das Netzwerk aufgrund der vielen Parameter sehr wahrscheinlich aufhören, auf einzelne Bilddetails einzugehen, da sie in der schieren Masse untergehen. Wenn wir jedoch ein Bild klassifizieren wollen, bspw. ob darin ein Hund zu sehen ist oder nicht, können diese Details, wie die Nase oder die Ohren, den entscheidenden Ausschlag für das richtige Ergebnis geben.
Was macht das Convolutional Neural Network anders?
Das Convolutional Neural Network fährt aus diesen Gründen einen anderen Ansatz, der der Art und Weise nachgeahmt ist, wie wir unsere Umwelt mit dem Auge erfassen. Wenn wir ein Bild sehen, dann teilen wir es automatisch in viele kleine Unterbereiche auf und analysieren dieses einzeln. Durch die Zusammensetzung dieser Teilbilder verarbeiten und interpretieren wir das Bild. Wie lässt sich dieses Prinzip in einem Convolutional Neural Network umsetzen?
Die Arbeit passiert in der sogenannten Convolution Layer. Dazu definieren wir einen Filter, der bestimmt wie groß die Teilbilder sein sollen, die wir betrachten, und eine Schrittlänge, die entscheidet wie viele Pixel wir zwischen den Berechnungen weiterfahren, also wie nahe die Teilbilder aneinander liegen. Durch diesen Schritt haben wir die Dimensionalität des Bildes stark reduziert.
Als nächstes folgt die Pooling Layer. Rein rechnerisch passiert hier dasselbe erstmal wie in der Convolution Layer mit dem Unterschied, dass wir vom Ergebnis je nach Anwendung entweder nur den Durchschnitts- oder Maximalwert übernehmen. Dadurch bleiben kleine Features in wenigen Pixeln erhalten, die für die Aufgabenlösung entscheidend sind.
Zum Abschluss kommt eine Fully-Connected Layer im Convolutional Neural Network, wie wir sie bereits von den normalen Neural Networks kennen. Nachdem wir nun die Dimensionen des Bildes stark reduziert haben, können wir nun die eng-vermaschten Schichten nutzen. Hier werden die einzelnen Teilbilder wieder miteinander verknüpft, um die Zusammenhänge zu erkennen und die Klassifizierung vorzunehmen.
Nachdem wir nun ein Grundverständnis haben, was die einzelnen Schichten des Convolutional Neural Network im groben machen, können wir uns im Detail damit beschäftigen, wie aus einem Bild eine Klassifizierung wird. Dazu versuchen wir, aus einem 4x4x3 Bild zu erkennen, ob darin ein Hund zu sehen ist.
Detail: Convolutional Layer
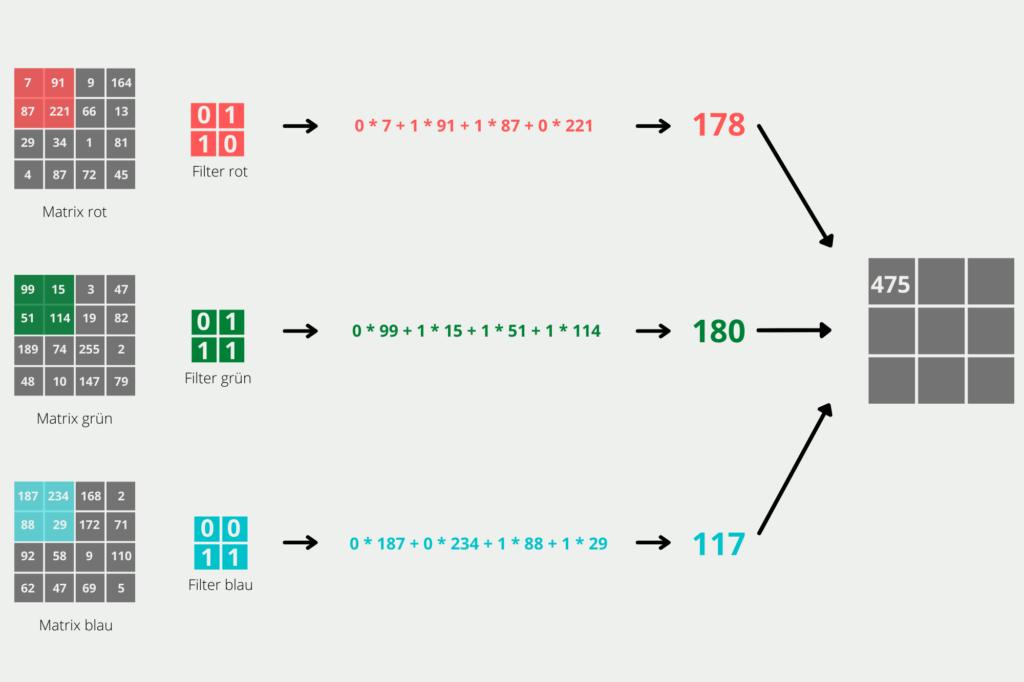
In ersten Schritt wollen wir die Dimensionen des 4x4x3 Bildes verringern. Dazu definieren wir für jede Farbe einen Filter mit der Dimension 2×2. Zusätzlich wollen wir eine Schrittlänge von 1, d.h. nach jedem Berechnungsschritt soll der Filter um genau einen Pixel weiterverschoben. Dadurch verringert sich zwar die Dimension nicht so stark, aber Details des Bildes bleiben erhalten. Wenn wir eine 4×4 Matrix mit einer 2×2 abwandern und in jedem Schritt eine Spalte oder eine Zeile weitergehen, hat unsere Convolutional Layer eine 3×3 Matrix als Output. Die einzelnen Werte der Matrix errechnen sich, indem wir das Skalarprodukt der 2×2 Matrizen bilden, wie aus der Grafik hervorgeht.
Detail: Pooling Layer
Die (Max) Pooling Layer übernimmt die 3×3 Matrix der Convolutional Layer als Input und versucht die Dimensionalität weiter zu reduzieren und zusätzlich die wichtigen Features im Bild zu übernehmen. Wir wollen als Output dieser Schicht eine 2×2 Matrix generieren, deshalb unterteilen wir den Input in alle möglichen 2×2 Teilmatrizen und suchen in diesen Feldern den höchsten Wert. Das ist dann der Wert im Feld der Output-Matrix. Wenn wir statt einer Max Pooling Layer die Average Pooling Layer nutzen würden, würden wir stattdessen den Durchschnitt der vier Felder berechnen.
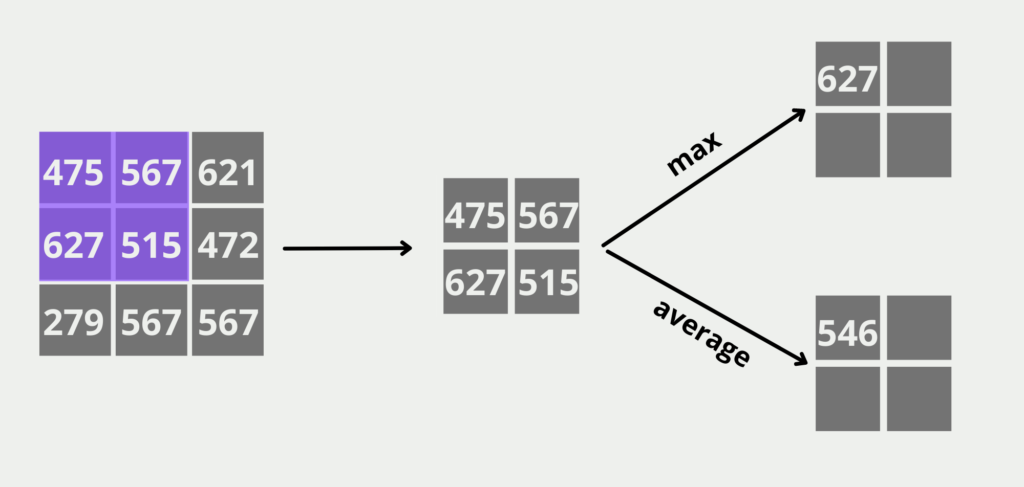
Die Pooling Layer im Convolutional Neural Network sorgt zusätzlich dafür Noise aus dem Bild herauszufiltern, also Elemente des Bildes die nicht zur Klassifizierung beitragen. Beispielsweise, ob der Hund vor einem Haus oder vor einem Wald steht ist erstmal unwichtig.
Detail: Fully-Connected Layer
Die Fully-Connected Layer macht nun genau das, was wir zu Beginn mit dem ganzen Bild vorhatten. Wir erstellen für jeden Eintrag in der kleineren 2×2 Matrix ein Neuron bereit und verbinden diese mit allen Neuronen der nächsten Schicht. Dadurch haben wir deutlich weniger Dimensionen und benötigen weniger Ressourcen im Training.
Diese Layer lernt dann schließlich, welche Teilbereiche des Bildes benötigt werden, um die Klassifikation Hund oder Nicht-Hund treffen zu können. Wenn wir Bilder haben die deutlich größer sind als unser 5x5x3 Beispiel, ist es natürlich auch möglich die Convolutional Layer und Pooling Layer öfters hintereinander zu setzen, bevor man in die Fully-Connected Layer geht. Dadurch kann man die Dimensionalität weit genug heruntersetzen, um den Trainingsaufwand zu reduzieren.
Wie kann die Trainingsmenge für Convolutional Neural Networks vergrößert werden?
Zum Training von Modellen in der Bildverarbeitung werden oft große Datensätze benötigt. Vor allem im Bereich des Supervised Learnings, bei denen jedes Bild ein Label benötigt, sind diese jedoch oft nur schwer und teuer zu bekommen, da sie meist von Hand klassifiziert werden müssen. Deshalb gibt es im Bereich der Data Augmentation verschiede Möglichkeiten den Datensatz künstlich zu vergrößern.
Bei der Datenerweiterung werden die vorhandenen Trainingsdaten transformiert, um neue Trainingsbeispiele zu erstellen. Die Idee ist, dass diese neuen Beispiele den ursprünglichen Beispielen so ähnlich sind, dass sie die gleichen zugrunde liegenden Muster erfassen, aber so unterschiedlich sind, dass sie dem Netzwerk zusätzliche Informationen liefern.
Einige gängige Transformationen, die in CNNs zur Datenerweiterung verwendet werden, sind:
- Drehen: Das Drehen des Bildes um einen bestimmten Winkel kann dem Netz helfen, rotationsinvariante Merkmale zu lernen.
- Spiegeln: Durch horizontales oder vertikales Drehen des Bildes kann das Netz Merkmale erlernen, die sich nicht verändern lassen.
- Zuschneiden und Größenänderung: Das zufällige Zuschneiden und Ändern der Größe des Bildes kann dem Netzwerk helfen, skaleninvariante Merkmale zu lernen.
- Farbverschiebung: Die Anwendung von zufälligen Farbtransformationen auf das Bild, wie z. B. die Änderung der Helligkeit oder des Kontrasts, kann dem Netzwerk helfen, farbinvariante Merkmale zu lernen.
- Gaußsches Rauschen: Das Hinzufügen von Gaußschem Rauschen zum Bild kann dem Netz helfen, Merkmale zu lernen, die gegenüber Rauschen robust sind.
- Elastische Verformung: Die Anwendung von elastischen Verformungen auf das Bild kann dem Netz helfen, Merkmale zu erlernen, die gegenüber kleinen Verzerrungen robust sind.
Es ist wichtig zu beachten, dass die Datenerweiterung so vorgenommen werden sollte, dass der semantische Inhalt des Bildes erhalten bleibt. Wenn man zum Beispiel das Bild einer Katze horizontal dreht, erhält man immer noch das Bild einer Katze, aber wenn man ein Bild mit Text horizontal dreht, erhält man Kauderwelsch.
Insgesamt kann die Datenerweiterung ein leistungsfähiges Instrument zur Verbesserung der Leistung von CNNs sein, insbesondere wenn sie in Kombination mit anderen Techniken wie Regularisierung und frühzeitigem Abbruch eingesetzt wird.
Welche Optimierungsalgorithmen können zum Training von CNNs verwendet werden?
Es gibt mehrere Optimierungsalgorithmen, die zum Trainieren von Convolutional Neural Networks (CNN) verwendet werden können, darunter:
- Stochastischer Gradientenabstieg (SGD): SGD ist ein beliebter Optimierungsalgorithmus, der zum Trainieren von CNNs verwendet wird. Bei diesem Verfahren werden die Gewichte des Netzes anhand der Gradienten der Verlustfunktion in Bezug auf die Gewichte aktualisiert. Die Lernrate bestimmt die Schrittweite der Gewichtungsaktualisierungen.
- Adagrad: Adagrad ist ein adaptiver Optimierungsalgorithmus, der die Lernrate für jedes Gewicht auf der Grundlage der historischen Gradienten für dieses Gewicht anpasst. Dies kann in Fällen nützlich sein, in denen einige Gewichte mehr Aktualisierungen benötigen als andere.
- Adadelta: Adadelta ist ein weiterer adaptiver Optimierungsalgorithmus, der eine Schätzung des zweiten Moments der Gradienten zur adaptiven Anpassung der Lernrate verwendet. Er wurde entwickelt, um einige der Einschränkungen von Adagrad zu beheben, wie z. B. das Problem der abnehmenden Lernrate.
- Adam: Adam ist ein beliebter adaptiver Optimierungsalgorithmus, der Ideen von Adagrad und RMSprop kombiniert. Er behält eine Schätzung der ersten und zweiten Momente der Gradienten bei, um die Lernrate adaptiv anzupassen.
- Momentum: Momentum ist eine Technik, die den Aktualisierungen der Gewichte einen Momentum-Term hinzufügt, der dem Optimierungsalgorithmus hilft, sich in dieselbe Richtung wie die vorherigen Aktualisierungen zu bewegen. Dies kann dazu beitragen, die Konvergenz zu beschleunigen und Oszillationen zu reduzieren.
- Nesterov-Beschleunigter Gradient (NAG): NAG ist eine Variante des Momentums, bei der der Gradient an einem zukünftigen Punkt im Gewichtsraum auf der Grundlage des aktuellen Momentums berechnet wird. Dies kann dazu beitragen, Oszillationen zu reduzieren und die Konvergenz zu beschleunigen.
Jeder Optimierungsalgorithmus hat seine Stärken und Schwächen, und die Wahl des Algorithmus hängt von dem spezifischen Problem, das gelöst werden soll, und den Eigenschaften des Datensatzes ab. Es ist üblich, verschiedene Optimierungsalgorithmen auszuprobieren und ihre Leistung mit einer Validierungsmenge zu vergleichen, um den besten Algorithmus auszuwählen.
Das solltest Du mitnehmen
- Convolutional Neural Networks werden in der Bild- und Sprachverarbeitung genutzt und orientieren sich am Aufbau der menschlichen Sehrinde.
- Sie bestehen aus Convolutional Layer, Pooling Schicht und der Fully-Connected Layer.
- Convolutional Neural Networks zerteilen das Bild in kleinere Bereiche, um diese erstmal getrennt voneinander zu betrachten.
- Dadurch sind Convolutional Neural Networks deutlich ressourceneffizienter, als wenn wir eine solche Berechnung in einem Fully-Connected Neural Network machen würden.

Was ist eine Boltzmann Maschine?
Die Leistungsfähigkeit von Boltzmann Maschinen freisetzen: Von der Theorie zu Anwendungen im Deep Learning und deren Rolle in der KI.

Was ist die Gini-Unreinheit?
Erforschen Sie die Gini-Unreinheit: Eine wichtige Metrik für die Gestaltung von Entscheidungsbäumen beim maschinellen Lernen.

Was ist die Hesse Matrix?
Erforschen Sie die Hesse Matrix: Ihre Mathematik, Anwendungen in der Optimierung und maschinellen Lernen.

Was ist Early Stopping?
Beherrschen Sie die Kunst des Early Stoppings: Verhindern Sie Overfitting, sparen Sie Ressourcen und optimieren Sie Ihre ML-Modelle.

Was sind Gepulste Neuronale Netze?
Tauchen Sie ein in die Zukunft der KI mit Gepulste Neuronale Netze, die Präzision, Energieeffizienz und bioinspiriertes Lernen neu denken.

Was ist RMSprop?
Meistern Sie die RMSprop-Optimierung für neuronale Netze. Erforschen Sie RMSprop, Mathematik, Anwendungen und Hyperparameter.
Andere Beiträge zum Thema Convolutional Neural Network
- Eine Erklärung zu Convolutional Neural Networks und deren Umsetzung in Tensorflow findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.