In der Welt des maschinellen Lernens gibt es eine leistungsstarke Technik, die es den Modellen ermöglicht, mehrere Aufgaben gleichzeitig zu bewältigen und dabei von gemeinsamem Wissen zu profitieren. Diese Technik ist als Multi-Task Learning (MTL) bekannt. Anstatt für jede Aufgabe ein eigenes Modell zu trainieren, nutzt MTL die Verbindungen zwischen verwandten Aufgaben, um die Leistung und Effizienz von Algorithmen für maschinelles Lernen zu verbessern. Ob es sich um Computer Vision, natürliche Sprachverarbeitung, Gesundheitswesen oder Empfehlungssysteme handelt, MTL hat sich in einer Vielzahl von Anwendungen als wegweisend erwiesen.
Was ist Multi-Task Learning?
Multi-Task Learning ist eine Technik des maschinellen Lernens, die darauf abzielt, die Leistung eines Modells zu verbessern, indem es für die gleichzeitige Ausführung mehrerer verwandter Aufgaben trainiert wird. Ein einzelnes Modell ist so konzipiert, dass es nicht nur eine primäre Aufgabe, sondern mehrere Aufgaben bewältigt, die in irgendeiner Weise miteinander verbunden sind. Bei diesem Ansatz werden die gemeinsamen Informationen und Muster zwischen den Aufgaben genutzt, um die Leistung, Generalisierung und Effizienz des Modells zu verbessern.
MTL ist auf dem Gebiet des maschinellen Lernens aus mehreren Gründen von großer Bedeutung:
- Effizienter Wissenstransfer: MTL ermöglicht es dem Modell, Wissen von einer Aufgabe auf eine andere zu übertragen. Es profitiert von den gemeinsam genutzten Mustern und Informationen, so dass es nicht für jede Aufgabe von Grund auf neu lernen muss.
- Verbesserte Generalisierung: Durch das gemeinsame Lernen mehrerer Aufgaben kann das Modell besser verallgemeinern und genauere Vorhersagen machen, insbesondere wenn die Daten für einzelne Aufgaben begrenzt sind.
- Regularisierungseffekt: MTL wirkt als eine Form der Regularisierung. Durch die gemeinsame Optimierung mehrerer Aufgaben wird eine Überanpassung verhindert, was zu robusteren Modellen führt.
- Geringere Datenanforderungen: Anstatt für jede einzelne Aufgabe eine große Menge an Daten zu benötigen, kann MTL mit kleineren Datensätzen für jede Aufgabe effektiv arbeiten, was es in Situationen mit knappen Daten praktisch macht.
Es unterscheidet sich vom traditionellen Single-Task-Learning in folgenden Punkten:
- Aufgabenunabhängigkeit: Beim Single-Task-Learning wird jedes Modell unabhängig für eine bestimmte Aufgabe trainiert. Beim MTL werden mehrere Aufgaben gemeinsam trainiert, und ihre Abhängigkeiten werden berücksichtigt.
- Gemeinsame Parameter: In der Regel werden Parameter und Merkmale für mehrere Aufgaben gemeinsam genutzt. Beim Lernen mit nur einer Aufgabe werden die gemeinsamen Informationen nicht in gleichem Maße genutzt.
- Gesteigerte Leistung: Im Vergleich zum Lernen mit nur einer Aufgabe, bei dem die Leistung für eine Aufgabe auf Kosten der anderen optimiert werden kann, führt dies häufig zu einer verbesserten Leistung für alle beteiligten Aufgaben.
Die wichtigsten Vorteile sind die folgenden
- Verbesserte Genauigkeit: MTL kann zu genaueren Vorhersagen führen, indem das zwischen den Aufgaben geteilte Wissen genutzt wird.
- Daten-Effizienz: Es kann mit kleineren Datensätzen arbeiten und ist daher ideal für Szenarien mit begrenzter Datenverfügbarkeit.
- Zeiteffizienz: MTL reduziert die Notwendigkeit, separate Modelle für jede Aufgabe zu trainieren, und spart so Zeit und Rechenressourcen.
- Bessere Verallgemeinerung: Die gemeinsame Optimierung mehrerer Aufgaben führt häufig zu einer besseren Generalisierung, insbesondere bei komplexen und zusammenhängenden Aufgaben.
- Regularisierung: MTL fungiert als eine Form der Regularisierung, die das Risiko einer Überanpassung bei einzelnen Aufgaben verringert.
Multi-Task Learningist eine vielseitige Technik, die in verschiedenen Bereichen eingesetzt wird, z. B. bei der Verarbeitung natürlicher Sprache, beim Computersehen und im Gesundheitswesen, um nur einige zu nennen. Durch die Nutzung von gemeinsamem Wissen bietet es einen überzeugenden Ansatz zur effizienten Bewältigung komplexer maschineller Lernprobleme.
Was sind die verschiedenen Arten des Multi-Task Learnings?
Multi-Task Learning umfasst verschiedene Ansätze, die gemeinsame Informationen zwischen Aufgaben nutzen, um die Leistung von Modellen für maschinelles Lernen zu verbessern. Die Wahl des MTL-Typs hängt von der spezifischen Problemstellung, der Datenverfügbarkeit und den gewünschten Ergebnissen ab. Im Folgenden werden verschiedene Typen unterschieden und ihre Angemessenheit und Kompromisse diskutiert:
- Gemeinsame Nutzung von Hard-Parametern:
- Ansatz: Beim Hard-Parameter-Sharing teilen sich alle Aufgaben denselben Satz von Modellparametern. Im Wesentlichen gibt es ein gemeinsames Modell, das gemeinsam lernt, alle Aufgaben zu erfüllen.
- Anwendbarkeit: Hard-Parameter-Sharing ist geeignet, wenn Aufgaben eng miteinander verbunden sind nd gemeinsame zugrunde liegende Strukturen oder Merkmale aufweisen. Sie funktioniert gut, wenn die Aufgaben ähnliche Datenverteilungen und Ziele haben.
- Vorteile:
- Es fördert einen starken Wissenstransfer zwischen den Aufgaben, was zu einer verbesserten Generalisierung führt.
- Es kann rechnerisch effizient sein, da nur ein einziger Satz von Parametern gelernt und gepflegt werden muss.
- Nachteile:
- Wenn die Aufgaben unähnlich sind, kann die gemeinsame Nutzung harter Parameter die Leistung einiger Aufgaben beeinträchtigen.
- Es kann schwierig sein, ein geeignetes Gleichgewicht zwischen Aufgaben mit unterschiedlichen Daten und unterschiedlicher Komplexität zu finden.
- Gemeinsame Nutzung von Soft-Parametern:
- Ansatz: Die gemeinsame Nutzung von Soft-Parametern ermöglicht ein gewisses Maß an Flexibilität bei der gemeinsamen Nutzung von Modellparametern. Während es eine gemeinsame Komponente für gemeinsame Merkmale gibt, kann jede Aufgabe auch ihre eigenen aufgabenspezifischen Parameter haben.
- Anwendbarkeit: Die gemeinsame Nutzung von Soft-Parametern ist geeignet, wenn die Aufgaben sowohl gemeinsame als auch aufgabenspezifische Merkmale aufweisen. Sie ermöglicht eine individuelle Anpassung und profitiert gleichzeitig vom gemeinsamen Wissen.
- Vorteile:
- Es schafft ein Gleichgewicht zwischen aufgabenspezifischem und gemeinsamem Wissen, wodurch es an verschiedene Aufgaben angepasst werden kann.
- Die gemeinsame Nutzung von Soft-Parametern kann die Unähnlichkeit zwischen Aufgaben ausgleichen.
- Nachteile:
- Es ist komplexer als das Hard-Parameter-Sharing, sowohl in Bezug auf die Implementierung als auch auf die Berechnungen.
- Die Feinabstimmung von Hyperparametern zum Ausgleich von gemeinsamen und aufgabenspezifischen Parametern kann eine Herausforderung darstellen.
- Aufgabenspezifische Architekturen:
- Ansatz: Bei dieser Art von MTL hat jede Aufgabe ihre eigene spezielle Architektur, die sowohl Merkmalsextraktoren als auch Modellparameter umfasst. Es gibt keine gemeinsame Nutzung von Parametern zwischen den Aufgaben.
- Anwendbarkeit: Aufgabenspezifische Architekturen sind geeignet, wenn die Aufgaben sehr unterschiedlich sind und unterschiedliche Datenverteilungen und Ziele haben. Sie ermöglichen eine maximale Anpassung der Aufgabe.
- Vorteile:
- Sie ermöglicht die Ausführung von Aufgaben, die sich grundlegend unterscheiden und sogar nicht miteinander verbunden sind.
- Es besteht kein Risiko einer negativen Übertragung, da die Aufgaben in Bezug auf die Parameter unabhängig sind.
- Nachteile:
- Gemeinsame Informationen werden nicht vollständig genutzt, was zu einer Verschwendung von Ressourcen führen kann.
- Bei Aufgaben mit begrenzten Daten kann es eine Herausforderung sein, aufgabenspezifische Architekturen zu erstellen.
Die Wahl des richtigen MTL-Typs hängt von dem spezifischen Problem ab, das Du angehen willst. In der Praxis ist es üblich, mit der gemeinsamen Nutzung von Hard- oder Soft-Parametern zu beginnen und diese nach Bedarf anzupassen. Bei der Wahl sollten der Grad der Verwandtschaft zwischen den Aufgaben, die Datenverfügbarkeit und die Rechenressourcen berücksichtigt werden. Jede Art von MTL hat ihre Stärken und Schwächen, so dass es für optimale Ergebnisse unerlässlich ist, den Ansatz an das jeweilige Problem anzupassen.
Was sind die mathematischen Grundlagen des Multi-Task Learnings?
Das Multi-Task Learning basiert auf mathematischen Prinzipien, die darauf abzielen, mehrere Aufgaben gleichzeitig zu optimieren und dabei die gemeinsamen Informationen dieser Aufgaben zu nutzen. Die wichtigsten mathematischen Konzepte und Grundlagen des MTL sind
Verlustfunktion:
- Die wichtigste mathematische Grundlage ist die Verlustfunktion. Jede Aufgabe hat ihre eigene Verlustfunktion, die den Fehler oder die Diskrepanz zwischen den Vorhersagen des Modells und der Grundwahrheit für diese Aufgabe quantifiziert.
- Die Gesamtverlustfunktion für MTL ist eine Kombination aus den einzelnen aufgabenspezifischen Verlustfunktionen. Sie kann wie folgt dargestellt werden:
\(\)\[L_{total} = Σ_i L_i \]
- Dabei ist \(L_{total} \) der Gesamtverlust und \(L_i \) der Verlust einer Aufgabe \(i \). Das Ziel von MTL ist es, diesen kombinierten Verlust zu minimieren und somit alle Aufgaben gleichzeitig zu optimieren.
Gemeinsame Nutzung von Parametern:
- Ein entscheidender Aspekt von MTL ist die gemeinsame Nutzung von Modellparametern durch die Aufgaben. Mathematisch gesehen wird diese gemeinsame Nutzung durch Beschränkung oder Regulierung der Parameter erreicht. Dadurch wird das Modell ermutigt, Merkmale zu lernen, die für mehrere Aufgaben relevant sind, was zu gemeinsamem Wissen führt.
- Mathematisch gesehen kann dies als Regularisierungsterm dargestellt werden, der zur Verlustfunktion hinzugefügt wird. Bei der gemeinsamen Nutzung von harten Parametern könnte es sich beispielsweise um einen Strafterm auf die Frobenius-Norm der Gewichtsmatrizen handeln, der sie dazu anregt, ähnlich zu sein.
Regularisierung:
- MTL verwendet häufig Regularisierungstechniken, um das Lernen von aufgabenspezifischen Parametern zu kontrollieren und die gemeinsame Nutzung von Parametern zu fördern.
- Zu den üblichen Regularisierungstermini gehören die L1- und L2-Regularisierung, die als Strafterme für die Modellparameter in die Verlustfunktion integriert werden können.
Optimierungsalgorithmen:
- Die MTL stützt sich auf Optimierungsalgorithmen zur Minimierung der kombinierten Verlustfunktion. Üblicherweise werden der stochastische Gradientenabstieg (SGD) und seine Varianten verwendet.
- Der Optimierungsprozess umfasst die Berechnung von Gradienten der Verlustfunktion in Bezug auf die Modellparameter für jede Aufgabe. Die Gradienten werden dann verwendet, um die Modellparameter iterativ zu aktualisieren.
Matrix-Faktorisierung:
- In einigen Fällen, insbesondere bei kollaborativen Filtersystemen und Empfehlungssystemen, werden Techniken der Matrixfaktorisierung eingesetzt. Mathematisch gesehen wird dabei eine Benutzer-Element-Interaktionsmatrix in zwei niedrigere Matrizen zerlegt, die latente Merkmale darstellen.
Bayesscher Rahmen:
- Bayes’sche Ansätze für MTL beinhalten die Definition von Prioritätsverteilungen über Modellparameter und die Ableitung von Posterior-Verteilungen mit Techniken wie Bayes’scher Inferenz oder Markov Chain Monte Carlo (MCMC).
Das Verständnis dieser mathematischen Grundlagen ist entscheidend für die Entwicklung und Feinabstimmung von MTL-Modellen. Es ermöglicht Forschern und Praktikern, Verlustfunktionen zu entwickeln, geeignete Regularisierungsterme zu wählen und Optimierungsalgorithmen auszuwählen, die auf das jeweilige spezifische Problem abgestimmt sind. Durch die Nutzung dieser mathematischen Prinzipien kann MTL effektiv Wissen zwischen Aufgaben austauschen und die Leistung von Modellen für maschinelles Lernen in einer Reihe von Bereichen verbessern.
Welche Anwendungen gibt es für diesen Lernansatz?
Multi-Task Learning ist eine vielseitige Technik mit einer breiten Palette von Anwendungen in verschiedenen Bereichen, die alle das gemeinsame Ziel haben, die Modellleistung durch die Nutzung von gemeinsamem Wissen zu verbessern. Hier ein Blick auf einige prominente Bereiche, in denen MTL einen bedeutenden Einfluss ausgeübt hat:
In der natürlichen Sprachverarbeitung (NLP) wird sie häufig für Aufgaben wie Sentimentanalyse, Named Entity Recognition (NER), Part-of-Speech-Tagging und Dependency Parsing eingesetzt. Durch das Trainieren von Modellen für die gleichzeitige Ausführung mehrerer verwandter Aufgaben werden NLP-Modelle geschickter im Verstehen von Sprachnuancen und Kontext.
Im Bereich der Computer Vision ist dieser Lernansatz bei Aufgaben wie der Objekterkennung, der Bildsegmentierung und der Gesichtserkennung hilfreich. So kann ein einziges Modell beispielsweise verschiedene Objektklassen identifizieren und so die Genauigkeit der Objekterkennung verbessern.
Das Gesundheitswesen profitiert von MTL, indem es die gleichzeitige Diagnose von Krankheiten, die Vorhersage molekularer Eigenschaften und die Entdeckung von Medikamenten ermöglicht. Dieser Ansatz führt zu genaueren Diagnosen und Arzneimittelinteraktionen, was letztlich die Patientenversorgung verbessert.
Empfehlungssysteme setzen Multitasking ein, um Aufgaben wie die Vorhersage der Interaktion zwischen Benutzer und Artikel, die Erstellung von Empfehlungslisten und die personalisierte Bewertung zu optimieren. Dies führt zu effektiveren und maßgeschneiderten Empfehlungen.
Im Zusammenhang mit autonomen Fahrzeugen spielt MTL eine entscheidende Rolle bei der Verbesserung der Sicherheit und Zuverlässigkeit. Aufgaben wie Fahrspurerkennung, Objekterkennung und Straßenzustandsbewertung werden gemeinsam optimiert und tragen so zu sichereren selbstfahrenden Systemen bei.
Die Spracherkennung profitiert von diesem Lernansatz für die Phonemerkennung, die Sprecheridentifizierung und die Sprachmodellierung. Die gleichzeitige Verbesserung dieser Aufgaben steigert die Genauigkeit von Spracherkennungssystemen.
Bei der Texterzeugung, insbesondere bei Anwendungen wie Chatbots und natürlichem Sprachverständnis, wird MTL eingesetzt, um Aufgaben wie die Erkennung von Entitäten, die Analyse von Gefühlen und die Generierung von Antworten zu optimieren, was zu kontextbezogeneren und genaueren Antworten führt.
In diesen verschiedenen Anwendungen zeichnet sich MTL durch die Nutzung von gemeinsamem Wissen zwischen den Aufgaben aus, was zu einer verbesserten Generalisierung, einer höheren Modelleffizienz und einer besseren Leistung führt. Ihre Anpassungsfähigkeit in verschiedenen Bereichen unterstreicht ihren Wert bei der Bewältigung realer Herausforderungen im Bereich des maschinellen Lernens und der künstlichen Intelligenz, und mit der weiteren Entwicklung der MTL-Forschung werden sich ihre Anwendungsmöglichkeiten wahrscheinlich noch erweitern und neue Möglichkeiten für die gemeinsame Nutzung von Wissen und verbesserte Vorhersagen bieten.
Was sind die Herausforderungen und Überlegungen beim Multi-Task Learning?
Multi-Task Learning bietet zwar zahlreiche Vorteile, aber auch einzigartige Herausforderungen und Überlegungen, die angegangen werden müssen, um sein volles Potenzial auszuschöpfen. Im Folgenden werden einige der wichtigsten Herausforderungen und zu berücksichtigenden Faktoren aufgeführt:
- Aufgabenauswahl und -bezug: Die Auswahl der richtigen Aufgaben für MTL ist entscheidend. Die Aufgaben sollten in irgendeiner Weise miteinander verknüpft sein, um vom gemeinsamen Wissen zu profitieren. Die Auswahl unzusammenhängender Aufgaben kann zu ineffizientem oder ineffektivem MTL führen.
- Datenverfügbarkeit: Unzureichende Daten für einige Aufgaben können eine Herausforderung darstellen. MTL kann im Vergleich zum Lernen mit nur einer Aufgabe mehr Daten erfordern. Es ist wichtig, die Datenanforderungen für die verschiedenen Aufgaben auszugleichen.
- Aufgabeninterferenz: Aufgabeninterferenzen treten auf, wenn sich die Optimierung einer Aufgabe negativ auf die Leistung einer anderen auswirkt. Der Ausgleich zwischen aufgabenspezifischen und gemeinsamen Parametern ist entscheidend, um Interferenzen abzuschwächen.
- Negative Übertragung: Ein negativer Transfer liegt vor, wenn gemeinsam genutztes Wissen die Leistung verschlechtert. Es ist wichtig, auf negativen Transfer zu achten und das MTL-Modell entsprechend anzupassen.
- Rechenkomplexität: Sie kann rechenintensiv sein, insbesondere wenn zahlreiche Aufgaben optimiert werden. Effiziente Modellarchitekturen und Optimierungstechniken sind notwendig, um diese Komplexität zu bewältigen.
- Abstimmung der Hyperparameter: Um das richtige Gleichgewicht zwischen gemeinsamen und aufgabenspezifischen Parametern zu finden, müssen die Hyperparameter sorgfältig abgestimmt werden. Oft ist es ein Versuch-und-Irrtum-Prozess, um die beste Leistung zu erzielen.
- Kompromiss bei der Generalisierung: MTL versucht, die Generalisierung zu verbessern, aber das richtige Gleichgewicht zwischen Overfitting und Underfitting zu finden, kann eine Herausforderung sein. Die richtige Regularisierung und das Management der Modellkomplexität sind entscheidend.
- Modellarchitektur: Der Entwurf einer effektiven Modellarchitektur ist nicht immer einfach. Entscheidungen wie die gemeinsame Nutzung von Hard- und Soft-Parametern oder aufgabenspezifische Architekturen können die Leistung erheblich beeinflussen.
- Etikettenrauschen und Ausreißer: MTL-Modelle sind anfällig für Etikettenrauschen und Ausreißer, die bestimmte Aufgaben unverhältnismäßig stark beeinträchtigen können. Robuste Datenvorverarbeitungs- und Bereinigungstechniken sind erforderlich.
Die Bewältigung dieser Herausforderungen und Überlegungen ist für die erfolgreiche Implementierung von Multi-Task-Learning unerlässlich. Es erfordert eine Kombination aus Fachwissen, robusten Experimenten und einem durchdachten Modelldesign. Wenn es effektiv durchgeführt wird, kann MTL die Leistung und Effizienz in einem breiten Spektrum von Anwendungen erheblich verbessern.
Was ist der aktuelle Stand der Technik?
Multi-Task Learning ist ein sich schnell entwickelnder Bereich mit verschiedenen fortschrittlichen Techniken, die die Grenzen dessen, was beim gemeinsamen Wissenstransfer zwischen Aufgaben möglich ist, immer weiter hinausschieben. Im Folgenden werden einige hochmoderne Techniken und Methoden vorgestellt, die in der MTL-Forschung eine Vorreiterrolle spielen:
- Transfer Learning mit vortrainierten Modellen: Vorgefertigte Modelle, insbesondere im Zusammenhang mit Deep Learning, sind zu einem Eckpfeiler von MTL geworden. Modelle wie BERT, GPT-3 und ResNet, die auf großen Datensätzen trainiert wurden, dienen als hervorragende Merkmalsextraktoren für MTL-Aufgaben. Die Feinabstimmung dieser Modelle für spezifische Aufgaben ist ein weit verbreiteter und effektiver Ansatz.
- Meta-Lernen: Meta-Learning-Techniken zielen darauf ab, dass Modelle lernen, wie man lernt. Meta-Learning-Algorithmen wie Model-Agnostic Meta-Learning (MAML) und Reptile ermöglichen es den Modellen, sich mit minimalen Daten schnell an neue Aufgaben anzupassen. Dies ist besonders nützlich in Umgebungen, in denen sich die Aufgabenverteilung im Laufe der Zeit ändern kann.
- Neuronale Architektur-Suche (NAS): NAS erforscht den automatischen Entwurf neuronaler Netzwerkarchitekturen. Im Kontext von MTL kann NAS aufgabenspezifische Architekturen oder gemeinsame Komponenten entdecken und das Modell für mehrere Aufgaben optimieren.
- Gradientenregulierungstechniken: Techniken wie Gradientenregulierung und Gradientenanpassung werden eingesetzt, um Aufgabeninterferenzen zu verhindern und negative Übertragungen abzuschwächen. Diese Ansätze helfen bei der Feinabstimmung des Gleichgewichts zwischen gemeinsamen und aufgabenspezifischen Parametern.
- Dynamisches Task Routing: Dynamische Task-Routing-Methoden weisen den Aufgaben adaptiv Ressourcen und Parameter zu. Mit diesen Algorithmen können MTL-Modelle entscheiden, wie die Ressourcen je nach Wichtigkeit der Aufgaben aufgeteilt und zugewiesen werden.
- Lernen nach Lehrplan: Bei Lehrplan-Lernstrategien wird das Modell schrittweise mit immer komplexeren Aufgaben konfrontiert. Dies ermöglicht einen reibungsloseren Wissenstransfer von einfacheren zu komplexeren Aufgaben und verringert das Risiko eines negativen Transfers.
- Aufmerksamkeitsmechanismen: Aufmerksamkeitsmechanismen, wie z. B. die Transformer-Architektur, spielen beim MTL eine entscheidende Rolle, da sie es den Modellen ermöglichen, sich auf die für die jeweilige Aufgabe relevanten Informationen zu konzentrieren. Die feinkörnige Aufmerksamkeit erleichtert den Modellen die Verwaltung von gemeinsamem Wissen.
Diese hochmodernen Techniken stellen die Spitze der Multi-Task Learning Forschung dar und befassen sich mit den Herausforderungen und Komplexitäten der Optimierung von Modellen für mehrere Aufgaben. Durch die Kombination dieser fortschrittlichen Methoden mit domänenspezifischem Wissen erweitern Forscher und Praktiker die Grenzen dessen, was MTL erreichen kann, und machen es zu einem vielversprechenden Forschungsgebiet im Bereich des maschinellen Lernens und der künstlichen Intelligenz.
Wie kann man Multi-Task Learning in Python implementieren?
Multi-Task Learning kann man mit Python und TensorFlow implementieren. Das folgende Beispiel beinhaltet zwei verwandte Aufgaben: Stimmungsanalyse und Emotionserkennung. Wir werden ein gemeinsames neuronales Netzwerk erstellen, das gleichzeitig lernt, beide Aufgaben zu erfüllen.
- Datenvorbereitung: Beginne mit der Vorbereitung Deiner Datensätze. Du solltest sowohl für die Stimmungsanalyse als auch für die Erkennung von Emotionen beschriftete Daten haben. Stelle sicher, dass die Daten vorverarbeitet sind, und teile sie in Trainings- und Testdatensätze auf.
- Wähle ein Deep Learning Framework: Wir verwenden für dieses Beispiel TensorFlow, ein beliebtes Deep Learning Framework. Du kannst es mit
pip install tensorflowinstallieren. - Definiere eine gemeinsam genutzte Netzwerkarchitektur: Erstelle ein gemeinsames neuronales Netzwerk, das die eingegebenen Textdaten verarbeitet und gemeinsame Repräsentationen lernt. Für unser Beispiel verwenden wir ein einfaches neuronales Netzwerk mit einer Einbettungsschicht, LSTM-Schichten und einer gemeinsamen dichten Schicht.
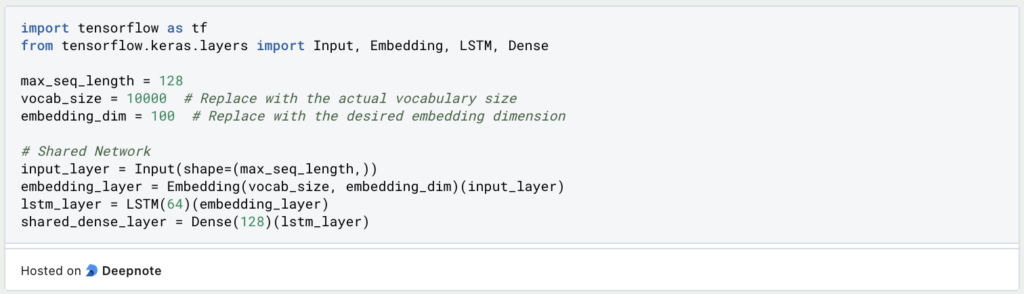
4. Definiere aufgabenspezifische Kopfnetzwerke: Erstelle aufgabenspezifische Kopfnetzwerke sowohl für die Stimmungsanalyse als auch für die Emotionserkennung. Diese Kopfnetzwerke erzeugen Vorhersagen, die für jede Aufgabe spezifisch sind.

5. Verlustfunktionen: Definiere aufgabenspezifische Verlustfunktionen für jede Aufgabe. Wir werden die binäre Kreuzentropie für die Stimmungsanalyse und die kategoriale Kreuzentropie für die Emotionserkennung verwenden.

6. Training: Trainiere das MTL-Modell mit Daten aus beiden Aufgaben. Du kannst den kombinierten Verlust aus Sentimentanalyse und Emotionserkennung verwenden, um die Parameter des Modells zu aktualisieren.

- Bewertung: Bewerte die Leistung des MTL-Modells auf separaten Validierungs- und Testdatensätzen für die Aufgaben der Stimmungsanalyse und der Emotionserkennung. Verwende relevante Bewertungsmetriken, wie z. B. die Genauigkeit für die Stimmungsanalyse und den F1-Score für die Emotionserkennung.
- Inferenz: Mit dem trainierten MTL-Modell kannst Du nun Vorhersagen auf neuen Textdaten für beide Aufgaben treffen und gleichzeitig Ergebnisse der Stimmungsanalyse und der Emotionserkennung liefern.
- Transfer-Lernen und Feinabstimmung: Wenn Du über vortrainierte Schichten (z. B. Worteinbettungen) oder Modelle (z. B. BERT) verfügst, die für verschiedene Aufgaben verwendet werden, kannst Du diese für Deine spezifischen Aufgaben feinabstimmen. Auf diese Weise wird vorhandenes Wissen genutzt und Trainingszeit gespart.
- Überwachung und Anpassung: Überwache kontinuierlich die Leistung des Modells und passe die MTL-Architektur an, wenn neue Daten oder Aufgaben verfügbar werden. Inkrementelles Lernen und Umschulung sind oft notwendig, um eine optimale Leistung zu erhalten.
In diesem Beispiel haben wir MTL für Sentiment-Analyse und Emotionserkennung mit Python und TensorFlow implementiert. Du kannst diese Vorlage an komplexere Modelle und Aufgaben anpassen und verschiedene Netzwerkarchitekturen und Hyperparameter erforschen, um das MTL-Modell für Ihre spezifische Anwendung fein abzustimmen.
Das solltest Du mitnehmen
- MTL bietet einen leistungsstarken Ansatz zur Verbesserung der Modellleistung, indem es das gleichzeitige Lernen an mehreren verwandten Aufgaben ermöglicht.
- Der gemeinsame Wissenstransfer in MTL reduziert den Bedarf an separaten Modellen und ermöglicht eine effiziente Nutzung der Daten.
- MTL ist in verschiedenen Bereichen anwendbar, darunter NLP, Computer Vision, Gesundheitswesen, Empfehlungssysteme, autonome Fahrzeuge und mehr.
- Zu den Herausforderungen bei MTL gehören Aufgabenauswahl, Datenverfügbarkeit, Aufgabeninterferenzen und negativer Transfer, die sorgfältig berücksichtigt werden müssen.
- Modernste Techniken, wie Transfer-Lernen mit vortrainierten Modellen und Meta-Lernen, bringen das Feld der MTL weiter voran.
- Die Implementierung von MTL in Python unter Verwendung von Deep-Learning-Frameworks umfasst die Datenvorbereitung, die Definition gemeinsamer Netzwerke, aufgabenspezifische Kopfnetzwerke, Verlustfunktionen, Training, Bewertung und Anpassung.
- MTL ist ein dynamisches Feld mit dem Potenzial, komplexe reale Herausforderungen zu bewältigen und Innovationen im Bereich des maschinellen Lernens und der künstlichen Intelligenz voranzutreiben.

Was ist Manifold Learning?
Entdecken Sie die Welt des Manifold Learning - Ein tiefer Einblick in die Grundlagen, Anwendungen und die Programmierung.

Was ist die Grid Search?
Optimieren Sie Ihre Modelle für maschinelles Lernen mit Grid Search. Erforschen Sie die Abstimmung von Hyperparametern mit Python.

Was ist die Lernrate?
Entfalten Sie die Kraft der Lernraten beim maschinellen Lernen: Tauchen Sie ein in Strategien, Optimierung und Feinabstimmung für Modelle.

Was ist die Random Search?
Optimieren Sie Modelle für maschinelles Lernen: Lernen Sie, wie die Random Search Hyperparameter effektiv abstimmt.

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.

Was ist der Omitted Variable Bias?
Verständnis des Omitted Variable Bias: Ursachen, Konsequenzen und Prävention. Erfahren Sie, wie Sie diese Falle vermeiden.
Andere Beiträge zum Thema Multi-Task Learning
Hier findest Du eine Dokumentation, wie Du einen Multi-Task Recommender in TensorFlow trainieren kannst.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.