In the world of machine learning, there’s a powerful technique that allows models to tackle multiple tasks simultaneously, benefiting from shared knowledge. This technique is known as Multi-Task Learning (MTL). Instead of training a separate model for each task, MTL leverages the connections between related tasks to enhance the performance and efficiency of machine learning algorithms. Whether it’s computer vision, natural language processing, healthcare, or recommendation systems, MTL has proven to be a game-changer in a wide range of applications.
What is Multi-Task Learning?
Multi-task learning is a machine learning technique that aims to improve the performance of a model by training it to perform multiple related tasks simultaneously. A single model is designed to address not just one primary task but several tasks that are connected in some way. This approach leverages the shared information and patterns between tasks to enhance the model’s performance, generalization, and efficiency.
MTL holds significant importance in the field of machine learning for several reasons:
- Efficient Knowledge Transfer: MTL allows the model to transfer knowledge from one task to another. It benefits from the shared patterns and information, reducing the need for learning from scratch for each task.
- Improved Generalization: By learning multiple tasks together, the model can generalize better and make predictions that are more accurate, especially when data is limited for individual tasks.
- Regularization Effect: MTL acts as a form of regularization. By jointly optimizing multiple tasks, it helps prevent overfitting and leads to more robust models.
- Reduced Data Requirements: Instead of needing a vast amount of data for each task separately, MTL can work effectively with smaller datasets for each task, making it practical in situations where data is scarce.
It differs from traditional single-task learning in the following ways:
- Task Independence: In single-task learning, each model is trained independently for a specific task. In MTL, multiple tasks are learned together, and their interdependencies are considered.
- Shared Parameters: It typically involves shared parameters and features across tasks. Single-task learning does not exploit shared information to the same extent.
- Enhanced Performance: It often results in enhanced performance for all tasks involved, as compared to single-task learning where the performance may be optimized for one task at the expense of others.
The key advantages are as follows:
- Improved Accuracy: MTL can lead to more accurate predictions by leveraging the knowledge shared between tasks.
- Data Efficiency: It can work with smaller datasets, making it ideal for scenarios with limited data availability.
- Time Efficiency: MTL reduces the need to train separate models for each task, saving time and computational resources.
- Better Generalization: Jointly optimizing multiple tasks often results in better generalization, especially in complex and interrelated tasks.
- Regularization: MTL acts as a form of regularization, reducing the risk of overfitting on individual tasks.
Multi-task learning is a versatile technique used in various domains, including natural language processing, computer vision, and healthcare, to name a few. By harnessing the power of shared knowledge, it offers a compelling approach to tackling complex machine learning problems efficiently.
What are the different types of Multi-Task Learning?
Multi-task learning encompasses various approaches that leverage shared information between tasks to improve the performance of machine learning models. The choice of MTL type depends on the specific problem, data availability, and desired outcomes. Here, we differentiate between different types and discuss their appropriateness and trade-offs:
1. Hard-Parameter Sharing:
- Approach: In hard-parameter sharing, all tasks share the same set of model parameters. Essentially, there is one shared model that jointly learns to perform all tasks.
- Applicability: Hard-parameter sharing is suitable when tasks are closely related and share common underlying structures or features. It works well when the tasks have similar data distributions and objectives.
- Advantages:
- It promotes strong transfer of knowledge between tasks, leading to enhanced generalization.
- It can be computationally efficient, as it requires learning and maintaining a single set of parameters.
- Disadvantages:
- If tasks are dissimilar, hard-parameter sharing may hinder the performance of some tasks.
- It can be challenging to find a suitable balance between tasks with varying data and complexity.
2. Soft-Parameter Sharing:
- Approach: Soft-parameter sharing allows for a degree of flexibility in sharing model parameters. While there is a shared component for common features, each task can also have its own task-specific parameters.
- Applicability: Soft-parameter sharing is appropriate when tasks exhibit both shared and task-specific characteristics. It allows for customization while benefiting from common knowledge.
- Advantages:
- It strikes a balance between task-specificity and shared knowledge, making it adaptable to diverse tasks.
- Soft-parameter sharing can accommodate dissimilarity between tasks.
- Disadvantages:
- It is more complex than hard-parameter sharing, both in terms of implementation and computation.
- Fine-tuning hyperparameters for balancing shared and task-specific parameters can be challenging.
3. Task-Specific Architectures:
- Approach: In this type of MTL, each task has its own dedicated architecture, including both feature extractors and model parameters. There is no sharing of parameters between tasks.
- Applicability: Task-specific architectures are suitable when tasks are highly dissimilar and have distinct data distributions and objectives. It allows for maximum task customization.
- Advantages:
- It accommodates tasks that are fundamentally different, even unrelated.
- There is no risk of negative transfer, as tasks are independent in terms of parameters.
- Disadvantages:
- It does not fully exploit shared information, potentially leading to wasted resources.
- For tasks with limited data, it can be challenging to build task-specific architectures.
Choosing the right type of MTL depends on the specific problem you are addressing. In practice, it is common to start with hard-parameter sharing or soft-parameter sharing and adapt as needed. The choice should consider the degree of relatedness between tasks, data availability, and computational resources. Each type of MTL has its strengths and weaknesses, making it essential to tailor the approach to the problem at hand for optimal results.
What are the mathematical foundations of Multi-Task Learning?
Multi-task learning is founded on mathematical principles that aim to optimize multiple tasks simultaneously while leveraging shared information across these tasks. The key mathematical concepts and foundations of MTL are essential for understanding its operation and effectiveness. Here, we delve into the mathematical underpinnings:
Loss Function:
- The primary mathematical foundation is the loss function. Each task has its own loss function, which quantifies the error or discrepancy between the model’s predictions and the ground truth for that task.
- The overall loss function for MTL is a combination of the individual task-specific loss functions. It can be represented as:
\(\)\[L_{total} = Σ_i L_i \]
- Where \(L_{total} \) is the total loss, and \(L_i \) represents the loss of a task \(i \). The objective in MTL is to minimize this combined loss, effectively optimizing all tasks simultaneously.
Parameter Sharing:
- A critical aspect of MTL is the sharing of model parameters between tasks. Mathematically, this sharing is achieved by constraining or regularizing the parameters. This encourages the model to learn features that are relevant to multiple tasks, leading to shared knowledge.
- Mathematically, this can be represented as a regularization term added to the loss function. For example, in hard-parameter sharing, it could be a penalty term on the Frobenius norm of the weight matrices, encouraging them to be similar.
Regularization:
- MTL often employs regularization techniques to control the learning of task-specific parameters and to promote parameter sharing.
- Common regularization terms include L1 and L2 regularization, which can be incorporated into the loss function as penalty terms on the model parameters.
Optimization Algorithms:
- MTL relies on optimization algorithms to minimize the combined loss function. Stochastic gradient descent (SGD) and its variants are commonly used.
- The optimization process involves computing gradients of the loss function with respect to the model parameters for each task. The gradients are then used to update the model parameters iteratively.
Matrix Factorization:
- In some settings, particularly in collaborative filtering and recommendation systems, matrix factorization techniques are employed. Mathematically, this involves decomposing a user-item interaction matrix into two lower-dimensional matrices representing latent features.
Bayesian Framework:
- Bayesian approaches to MTL involve defining prior distributions over model parameters and inferring posterior distributions using techniques such as Bayesian inference or Markov Chain Monte Carlo (MCMC).
Understanding these mathematical foundations is crucial for developing and fine-tuning MTL models. It allows researchers and practitioners to craft loss functions, choose appropriate regularization terms, and select optimization algorithms that align with the specific problem at hand. By leveraging these mathematical principles, MTL can effectively share knowledge between tasks and enhance the performance of machine learning models across a range of domains.
What are the applications of this learning approach?
Multi-Task Learning is a versatile technique with a wide range of applications across various domains, all sharing the common goal of enhancing model performance by leveraging shared knowledge. Here’s a look at some of the prominent areas where MTL has made a significant impact:
In Natural Language Processing (NLP), it is widely used for tasks like sentiment analysis, Named Entity Recognition (NER), part-of-speech tagging, and dependency parsing. By training models to perform multiple related tasks simultaneously, NLP models become more adept at understanding language nuances and context.
In the realm of Computer Vision, this learning approach is instrumental in tasks such as object detection, image segmentation, and facial recognition. For example, a single model can identify various object classes, improving object detection accuracy.
Healthcare benefits from MTL by enabling simultaneous disease diagnosis, molecular property prediction, and drug discovery. This approach leads to more accurate diagnoses and drug interactions, ultimately improving patient care.
Recommender Systems employ multi-task to optimize tasks like user-item interaction prediction, recommendation list generation, and personalized ranking. This results in more effective and tailored recommendations.
In the context of Autonomous Vehicles, MTL plays a crucial role in enhancing safety and reliability. Tasks like lane detection, object detection, and road condition assessment are optimized collectively, contributing to safer self-driving systems.
Speech Recognition benefits from this learning approach for phoneme recognition, speaker identification, and language modeling. Simultaneously improving these tasks enhances the accuracy of speech recognition systems.
In Text Generation, particularly for applications like chatbots and natural language understanding, MTL is employed to optimize tasks such as entity recognition, sentiment analysis, and response generation, leading to more contextually relevant and accurate responses.
Across these diverse applications, MTL excels at leveraging shared knowledge between tasks, resulting in enhanced generalization, improved model efficiency, and superior performance. Its adaptability across various domains underscores its value in addressing real-world challenges in machine learning and artificial intelligence, and as research in MTL continues to evolve, its potential applications are likely to expand further, offering new opportunities for knowledge sharing and improved predictions.
What are the Challenges and Considerations of Multi-Task Learning?
While Multi-Task Learning offers numerous advantages, it also presents unique challenges and considerations that need to be addressed to harness its full potential. Here are some key challenges and factors to take into account:
- Task Selection and Relatedness: Choosing the right tasks for MTL is critical. Tasks should be related in some way to benefit from shared knowledge. Selecting unrelated tasks can lead to inefficient or ineffective MTL.
- Data Availability: Insufficient data for some tasks can pose a challenge. MTL may require more data compared to single-task learning. Balancing the data requirements across tasks is essential.
- Task Interference: Task interference occurs when the optimization of one task negatively impacts the performance of another. Balancing task-specific and shared parameters is crucial to mitigate interference.
- Negative Transfer: Negative transfer happens when shared knowledge degrades performance. It’s essential to monitor for negative transfer and adapt the MTL model accordingly.
- Computational Complexity: It can be computationally demanding, especially when optimizing numerous tasks. Efficient model architectures and optimization techniques are necessary to manage this complexity.
- Hyperparameter Tuning: Finding the right balance between shared and task-specific parameters requires careful hyperparameter tuning. It’s often a trial-and-error process to achieve the best performance.
- Generalization Trade-Off: MTL seeks to improve generalization, but striking the right balance between overfitting and underfitting can be challenging. Proper regularization and model complexity management are crucial.
- Model Architecture: Designing an effective model architecture is not always straightforward. Choices like hard-parameter sharing, soft-parameter sharing, or task-specific architectures can greatly impact performance.
- Label Noise and Outliers: MTL models are susceptible to label noise and outliers, which can disproportionately affect certain tasks. Robust data preprocessing and cleaning techniques are necessary.
Navigating these challenges and considerations is integral to the successful implementation of Multi-Task Learning. It requires a combination of domain expertise, robust experimentation, and thoughtful model design. When done effectively, MTL can significantly improve performance and efficiency across a wide range of applications.
What are the State-of-the-Art Techniques?
Multi-Task Learning is a rapidly evolving field with various advanced techniques that are pushing the boundaries of what is possible in shared knowledge transfer between tasks. Here are some state-of-the-art techniques and methodologies that are at the forefront of MTL research:
1. Transfer Learning with Pre-trained Models: Pre-trained models, particularly in the context of deep learning, have become a cornerstone of MTL. Models like BERT, GPT-3, and ResNet, trained on large-scale datasets, serve as excellent feature extractors for MTL tasks. Fine-tuning these models for specific tasks is a prevalent and effective approach.
2. Meta-Learning: Meta-learning techniques aim to enable models to learn how to learn. Meta-learning algorithms, such as Model-Agnostic Meta-Learning (MAML) and Reptile, allow models to adapt quickly to new tasks with minimal data. This is particularly useful in settings where task distribution may change over time.
3. Neural Architecture Search (NAS): NAS explores the automated design of neural network architectures. In the context of MTL, NAS can discover task-specific architectures or shared components, optimizing the model for multiple tasks.
4. Gradient Regularization Techniques: Techniques like gradient regularization and gradient alignment are used to prevent task interference and mitigate negative transfer. These approaches help fine-tune the balance between shared and task-specific parameters.
5. Dynamic Task Routing: Dynamic task routing methods adaptively allocate resources and parameters to tasks. These algorithms allow MTL models to decide how to share and allocate resources based on the importance of tasks.
6. Curriculum Learning: Curriculum learning strategies gradually expose the model to tasks of increasing complexity. This enables a smoother transfer of knowledge from simpler to more complex tasks, reducing the risk of negative transfer.
7. Attention Mechanisms: Attention mechanisms, such as the Transformer architecture, play a crucial role in MTL by allowing models to focus on relevant information for each task. The fine-grained attention makes it easier for models to manage shared knowledge.
These state-of-the-art techniques represent the cutting edge of Multi-Task Learning research, addressing the challenges and complexities of optimizing models for multiple tasks. By combining these advanced methodologies with domain-specific knowledge, researchers and practitioners continue to push the boundaries of what MTL can achieve, making it a highly promising area of study in machine learning and artificial intelligence.
How can you implement Multi-Task Learning in Python?
Let’s walk through how to implement Multi-Task Learning using Python and TensorFlow, with a concrete example involving two related tasks: sentiment analysis and emotion detection. We’ll create a shared neural network that simultaneously learns to perform both tasks.
1. Data Preparation: Start by preparing your datasets. You should have labeled data for both sentiment analysis and emotion detection. Ensure the data is preprocessed, and split it into training and testing sets.
2. Select a Deep Learning Framework: We’ll use TensorFlow, a popular deep learning framework, for this example. You can install it using pip install tensorflow.
3. Define a Shared Network Architecture: Create a shared neural network that will process input text data and learn shared representations. For our example, let’s use a simple neural network with an Embedding layer, LSTM layers, and a shared dense layer.
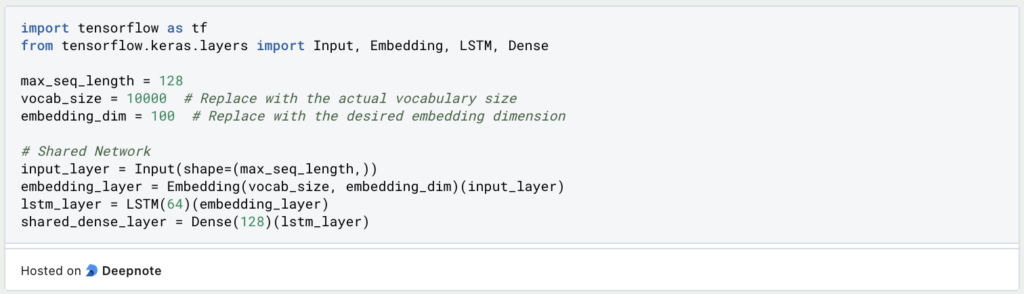
4. Define Task-Specific Head Networks: Create task-specific head networks for both sentiment analysis and emotion detection. These head networks will produce predictions specific to each task.

5. Loss Functions: Define task-specific loss functions for each task. We’ll use binary cross-entropy for sentiment analysis and categorical cross-entropy for emotion detection.

6. Training: Train the MTL model using data from both tasks. You can use the combined loss from sentiment analysis and emotion detection to update the model’s parameters.

7. Evaluation: Evaluate the MTL model’s performance on separate validation and test datasets for both sentiment analysis and emotion detection tasks. Use relevant evaluation metrics, such as accuracy for sentiment and F1 score for emotion detection.
8. Inference: With the trained MTL model, you can now make predictions on new text data for both tasks, simultaneously providing sentiment analysis and emotion detection results.
9. Transfer Learning and Fine-Tuning: If you have pre-trained layers (e.g., word embeddings) or models (e.g., BERT) that are shared across tasks, you can fine-tune them for your specific tasks. This leverages existing knowledge and saves training time.
10. Monitoring and Adaptation: Continuously monitor the model’s performance and adapt the MTL architecture as new data or tasks become available. Incremental learning and retraining are often necessary to maintain optimal performance.
In this example, we’ve implemented MTL for sentiment analysis and emotion detection using Python and TensorFlow. You can adapt this template to more complex models and tasks, exploring various network architectures and hyperparameters to fine-tune the MTL model for your specific application.
This is what you should take with you
- MTL offers a powerful approach to enhancing model performance by allowing simultaneous learning on multiple related tasks.
- The shared knowledge transfer in MTL reduces the need for separate models and leverages data efficiently.
- MTL is applicable in diverse domains, including NLP, computer vision, healthcare, recommendation systems, autonomous vehicles, and more.
- Challenges in MTL include task selection, data availability, task interference, and negative transfer, which require careful consideration.
- State-of-the-art techniques, like transfer learning with pre-trained models and meta-learning, continue to advance the field of MTL.
- Implementing MTL in Python, using deep learning frameworks, involves data preparation, shared network definition, task-specific head networks, loss functions, training, evaluation, and adaptation.
- MTL is a dynamic field with the potential to address complex real-world challenges and drive innovation in machine learning and artificial intelligence.

What is the Adam Optimizer?
Unlock the Potential of Adam Optimizer: Get to know the basucs, the algorithm and how to implement it in Python.

What is One-Shot Learning?
Mastering one shot learning: Techniques for rapid knowledge acquisition and adaptation. Boost AI performance with minimal training data.

What is the Bellman Equation?
Mastering the Bellman Equation: Optimal Decision-Making in AI. Learn its applications & limitations. Dive into dynamic programming!

What is the Singular Value Decomposition?
Unlocking insights and patterns: Learn the power of Singular Value Decomposition (SVD) in data analysis. Discover its applications.

What is the Poisson Regression?
Learn about Poisson regression, a statistical model for count data analysis. Implement Poisson regression in Python for accurate predictions.

What is blockchain-based AI?
Discover the potential of Blockchain-Based AI in this insightful article on Artificial Intelligence and Distributed Ledger Technology.
Other Articles on the Topic of Multi-Task Learning
Here you can find a documentation on how to train a Multi-Task Recommender in TensorFlow.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.