In der sich ständig erweiternden Landschaft der datengesteuerten Technologien ist die Nachfrage nach qualitativ hochwertigen, vielfältigen Datensätzen von größter Bedeutung geworden. Daten aus der realen Welt sind jedoch oft mit Einschränkungen verbunden, z. B. Bedenken hinsichtlich des Datenschutzes, eingeschränktem Zugang oder einfach unzureichender Menge. Hier kommt die synthetische Datengenerierung ins Spiel, die eine innovative Lösung zur Überbrückung dieser Lücken bietet.
Synthetische Daten, die künstlich erzeugt werden, um die Eigenschaften realer Datensätze zu imitieren, haben sich in verschiedenen Branchen zu einem echten Wendepunkt entwickelt. Vom Gesundheitswesen und Finanzwesen bis hin zu autonomen Fahrzeugen und maschinellem Lernen eröffnet die Möglichkeit, Daten zu generieren, die echten Informationen sehr ähnlich sind, neue Wege für Innovation und Entwicklung.
Dieser Artikel taucht in die dynamische Welt der synthetischen Datengenerierung ein und untersucht ihre Vorteile, Methoden und Anwendungen in verschiedenen Sektoren. Wir entschlüsseln die Techniken, die hinter der Erstellung synthetischer Datensätze stehen, untersuchen ihre praktischen Auswirkungen und stellen uns den Herausforderungen, die mit diesem bahnbrechenden Ansatz verbunden sind. Begleite uns auf eine Reise in die Zukunft der Datenwissenschaft, in der synthetische Daten den Weg zu mehr Datenschutz, verbessertem Modelltraining und beschleunigten Fortschritten in der künstlichen Intelligenz ebnen.
Was sind synthetische Daten?
Synthetische Daten sind künstlich erzeugte Datensätze, die die statistischen Eigenschaften und Muster von realen Daten nachbilden sollen. Im Gegensatz zu tatsächlichen Daten, die aus Beobachtungen oder Experimenten stammen, werden synthetische Daten mithilfe von Algorithmen und Modellen erstellt. Diese Nachahmung zielt darauf ab, die Komplexität und Vielfalt authentischer Datensätze zu erfassen und dient als leistungsfähiges Instrument in Szenarien, in denen sich die Beschaffung oder Nutzung echter Daten als schwierig erweist.
Bei diesem Prozess werden Datenpunkte erzeugt, die ähnliche Merkmale wie der ursprüngliche Datensatz aufweisen, aber keine tatsächlichen Beobachtungen darstellen. Verschiedene Techniken, darunter Generative Adversarial Networks (GANs), regelbasierte Methoden und statistische Modelle, werden eingesetzt, um synthetische Daten zu erzeugen, die die Merkmale des echten Gegenstücks widerspiegeln.
Synthetische Daten finden in verschiedenen Bereichen Anwendung, darunter auch im Bereich des maschinellen Lernens, wo sie beim Trainieren und Validieren von Modellen helfen, ohne sensible Informationen zu gefährden. Ihre Rolle erstreckt sich auch auf den Schutz der Privatsphäre, die Überwindung von Datenknappheit und die Erleichterung von Innovationen in Szenarien, in denen der Zugang zu echten Daten eingeschränkt ist.
Im Wesentlichen fungieren synthetische Daten als virtuelles Gegenstück und bieten Forschern, Entwicklern und Datenwissenschaftlern eine wertvolle Ressource zur Bewältigung von Herausforderungen im Zusammenhang mit der begrenzten Verfügbarkeit von Daten, der Wahrung der Privatsphäre und der algorithmischen Erforschung.
Welche Vorteile haben synthetische Daten?
Synthetische Daten erweisen sich als transformative Verbündete im Bereich der Datenwissenschaft und bieten eine Fülle von Vorteilen, mit denen kritische Herausforderungen in verschiedenen Branchen angegangen werden können. In Situationen, in denen authentische Daten nur begrenzt oder schwer zu beschaffen sind, können synthetische Daten die Lücke füllen. Dies erweist sich als besonders wertvoll in den frühen Phasen der Modellentwicklung oder in Nischenbereichen, in denen reale Daten Mangelware sind.
Einer der Hauptvorteile liegt in der Wahrung der Privatsphäre, denn sie ermöglicht die Erstellung von Datensätzen, die die Privatsphäre schützen, was in Bereichen wie dem Gesundheitswesen und dem Finanzwesen, wo der Schutz sensibler Informationen von größter Bedeutung ist, von entscheidender Bedeutung ist. Forscher und Analysten können realistische Szenarien simulieren, ohne die Privatsphäre des Einzelnen zu gefährden. Synthetische Datensätze bieten auch eine kontrollierte Umgebung für strenge Tests und die Entwicklung von Algorithmen für maschinelles Lernen. Forscher können Variablen manipulieren, spezifische Szenarien einführen und die Reaktionen der Algorithmen bewerten, wodurch der Innovationszyklus beschleunigt wird.
Darüber hinaus ermöglichen synthetische Daten die Anpassung von Datensätzen an spezifische Anforderungen. Dazu gehört die Generierung von Daten mit unterschiedlichen Merkmalen, Verteilungsverschiebungen oder spezifischen Anomalien, so dass die Forscher die Belastbarkeit von Algorithmen in verschiedenen Szenarien testen können. In Situationen, in denen die Erhebung großer Mengen echter Daten ressourcenintensiv ist, bieten synthetische Daten eine effizientere Alternative. Sie verringern den Bedarf an umfangreichen Datenerhebungen und die damit verbundenen Kosten und liefern dennoch wertvolle Erkenntnisse.
Synthetische Daten sind von unschätzbarem Wert in Bereichen wie autonomen Fahrzeugen, wo ein breites Spektrum von Fahrbedingungen für das Training robuster Modelle entscheidend ist. Darüber hinaus werden ethische Bedenken im Zusammenhang mit der Verwendung realer Daten ausgeräumt, insbesondere wenn es um sensible oder geschützte Informationen geht. Dies gewährleistet ein verantwortungsvolles und ethisches Experimentieren in verschiedenen Bereichen. Die Vorteile synthetischer Daten gehen weit über die konventionellen Datenbeschränkungen hinaus und ebnen den Weg für Innovation, datenschutzbewusste Forschung und beschleunigte Fortschritte in der Data-Science-Landschaft.
Welche Methoden werden für die synthetische Datengenerierung genutzt?
Die Kunst der synthetischen Datengenerierung besteht in der Anwendung hochentwickelter Methoden, um die Feinheiten realer Datensätze nachzubilden. An der Spitze dieser Techniken stehen Generative Adversarial Networks (GANs), ein hochmoderner Ansatz, bei dem ein Generator und ein Diskriminator in ein dynamisches Wechselspiel treten. Der Generator erzeugt synthetische Daten mit dem Ziel, den Diskriminator zu täuschen, der seinerseits zwischen echten und synthetischen Proben unterscheiden kann. Durch diesen kontradiktorischen Prozess werden die synthetischen Daten verfeinert und ihre Ähnlichkeit mit authentischen Datensätzen kontinuierlich verbessert.
Eine Ergänzung zu GANs sind Variational Autoencoders (VAEs), die probabilistische Modelle verwenden, um die zugrunde liegende Struktur der Eingabedaten zu erfassen. VAEs konzentrieren sich auf die Kodierung und Dekodierung von Informationen und erzeugen synthetische Datenpunkte durch Stichproben aus der kodierten Verteilung. Diese Methode führt Variabilität ein, die für die Simulation der in realen Datensätzen beobachteten Vielfalt entscheidend ist.
Regelbasierte Ansätze stellen eine weitere Facette der Generierung synthetischer Daten dar. Durch die Einbeziehung vordefinierter Regeln und Beschränkungen emulieren diese Methoden bestimmte Muster oder Merkmale, die in authentischen Datensätzen vorhanden sind. Obwohl sie weniger flexibel sind als auf maschinellem Lernen basierende Methoden, bieten regelbasierte Ansätze Präzision bei der Kontrolle der Eigenschaften der generierten Daten.
Statistische Modelle, die Techniken wie Bootstrapping und Monte-Carlo-Simulationen umfassen, tragen zur Landschaft der synthetischen Daten bei. Diese Methoden nutzen statistische Eigenschaften, die aus bestehenden Datensätzen abgeleitet werden, um neue Stichproben zu erzeugen. Bootstrapping beinhaltet eine erneute Stichprobenziehung mit Ersetzung, um die Variabilität der ursprünglichen Daten zu erfassen, während Monte-Carlo-Simulationen Zufallsprozesse simulieren und eine statistische Grundlage für synthetische Daten bieten.
Diese verschiedenen Methoden sind auf die unterschiedlichen Anforderungen und Herausforderungen bei der Datengenerierung abgestimmt. GANs und VAEs zeichnen sich durch die Erfassung komplexer Muster und Verteilungen aus, während regelbasierte und statistische Ansätze explizite Kontrolle und Anpassung bieten. Die Synergie dieser Methoden treibt den dynamischen Bereich der synthetischen Datenerzeugung voran und ermöglicht es Forschern und Datenwissenschaftlern, Datensätze zu erstellen, die den Reichtum und die Komplexität der realen Welt widerspiegeln.
Was sind die Anwendungen der synthetischen Datengenerierung in verschiedenen Branchen?
Die Anwendungen der synthetischen Datengenerierung sind in verschiedenen Branchen zu finden, die konventionelle Ansätze umgestalten und neue Möglichkeiten erschließen.
Gesundheitswesen:
Im Bereich des Gesundheitswesens spielen synthetische Daten eine zentrale Rolle, wenn es darum geht, Bedenken hinsichtlich des Datenschutzes im Zusammenhang mit Patientenakten auszuräumen. Sie erleichtern die Entwicklung und das Testen medizinischer Algorithmen, ohne dass sensible Informationen gefährdet werden. Vom Training von Diagnosemodellen bis hin zur Förderung der personalisierten Medizin werden synthetische Gesundheitsdaten zu einem Eckpfeiler für die medizinische Forschung.
Finanzen:
Der Finanzsektor nutzt synthetische Daten, um das Risikomanagement und Strategien zur Betrugserkennung zu verbessern. Synthetische Finanzdatensätze simulieren verschiedene Marktszenarien und ermöglichen es den Instituten, ihre Modelle und Algorithmen zu verfeinern. Dieser proaktive Ansatz erhöht die Robustheit von Finanzsystemen und ermöglicht eine bessere Entscheidungsfindung und Risikominderung.
Autonome Fahrzeuge:
Synthetische Daten erweisen sich als unverzichtbar beim Training von Algorithmen für autonome Fahrzeuge. Simulierte Fahrszenarien, die durch synthetische Datensätze erzeugt werden, bieten eine sichere und kontrollierte Umgebung für die Prüfung und Verbesserung von Fahrzeugsystemen. Dies beschleunigt die Entwicklung zuverlässiger und anpassungsfähiger Technologien für das autonome Fahren.
eCommerce:
Im eCommerce helfen synthetische Daten bei der Gestaltung personalisierter Kundenerlebnisse. Durch die Erstellung synthetischer Kundenprofile und Transaktionsdaten können Unternehmen ihre Marketingstrategien optimieren, Empfehlungssysteme verbessern und ihre Dienstleistungen auf individuelle Vorlieben abstimmen. Dieser datengesteuerte Ansatz steigert die Kundenbindung und -zufriedenheit.
Fertigung:
Die Fertigungsindustrie nutzt synthetische Daten, um Produktionsprozesse zu rationalisieren und zu optimieren. Die Simulation verschiedener Fertigungsszenarien hilft dabei, potenzielle Engpässe zu erkennen, die Logistik der Lieferkette zu optimieren und die betriebliche Effizienz insgesamt zu verbessern. Diese datengestützten Erkenntnisse ermöglichen es den Herstellern, fundierte Entscheidungen zur Prozessverbesserung zu treffen.
Cybersicherheit:
Synthetische Daten erweisen sich als hilfreich bei der Verstärkung von Cybersicherheitsmaßnahmen. Durch die Simulation von Cyber-Bedrohungen und -Angriffen können Unternehmen ihre Sicherheitssysteme effektiv trainieren und testen. Synthetische Datensätze schaffen realistische Szenarien, die es Cybersicherheitsexperten ermöglichen, proaktiv Schwachstellen zu erkennen und die Widerstandsfähigkeit digitaler Infrastrukturen zu verbessern.
Diese Anwendungen stellen nur einen Bruchteil der weitreichenden Auswirkungen synthetischer Daten in verschiedenen Branchen dar. Im Zuge des technologischen Fortschritts werden die Vielseitigkeit und Anpassungsfähigkeit synthetischer Datensätze auch weiterhin die Grenzen der Innovation neu definieren und maßgeschneiderte Lösungen für branchenspezifische Herausforderungen bieten.
Welche Herausforderungen hat die synthetische Dategenerierung?
Die Generierung synthetischer Daten öffnet zwar die Türen zur Innovation, stößt aber auch auf ein Spektrum von Herausforderungen und Einschränkungen, die eine sorgfältige Prüfung erfordern.
- Komplexität und Realismus: Die Erstellung synthetischer Datensätze, die die Komplexität realer Szenarien authentisch wiedergeben, bleibt eine gewaltige Herausforderung. Modelle können Schwierigkeiten haben, komplizierte Muster und Abhängigkeiten in verschiedenen Datensätzen zu replizieren, was zu einer potenziellen Kluft zwischen synthetischen und echten Daten führt.
- Verzerrungen und Verallgemeinerung: Synthetische Daten können trotz ausgefeilter Algorithmen unbeabsichtigt Verzerrungen verursachen oder sich nicht gut auf alle realen Szenarien verallgemeinern lassen. Die Sicherstellung, dass synthetische Datensätze die Vielfalt authentischer Daten genau widerspiegeln, bleibt eine ständige Herausforderung, die sich auf die Zuverlässigkeit von Modellen auswirkt, die mit solchen Daten trainiert wurden.
- Bewertungsmetriken: Die Festlegung umfassender Bewertungsmaßstäbe für die Qualität synthetischer Daten erweist sich als schwierig. Die Quantifizierung, wie gut synthetische Datensätze die statistischen Eigenschaften echter Daten nachbilden, erfordert nuancierte Metriken, und das Fehlen standardisierter Messgrößen kann eine effektive Bewertung behindern.
- Bereichsspezifische Herausforderungen: Bestimmte Bereiche stellen besondere Herausforderungen für die Generierung synthetischer Daten dar. In Branchen wie dem Gesundheitswesen muss der Schutz der Privatsphäre genauestens beachtet werden, was es schwierig macht, die Erstellung realistischer Daten mit der Notwendigkeit des Schutzes sensibler Informationen in Einklang zu bringen.
- Begrenzte Variabilität in der realen Welt: Synthetische Datensätze können nur schwer die volle Variabilität realer Daten erfassen. Diese Einschränkung kann die Leistung von Modellen in unvorhersehbaren Szenarien beeinträchtigen, die bei der Erzeugung synthetischer Daten nicht angemessen berücksichtigt wurden.
- Ethische Erwägungen: Die Verwendung synthetischer Daten wirft ethische Fragen auf, insbesondere wenn sie in sensiblen Bereichen eingesetzt werden. Das Abwägen zwischen dem Bedarf an realistischen Daten und ethischen Erwägungen, wie z. B. den möglichen Auswirkungen auf Randgruppen, erfordert eine sorgfältige Prüfung und die Einhaltung ethischer Richtlinien.
- Ressourcenintensität: Bestimmte Methoden zur Generierung synthetischer Daten, insbesondere solche, die fortschrittliche maschinelle Lernmodelle nutzen, können ressourcenintensiv sein. Das Training komplexer Modelle kann erhebliche Rechenleistung und Zeit erfordern, was für Organisationen mit begrenzten Ressourcen eine Herausforderung darstellt.
- Herausforderungen in Nischenbereichen: In spezialisierten Bereichen ist die Erstellung genauer und repräsentativer synthetischer Datensätze eine größere Herausforderung. In Nischenbranchen fehlen möglicherweise die umfangreichen realen Daten, die für eine effektive Generierung synthetischer Daten erforderlich sind, was deren Anwendbarkeit einschränkt.
Für Praktiker und Forscher, die mit synthetischen Daten arbeiten, ist es von entscheidender Bedeutung, diese Herausforderungen anzuerkennen. Indem sie sich mit diesen Einschränkungen auseinandersetzen, kann sich das Feld hin zu robusteren Methoden und Praktiken entwickeln und so das Vertrauen in die Anwendung synthetischer Daten in verschiedenen Bereichen stärken.
Welche Tools und Plattformen können für die synthetische Datengenerierung verwendet werden?
In der weitläufigen Landschaft der synthetischen Datengenerierung hat sich eine Vielzahl von Tools und Plattformen herausgebildet, die den differenzierten Bedürfnissen von Datenwissenschaftlern und Forschern gerecht werden, die realistische und vielfältige Datensätze für eine Vielzahl von Anwendungen erstellen wollen.
Im Bereich der speziellen Plattformen für synthetische Daten bieten Angebote wie Syntho und Mostly AI umfassende End-to-End-Lösungen. Diese Plattformen zeichnen sich durch fortschrittliche Algorithmen und robuste Mechanismen zur Wahrung der Privatsphäre aus, die die Erzeugung synthetischer Datensätze gewährleisten, die nicht nur die reale Welt widerspiegeln.
Die Python-Bibliothek Faker ist ein bemerkenswerter Anwärter, der für seine Vielseitigkeit bei der Erstellung realistischer und dennoch fiktiver Daten bekannt ist. Durch die Unterstützung verschiedener Datentypen erweist sich Faker als hilfreich in Szenarien, in denen die Wahrung der Privatsphäre von größter Bedeutung ist, und bietet einen unkomplizierten und zugänglichen Ansatz zur Erzeugung synthetischer Daten.
Für Praktiker, die in den Bereich des Deep Learning eintauchen, bieten Frameworks wie TensorFlow und Keras eine robuste Grundlage für die Implementierung von Generative Adversarial Networks (GANs). GANs, die für ihre Fähigkeit bekannt sind, komplexe Datenverteilungen zu erfassen, eröffnen Wege für die anspruchsvolle Generierung synthetischer Daten, die sich eng an die Komplexität realer Datensätze anlehnen.
PyTorch, ein weiteres leistungsstarkes Deep-Learning-Framework, glänzt bei der Arbeit mit probabilistischen Modellen wie Variational Autoencodern (VAEs). PyTorch bietet Flexibilität bei der Kodierung und Dekodierung von Datenverteilungen und ermöglicht die Erstellung synthetischer Datensätze mit nuancierten Strukturen und Beziehungen.
Bibliotheken zur Datenerweiterung bereichern das Toolkit zur Erzeugung synthetischer Daten. imgaug, das auf Bilder zugeschnitten ist, und nlpaug, das auf Text spezialisiert ist, spielen eine zentrale Rolle bei der Einführung von Variationen in Datensätze, der Erweiterung ihres Umfangs und der Verbesserung der Robustheit von Modellen für maschinelles Lernen.
Auf den Datenschutz ausgerichtete Tools wie Mimic und OpSynth stellen den Schutz sensibler Informationen in den Vordergrund. Diese Tools ermöglichen die Erstellung synthetischer Datensätze, die reale Szenarien widerspiegeln und gleichzeitig die Privatsphäre schützen, was sie in Bereichen wie dem Gesundheits- und Finanzwesen besonders wertvoll macht.
DataRobot Paxata stellt eine nahtlose Integration von Datenaufbereitung und synthetischer Datenerzeugung dar. Durch die Kombination von visuellem Datenprofiling mit automatischer Datenaufbereitung rationalisiert diese Plattform den Prozess der Generierung synthetischer Daten und richtet sich an Benutzer, die Effizienz und benutzerfreundliche Workflows suchen.
H2O.ai bietet Lösungen, die auf Einfachheit und Effizienz bei der Erstellung synthetischer Datensätze für maschinelles Lernen und KI-Anwendungen ausgerichtet sind. Der Ansatz der Plattform stellt sicher, dass Praktiker auf einfache Weise verschiedene synthetische Datensätze erzeugen können, die auf die einzigartigen Anforderungen ihrer Projekte abgestimmt sind.
Die Vielfalt der verfügbaren Tools stellt sicher, dass die Anwender ihren Ansatz auf die spezifischen Anwendungsfälle, Datentypen und Datenschutzaspekte ihrer Projekte abstimmen können. Diese Vielfalt im Toolkit für die Generierung synthetischer Daten ermöglicht die Erstellung von Datensätzen, die nicht nur technischen Anforderungen genügen, sondern auch ethischen und datenschutzrechtlichen Standards entsprechen und so das Vertrauen in die Anwendung synthetischer Daten in verschiedenen Bereichen fördern.
Wie kannst Du die Synthetische Datengenerierung in Python nutzen?
In Python wird die Vielseitigkeit der Generierung synthetischer Daten durch verschiedene Bibliotheken zum Leben erweckt, die auf unterschiedliche Anforderungen zugeschnittene Funktionalitäten bieten. Lass uns ein praktisches Beispiel anhand eines öffentlichen Datensatzes durchspielen und die einzelnen Schritte demonstrieren:
- Datenexploration:
Wähle einen öffentlichen Datensatz aus, der für Deinen Bereich relevant ist. Nehmen wir zum Beispiel den “Iris”-Datensatz, einen klassischen Datensatz für maschinelles Lernen, der in scikit-learn verfügbar ist. Dieser Datensatz enthält Messungen von Kelchblattlänge, Kelchblattbreite, Blütenblattlänge und Blütenblattbreite für drei verschiedene Arten von Irisblüten.
- Datengenerierung mit Faker:
Beginne mit der Installation der Faker-Bibliothek, falls diese noch nicht installiert ist. Verwende den folgenden Befehl:

- Synthetische Daten generieren: Importiere die erforderlichen Bibliotheken und erstelle mit Faker synthetische Daten. In diesem Beispiel werden wir zusätzliche Daten für den “Iris”-Datensatz simulieren, indem wir falsche Namen für die Arten der Blumen erzeugen:
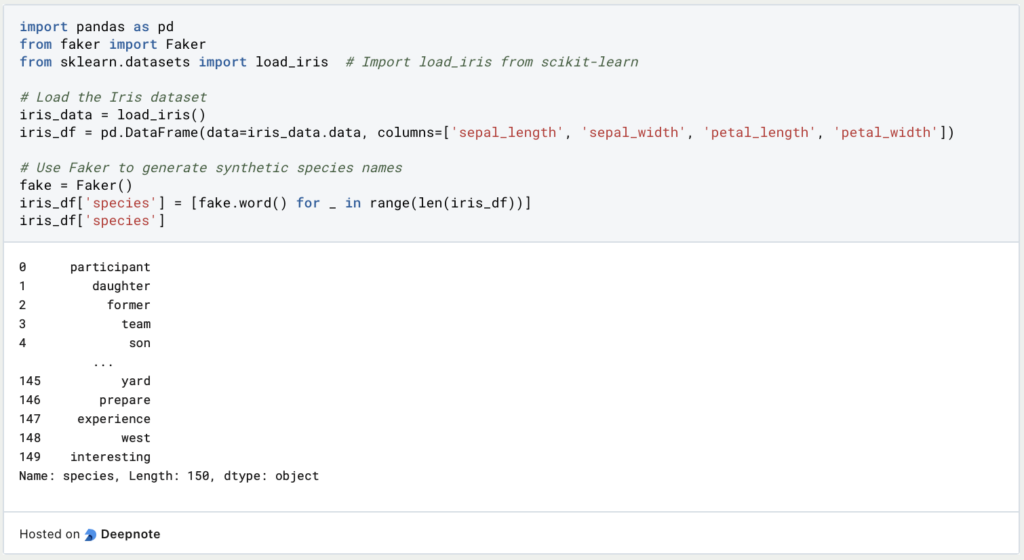
- Datenanalyse: Analysiere die synthetischen Daten zusammen mit dem Originaldatensatz, um die eingeführten Abweichungen zu beobachten. Dieser Schritt stellt sicher, dass die generierten Daten mit den Merkmalen des realen Datensatzes übereinstimmen.
- Datenintegration: Führe die realen und synthetischen Datensätze zusammen, um einen umfassenden Datensatz für das Training von Machine-Learning-Modellen zu erstellen. Diese Integration erhöht die Vielfalt der Datensätze und verbessert möglicherweise die Modellgeneralisierung.
Dieses Beispiel zeigt die nahtlose Integration der Erzeugung synthetischer Daten mithilfe der Faker-Bibliothek mit einem bekannten öffentlichen Datensatz. Obwohl der Iris-Datensatz relativ einfach ist, lassen sich die Prinzipien auch auf komplexere Datensätze in verschiedenen Bereichen anwenden und veranschaulichen die praktische Umsetzung synthetischer Daten in Python.
Das solltest Du mitnehmen
- Die Landschaft der Generierung synthetischer Daten bietet ein vielfältiges Toolkit, das von speziellen Plattformen bis hin zu vielseitigen Bibliotheken reicht und den unterschiedlichen Bedürfnissen von Datenwissenschaftlern und Forschern gerecht wird.
- Datenschutzorientierte Tools wie Mimic und OpSynth sind ein Beispiel für das Engagement zum Schutz sensibler Informationen und machen die synthetische Datengenerierung zu einer praktikablen Lösung für datenschutzbewusste Anwendungen.
- Die Integration von Deep-Learning-Frameworks wie TensorFlow, Keras und PyTorch ermöglicht die Implementierung anspruchsvoller Techniken wie GANs und VAEs und verbessert die Fähigkeit, komplizierte reale Datenverteilungen zu replizieren.
- Die synthetische Datengenerierung findet in den verschiedensten Bereichen Anwendung, vom Gesundheitswesen bis zum Finanzwesen, und zeigt die Vielseitigkeit bei der Erstellung von Datensätzen, die reale Szenarien widerspiegeln.
- Plattformen wie DataRobot Paxata und Lösungen von H2O.ai rationalisieren den Prozess durch die Integration von Datenaufbereitung und synthetischer Datengenerierung, wobei Effizienz und benutzerfreundliche Arbeitsabläufe im Vordergrund stehen.
- Das Toolkit ermöglicht es Praktikern, ein Gleichgewicht zwischen der Erstellung realistischer Datensätze und der Einbeziehung von Flexibilität zu finden, um sicherzustellen, dass die synthetischen Daten mit den Komplexitäten und Nuancen realer Datensätze übereinstimmen.
- Die Generierung synthetischer Daten trägt zu einer ethischen Datenpraxis bei, indem sie Alternativen für Szenarien bietet, in denen reale Daten Bedenken hinsichtlich des Datenschutzes aufwerfen können, und fördert so eine verantwortungsvolle und transparente Nutzung von Daten.

Prompt Engineering einfach erklärt: Grundlagen, Beispiele und Best Practices
Warum gute Prompts selten mit „Schreib mir…“ beginnen „Schreib mir eine Analyse zu diesem Kundenfeedback.“ Das klingt zuerst eindeutig. Trotzdem liefert ein KI-Modell darauf oft eine Antwort, die zwar gut formuliert ist, aber kaum weiterhilft. Genau hier beginnt Prompt engineering deutsch erklärt: Nicht die KI ist automatisch schlecht, sondern die Aufgabe war für das Modell… Weiterlesen »Prompt Engineering einfach erklärt: Grundlagen, Beispiele und Best Practices
Retrieval Augmented Generation: So nutzt du eigene Daten mit KI
Lerne Retrieval Augmented Generation praxisnah kennen und erfahre, wie du KI mit eigenen Daten verbindest. Jetzt verständlich einsteigen!

Retrieval-Augmented Generation (RAG) erklärt: So verbinden Sie große Sprachmodelle mit Ihren eigenen Daten (Python-Tutorial)
Warum LLMs bei privaten Daten scheitern — und warum RAG das löst Große Sprachmodelle wie GPT-5 oder Claude werden nur mit Daten bis zu einem bestimmten Zeitpunkt trainiert. Sie wissen nicht, was in der internen Dokumentation deines Unternehmens, in deiner Produktdatenbank oder im Verkaufsbericht des letzten Quartals steht. Sie können auch keinen privaten Notion-Workspace durchsuchen… Weiterlesen »Retrieval-Augmented Generation (RAG) erklärt: So verbinden Sie große Sprachmodelle mit Ihren eigenen Daten (Python-Tutorial)

Was ist eine Boltzmann Maschine?
Die Leistungsfähigkeit von Boltzmann Maschinen freisetzen: Von der Theorie zu Anwendungen im Deep Learning und deren Rolle in der KI.

Was ist die Gini-Unreinheit?
Erforschen Sie die Gini-Unreinheit: Eine wichtige Metrik für die Gestaltung von Entscheidungsbäumen beim maschinellen Lernen.

Was ist die Hesse Matrix?
Erforschen Sie die Hesse Matrix: Ihre Mathematik, Anwendungen in der Optimierung und maschinellen Lernen.
Andere Beiträge zum Thema Synthetische Datengenerierung
Hier findest Du einen Artikel über die synthetische Datengenerierung bei Microsoft.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.