Collaborative filtering is a powerful technique used in recommendation systems to provide personalized recommendations to users based on their past behaviors and preferences. This technique leverages the similarities and relationships between users and items in a dataset to predict user-item interactions. Collaborative filtering is widely used in e-commerce, social media, and entertainment industries, and has significantly improved the user experience in these domains.
In this article, we will explore the concept of collaborative filtering, its different types, and how it works. We will also discuss the challenges and limitations and some practical applications of this technique in real-world scenarios.
What is Collaborative Filtering?
Collaborative filtering is a popular technique in machine learning that is used to make recommendations based on the preferences and behaviors of similar users. Its algorithms analyze user data, such as ratings, reviews, and purchase histories, to identify patterns and similarities in user behavior and then use this information to predict which items or products a user might be interested in.
Collaborative filtering has a long history and is often associated with the development of recommender systems. In the early days of e-commerce, companies struggled to find an effective way to recommend products to customers. However, in the late 1990s, collaborative filtering emerged as a powerful technique for making recommendations based on the behavior of similar users.
Since then, it has become a popular area of research and has been applied in a wide range of industries, including e-commerce, entertainment, social media, and healthcare. Today, collaborative filtering algorithms are used to power many of the world’s most popular recommendation systems, including those used by Amazon, Netflix, and Spotify.
What are the different types of Collaborative Filtering?
The concept can be broadly classified into two types:
- User-based collaborative filtering: This method recommends items to a target user based on the preferences of similar users. In this approach, the system first identifies users who have similar interests or preferences to the target user, and then recommends items that these similar users have rated highly. For example, if two users have rated several movies similarly, the system may recommend a movie to one user based on the high rating given to that movie by the other user.
- Item-based collaborative filtering: In this method, the system recommends items that are similar to the ones that the target user has already rated highly. The system analyzes the ratings given by all users to different items and identifies items that have similar ratings. Then, when a target user rates an item, the system recommends other items that have similar ratings to the one that the user liked. For example, if a user likes a particular book, the system may recommend other books that have similar themes, genres, or writing styles.
Both approaches have their advantages and disadvantages. User-based collaborative filtering may have better accuracy when there is sufficient data available, while item-based collaborative filtering may be more scalable and have better performance with sparse data. The choice of approach depends on the specific requirements and constraints of the problem being solved.
How does Collaborative Filtering work?
Collaborative filtering is a technique used by recommender systems to predict user preferences and recommend items based on the similarities of users’ past preferences. It assumes that people who share similar preferences in the past are likely to share similar preferences in the future. There are two main approaches to collaborative filtering: user-based and item-based.
User-based filtering involves comparing a user’s preferences with other users who have similar preferences and then recommending items that similar users have liked. For example, if user A likes movies X, Y, and Z, and user B also likes movies X and Y, then user-based collaborative filtering would recommend movie Z to user B.
Item-based filtering involves comparing the items themselves and then recommending items that are similar to those a user has already liked. For example, if a user likes movies X, Y, and Z, item-based collaborative filtering would recommend other movies that are similar to X, Y, and Z.
Both user-based and item-based collaborative filtering can be used in combination to provide better recommendations. These algorithms can be further categorized into memory-based and model-based techniques.
Memory-based collaborative filtering algorithms use the entire dataset to find patterns and make recommendations. They can be further divided into two types: neighborhood-based and model-based. Neighborhood-based methods calculate the similarities between users or items, while model-based methods use machine learning algorithms to predict user preferences.
Model-based collaborative filtering algorithms create a model based on user behavior and use it to predict user preferences. These algorithms use machine learning techniques such as matrix factorization and clustering to identify patterns in the data and predict user preferences.
Overall, this technique has been widely adopted in various industries, including e-commerce, social media, and entertainment. It has been shown to be effective in improving user engagement, sales, and customer satisfaction.
What are advantages and limitations of Collaborative Filtering?
Collaborative filtering, a popular technique in recommendation systems, offers several advantages and has some limitations to consider. Understanding these aspects is crucial for effectively implementing and leveraging collaborative filtering in real-world applications.
Advantages:
- User-Centric Recommendations: Collaborative filtering focuses on user preferences and behavior, enabling personalized recommendations based on similarities between users. This approach helps deliver tailored suggestions that align with individual tastes and interests.
- Independence from Content Metadata: The filtering doesn’t rely heavily on explicit item features or metadata. Instead, it leverages the collective wisdom of users to make recommendations. This makes it suitable for scenarios where item information may be limited or not readily available.
- Serendipity and Novelty: These algorithms can introduce users to new and unexpected items they may not have discovered otherwise. By identifying patterns and connections between users, collaborative filtering fosters serendipitous discovery and promotes novel recommendations.
- Scalability and Flexibility: Collaborative filtering can scale effectively as the user base and item catalog grow. It adapts well to dynamic environments where user preferences evolve and new items are added. Additionally, it can accommodate various data types, including ratings, likes, or purchase histories.
Limitations:
- Cold Start Problem: It struggles when dealing with new users or items with limited or no historical data. Without sufficient user-item interactions, the algorithm may struggle to generate accurate recommendations for these cases. Complementary approaches like content-based filtering can help address the cold start problem.
- Sparsity of Data: Collaborative filtering relies on user-item interactions to identify similarities and make recommendations. However, sparse data, where users have only interacted with a small subset of items, can impact the accuracy and coverage of recommendations. Techniques like matrix factorization or neighborhood-based methods can mitigate this limitation.
- Popularity Bias and Limited Diversity: It tends to favor popular items and may overlook niche or less-popular options. This can result in recommendations that lack diversity, potentially leading to filter bubbles or limited exposure to alternative choices. Hybrid approaches combining collaborative and content-based filtering can mitigate this issue.
- Privacy and Data Quality Concerns: The algorithm relies on collecting and analyzing user data to make recommendations. Privacy concerns arise when sensitive user information is utilized, necessitating appropriate anonymization and data protection measures. Additionally, the quality and reliability of user-generated data, such as ratings or reviews, can impact the accuracy of collaborative filtering.
Understanding these advantages and limitations helps practitioners and system designers employ collaborative filtering effectively, considering its strengths while addressing its inherent challenges. Additionally, combining collaborative filtering with complementary techniques can enhance recommendation quality, diversity, and user satisfaction in various domains.
What are real-world applications of Collaborative Filtering?
Collaborative filtering has found numerous applications in the real world. Here are some examples:
- E-commerce: Many e-commerce websites such as Amazon, eBay, and Netflix use collaborative filtering algorithms to recommend products and movies to their customers based on their purchase and rating history.
- Social media: Social media platforms like Facebook, Twitter, and LinkedIn use the technique to suggest friends and connections based on a user’s interactions with others on the platform.
- Music streaming: Music streaming platforms such as Spotify and Pandora use collaborative filtering to suggest new songs and playlists to their users based on their listening history and preferences.
- Online advertising: Collaborative filtering algorithms are used to show personalized advertisements to users based on their search history and online behavior.
- Healthcare: They are also being used in healthcare to predict patient outcomes and suggest personalized treatments based on the patient’s medical history and the outcomes of similar patients.
- News and content delivery: News and content websites use it to recommend articles and videos to users based on their reading and viewing history.
- Online education: Online learning platforms such as Coursera and Udemy use collaborative filtering algorithms to suggest courses and learning materials to their users based on their past learning history and preferences.
These are just a few examples of how the algorithm is being used in various industries to improve user experience and personalize recommendations.
Which techniques are used for improving Collaborative Filtering?
Collaborative filtering has been a popular and effective approach for recommendation systems. However, there are some challenges in implementing it, and there have been several techniques developed to improve its performance. Some of these techniques are:
- Regularization: One of the main challenges is overfitting, which can occur when the model is too complex and captures noise instead of the underlying patterns in the data. Regularization is a technique used to address overfitting by adding a penalty term to the loss function, which discourages large weights.
- Similarity Metrics: Collaborative filtering relies on similarity measures between users or items. There are several similarity metrics used in collaborative filtering, including cosine similarity, Pearson correlation coefficient, and Jaccard similarity. Choosing an appropriate similarity metric can have a significant impact on the performance of the collaborative filtering algorithm.
- Matrix Factorization: Matrix factorization is a technique used to reduce the dimensionality of the user-item matrix by representing it as the product of two lower-dimensional matrices. This technique can be used to identify latent factors that are not explicitly represented in the original data and improve the accuracy of recommendations.
- Deep Learning: Deep learning techniques, such as neural networks, have been applied to collaborative filtering to capture complex patterns in the data. These techniques can improve the accuracy of recommendations, especially in cases where the data is high-dimensional or non-linear.
- Hybrid Models: Hybrid models combine different recommendation techniques, such as collaborative filtering and content-based filtering, to improve the accuracy of recommendations. Hybrid models can overcome the limitations of individual techniques and provide more accurate recommendations.
These techniques are not exhaustive, and there are several other techniques used to improve collaborative filtering performance. The choice of technique depends on the specific problem, the data available, and the desired accuracy of recommendations.
How to do Collaborative Filtering in Python?
In this example, we will explore collaborative filtering, a popular technique used in recommender systems. Collaborative filtering leverages the behavior and preferences of users to make personalized recommendations. We will use Python and a public dataset, the MovieLens dataset, to demonstrate how collaborative filtering can be implemented and used to predict ratings for user-item pairs. By understanding the principles and code behind it, you can apply this technique to build your own recommendation systems in various domains. Let’s dive into the code and see how it works!
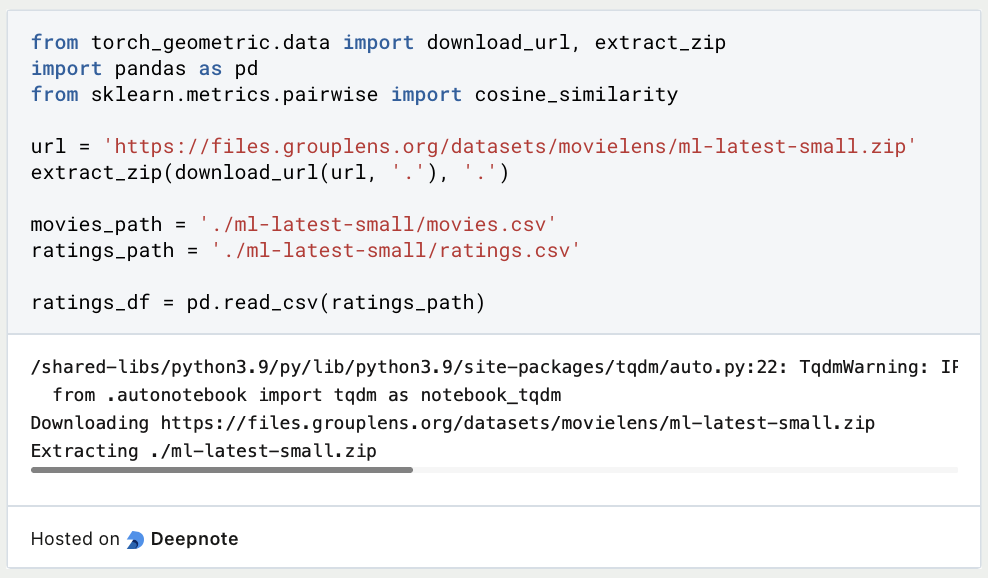
In this section, we import the necessary libraries, including pandas for data manipulation and sklearn’s cosine_similarity for calculating cosine similarity between items. We load the MovieLens dataset using pd.read_csv() and store it in the ratings DataFrame.

Here, we create a user-item matrix by pivoting the ratings DataFrame. The index of the matrix represents user IDs, the columns represent item IDs, and the values are the ratings given by users to items. We use pivot_table() to aggregate the ratings, and we set fill_value=0 to replace missing values with zeros.

Next, we calculate the item-item similarity matrix using cosine similarity. We transpose the user-item matrix using .T to calculate the similarity between items. cosine_similarity() computes the pairwise cosine similarity between item vectors, resulting in a symmetric similarity matrix.
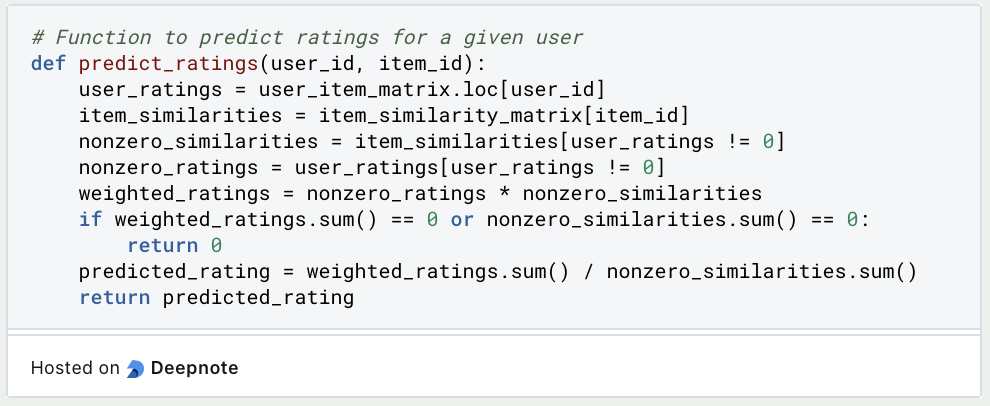
Here, we define a function predict_ratings() that takes a user_id and item_id as input and predicts the rating for that user-item pair. Inside the function, we retrieve the ratings given by the user for all items, the similarity scores between the target item and other items, and filter out the nonzero ratings and their corresponding similarities. We calculate the weighted ratings by multiplying the nonzero ratings with their respective similarities. If the sum of weighted ratings or the sum of nonzero similarities is zero (to handle cases where there are no available ratings or similarities), we return 0. Otherwise, we compute the predicted rating as the weighted average of ratings divided by the sum of similarities.
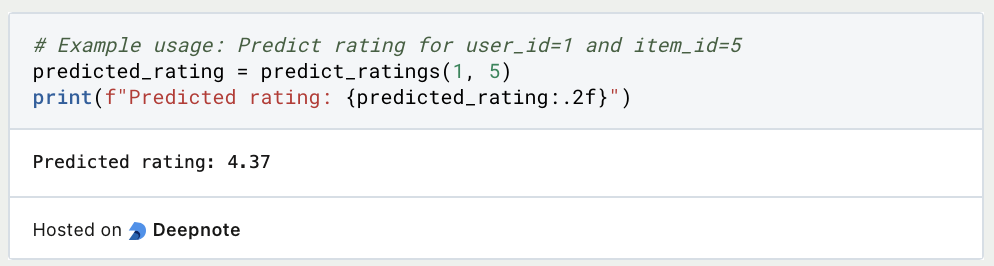
Finally, we showcase an example usage of the predict_ratings() function by predicting the rating for user_id=1 and item_id=5. The predicted rating is printed using f-string formatting to two decimal places.
You can modify and adapt this code example for your specific dataset and recommendation needs. It provides a foundation for collaborative filtering in Python using a public dataset and serves as a starting point for further exploration and customization.
This is what you should take with you
- Collaborative filtering is a popular approach for recommendation systems that is widely used in different industries.
- It can be implemented using two main types: user-based and item-based collaborative filtering.
- The algorithm works by finding patterns in user behavior to make recommendations to other users with similar preferences.
- Collaborative filtering has many real-world applications such as online shopping, streaming services, and social media platforms.
- Techniques such as matrix factorization, deep learning, and hybrid systems are used to improve the performance.
- Collaborative filtering is not without its limitations, including the cold start problem and the potential for creating filter bubbles.

What is Data Privacy?
Explore the essence of data privacy in our world. Uncover regulations, best practices, and the evolving landscape of personal information.

How can you create a website without hiring a developer?
In the past, building a new website usually required hiring an external service provider. Web developers still exist today, but they can be expensive. That’s why it’s great that there are also free options available. Here you can find out what they are and how you can benefit from them. What is a web developer?… Read More »How can you create a website without hiring a developer?

What is Knowledge Representation?
Explore Knowledge Representation in AI: Learn how machines store and process knowledge, powering the future of artificial intelligence.

What is Quantum Computing?
Dive into the quantum revolution with our article of quantum computing. Uncover the future of computation and its transformative potential.

What is Anomaly Detection?
Discover effective anomaly detection techniques in data analysis. Detect outliers and unusual patterns for improved insights. Learn more now!

What is the T5-Model?
Unlocking Text Generation: Discover the Power of T5 Model for Advanced NLP Tasks - Learn Implementation and Benefits.
Other Articles on the Topic of Collaborative Filtering
The Technical University of Munich published an interesting article on recommendation systems based on collaborative filtering.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.