Overfitting is a term from the field of data science and describes the property of a model to adapt too strongly to the training data set. As a result, the model performs poorly on new, unseen data. However, the goal of a Machine Learning model is a good generalization, so the prediction of new data becomes possible.
What is Overfitting?
The term overfitting is used in the context of predictive models that are too specific to the training data set and thus learn the scatter of the data along with it. This often happens when the model has too complex a structure for the underlying data. The problem is that the trained model generalizes poorly, i.e., provides inadequate predictions for new, unseen data. The performance on the training data set, on the other hand, was excellent, which is why one could assume a high model quality.
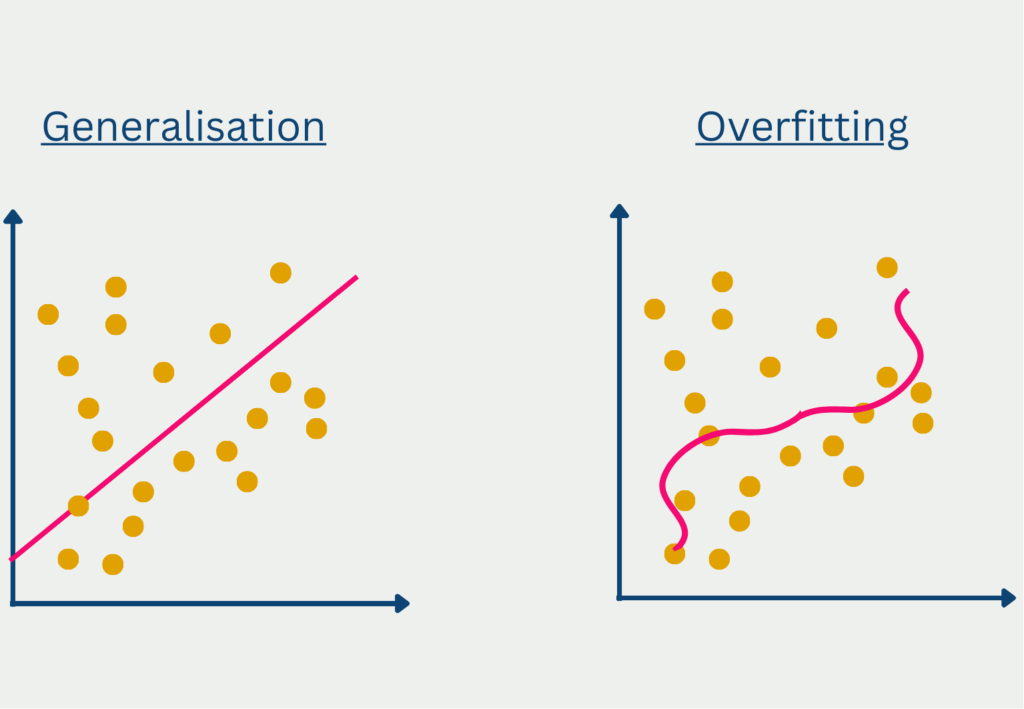
Some factors may indicate an impending overfitting early on:
- Small Data Set: If there are only a few individual data sets in the training, the probability is very high that these are simply learned by heart, and far too little information is available to be able to learn an underlying structure. The more training parameters the model has, the more problematic it becomes. A neural network, for example, has a large number of parameters on each hidden layer. Therefore, the more complex the model, the larger the data set should be.
- Selection of the Training Dataset: If the selection of datasets is already unbalanced, there is a high probability that the model will train them and thus have poor generalization. The sample from a population should always be randomly chosen so that selection bias does not occur. To make an extrapolation during an election, not only the voters at one polling place should be surveyed, as they are not representative of the whole country, but only represent the opinion in that constituency.
- Many Training Epochs: A model trains several epochs and in each epoch has the goal of further minimizing the loss function and thereby increasing the quality of the model. However, at a certain point, only improvements in backpropagation can be achieved by adapting more to the training dataset.
How do you recognize Overfitting?
Unfortunately, there is no central analysis that can determine with certainty whether a model is overfitted or not. However, there are some parameters and analyses that can provide indications of impending overfitting. The best and simplest method is to look at the error curve of the model over the iterations.
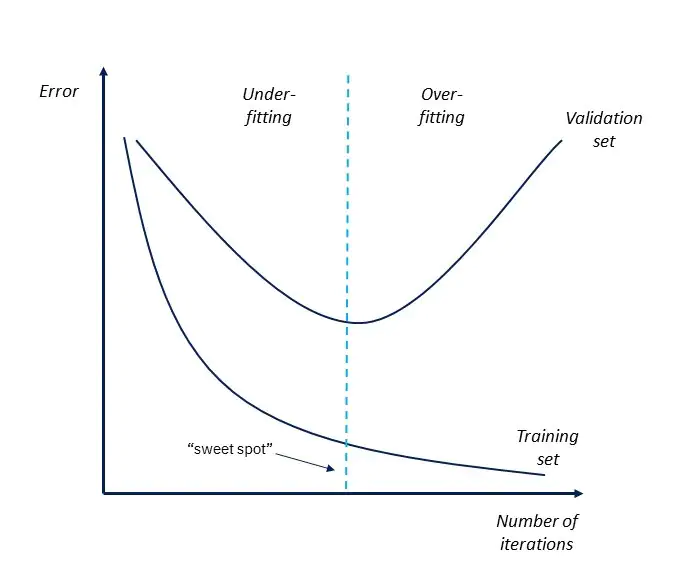
If the error in the training data set continues to decrease, but the error in the validation data set begins to increase again, this indicates that the model fits the training data too closely and thus generalizes poorly. The same evaluation can be done with the loss function.
To build such a graph, you need the so-called validation or test set, i.e. unseen data for the model. If the data set is large enough, you can usually split off 20-30% of the data set and use it as a test data set. Otherwise, there is also the possibility to use the so-called k-fold cross-validation, which is somewhat more complex and can therefore also be used for smaller data sets.
The data set is divided into k blocks of equal size. One of the blocks is randomly selected and serves as the test data set and the other blocks in turn are the training data. However, in the second training step, another block is defined as the test data, and the process repeats.
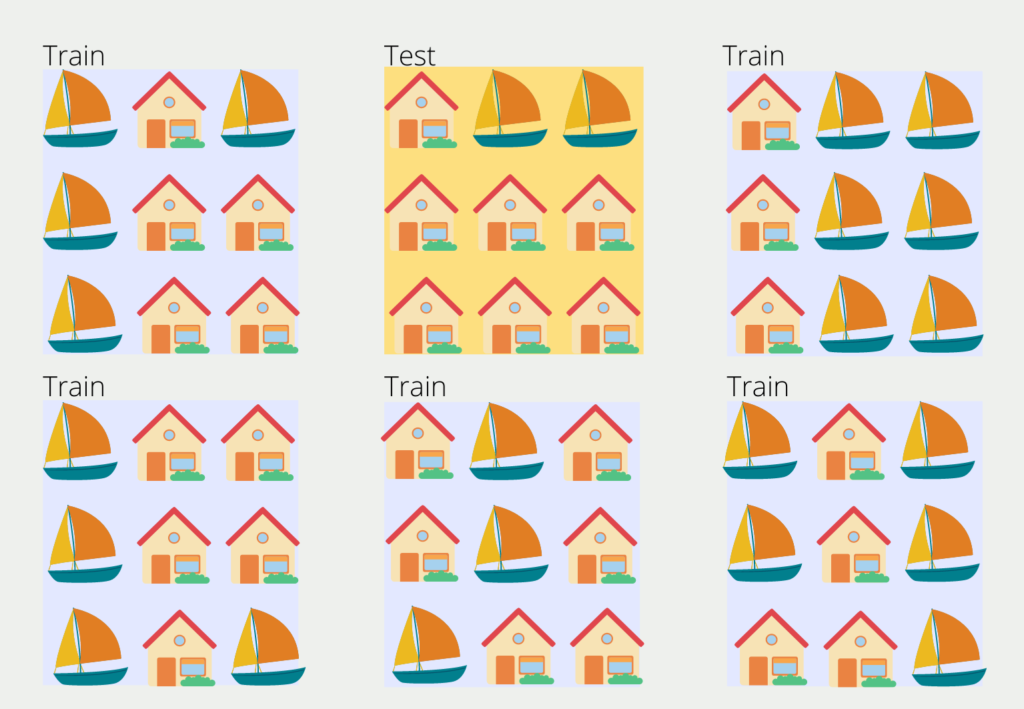
The number of blocks k can be chosen arbitrarily and in most cases, a value between 5 and 10 is chosen. A too large value leads to a less biased model, but the risk of overfitting increases. A too small k value leads to a more biased model, as it then actually corresponds to the hold-out method.
How to prevent Overfitting?
There are many different ways to prevent overfitting, or at least reduce the likelihood of it. From the following suggestions, in many cases already two should be sufficient to keep the risk of overfitting low:
- Data Set: The data set plays a very important role in avoiding overfitting. It should be as large as possible and contain different data. Furthermore, enough time should have been spent on the data preparation process. If incorrect or missing data occurs too frequently, the complexity increases and the risk of overfitting increases accordingly. A clean data set, on the other hand, makes it easier for the model to recognize the underlying structure.
- Data Augmentation: In many applications, such as image recognition, individual data sets are used and given to the model with slight modifications for training. These changes can be, for example, a black and white copy of an image or the same text with some typos in it. This makes the model more stable and helps it learn to deal with data variations and become more independent of the original training data set.
- Stopping Rule: When starting a model, you specify a maximum number of epochs after which the training is finished. In addition, it can make sense to stop the training at an early stage, for example, if it does not make any real progress over several epochs (the loss function no longer decreases) and there is thus a risk that the model runs into overfitting. In TensorFlow, a separate callback can be defined for this purpose:
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)- Feature Selection: A dataset often contains a variety of features that are given as input to the model. Such underfitting can occur when the model is not sufficiently complex to represent the complex underlying structure. Another problem may be that important features are missing from the data set that is needed to calculate the relationship. However, not all of them are really needed for the prediction of the correct result. Some features may even be correlated, i.e. interdependent. If a large number of features are available, a preselection should be made with the help of suitable algorithms. Otherwise, the complexity of the model increases and the risk of overfitting is high.
Overfitting vs. Underfitting
Overfitting and underfitting are two problems that frequently occur when training a machine learning algorithm. Both have a significant influence on the generalization ability of the model, i.e. on how good the predictions of the model are on new data. In the case of overfitting, the model structure is too complex, which means that it adapts too strongly to the training data and also learns the noise in the training data. This results in incorrect predictions for the test data, which may not have this noise. Overfitting can be detected via the accuracies, which are very high on the training or validation set, but very low on the test data. This is an indicator of overfitting.
In underfitting, on the other hand, the model is not complex enough to recognize and learn the underlying structure in the data. As a result, the model performance is severely impaired for both the training data and the test data. Underfitting can be recognized by the fact that the error on the training data is very high and also stagnates at a high level in the further course of training and does not decrease. Although underfitting occurs much less frequently than overfitting, it is a serious problem in the creation of machine learning models.
The problem with these two phenomena is that they are in balance with each other and it can be difficult to find the point at which overfitting has been prevented without the model slipping into underfitting. Various techniques can be used to find this balance.
The most common methods include
- Regularization: Regularization involves adding various parameters to the loss function that take into account the number of model parameters, and penalizing the addition of new input parameters that do not sufficiently improve the model. This helps to combat overfitting.
- Cross-validation: Cross-validation ensures a dynamic mixing of the training and validation sets. This provides the model with a larger amount of training data and the performance of the model is evaluated more independently during training.
- Early stopping: This rule is used to stop the training of a machine learning model at an early stage if it can be assumed that overfitting could occur in the subsequent training runs. This involves investigating whether the loss of validation increases over several epochs or iterations, which indicates an imminent overfitting.
The balance between overfitting and underfitting is a crucial issue when training machine learning models, which should be considered and taken into account during training to achieve good generalization.
What are the consequences of overfitting in the application?
Overfitting can have significant consequences in the real world, especially in applications where the model’s predictions are used to inform decisions. Some examples of the consequences of overfitting are:
- Poor generalization: Overfitted models are highly tuned to the training data and therefore often do not generalize well to unseen data. This means that the model performs well on the training data but poorly on the new data, making it useless in real-world applications.
- Decision-making biases: Overfitted models can lead to biased results that favor certain outcomes or groups of data. This can be particularly problematic in decision-making applications, such as credit scoring or medical diagnosis, where even small deviations can have significant consequences.
- Wasted resources: Overfitting often leads to the development of complex models that require significant computational resources to train and deploy. This can result in wasted time, money, and computing power, especially if the resulting model is not useful in practice.
- Increased risk: Overfitted models can give the impression of accuracy, leading to overconfidence in their predictions. This can increase the risk of making incorrect decisions or taking inappropriate actions based on flawed model results.
In summary, overfitting can have serious practical consequences, which is why it is important to develop models that balance complexity and generalization.
This is what you should take with you
- Overfitting is a term from the field of data science and describes the property of a model to adapt itself too strongly to the training data set.
- It is usually recognizable by the fact that the error in the test data set increases again, while the error in the training data set continues to decrease.
- Among other things, overfitting can be prevented by inserting an early stopping rule or by removing features from the data set in advance that are correlated with other features.

What is the Adam Optimizer?
Unlock the Potential of Adam Optimizer: Get to know the basucs, the algorithm and how to implement it in Python.

What is One-Shot Learning?
Mastering one shot learning: Techniques for rapid knowledge acquisition and adaptation. Boost AI performance with minimal training data.

What is the Bellman Equation?
Mastering the Bellman Equation: Optimal Decision-Making in AI. Learn its applications & limitations. Dive into dynamic programming!

What is the Singular Value Decomposition?
Unlocking insights and patterns: Learn the power of Singular Value Decomposition (SVD) in data analysis. Discover its applications.

What is the Poisson Regression?
Learn about Poisson regression, a statistical model for count data analysis. Implement Poisson regression in Python for accurate predictions.

What is blockchain-based AI?
Discover the potential of Blockchain-Based AI in this insightful article on Artificial Intelligence and Distributed Ledger Technology.
Other Articles on the Topic of Overfitting
- IBM offers an interesting article on overfitting and was also used as a source for this post.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.