Elasticsearch is a distributed search engine based on Apache Lucene. It is a popular search engine for full-text searches or log analysis and is therefore used by many large companies such as Netflix, Slack, and Uber.
How does Elasticsearch work?
This search engine is based on the fact that the raw data and documents that are to be searched are combined in an index. For this purpose, they are normalized and parsed in the indexing step so that the final search can run faster. This pre-processed index can be searched much faster than the original documents and data.
Let’s assume we have an online store with various pieces of furniture, which we want to make accessible to our customers with the help of a search. For each piece of furniture, there is information that should be considered in the search. This includes, among other things, the product properties (e.g. the dimensions, color, or special features) and the product description. To ensure that these textual properties can be searched quickly, we use the full-text search Elasticsearch.
To do this, we have to store the data and documents in its index. This can be thought of as a database in which all information is stored. In the index, there are several so-called types, which are comparable with tables in a database.
In our example, only the product properties could be stored in one type, while the product descriptions are stored in a second type. In the types, there are then finally still the documents in which individual data records are held. Although the index is not a strict relational database, a certain structure must still be maintained so that a quick search is possible.
In our example, the individual pieces of furniture are prepared in the documents and stored in a structure so that they are easier to find for the final search. For this purpose, the so-called attributes are defined within the documents, which come closest to the columns in a table.
What should be considered during indexing?
Indexing data is one of the most important functions of Elasticsearch. Indexing involves storing and retrieving data. It uses a structure called an index to organize the data. An index is a collection of documents that have similar properties. Elasticsearch provides a flexible and dynamic mapping feature that allows users to map and store different types of data. Here are some important points to consider when indexing data:
- Indexing is automatic and can occur when data is added to or removed from an index.
- Elasticsearch uses a flexible schema that can accommodate a variety of data types.
- Users can customize index settings to optimize search performance or limit the amount of storage used.
- A wide range of indexing options are supported, including geographic locations, full-text search, and numeric data.
- Multiple indexes can also be searched simultaneously, which can be useful for large amounts of data.
- The data indexing process in Elasticsearch is designed for scalability and can handle large amounts of data with high efficiency.
- It offers powerful search capabilities that allow users to search and retrieve data with complex queries and filters.
Overall, the data indexing process is a crucial aspect of Elasticsearch, as it allows users to store and retrieve data with high efficiency and flexibility. With its powerful indexing and search capabilities, Elasticsearch has become a popular tool for managing and analyzing large amounts of data.
What do you use Elasticsearch for?
Elasticsearch can be used wherever search functionality is needed. Additionally, it stands out for its high scalability and fast search process. A number of applications for which it can be considered are:
- Search on websites
- Search engines in applications
- Search engine for corporate data
- Searching log files
- Search in geodata
- Search in security and monitoring files
What are the Components of Elasticsearch?
Because of its widespread use and many benefits, a whole stack of tools has formed around Elasticsearch that goes beyond just search.
With the help of Logstash, data can be collected and prepared so that it is better suited for subsequent indexing. The open-source program can be understood as Elastic’s ETL tool and offers comparable functionalities by pulling together data from different sources, transforming it, and bringing it to the final storage location.
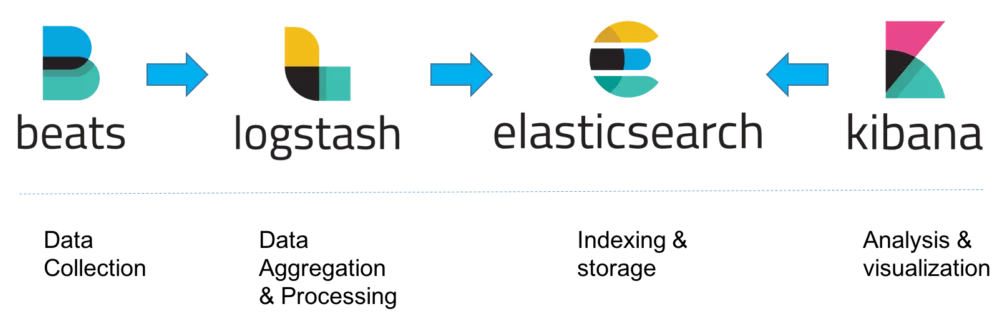
The tool that is downstream of Elastic’s search is Kibana. It offers the possibility to visualize and analyze the information from the search index. This so-called ELK (Elastic, Logstash, Kibana) stack thus offers the possibility to cover the complete range from obtaining the data, through a search, to the analysis of the index.
What are the benefits of Elasticsearch?
Elasticsearch is a very popular search engine nowadays due to its many advantages. Some of them are:
- Speed: Due to the indexing, it is significantly faster than comparable algorithms, especially in full-text search. In addition, preparatory indexing does not take very long either, which means that the overall process from inclusion in the index to findability in the search is very fast. This is very advantageous for applications where the speed of the search is an important criterion.
- Distributed Architecture: The index is distributed across different physical machines, called shards. Copies of individual documents are also created to compensate for the failure of a single machine. This cluster structure allows the performance of the search to be scaled.
- Other Functionalities: Elasticsearch also offers many other functions that help to ensure that search performance is very high. These include, for example, data rollups or index lifecycle management.
- Business Analytics: The components already described offer, among other things, the possibility to visualize and process the index or the processed data. This offers a holistic approach.
What Advantages does Elasticsearch offer over other Search Engines?
The first factor is that Elasticsearch is open source and can therefore be implemented completely free of charge. Costs may be incurred if external help is needed for the implementation. Other search engine providers, including Google, offer free versions of their search engines, but these then often contain advertising, which can only be canceled by a paid version.
A second important point is that the composition of the index is very flexible and you can freely determine which elements are to be found in the full-text search and which are not. This is also a unique selling point compared to other search providers.
Finally, the ELK stack also offers the possibility of being able to view the search holistically, from the collection of data, through the processing, to the finished search. This component, too, is rather sought in vain in other search engines and therefore explains the spread of Elasticsearch.
What are the Disadvantages of Elasticsearch?
Despite the immense benefits of Elastic’s search algorithm, there are also some issues that should be considered and weighed before implementation:
- Search is not compatible with all store systems and infrastructures.
- With self-hosted servers, implementing Elasticsearch can become very costly and complicated.
- The distribution of the index over an entire cluster offers advantages in terms of scaling, but can also quickly become a disadvantage. This is the case if too many so-called primary shards are used and the index is thus distributed over many machines. As a result, all of these machines must become active when a new document is indexed, which leads to a high load on the system just for indexing.
- What does the future of search engines look like?
The future of search engines looks promising, as advances in artificial intelligence and machine learning have the potential to significantly improve the quality and relevance of search results. Here are some key developments to watch out for:
- Personalization: search engines will increasingly tailor search results to individual users based on their preferences, search history, and behavior.
- Voice search: the rise of voice assistants like Siri, Alexa, and Google Assistant is changing the way people interact with search engines. Expect more natural language queries and personalized responses.
- Visual search: As image recognition technology continues to improve, visual search capabilities will become more sophisticated. Users will be able to search for products and information simply by taking a photo.
- AI-enabled search: Machine Learning algorithms will be increasingly used to understand user intent and deliver more relevant results. Natural language processing and semantic search will also play a greater role.
- Augmented Reality: search engines may soon be integrated with augmented reality technologies to provide a more immersive and interactive search experience.
In addition, advances in Conversational AI, such as ChatGPT or the commonly used Voice Searches, indicate that users no longer expect a static search engine, but rather want to discuss questions and concerns in a conversation. In this respect, it remains exciting to observe how this feature will be implemented and what impact it will have on websites, for example.

Overall, the future of search engines is about delivering faster, more personalized, and more relevant results to users, leveraging the latest advances in artificial intelligence and other cutting-edge technologies.
This is what you should take with you
- Elasticsearch is a popular full-text search for various applications.
- The basic principle is to index the data and thus make it easier and faster for the search algorithm to find.
- This search algorithm is characterized, among other things, by the speed of the process and by the fact that the index can be divided into a computer cluster and is therefore scalable.

What is a Boltzmann Machine?
Unlocking the Power of Boltzmann Machines: From Theory to Applications in Deep Learning. Explore their role in AI.

What is the Gini Impurity?
Explore Gini impurity: A crucial metric shaping decision trees in machine learning.

What is the Hessian Matrix?
Explore the Hessian matrix: its math, applications in optimization & machine learning, and real-world significance.

What is Early Stopping?
Master the art of Early Stopping: Prevent overfitting, save resources, and optimize your machine learning models.

What is RMSprop?
Master RMSprop optimization for neural networks. Explore RMSprop, math, applications, and hyperparameters in deep learning.

What is the Conjugate Gradient?
Explore Conjugate Gradient: Algorithm Description, Variants, Applications and Limitations.
Other Articles on the Topic of Elasticsearch
Much of the information from this article comes from the following sources:
- Elasticsearch B.V. (2022, June 13). What is Elasticsearch?. https://www.elastic.co/de/what-is/elasticsearch
- Recast IT (2022, June 15). Elasticsearch. https://www.recast-it.com/themen/elasticsearch/

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.