The Extract, Transform, Load process (short: ETL) describes the steps between collecting data from various sources to the point where it can finally be stored in a data warehouse solution. When large amounts of data are to be visualized, the individual stages come into play.
What is ETL?
Companies and organizations are faced with the challenge of having to deal with ever-larger volumes of data. This information also comes from many different systems with their own data structures and logic. This data should be stored as uniformly as possible in a central data warehouse in order to be available for data mining or data analytics.
For this information to be reliable and resilient, it must be pulled from the various source systems, prepared, and then loaded into a target system. All of this happens in the ETL process.
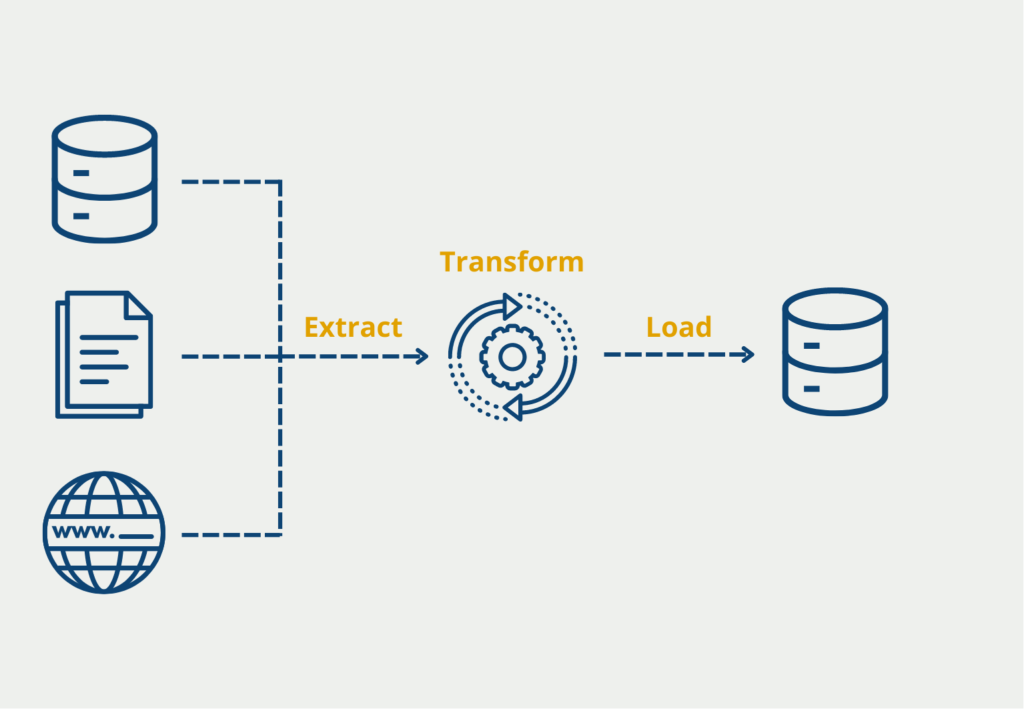
What are the ETL Process Steps?
To better understand the Extract, Transform, Load process, it is worthwhile to look at the individual phases in detail:
ETL Extract
Extraction is the process step in which data is retrieved from various sources and stored centrally. In this step, among other things, data quality checks are performed to ensure a clean state in the data warehouse. These checks can include, for example, matching the data type or looking for missing values. For example, checks could be made to see if all items that represent a price are also marked in USD. If the data has gross quality defects, it can also be rejected at this stage. If there are no or only a few deficiencies, the data is passed to the next stage, where the necessary changes are made.
The Extract step involves loading information from a wide variety of sources. These include, among others:
ETL Transform
In this stage, all data is transformed into a structure that matches the data model of the data warehouse or the application. If there are still data quality problems, these are now processed. This includes, for example, filling in missing values or correcting errors. In addition, basic calculations are already made here with which the data can be summarized or prepared. This could include, for example, that the turnover is already aggregated on a daily basis and not each order is saved individually if this is required.
ETL Load
The data we prepared in the previous steps can now be loaded into the data warehouse or the target database. If there is already older information of the same type there, this must be supplemented accordingly or even exchanged. This is often done using a unique ID or by entering the time at which the information was saved. In this way, the data can be compared and the obsolete information can be specifically deleted.
How is ETL used in business intelligence applications?
Business Intelligence (BI) is the process of transforming raw data into meaningful insights to support strategic decision-making within an organization. ETL plays a pivotal role in enabling effective BI by providing the necessary data integration, transformation, and loading capabilities. Below are some key applications of ETL in Business Intelligence:
- Data Integration: ETL serves as the backbone of BI by integrating data from various sources, including databases, spreadsheets, applications, and cloud services. Data integration ensures that all relevant information is gathered in a central data repository, allowing business analysts and decision-makers to access a comprehensive and unified view of the organization’s data.
- Data Cleansing and Validation: BI heavily relies on accurate and reliable data. ETL processes include data cleansing and validation steps, where data inconsistencies, errors, and duplicates are identified and rectified. By ensuring data quality, ETL helps maintain the integrity of BI reports and dashboards, leading to more trustworthy insights and analysis.
- Historical Data Loading: BI often requires analyzing historical data to identify trends, patterns, and long-term performance indicators. ETL allows the loading of historical data into data warehouses or data marts, enabling BI tools to access this information for retrospective analysis and trend identification.
- Real-time Data Streaming: In certain BI scenarios, real-time data is essential for timely decision-making. ETL can be designed to accommodate real-time data streaming, where data is extracted, transformed, and loaded into the BI system continuously or at regular intervals. This ensures that the BI reports and dashboards display the most current information, enabling agile and responsive decision-making.
- Incremental Data Loading: ETL provides the capability to perform incremental data loading, where only new or updated data is extracted and loaded into the BI system. This approach reduces the processing time and resource consumption, as only the changes since the last data update are considered, allowing for more frequent updates of the BI data.
In conclusion, ETL plays a vital role in Business Intelligence by facilitating data integration, cleansing, and validation, historical and real-time data loading, incremental data updates, data aggregation, multi-dimensional data modeling, and data governance. With the help of ETL, BI applications can deliver accurate, reliable, and actionable insights that empower organizations to make informed decisions and gain a competitive advantage in today’s data-driven business landscape.
What are the advantages of ETL?
ETL is a crucial process in modern data management, enabling organizations to collect, manipulate, and integrate data from various sources into a central data repository. This data integration approach offers numerous advantages that empower businesses to make data-driven decisions, enhance operational efficiency, and gain a competitive edge. Below are some key advantages of ETL:
- Data Integration and Consolidation: ETL allows organizations to extract data from heterogeneous sources, such as databases, spreadsheets, web services, and cloud applications, and transform it into a unified, standardized format. By consolidating data from multiple sources, businesses can eliminate data silos and gain a holistic view of their operations, leading to better insights and informed decision-making.
- Improved Data Quality: Data quality is critical for making accurate and reliable decisions. The Transform phase in ETL allows data cleansing, enrichment, and validation. It ensures that erroneous, duplicate, or incomplete data is identified and corrected, resulting in higher data quality. Clean and consistent data enhances the trustworthiness of analytics and reporting, reducing the risk of making faulty business choices.
- Efficient Data Processing: ETL processes are designed to handle large volumes of data efficiently. By optimizing data extraction and transformation tasks, ETL tools can significantly reduce the time required to process vast amounts of information. This efficiency enables businesses to update their data repositories more frequently, ensuring that decisions are based on up-to-date information.
- Enhanced Business Intelligence: ETL serves as a backbone for business intelligence (BI) initiatives. By integrating disparate data sources, ETL pipelines create a comprehensive data warehouse that BI tools can query to generate meaningful insights and visualizations. The availability of reliable, integrated data accelerates the BI process and enables users to analyze trends, patterns, and performance indicators with ease.
- Scalability and Flexibility: As businesses grow, the volume and variety of data they handle also increase. ETL provides the flexibility to adapt to changing data requirements, allowing organizations to incorporate new data sources and scale their data processing capabilities as needed. This adaptability ensures that the data infrastructure can keep pace with business expansion and evolving data needs.
- Regulatory Compliance and Data Security: Many industries must adhere to strict regulations concerning data privacy and security. ETL enables data cleansing and masking, which ensures that sensitive information is protected before being stored in the data warehouse. By controlling access and implementing data governance policies during the ETL process, organizations can maintain compliance with regulatory standards and protect sensitive data.
- Time and Cost Savings: By automating data integration and transformation tasks, ETL processes reduce the time and effort required to manage data manually. This automation leads to significant cost savings, as it reduces the need for manual data entry and minimizes the risk of human errors in data handling.
In conclusion, ETL is a fundamental process that offers numerous advantages to organizations seeking to harness the power of data-driven decision-making. By providing data integration, improved data quality, efficient processing, enhanced business intelligence, scalability, and compliance adherence, ETL lays the groundwork for robust data management, aiding businesses in achieving their goals and staying competitive in a data-centric world.
What are the challenges of ETL?
The ETL stages pose the greatest possible challenge when many and very different systems and their data are to be migrated. Then it is not uncommon that the data models are completely different and a lot of work must go into their transformation.
Otherwise, the transformation step is also very costly if the data quality has deficiencies that must first be corrected. In some applications, missing values cannot be prevented at all and must still be handled accordingly. For example, if we have measurement data in a production line that measures components on the assembly line, but maintenance was performed between May 30, 2021, and June 1, 2021, and thus no data was collected during this period. Accordingly, we are missing part length measurements for all records during this period. We could now either disregard the records from the period or, for example, replace the missing fields with the average of the measurements from the days immediately before and after.
ETL vs. ELT
The ETL process has already been established for several years and decades. However, the amount of data that accumulates in many applications has also increased significantly over the same period. Therefore, it would be a very expensive matter to structure all the resulting data directly and store it in a data warehouse. Instead, in most cases, unstructured data is first stored in a so-called data lake. There, the data is stored in its raw format until it is needed for a specific application.
For this, the ETL process was modified to the so-called ELT process. As the arrangement of the letters already indicates, the first step in filling a data lake is the “load” step. In the data lake, the data is still unstructured, unsorted, and not corrected.

As soon as this information is required for a specific use case and the target data format has been defined, the “transform” process takes place in which the data is prepared. Hadoop, for example, can be used as the technology for the data lake.
Are there other methods for data integration?
In addition to ETL and ELT, there are other frequently used options for data penetration. The choice always depends heavily on the specific use case and priorities. A selection of methods for data exchange and data integration are:
- ETL (Extract, Transform, Load): This is a process of extracting data from various sources, transforming it into an easy-to-analyze format, and then loading it into a target system.
- ELT (Extract, Load, Transform): Similar to ETL, but the transformation occurs after the data is loaded into the target system.
- Data Virtualization: In this method, a virtual layer is created between the data sources and the target system. The virtual layer allows the target system to access data from multiple sources without the need for physical integration. In plain language, this means that the user does not recognize that he is accessing different sources, but the data does not have to be transported from the source system.
- Data Federation: In this method, data from multiple sources is integrated by creating a virtual database that contains all the data from different sources.
- Data Replication: This method replicates data from multiple sources into a single target system.
- Master Data Management (MDM): This is a method of creating a master database with common data elements that can be shared among multiple systems.
- Application Programming Interfaces (APIs): APIs allow different systems to communicate with each other and exchange data.
- Change Data Capture (CDC): In this method, data changes are captured and recorded in real time so that systems can always work with the most current data.
How to find the right ETL tool?
Today, many free and paid tools can be found on the Internet that can be used to organize data integration in a company. With this sheer mass of options, one needs various criteria against which the tools can be neutrally compared and evaluated. The following points can help in many cases to find the right tool for the application:
- Budget: The cost of ETL tools can range from a few Euros to half a fortune. It must be determined how much money one is willing to spend on the solution. It is also important to consider that some require a one-time payment and other solutions are paid monthly.
- Initial Situation: The concrete tasks and accruing data volumes must be considered neutrally to determine how powerful the solution must be and what storage volumes are required. Consideration should also be given to how the situation will develop in the medium term.
- Human Resources: When selecting a suitable ETL tool, it should also be determined which people will use the program and to what extent. If one has trained personnel capable of adapting the program to individual needs, another tool can be chosen. Otherwise, it should rather be an easy-to-use solution that can best be used directly. Likewise, the question arises whether the existing personnel can already work with the programming language that the ETL tool uses. If not, expensive external consultants will have to be used, which in turn will have an impact on the budget.
- Compatibilities: Another important issue is which data sources should be connected to the system. Not all solutions offer suitable connectors for all database solutions. Thus, this is also an important selection criterion.
What Programs are available for ETL?
In the following, we present a small selection of ETL tools that have already established themselves and are positively highlighted in many similar articles. Furthermore, all presented programs are either completely free or offer the possibility to do a free trial.
IBM DataStage
This is a data integration tool designed specifically for enterprises. It offers the possibility to run through the classic ETL process as well as to build ELT pipelines. The execution of the pipelines is parallelized and offers automatic load balancing to further improve performance.
Like most tools, there are existing connectors for many databases and programs that do not necessarily have to be from IBM directly. The tool is also particularly useful if the data is to be used for downstream AI services.
Apache Hadoop
This open-source solution is quasi-standard for many Big Data applications and can also be used for extract-transform-load pipelines. It offers advantages especially when large amounts of unstructured data are to be processed and transported. Performance can be increased through the distributed computing cluster.
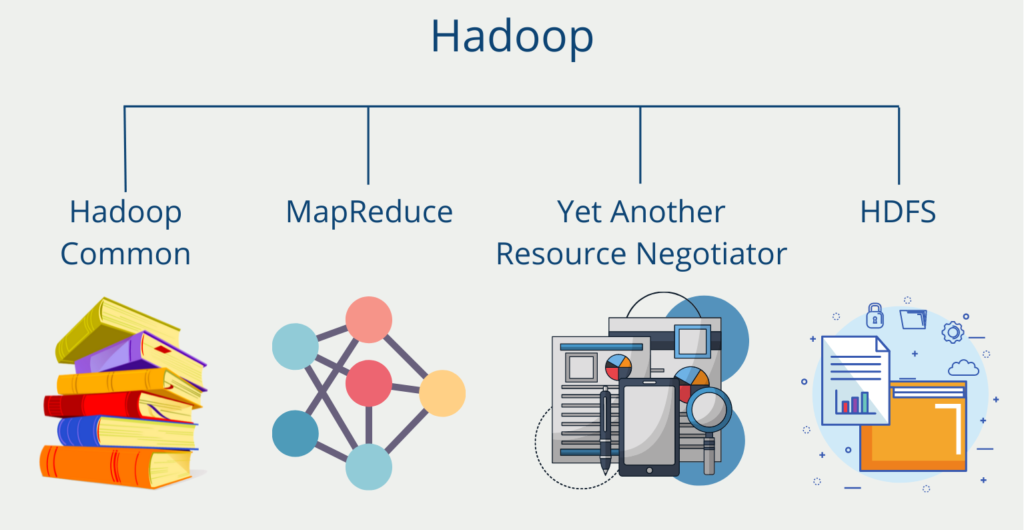
It also offers many integrations from various platforms and strong built-in features, such as the Hadoop Distributed File System or the MapReduce algorithm.
Hevo Pipeline
Hevo provides a powerful framework for working with ETL and ELT pipelines. Compared to previous programs, it also stands out for its simple front end, which allows many users to set up data pipelines within minutes. This is especially an advantage compared to Hadoop, as even untrained personnel can operate the program.
In addition, more than 150 different data sources can already be connected, including SaaS programs or databases with change data capturing. This basis is constantly being expanded in order to be able to establish a smooth plug-and-play with many databases. Furthermore, users also like customer service, which can help quickly and competently with potential problems.
This is what you should take with you
- ETL contains important process steps for collecting data from different systems, preparing it, and storing it in a target system.
- The individual stages ensure that the information is aligned with the data model and that certain quality standards are met.
- ETL is primarily used when data is to be stored in a data warehouse or displayed in BI applications.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of ETL
- Here you will find a comparison of popular ETL tools that automate many of the steps described.
- Otherwise, many basic ETL steps can also be done within Python. You can find some basic commands in our related section.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.