An algorithm includes finitely many steps to solve a given task. If the sequence of these operations is followed, the task will be solved subsequently in any case and the same results will always be delivered. Algorithms are widely used, especially in mathematics and computer science, because they can be used to solve complex problems easily and repeatedly.
How is the term defined?
We encounter algorithms in more and more areas of everyday life. Although the term is primarily at home in computer science and mathematics, we also encounter the simplest algorithms in everyday life. The hand-washing instructions which have been posted on many public sinks since the Corona pandemic are also an example.
For everyday use, the algorithm can therefore be understood as a fixed sequence of steps or work instructions, the execution of which leads to the desired result, namely in this case clean and hygienic hands. In even more general terms, they define procedures by which input values (dirty hands) can be transformed into fixed output values (clean/hygienic hands).
In computer science, however, this general definition is not sufficient. An algorithm is a finite set of steps whose execution leads to the solution of a predefined problem. If it is executed several times, it always delivers the same result.
Furthermore, an algorithm is well-defined if it contains only unambiguous instructions that can be executed exactly as they are. For example, a step of the hand washing instructions could be “Wash your hands under the stream of water.” This step is not well-defined because the execution is not clear from it. For example, questions such as “For how long do the hands need to be washed?” or “How strong should the water jet be for this?” still arise.
What are the Properties of an Algorithm?
The following properties are indicative:
- Unambiguity: The descriptions and steps must be unambiguous.
- Executability: All steps must be executable if the previous steps were executed correctly.
- Finiteness: Finiteness means that there is a finite set of steps to be executed.
- Termination: Termination means that the algorithm reaches a result after a certain amount of time. Termination and finiteness are mutually dependent. So by the finiteness of the steps, the function must be forced to an end.
- Determinacy: Given the same circumstances, the process steps always lead to the same result.
- Determinism: At each time of the execution there is exactly one unique subsequent step, which must be executed. This property is also a prerequisite for determinacy. If there were a selection of possible subsequent steps, there could not be an unambiguous result.
What are some examples?
- Navigation Device: The route description of a navigation device contains many successive steps that eventually lead to the entered destination. It thus satisfies all the properties of algorithms.
- Game Roboters: When computers learn games, such as chess or Go, they in many cases adhere to predefined sequences of steps. These have been programmed so that they are simply executed when a certain situation is recognized.
- Mathematics: Mathematical functions also represent predefined sequences of steps, since they specify a precise sequence of how to get from an input value to an output value.
- Traffic Lights: The switching times of traffic lights are also determined by clear instructions. Depending on the time or the measured traffic density, the traffic light switches from red to green and vice versa.
What are the key concepts of an algorithm?
In the realm of problem-solving strategies, algorithms bring structure and precision. To gauge their effectiveness and make informed choices, we rely on three critical concepts: time complexity, space complexity, and algorithmic efficiency.
1. Time Complexity:
- Time complexity quantifies the duration an algorithm requires to accomplish a task, typically measured in basic operations executed as a function of input size. This concept reveals how an algorithm’s execution time scales with increasing input size, enabling us to categorize their efficiency.
2. Space Complexity:
- Space complexity evaluates the memory or storage space an algorithm consumes while solving a problem. It’s expressed as a function of input size and helps us grasp an algorithm’s memory usage as the problem’s scale grows.
3. Algorithmic Efficiency:
- Algorithmic efficiency embodies a broader perspective, encompassing both time and space complexities. An efficient algorithm strikes a balance between minimizing time and space demands while ensuring accurate results. Achieving algorithmic efficiency is a fundamental aim in problem-solving because it optimizes computations for speed and resource utilization.
Efficiency holds the key when selecting strategies. In choosing the most suitable approach, it’s vital to consider the interplay between time and space complexities. A faster solution might consume more memory, while a memory-efficient one may take longer to execute. The choice hinges on the problem at hand, the available resources, and the desired performance.
Comprehending these pivotal concepts empowers us to evaluate and compare strategies effectively. It equips us with the discernment needed to design and select strategies to tackle an array of computational challenges, spanning data organization, intricate analysis, and optimization dilemmas.
What are the common algorithms used in computer science?
Common algorithms are used in practice in a variety of fields such as computer science, engineering, statistics, etc. Some of the most commonly used are:
- Sorting: Sorting processes are used to arrange a list of data in a particular order. Some of the most common sorting algorithms include bubble sort, insertion sort, selection sort, merge sort, and quicksort.
- Search: Search processes are used to find a specific value or element in a list of data. The most commonly used ones include linear search, binary search, and interpolation search.
- Graph: Graph algorithms are used to analyze and process graphs, which are structures consisting of nodes and edges. The most commonly used ones include the one defined by Dijkstra for finding the shortest paths, the one by Kruskal for minimum spanning trees, and Floyd-Warshall’s algorithm for shortest paths for all pairs.
- Machine Learning: Machine learning algorithms are used in artificial intelligence to automatically improve performance based on data. The most commonly used ones include linear regression, logistic regression, decision trees, and neural networks.
- Compression: These are used to reduce the size of data for efficient storage and transmission. The most commonly used include Huffman coding, Lempel-Ziv-Welch (LZW) algorithm, and run-length coding.
- Encryption: Encryption processes are used to secure data and protect it from unauthorized access. The most commonly used encryption algorithms include Advanced Encryption Standard (AES), Rivest-Shamir-Adleman (RSA) encryption, and Blowfish.
- Hashing: Hashing algorithms are used to map data of arbitrary size to fixed-size values. The most commonly used ones include MD5, SHA-1, and SHA-256.
These and many other algorithms are used in various applications such as web search engines, image and video processing, data analysis, networking, security, etc. If programmers and data scientists understand the basics of these, they can design and implement efficient and effective software solutions.
How are Machine Learning and Algorithms related?
As we have already learned, these are defined process chains that always achieve the same result with the same inputs. In the field of Machine Learning, it is therefore often referred to as algorithms that are capable of learning complex relationships.
For the grouping of data points, the so-called k-means clustering is often used. Here, different cluster centers are tested in a finite set of steps until sooner or later the perfect assignment in groups is learned. So this is actually an algorithm.
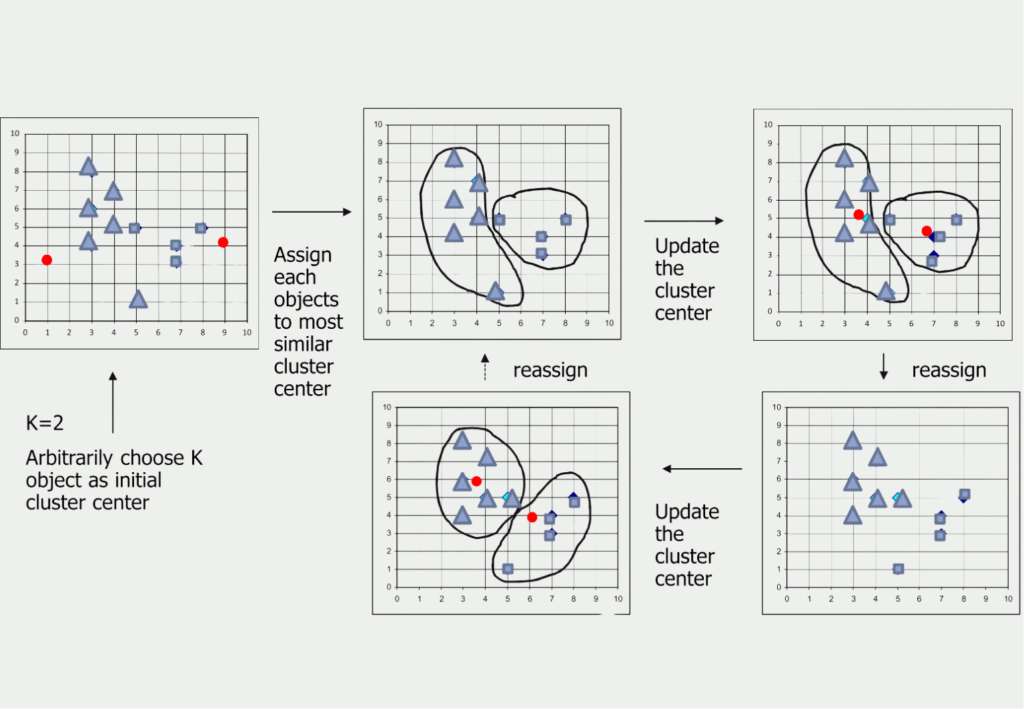
Such a unique mapping is also given for other Machine Learning algorithms, such as the Decision Tree or the Support Vector Machines.
In the field of deep learning, however, this assignment is not quite so obvious. In the case of neural networks, two training runs with the same data sets can lead to different results. This would actually speak against an assignment to the algorithms. However, this is mainly due to the initialization of the network during which, for example, the weights of the individual neurons are randomly assigned. If among other things, it is ensured that the weights are the same in two training runs, the results of the networks would also be the same. Thus, deep learning models also count as algorithms.
Are algorithms fair?
Algorithmic bias and fairness have become increasingly important topics in recent years as more and more decisions are made by them. The bias occurs when an algorithm produces results that systematically and unfairly discriminate against certain groups of people based on race, gender, age, or other characteristics.
One of the biggest concerns is that it can perpetuate and even exacerbate existing social inequalities. For example, if such a system is used in hiring decisions and is biased against women or minorities, it can lead to a perpetuation of a lack of diversity in the workplace.
To address it, it is important to understand how it can occur. One common cause of bias is biased training data. If the data used to train an algorithm is biased, it will reflect that bias in its results. This is especially true of Machine Learning algorithms, which learn from historical data.
Another cause of bias is the assumptions made by the developers. If the developers have implicit biases, those biases can be reflected in the process steps.
To mitigate the bias, several approaches can be taken. One approach is to use diverse training data that accurately reflects the diversity of the population. Another approach is to design code that is explicitly fair, such as those that use statistical methods to ensure that decisions are not based on protected characteristics.
It is important to note that while algorithms can be designed to be fair, there is no single definition of fairness. Different groups may have different views on what constitutes fair decision-making, and it is important to consider those perspectives when designing these systems.
In conclusion, algorithmic bias and fairness are critical considerations that impact people’s lives. By being aware of the potential for bias and taking steps to mitigate it, we can create systems that are more equitable and just.
What are algorithmic challenges?
In the realm of algorithms, certain challenges have gained iconic status due to their complexity and real-world relevance. Two such challenges are the Traveling Salesman Problem and the Knapsack Problem, each presenting unique problem-solving opportunities and applications.
The Traveling Salesman Problem (TSP):
The Traveling Salesman Problem is a classic optimization puzzle that poses the question: “Given a list of cities and the distances between each pair of cities, what is the shortest possible route that visits each city exactly once and returns to the starting city?” In its core, TSP seeks to find the most efficient path to minimize the travel distance while visiting all destinations. Despite its seemingly simple premise, solving TSP efficiently becomes increasingly difficult as the number of cities grows.
Applications of TSP:
- Logistics and Route Planning: TSP is integral in logistics for planning optimal routes for delivery and transportation services, saving time and resources.
- Manufacturing: TSP helps in designing efficient assembly lines and optimizing tool paths in manufacturing.
- VLSI Design: Large-scale integration (VLSI) design employs TSP to reduce wiring costs and layout complexity on semiconductor chips.
- Circuit Board Drilling: Minimizing drilling time and tool wear in the fabrication of circuit boards is another application of TSP.
The Knapsack Problem:
The Knapsack Problem is a classic combinatorial optimization dilemma that asks: “Given a set of items, each with a weight and a value, determine the most valuable combination of items that can be packed into a knapsack with a fixed capacity.” This problem revolves around the idea of choosing the right items to maximize the total value while staying within a constraint, which could be the weight limit of a backpack, for example.
Applications of the Knapsack Problem:
- Resource Allocation: The Knapsack Problem finds applications in various fields, such as finance for portfolio optimization and project management for resource allocation.
- Data Compression: In data compression algorithms, the Knapsack Problem is used to select a subset of data for efficient storage or transmission.
- Cryptography: Cryptographic systems like the Merkle-Hellman Knapsack Cryptosystem utilize this problem for secure encryption.
- Retail and Inventory Management: Retailers employ variants of the Knapsack Problem to optimize stock replenishment and inventory management.
These algorithmic challenges have captivated the minds of mathematicians and computer scientists for decades, and while they are often used for educational purposes, their practical applications continue to shape various industries. Solving them efficiently has real-world implications, from optimizing delivery routes to managing resources and enhancing data storage and security.
This is what you should take with you
- An algorithm includes finitely many steps to solve a given task.
- If the sequence of these workflows is followed, the task will be solved subsequently in any case and the same results will always be delivered.
- We encounter algorithms very often in everyday life, such as in navigation devices or traffic lights.
Machine learning models are also among them.

What is Collaborative Filtering?
Unlock personalized recommendations with collaborative filtering. Discover how this powerful technique enhances user experiences. Learn more!

What is Quantum Computing?
Dive into the quantum revolution with our article of quantum computing. Uncover the future of computation and its transformative potential.

What is Anomaly Detection?
Discover effective anomaly detection techniques in data analysis. Detect outliers and unusual patterns for improved insights. Learn more now!

What is the T5-Model?
Unlocking Text Generation: Discover the Power of T5 Model for Advanced NLP Tasks - Learn Implementation and Benefits.


What is MLOps?
Discover the world of MLOps and learn how it revolutionizes machine learning deployments. Explore key concepts and best practices.
Other Articles on the Topic of Algorithms
On Wikipedia, there is a detailed article on the topic.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.