Correlation refers to the relationship between two statistical variables. The two variables are then dependent on each other and change together. A positive correlation of two variables, therefore, means that an increase in A also leads to an increase in B. The association is undirected. It is therefore also true in the reverse case and an increase in variable B also changes the slope of A to the same extent.
Causation, on the other hand, describes a cause-effect relationship between two variables. Causation between A and B, therefore, means that the increase in A is also the cause of the increase in B. The difference quickly becomes clear with a simple example:
A study could likely find a positive correlation between a person’s risk of skin cancer and the number of times they visit the outdoor pool. So if a person visits the outdoor pool frequently, their risk of developing skin cancer also increases. A clear positive association. But is there also a causal effect between outdoor swimming pool visits and skin cancer? Probably not, because that would mean that only outdoor swimming pool visits are the cause of the increased risk of skin cancer.
It is much more likely that people who spend more time in outdoor swimming pools are also exposed to significantly more sunlight. If they do not take sufficient precautions with sunscreen or similar, more sunburns can occur, which increases the risk of skin cancer. The correlation between outdoor swimming pool visits and skin cancer risk is not causal.
A variety of curious correlations that very likely do not show causation can be found at tylervigen.com.
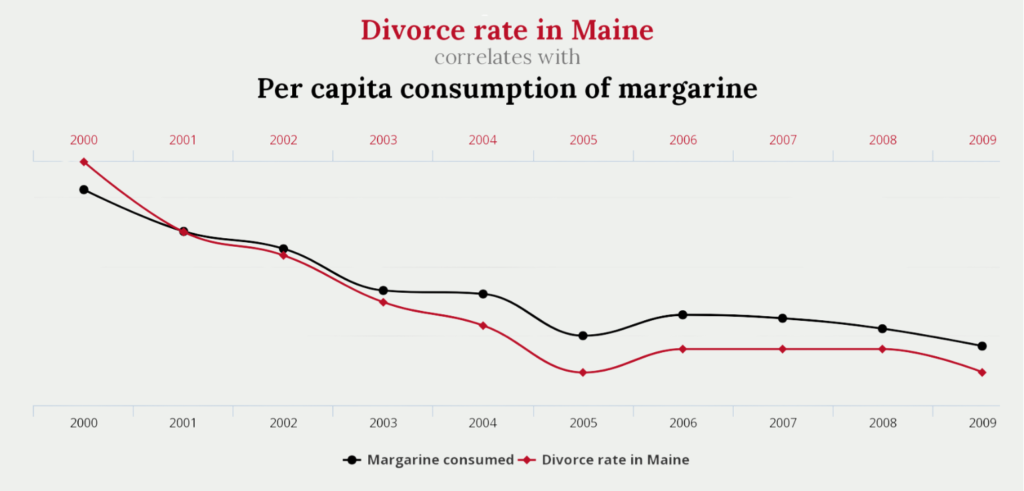
For example, there is a very high association between the divorce rate in the American state of Maine and the per capita consumption of margarine. Whether this is also causation can be doubted.
What are the Types of Correlation?
In general, two types of contexts can be distinguished:
- Linear or Non-Linear: The dependencies are linear if the changes in variable A always trigger a change with a constant factor in variable B. If this is not the case, the dependency is said to be non-linear. For example, there is a linear correlation between height and body weight. With every new centimeter of height gained, one is very likely to also gain a fixed amount of body weight, as long as one’s stature does not change. A non-linear relationship exists, for example, between the development of sales and the development of a company’s share price. With a 30% increase in sales, the stock price may increase by 10%, but with the subsequent 30% increase in sales, the stock price may only increase by 5%.
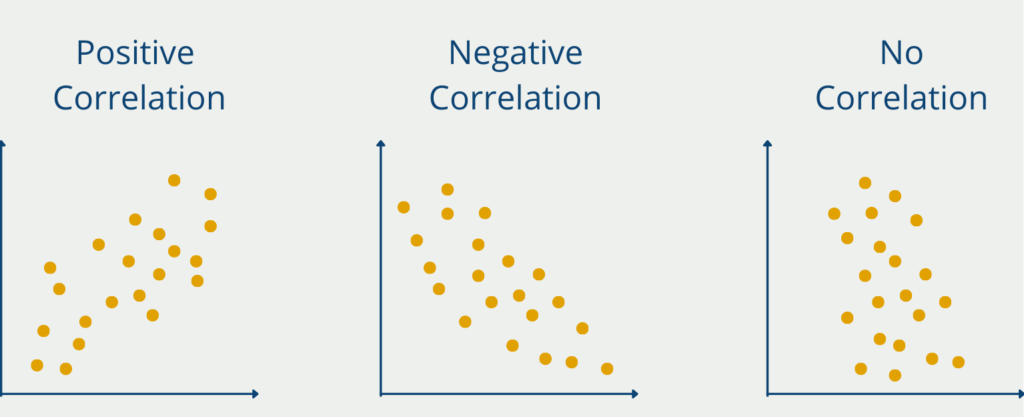
- Positive or Negative: If the increase in variable A leads to an increase in variable B, then there is a positive correlation. If, on the other hand, the increase in A leads to a decrease in B, then the dependency is negative.
How is the Pearson correlation calculated?
The Pearson correlation coefficient is most commonly used to measure the strength of the correlation between two variables. It can be easily calculated using the following values:
- Calculating the mean value for both variables
- Calculation of the standard deviations
- Deviation from the mean: The respective deviation from the mean must be calculated for each element of the two variables.
- Multiplying the deviations: Element by element, the deviations are then multiplied together and this is added up for all elements of the data sets.
- Divide by standard deviation: This calculation is then divided by the product of the two standard deviations and the number of data records, which is reduced by one.
\(\) \[r = \frac{ \sum_{i \in D}(x_{i} – \text{mean}(x)) \cdot (y_{i} – \text{mean}(y))}{(n-1) \cdot SD(x) \cdot SD(y)}\]
where:
- Σ represents across all observations in the datasets.
- xi and yi are the individual observations for variables x and y.
- mean(x) and mean(y) are the mean values for variables x and y.
- SD(x) and SD(y) are the individual standard deviations.
- n is the number of observations and n-1 correspondingly the number reduced by one.
What is the (Pearson) Correlation Coefficient and how is it interpreted?
The Correlation Coefficient indicates how strong the association between the two variables is. In the example of tylervigen.com, this correlation is very strong at 99.26% and means that the two variables move almost 1 to 1, i.e. an increase in the consumption of Margarine by 10% also leads to an increase in the divorce rate by 10%. This is illustrated in the screenshot above, as margarine consumption and the divorce rate decrease almost in parallel. This shows that a decrease in margarine consumption also leads to a decrease in the divorce rate.
The coefficient can also assume negative values. A coefficient smaller than 0 describes the Anti-Correlation and states that the two variables behave in opposite ways. For example, a negative association exists between current age and remaining life expectancy. The older a person gets, the shorter his or her remaining life expectancy.
What Correlation Coefficients are there?
Correlation is a fundamental concept in statistics that measures and quantifies the relationship between two variables. It not only shows the direction of the relationship but also determines the factor of how strongly the change in one variable leads to a change in the other variable. Depending on the relationship between the variables, there are various ways of calculating the specific correlation coefficient. In this section, we will take a closer look at the three widely used methods for calculating the correlation.
Pearson Coefficient
The Pearson correlation is most commonly used to quantify the strength of the linear relationship between two variables. However, it can only be used if it is assumed that the two variables are linearly dependent on each other and are also metrically scaled, i.e. have numerical values.
If these assumptions are made, the Pearson correlation can be calculated using this formula
\(\) \[r_{xy} = \frac{\sum (X_i – \overline{X})(Y_i – \overline{Y})}{\sqrt{\sum (X_i – \overline{X})^2} \sqrt{\sum (Y_i – \overline{Y})^2}} \]
Here, \(X_i\) and \(Y_i\) are the values of the two variables, and \(\overline{X}\) and \(\overline{Y}\) are the mean values of the variables. In addition, this formula can also be rewritten so that it uses the standard deviation in the denominator:
\(\) \[r = \frac{ \sum_{i \in D}(x_{i} – \text{mean}(x)) \cdot (y_{i} – \text{mean}(y))}{(n-1) \cdot SD(x) \cdot SD(y)}\]
The resulting values are then between -1 and 1, with positive values indicating a positive correlation and negative values indicating a negative correlation.
Spearman Coefficient
The Spearman correlation extends the assumptions of the Pearson correlation and generally examines the monotonic relationship between two variables without assuming a linear relationship. More generally, it examines whether a change in one variable leads to a change in the other variable, even if this relationship does not have to be linear. This makes it suitable not only for data sets with non-linear dependencies, but also so-called ordinal data, i.e. data sets in which only the order of the data points plays an important role, but not the exact distance.
The formula for the Spearman correlation is also largely based on this ranking. The data sets are first sorted according to the first variable and then according to the second variable. For both rankings, the ranks are numbered consecutively starting with 1 for the lowest value. The difference between the rank for the first variable and the rank for the second variable is then calculated for each data point:
\(\) \[ d_i = \text{Rank}(X_i) − \text{Rank}(Y_i) \]
The Spearman coefficient is then calculated using the following formula, where \(d\) is the explained difference for each data point and \(n\) is the number of data points in the dataset.
\(\) \[\rho = 1 – \frac{6 \sum d_i^2}{n(n^2 – 1)} \]
Kendall-Tau Coefficient
The Kendall-Tau correlation is another method for determining a correlation coefficient. Similar to the Spearman correlation, it can quantify non-linear relationships between the data and works on the ordinal relationships between the data. Compared to the Spearman correlation, it is particularly suitable for smaller data sets and captures the strength of the relationship somewhat more accurately.
The Kendall-Tau coefficient always looks at pairs of data points and distinguishes between concordant and discordant pairs. A concordant pair of data points is given if a pair of observations \((x_i, y_i)\) and \((x_j, y_j)\) match in the ranking of both variables. It must therefore apply that if \((x_i > y_i)\), then \((x_j > y_j)\) also applies. However, if the ranking does not match, then the pair is considered discordant.
The formula for calculating the Kendall-Tau coefficient is then obtained using the following formula:
\(\) \[\tau = \frac{(\text{Number of concordant Pairs}) – (\text{Number of discordant Pairs})}{\frac{1}{2}n(n-1)}\]
These are the most frequently used coefficients for calculating the correlation between two variables. The specific choice must be made depending on the data and the underlying application.
What problems are there when investigating correlation and causality?
When researching the relationships between two variables, it is important to bear in mind the problems that frequently occur to avoid misinterpretations or false results.
A classic mistake here is to infer causality from a correlation. A correlation simply describes a relationship between two variables which means that a change in one variable leads to a change in the other variable. This may or may not mean causality. To prove perfect causality, additional evidence is required, which can be obtained through randomized experiments and is usually very time-consuming.
Another problem can be reverse causality, where the direction of causality is misinterpreted. In such a case, the assumed effect of the causality may be the cause of the causality. The example described of the supposed causality between ice cream consumption and skin cancer is a reverse causality, as the supposed cause, namely the consumption of ice cream, is also an effect.
When examining the correlation, confounding variables should be considered in order to obtain correct figures for the correlation. Confounding variables are third variables that have an influence on both the cause and the effect. If these are not taken into account, this can lead to distorted correlation coefficients. A multivariate analysis that takes more than two variables into account can provide a remedy.
Not quite as well known as the problems mentioned so far is the post-hoc fallacy, in which causality is wrongly assumed because there is a temporal sequence between events. Just because one event follows another does not necessarily mean that there is an effect. There may be other reasons that lead to this observed relationship.
Simpson’s paradox occurs when the data is divided into several groups and a correlation is observed between the groups. The paradox describes the fact that this correlation reverses or even disappears when these groups are combined. Therefore, the effects of group assignments should be taken into account in the analysis, as these can influence the correlation between variables.
The ecological fallacy is the error of concluding individuals based on correlations found at the group level. Such predictions should generally be cautious, as statistical conclusions about individuals often lead to false assumptions.
Another common pitfall is the omission of variables, also known as omitted variable bias. Incorrect calculations of the correlation coefficient can occur if important variables that show a relationship are omitted. Therefore, all factors that are measurable and related to the research should always be considered before the analysis. If these are omitted, the results may simply be incorrect.
These problems should be known before setting up a study or experiment in order to avoid these errors and obtain meaningful data.
How do you prove Causation?
To reliably prove causation, scientific experiments are conducted. In these experiments, people or test objects are divided into groups (you can read more about how this happens in our article about Sampling), so that in the best case all characteristics of the participants are similar or identical except for the characteristic that is assumed to be the cause.
For the “skin cancer outdoor swimming pool case”, this means that we try to form two groups in which both groups of participants have similar or preferably even the same characteristics, such as age, gender, physical health, and exposure to sunlight per week. Now it is examined whether the outdoor swimming pool visits of one group (note: the exposed sun exposure must remain constant), changes the skin cancer risk compared to the group that did not go to the outdoor swimming pool. If this change exceeds a certain level, one can speak of causation.
Why are experiments important to prove causation?
Real causality can only be found and proven with the help of so-called randomized controlled trials (RCTs for short). Here are some important reasons why these experiments are essential for proving causation:
- Control: Only in an experiment possible confounding factors that influence the outcome variables can be controlled for. In a study, participants are randomly assigned to a so-called treatment and control group. Only the treatment group is then exposed to the influencing variable to determine causality. This ensures that the effects were only caused by the influencing variable and are not based on differences between the groups.
- Replication: Due to the precise description of the experiment, RCTs can be easily replicated by other researchers. This makes it possible to investigate whether the same or similar results are obtained when the experiment is repeated, which in turn increases the robustness of the results and underlines their generalizability.
- Accuracy: Only in experiments are all possible confounding variables measured, as far as this is possible, which maximizes the accuracy of the results.
- Ethical considerations: To avoid unethical decisions and false conclusions, causal relationships should not be based solely on observational studies. This can lead to false prejudices.
- Political implications: In many cases, policy decisions are based on causal relationships. To avoid serious legislative changes or bans being based solely on correlations, these should instead be confirmed in independent and meaningful experiments.
- Scientific progress: RCTs can lead to new scientific findings that can be understood and interpreted by other researchers. Experiments are used to test hypotheses and make new suggestions that can change and improve our entire lives.
In conclusion, it can be summarized that experiments and especially RCTs are essential to prove causation and calculate its strength. Particularly in areas such as medicine, psychology, and economics, such studies lead to significantly better results and reliable figures. Observational studies, on the other hand, are important for making assumptions or formulating initial hypotheses, but their significance is significantly lower.
This is what you should take with you
- Only in very few cases does a correlation also imply causation.
- Correlation means that two variables always change together. Causation, on the other hand, means that the change in one variable is the cause of the change in the other.
- The correlation coefficient indicates the strength of the association. It can be either positive or negative. If the coefficient is negative, it is called anticorrelation.
- To prove a causal effect one needs complex experiments.

What is Gibbs Sampling?
Explore Gibbs sampling: Learn its applications, implementation, and how it's used in real-world data analysis.

What is a Bias?
Unveiling Bias: Exploring its Impact and Mitigating Measures. Understand, recognize, and address bias in this insightful guide.

What is the Variance?
Explore variance's role in statistics and data analysis. Understand how it measures data dispersion.

What is the Kullback-Leibler Divergence?
Explore Kullback-Leibler Divergence, a vital metric in information theory and machine learning, and its applications.

What is the Maximum Likelihood Estimation?
Unlocking insights: Understand Maximum Likelihood Estimation (MLE), a potent statistical tool for parameter estimation and data modeling.

What is the Variance Inflation Factor (VIF)?
Learn how Variance Inflation Factor (VIF) detects multicollinearity in regression models for better data analysis.
Other Articles on the Topic of Correlation and Causation
- Detailed definitions of the terms can be found here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.