Hyperparameter Tuning beschreibt einen entscheidenden Schritt beim Training von Machine Learning Modelle, um die Leistung zu optimieren. Als Hyperparameter werden Merkmale bezeichnet, die vor dem Modelltraining festgelegt werden und die nicht aus den Daten erlernbar sind. Das Hyperparameter Tuning beschreibt den Prozess, diese Parameter für ein bestimmtes Modell und Datensatz anzupassen. In diesem Beitrag schauen wir uns die verschiedenen Arten von Hyperparametern genauer an und wie sie am besten auf das Modell angepasst werden können.
Was sind die verschiedenen Arten von Hyperparametern?
Die Hyperparameter eines Machine Leraning Modells müssen vor dem Trainingsstart festgelegt werden und können nicht, wie beispielsweise die Gewichtungen von Neuronen, aus dem Datensatz erlernt werden. Jedoch haben die Parameter einen enormen Einfluss auf die Leistung des Modells, weshalb es so wichtig ist, die richtigen Werte zu finden, um ein optimales Modell zu trainieren. Abhängig von der Modellart und der Architektur werden verschiedene Hyperparameter unterschieden:
- Lernrate: Dieser Wert bezeichnet die Schrittgröße mit der sich das Modell im Lauf des Trainings auf das Minimum der Verlustfunktion hinbewegt. Dieser Parameter hat entscheidenden Einfluss darauf, wie schnell das Modell lernt und ob es möglicherweise über das Minimum hinaus schießt.
- Regularisierung: Verschiede Regularisierungsparameter, wie zum Beispiel L1 oder L2, sorgen dafür, dass der Verlustfunktion ein Straftermin hinzugefügt wird, um Overfitting zu verhindern.
- Anzahl der Hidden Layers und Neuronen: Innerhalb eines neuronalen Netzes bestimmen diese Hyperparameter über die Architektur des Modells und haben damit einen zentralen Einfluss auf die Leistung des Modells. Über die Komplexität wird dadurch auch die Trainingszeit und Ressourcenmenge gesteuert.
- Dropout-Rate: Beim Dropout in neuronalen Netzen wird ein bestimmter Prozentsatz der Neuronen während eines Trainingsdurchlaufs zufällig überspringen. Dadurch kann eine Überanpassung verhindert werden, da das Modell lernt, sich nicht nur auf einzelne Neuronen zu verlassen. Die Dropout-Rate legt die Anzahl der Neuronen fest, die in jeder Iteration auf inaktiv gesetzt werden.
- Batchsize: Diese Größe bestimmt die Anzahl der Datenpunkte, die in jeder Trainingsiteration verwendet werden. Eine kleine Batchsize ermöglicht ein einfacheres Training und möglicherweise schnellere Anpassungen, während eine große Batchsize dafür sorgt, dass diese eine bessere Repräsentation der Stichprobe darstellen.
- Anzahl der Epochen: Dieser Hyperparameter bestimmt darüber, wie viele Durchläufe ein Modell trainiert. Ein längeres Modelltraining führt zu einer besseren Leistung, jedoch kann es auch zu einer Überanpassung kommen.
Warum ist Hyperparameter Tuning beim maschinellen Lernen wichtig?
Das Hyperparameter Tuning ist ein wesentlicher Schritt in jedem Modelltraining und beinhaltet verschiedene Prozesse, um die optimalen Werte für das Modell und den Datensatz zu finden. Da die Werte nicht während des Trainings erlernt werden können, benötigt es dafür oft verschiedene, unabhängige Modelltrainings, die dann anschließend miteinander verglichen werden können. Das Hyperparameter Tuning hat einen entscheidenden Einfluss auf die Leistung eines Modells und sollte deshalb unbedingt durchgeführt werden.
Durch die richtige Einstellung der Hyperparameter kann die bestmögliche Leistung eines Modells erzielt werden. Das bedeutet nicht nur, dass die Genauigkeit des Modells möglichst hoch ist, sondern auch, dass das Modell ausreichend komplex ist, um die zugrundeliegende Struktur in den Daten zu verstehen und abzubilden. Somit wird die Generalisierungsfähigkeit weiter erhöht. Außerdem haben die Hyperparameter einen entscheidenden Einfluss auf die Länge des Training, durch die Festlegung der Anzahl der Epochen, und auf die Modellkomplexität. Ein geeignetes Hyperparameter Tuning kann deshalb auch dazu führen, dass man die Trainingszeit und den Ressourcenbedarf optimieren kann. Dies ist vor allem bei aufwändigem Training und knappen Ressourcen, wie Zeit oder Rechenleistung, ein entscheidender Vorteil.
Welche Techniken werden zur Abstimmung der Hyperparameter verwendet?
In vielen Fällen ist nicht nur die Anzahl der Hyperparameter groß, sondern auch der Parameterraum an möglichen Werten. Deshalb benötigt man definierte Algorithmen, die bei der Wahl der optimalen Parameter unterstützen. In der Praxis können verschiedene Methoden genutzt werden, am häufigsten kommen jedoch die folgenden Techniken zum Einsatz.
- Grid Search: Bei dieser rechenintensiven Methode werden alle möglichen Kombinationen an Hyperparametern ausprobiert, um die beste zu finden. Dieses Vorgehen ist nicht nur rechenintensiv, sondern kann auch bei manchen Modellarchitekturen, wie beispielsweise Neuronalen Netzen, nicht wirklich möglich sein, aufgrund der großen Zahl an Kombinationen. Jedoch ist bei der Grid Search sichergestellt, dass die optimalsten Werte gefunden werden.
- Random Search: Dieser Ansatz nimmt nach dem Zufallsprinzip Stichproben aus dem verfügbaren Parameterbereich und nutzt diese für das Modelltraining. Bei einer großen Zahl an Hyperparametern wird dadurch der Rechenaufwand deutlich reduziert. Trotzdem bietet die Random Search noch eine umfassende Suche und ist deshalb oft die bessere Wahl im Vergleich zur Grid Search.
- Bayes’sche Optimierung: Die Bayes’sche Optimierung ist im Vergleich zu den zuvor vorgestellten Methoden eine fortschrittlichere Optimierungstechnik. Dabei wird ein probabilistisches Modell verwendet, um die Leistung des Modells bei einem bestimmten Satz von Hyperparametern vorherzusagen. Dieser Satz wird dann verwendet, um das ursprüngliche Modell zu trainieren und die Ergebnisse dieses Trainings werden an die Bayes’sche Optimierung zurückgespielt. Anhand dieser Werte wird dann das nächste, optimale Set an Hyperparametern ausgewählt.
- Gradientenbasierte Optimierung: Diese Optimierung basiert auf dem Prinzip des Gradientenabstiegs und wendet diesen Ansatz auf die Hyperparameter an. Dabei wird der Gradient der Verlustfunktion in Bezug auf die Hyperparameter betrachtet, was zwar meist sehr rechenintensiv ist, dafür aber eine schnelle Konvergenz und deutlich verbesserte Leistung ermöglicht.
- Evolutionäre Algorithmen: Diese Optimierungsalgorithmen sind durch den Prozess der natürlichen Selektion inspiriert und basieren auf der Idee, dass man eine Population aus möglichen Lösungen erstellt und im Laufe der Zeit diese Population weiterentwickelt. Die Weiterentwicklung findet dabei durch verschiedene genetische Operationen, wie Mutation, Crossover oder Selektion statt. Bei komplexen Optimierungsproblemen bietet sich dieser Ansatz an, da die Evolution der Parameter mit mehreren Zielen umgehen kann.
Die Wahl der richtigen Technik hängt von vielen verschiedenen Faktoren ab, wie beispielsweise der Zahl der Hyperparameter oder den verfügbaren Rechenressourcen.
Was sind die Herausforderungen beim Hyperparameter Tuning?
Das Hyperparameter Tuning beschreibt den Prozess, die optimalen Hyperparameter für ein Modell und einen Datensatz zu finden. Da diese Hyperparameter nicht aus den Daten heraus erlernt werden können, müssen sie gesetzt werden und durch verschiedene Trainingsiterationen hinweg beurteilt und verglichen werden. Dieser Prozess kann vor allem bei komplexen Modellen oder großen Datensätzen sehr zeit- und rechenintensiv sein. Deshalb muss man hierfür eine geeignete Strategie haben und gezielte Werte testen.
Eine zusätzliche Herausforderung beim Hyperparameter Tuning besteht darin sicherzustellen, dass das Modell nicht overfitted. Beim Overfitting ist das Modell zu sehr an den Trainingsdatensatz angepasst und liefert nur schlechte allgemeine Vorhersagen auf dem Testdatensatz. Mithilfe der Hyperparameter kann sichergestellt werden, dass das Risiko für Overfitting verringert wird, indem beispielsweise das Modell weniger komplex wird. Jedoch muss hierbei ein gutes Gleichgewicht gefunden werden, da falsches Hyperparameter Tuning auch zu einem höheren Risiko für Overfitting führen kann.
Für den Prozess der Hyperparameteroptimierung gibt es keinen einheitlichen Prozess, der immer erfolgsvorsprechend ist. Vielmehr benötigt man ein gutes Verständnis für das zu lösende Problem und den Datensatz, um die richtigen Parameter auszuwählen. Deshalb sollte auch im Projektplan immer genügend Zeit für das Hyperparameter Tuning einkalkuliert werden, um nicht in Zeitnot zu geraten.
Vor allem komplexe Modelle stellen noch eine weitere Herausforderung dar, da sie oft hochdimensional sind und somit viele verschiedene Parameter haben, deren Bereiche auch mitunter sehr groß sind. Neben diesen vielen Möglichkeiten der Parametersetzung ergibt sich hier auch das Problem, dass die Hyperparameter nicht unabhängig voneinander sind, sodass die Änderungen eines Wertes Auswirkungen auf andere Werte haben kann. Außerdem ist es auch oft nicht realistisch, dass man den perfekten Parametersatz findet, da einfach die Menge an Möglichkeiten zu groß ist. Deshalb sollte man eine gezielte Vorgehensweise wählen, um sicherzustellen, dass man die Tests der Hyperparameter sinnvoll einsetzt.
Das Hyperparameter Tuning ist ein wichtiger Teilschritt beim Training eines Machine Learning Modells. Es hat jedoch viele Herausforderungen, wie beispielsweise das Risiko einer Überanpassung oder die Erforschung großer, hochdimensionaler Räume.
Wie verwendet man die Cross Validation beim Hyperparameter Tuning?
Die Kreuzvalidierung ist eine bekannte Technik im Bereich des Machine Learning und hilft zu verstehen, wie gut ein Modell auf ungesehene Daten reagiert. Sie kann genauso auch für das Hyperparameter Tuning verwendet werden, um verschiedene Parametereinstellungen zu testen und zu vergleichen. Die Cross Validation nutzt eine sogenannte Resampling-Technik bei der der Datensatz in mehrere Teilmengen unterteilt wird. Die verbreiteste Umsetzung ist dabei die k-fold Cross Validation, bei der insgesamt k Teilmengen gebildet werden. Dabei wird in jeder Iteration eine andere Menge als Validierungsdatensatz genutzt, um eine unabhängige Aussage über die Leistung des Modells treffen zu können.
In vielen Fällen wird dafür der folgende Prozess genutzt:
- Partitionierung der Daten: Der Datensatz wird als erstes in die gleich großen Teilmengen gesplittet. Diese fungieren während dem Trainings entweder als Trainings- oder Validierungssatz. Die unterschiedlichen Validierungssätze können dann genutzt werden, um die Modellleistung unabhängig bewerten und vergleichen zu können.
- Auswahl von Hyperparametern: Vor dem Training wird ein Satz an Hyperparametern festgelegt, der in dieser Iteration getestet werden soll.
- Bewertung der Leistung: Nachdem das Modell mit den festgelegten Hyperparametern trainiert wurde, wird eine Leistungsmetrik gewählt und für den Validierungssatz berechnet. Diese Kennzahl dient als Indikator, wie gut das trainierte Modell auf neue, ungesehene Daten reagiert.
- Iterieren und Abstimmen: Schritt 2 und Schritt 3 werden anschließend für verschiedene Konfigurationen und Hyperparameter wiederholt. Dieser Prozess ermöglicht es, dass verschiedene Hyperparametereinstellungen unabhängig voneinander verglichen werden können.
- Aggregieren der Ergebnisse: Anschließend können die Ergebnisse zusammengefasst werden, um ein optimales Set an Hyperparameter zu bestimmen. Dafür können auch andere Metriken wie die Standardabweichung oder Konfidenzintervalle zu Rate gezogen werden, um die Stabilität und Zuverlässigkeit der gewählten Hyperparameter bewerten zu können.
Es gibt einige Vorteile, die die Kreuzvalidierung im Prozess des Hyperparameter Tunings mit sich bringt:
- Geringere Verzerrung: Dadurch, dass mehrere Foldings für die Evaluierung des Modells genutzt werden, ist die Verzerrung der Ergebnisse deutlich niedriger im Vergleich zu einem Modell, das lediglich mit einem Train/Test-Split trainiert wurde.
- Effiziente Nutzung von Daten: Der verfügbare Datensatz wird bestmöglich genutzt, da unterschiedliche Teilmengen entweder für das Training oder für die Validierung genutzt werden. Dies führt zu einer zuverlässigeren Leistungsabschätzung und es wird sichergestellt, dass auch kleine Datensätze effizient genutzt werden können.
- Bewertung der Generalisierung: Mithilfe der Kreuzvalidierung lässt sich eine robuste Schätzung der Modellleistung auf ungesehenen Daten abgeben. Dadurch kann beurteilt werden, ob die gewählten Hyperparameter zu guten Ergebnissen führen.
Abschließend ist es auch wichtig zu erwähnen, dass für die Abstimmung der Hyperparameter lediglich der Trainings- und Validierungssatz genutzt werden sollte, nicht aber der Testdatensatz. Dieser sollte für die endgültige Bewertung des Modells aufgehoben werden und nicht Teil des Trainingsprozesses werden. Auch deshalb ist die Kreuvalidierung ein robustes Tool für das Einstellen von Hyperparametern und das Training eines robusten Modells.
Welche Tools und Bibliotheken werden für das Hyperparameter Tuning verwendet?
Das Hyperparameter Tuning ist ein entscheidender Schritt beim Training von Machine Learning Modellen. In den vorherigen Kapiteln, wurden bereits einige Ansätze für ein erfolgreiches Hyperparameter Tuning vorgestellt. Nun wollen wir uns genauer mit den Tools und Python Bibliotheken beschäftigen, die dafür genutzt werden können.
- GridSearchCV: Dieses Modul aus der Scikit-Learn Bibliothek führt mit einfachen Befehlen eine Grid Search aus. Der Parameterraum und die Hyperparameter müssen vor der Suche definiert werden und anschließend hilft das Modul die richtigen Hyperparameter für ein bestimmtes Modell zu finden.
- RandomizedSearchCV: Diese Funktion stammt auch aus Scikit-Learn und ermöglicht eine RandomSearch auf einem vorher definierten Parameterraum. Für den Nutzer ist die Anwendung vergleichbar zu der GridSearch, jedoch werden mit der RandomSearch meist deutlich schneller die optimalen Hyperparameter gefunden.
- Bayes’sche Optimierung: Für die Bayes’sche Optimierung wird die speziellere Bibliothek skopt (kurz für scikit-optimize) genutzt, die eine Funktion dafür bietet. Damit lässt sich das aufwendige Verfahren der Bayes’schen Optimierung einfach umsetzen.
- Hyperopt: Hierbei handelt es sich um eine spezielle Python-Bibliothek zum Hyperparameter Tuning. Diese verfügt über Methoden zur Parallelisierung und kann mit anderen Machine Learning Bibliotheken kombiniert werden.
- Keras Tuner: Die Optimierungsbibliothek von Keras ist eine beliebte Wahl für verschiedenste Deep Learning Anwendungen. Sie bietet die gängigsten Suchalgorithmen, wie GridSearch oder Random Search, sowie vielen verschiedenen fortschrittlicheren Methoden.
Dies ist nur eine kleine Auswahl, die für das Hyperparameter Tuning verwendet werden können. Die konkrete Wahl hängt von verschiedensten Parametern, wie dem Modell oder den verfügbaren Ressourcen ab.
Wie wird Hyperparameter Tuning in realen Beispielen durchgeführt?
In diesem Kapitel stellen wir zwei konkrete Fallstudien vor, die demonstrieren, wie man Hyperparameter Tuning in der Anwendung nutzen kann.
- Fallstudie: Gradient Boosting für Regression
Datensatz: Wohnungspreise in Kalifornien
Zielsetzung: Optimieren der Leistung des Gradient Boosting Regressors
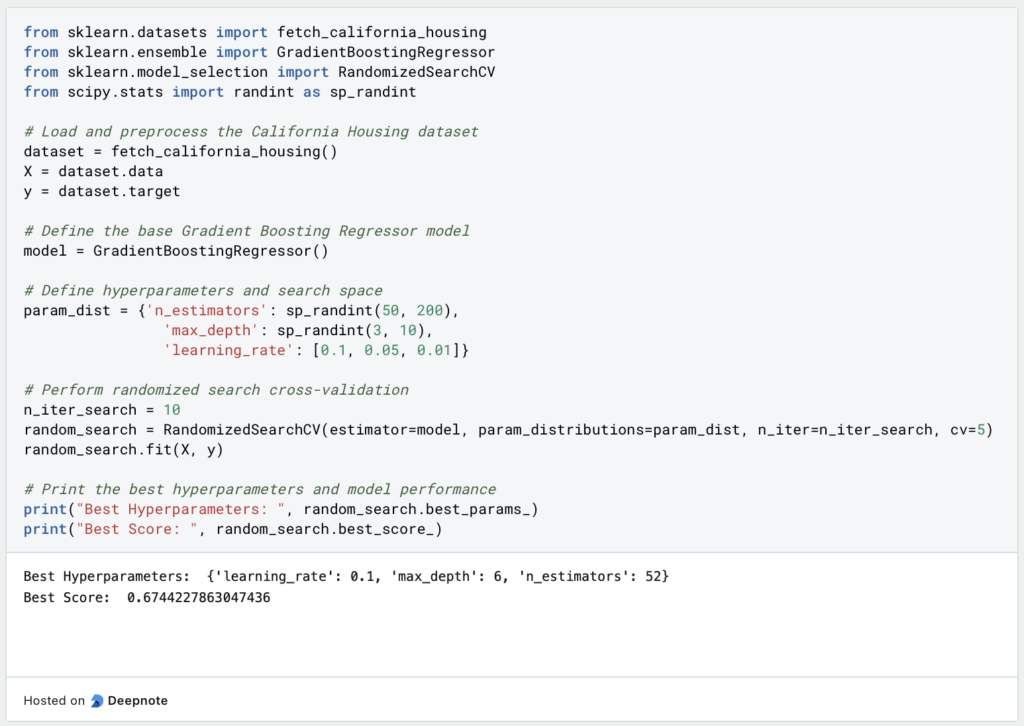
Diese Fallstudie beschäftigt sich mit dem “California Housing Prices” Datensatz und versucht eine Regression zu erlernen, um den Hauspreis anhand verschiedener Inputs richtig vorherzusagen. Dafür wird ein Gradient Boosting Regressor aus Scikit-Learn genutzt. Mithilfe der Random Search werden die optimalen Parameter für die Anzahl der Schätzer, die Lernrate und die maximale Tiefe gesucht. Für die Evaluierung des Modells und der Hyperparameter greift das Beispiel auf die Cross-Validation zurück und vergleicht die R-Squared Kennzahl der verschiedenen Modelle.
- Fallstudie: Klassifizierung mit Support-Vektor-Maschinen (SVM)
Datensatz: Brustkrebs Wisconsin
Zielsetzung: Optimierung der SVM-Leistung für die Klassifizierung von Brustkrebs mit

In diesem Beispiel wird der “Breast Cancer Wisconsin” Datensatz verwendet, um mithilfe einer Support Vector Machine richtige Klassifizierungen von Brustkrebspatienten zu machen. Bevor mit dem Training gestartet werden kann, wird der Datensatz mithilfe des StandardScalers auf eine einheitliche Skala gebracht. Anschließend wird die Grid Search und die Cross Validation genutzt, um die besten Hyperparameter zu finden. Konkrete werden die Werte für den Regularisierungsparameter C, den Kerneltyp und den Gammawert gesucht.
Durch die einfache Anwendung und Implementierung von Hyperparameter Tuning in Python wird es den Nutzern ermöglicht die Leistung ihrer Modelle zu verbessern und die optimale Modellarchitektur zu finden.
Das solltest Du mitnehmen
- Das Hyperparameter Tuning ist ein wichtiger, oft unterschätzter, Schritt beim Training von Machine Learning Modellen, der die Leistung des Modells optimieren kann.
- Je nach Modellart und Architektur gibt es verschiedene Hyperparameter, die genutzt werden können.
- Klassische Methoden für das Hyperparameter Tuning sind die Random Search oder die Bayes’sche Optimierung.
- In Python gibt es viele Tools und Bibliotheken, die bei der Wahl der richtigen Hyperparameter helfen können.

Was ist die Random Search?
Optimieren Sie Modelle für maschinelles Lernen: Lernen Sie, wie die Random Search Hyperparameter effektiv abstimmt.

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.

Was ist der Omitted Variable Bias?
Verständnis des Omitted Variable Bias: Ursachen, Konsequenzen und Prävention. Erfahren Sie, wie Sie diese Falle vermeiden.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.
Andere Beiträge zum Thema Hyperparameter Tuning
Google hat einen interessanten Artikel über Hyperparameter Tuning, den Du hier finden kannst.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.