Hyperparameter tuning describes a crucial step in the training of machine learning models to optimize performance. Hyperparameters are features that are defined before model training and cannot be learned from the data. Hyperparameter tuning describes the process of adapting these parameters for a specific model and dataset. In this article, we take a closer look at the different types of hyperparameters and how they can best be adapted to the model.
What are the different types of hyperparameters?
The hyperparameters of a machine learning model must be set before training starts and cannot be learned from the dataset like the weights of neurons, for example. However, the parameters have an enormous influence on the performance of the model, which is why it is so important to find the right values to train an optimal model. Depending on the model type and architecture, different hyperparameters are distinguished:
- Learning rate: This value describes the step size with which the model moves towards the minimum of the loss function during training. This parameter has a decisive influence on how quickly the model learns and whether it possibly overshoots the minimum.
- Regularization: Different regularization parameters, such as L1 or L2, ensure that a penalty term is added to the loss function to prevent overfitting.
- Number of hidden layers and neurons: Within a neural network, these hyperparameters determine the architecture of the model and therefore have a central influence on the performance of the model. The complexity also controls the training time and amount of resources.
- Dropout rate: With dropout in neural networks, a certain percentage of neurons are randomly skipped during a training run. This can prevent overfitting as the model learns not to rely solely on individual neurons. The dropout rate determines the number of neurons that are set to inactive in each iteration.
- Batch size: This determines the number of data points used in each training iteration. A small batch size allows for easier training and potentially faster adjustments, while a large batch size ensures that these are a better representation of the sample.
- Number of epochs: This hyperparameter determines how many runs a model trains. Longer model training leads to better performance, but it can also lead to overfitting.
Why is hyperparameter tuning important in machine learning?
Hyperparameter tuning is an essential step in any model training and involves various processes to find the optimal values for the model and the dataset. As the values cannot be learned during training, this often requires different, independent model training, which can then be compared with each other. Hyperparameter tuning has a decisive influence on the performance of a model and should therefore be carried out without fail.
The best possible performance of a model can be achieved by setting the hyperparameters correctly. This not only means that the accuracy of the model is as high as possible, but also that the model is sufficiently complex to understand and map the underlying structure in the data. This further increases the generalization capability. In addition, the hyperparameters have a decisive influence on the length of the training, by determining the number of epochs, and on the model complexity. A suitable hyperparameter tuning
Which techniques are used to tune the hyperparameters?
In many cases, not only the number of hyperparameters is large, but also the parameter space of possible values. Defined algorithms are therefore required to help select the optimum parameters. Various methods can be used in practice, but the following techniques are the most commonly used.
- Grid search: In this computationally intensive method, all possible combinations of hyperparameters are tried out to find the best one. This procedure is not only computationally intensive but may also not be possible with some model architectures, such as neural networks, due to the large number of combinations. However, the grid search ensures that the most optimal values are found.
- Random Search: This approach takes random samples from the available parameter range and uses them for model training. With a large number of hyperparameters, this significantly reduces the computational effort. Nevertheless, the random search still offers a comprehensive search and is therefore often the better choice compared to the grid search.
- Bayesian optimization: Bayesian optimization is a more advanced optimization technique compared to the methods presented above. It uses a probabilistic model to predict the performance of the model given a specific set of hyperparameters. This set is then used to train the original model and the results of this training are fed back to the Bayesian optimization. These values are then used to select the next optimal set of hyperparameters.
- Gradient-based optimization: This optimization is based on the principle of gradient descent and applies this approach to the hyperparameters. The gradient of the loss function is considered to be the hyperparameters, which is usually very computationally intensive but enables fast convergence and significantly improved performance.
- Evolutionary algorithms: These optimization algorithms are inspired by the process of natural selection and are based on the idea that you create a population of possible solutions and evolve this population over time. Further development takes place through various genetic operations such as mutation, crossover, or selection. This approach is suitable for complex optimization problems, as the evolution of parameters can handle multiple objectives.
The choice of the right technique depends on many different factors, such as the number of hyperparameters or the available computing resources.
What are the challenges of hyperparameter tuning?
Hyperparameter tuning describes the process of finding the optimal hyperparameters for a model and data set. As these hyperparameters cannot be learned from the data, they must be set assessed, and compared across various training iterations. This process can be very time-consuming and computationally intensive, especially for complex models or large data sets. It is therefore necessary to have a suitable strategy for this and to test specific values.
An additional challenge in hyperparameter tuning is to ensure that the model is not overfitted. When overfitting, the model is too closely adapted to the training data set and only provides poor general predictions on the test data set. The hyperparameters can be used to ensure that the risk of overfitting is reduced, for example by making the model less complex. However, a good balance must be found here, as incorrect hyperparameter tuning can also lead to a higher risk of overfitting.
There is no uniform process for the hyperparameter optimization process that is always promising. Rather, a good understanding of the problem to be solved and the data set is required to select the correct parameters. For this reason, sufficient time should always be allowed in the project plan for hyperparameter tuning so as not to run out of time.
Complex models in particular present a further challenge, as they are often high-dimensional and therefore have many different parameters, the ranges of which are sometimes very large. In addition to these many possibilities for setting parameters, there is also the problem that the hyperparameters are not independent of each other, meaning that changes to one value can have an impact on other values. Furthermore, it is often not realistic to find the perfect parameter set, as the number of possibilities is simply too large. You should therefore choose a targeted approach to ensure that you use the hyperparameter tests sensibly.
Hyperparameter tuning is an important step in the training of a machine learning model. However, it has many challenges, such as the risk of overfitting or exploring large, high-dimensional spaces.
How to use cross-validation in hyperparameter tuning?
Cross-validation is a well-known technique in the field of machine learning and helps to understand how well a model responds to unseen data. It can also be used for hyperparameter tuning to test and compare different parameter settings. Cross-validation uses a so-called resampling technique in which the data set is divided into several subsets. The most common implementation is k-fold cross-validation, in which a total of k subsets are formed. In each iteration, a different set is used as a validation data set to be able to make an independent statement about the performance of the model.
In many cases, the following process is used for this:
- Partitioning the data: The data set is first split into subsets of the same size. These act as either a training or validation set during training. The different validation sets can then be used to independently evaluate and compare the model performance.
- Selection of hyperparameters: Before training, a set of hyperparameters is defined to be tested in this iteration.
- Performance evaluation: After the model has been trained with the specified hyperparameters, a performance metric is selected and calculated for the validation set. This metric serves as an indicator of how well the trained model responds to new, unseen data.
- Iterate and tune: Step 2 and Step 3 are then repeated for different configurations and hyperparameters. This process allows different hyperparameter settings to be compared independently of each other.
- Aggregating the results: The results can then be summarized to determine an optimal set of hyperparameters. Other metrics such as standard deviation or confidence intervals can also be used to assess the stability and reliability of the selected hyperparameters.
There are several advantages that cross-validation brings to the hyperparameter tuning process:
- Reduced bias: By using multiple foldings to evaluate the model, the bias in the results is significantly lower compared to a model that has only been trained with a train/test split.
- Efficient use of data: The available dataset is utilized in the best possible way as different subsets are used for either training or validation. This leads to a more reliable performance estimation and ensures that even small data sets can be used efficiently.
- Evaluation of generalization: Cross-validation can be used to provide a robust estimate of model performance on unseen data. This makes it possible to assess whether the selected hyperparameters lead to good results.
Finally, it is also important to mention that only the training and validation set should be used to tune the hyperparameters, not the test data set. This should be kept for the final evaluation of the model and not become part of the training process. This is another reason why cross-validation is a robust tool for setting hyperparameters and training a robust model.
Which tools and libraries are used for hyperparameter tuning?
Hyperparameter tuning is a crucial step in the training of machine learning models. In the previous chapters, some approaches for successful hyperparameter tuning have already been presented. Now let’s take a closer look at the tools and Python libraries that can be used for this purpose.
- GridSearchCV: This module from the Scikit-Learn library performs a grid search using simple commands. The parameter space and the hyperparameters must be defined before the search and then the module helps to find the correct hyperparameters for a specific model.
- RandomizedSearchCV: This function also comes from Scikit-Learn and enables a RandomSearch on a previously defined parameter space. For the user, the application is comparable to the GridSearch, but the optimal hyperparameters are usually found much faster with the RandomSearch.
- Bayesian optimization: The more specialized library skopt (short for scikit-optimize) is used for Bayesian optimization, which offers a function for this. This makes it easy to implement the complex Bayesian optimization process.
- Hyperopt: This is a special Python library for hyperparameter tuning. It has methods for parallelization and can be combined with other machine learning libraries.
- Keras Tuner: The Keras optimization library is a popular choice for various deep learning applications. It offers the most common search algorithms, such as GridSearch or Random Search, as well as many different more advanced methods.
This is just a small selection that can be used for hyperparameter tuning. The specific choice depends on various parameters, such as the model or the available resources.
How to do Hyperparameter Tuning in real-world examples?
In this chapter, we present two concrete case studies that demonstrate how hyperparameter tuning can be used in the application.
- Case Study: Gradient Boosting for Regression
Dataset: California Housing Prices
Objective: Optimize Gradient Boosting Regressor performance
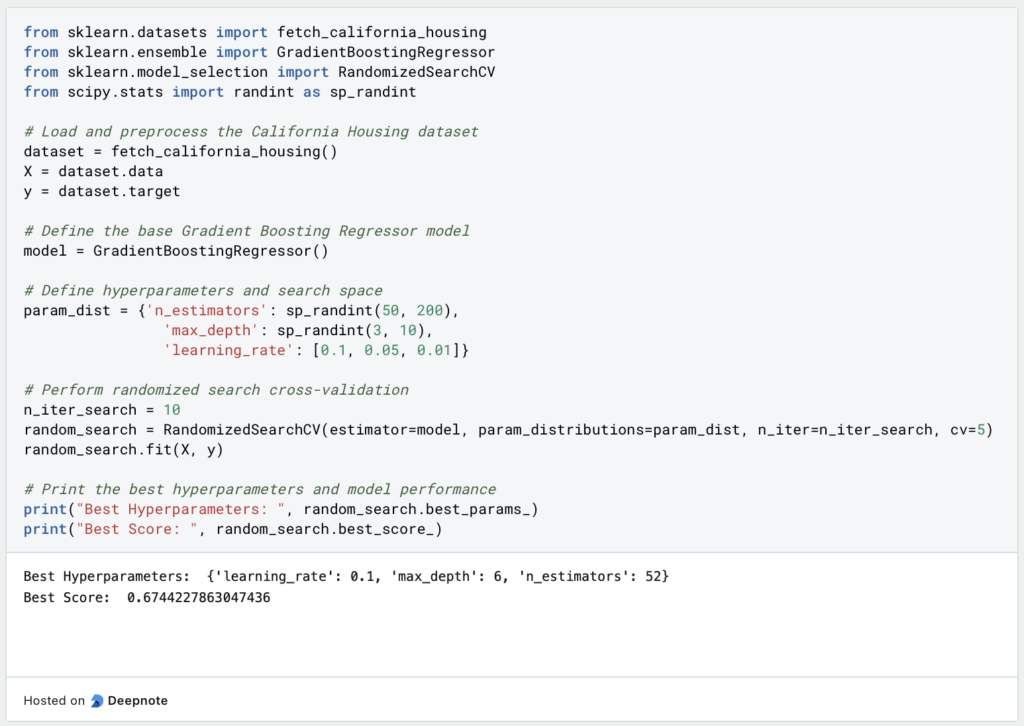
This case study deals with the “California Housing Prices” dataset and tries to learn a regression to correctly predict the house price based on different inputs. A gradient boosting regressor from Scikit-Learn is used for this purpose. Random search is used to find the optimal parameters for the number of estimators, the learning rate and the maximum depth. To evaluate the model and the hyperparameters, the example uses cross-validation and compares the R-Squared key figure of the different models.
2. Case Study: Classification with Support Vector Machines (SVM)
Dataset: Breast Cancer Wisconsin
Objective: Optimize SVM performance for breast cancer classification using

In this example, the “Breast Cancer Wisconsin” dataset is used to make correct classifications of breast cancer patients using a support vector machine. Before training can begin, the data set is brought to a uniform scale using the StandardScaler. Grid search and cross-validation are then used to find the best hyperparameters. Specifically, the values for the regularization parameter C, the kernel type, and the gamma value are searched for.
The simple application and implementation of hyperparameter tuning in Python enables users to improve the performance of their models and find the optimal model architecture.
This is what you should take with you
- Hyperparameter tuning is an important, often underestimated, step in the training of machine learning models that can optimize the performance of the model.
- Depending on the model type and architecture, various hyperparameters can be used.
- Classic methods for hyperparameter tuning are random search or Bayesian optimization.
- There are many tools and libraries in Python that can help you choose the right hyperparameters.

What is Random Search?
Optimize Machine Learning Models: Learn how Random Search fine-tunes hyperparameters effectively.

What is the Lasso Regression?
Explore Lasso regression: a powerful tool for predictive modeling and feature selection in data science. Learn its applications and benefits.

What is the Omitted Variable Bias?
Understanding Omitted Variable Bias: Causes, Consequences, and Prevention in Research." Learn how to avoid this common pitfall.

What is the Adam Optimizer?
Unlock the Potential of Adam Optimizer: Get to know the basucs, the algorithm and how to implement it in Python.

What is One-Shot Learning?
Mastering one shot learning: Techniques for rapid knowledge acquisition and adaptation. Boost AI performance with minimal training data.

What is the Bellman Equation?
Mastering the Bellman Equation: Optimal Decision-Making in AI. Learn its applications & limitations. Dive into dynamic programming!
Other Articles on the Topic of Hyperparameter Tuning
Google has an interesting article on Hyperparameter Tuning that you can find here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.