Die Dropout Layer ist eine Schicht, die beim Aufbau von Neuronalen Netzwerken genutzt wird, um das Overfitting zu verhindern. Dabei werden einzelne Knoten in verschiedenen Trainingsabläufen mithilfe einer Wahrscheinlichkeit ausgeschlossen, so, als ob sie gar nicht Bestandteil der Netzwerkarchitektur wären.
Bevor wir jedoch zu den Details dieser Schicht kommen können, sollten wir erstmal verstehen, wie ein Neuronales Netz funktioniert und wieso es zu Overfitting kommen kann.
Wie funktioniert ein Perceptron?
Das Perceptron ist ein ursprünglich mathematisches Modell und wurde erst später in der Informatik und im Machine Learning genutzt, aufgrund der Eigenschaft komplexe Zusammenhänge erlernen zu können. In der einfachsten Form besteht es aus genau einem sogenannten Neuron, das den Aufbau des menschlichen Gehirns nachahmt.
Das Perceptron hat dabei mehrere Eingänge, die sogenannten Inputs, an denen es numerische Informationen, also Zahlenwerte erhält. Je nach Anwendung kann sich die Zahl der Inputs unterscheiden. Die Eingaben haben verschiedene Gewichte, die angeben, wie einflussreich die Inputs für die schlussendliche Ausgabe sind. Während des Lernprozesses werden die Gewichte so geändert, dass möglichst gute Ergebnisse entstehen.
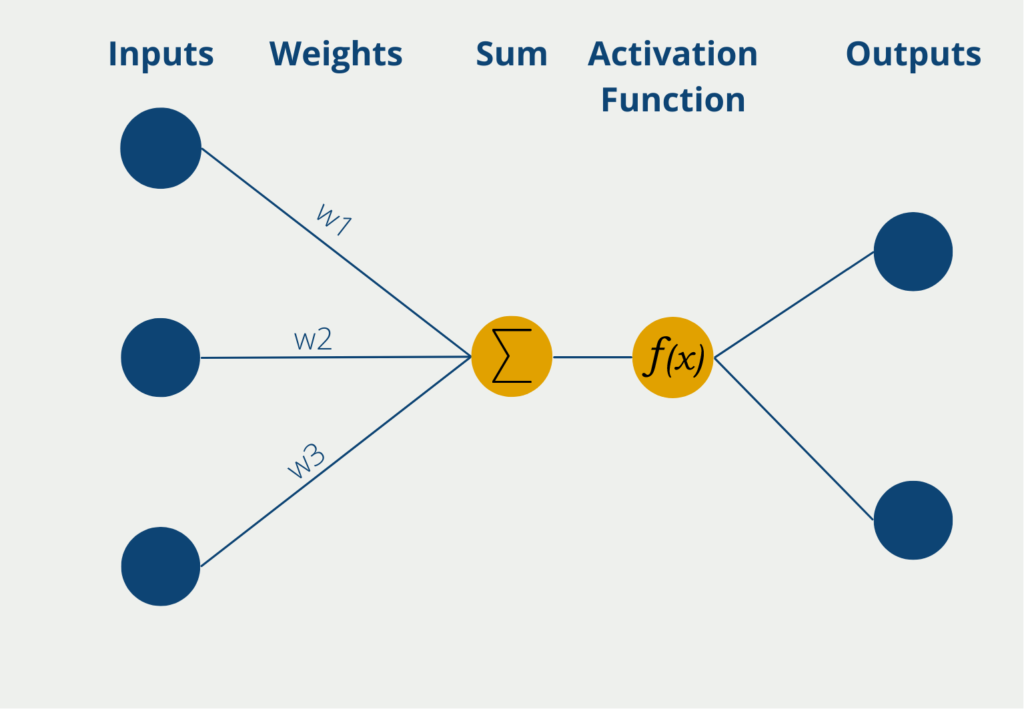
Das Neuron selbst bildet dann die Summe der Inputwerte multipliziert mit den Gewichten der Inputs. Diese gewichtete Summe wird weitergeleitet an die sogenannte Aktivierungsfunktion. In der einfachsten Form eines Neurons gibt es genau zwei Ausgaben, es können also nur binäre Outputs vorhergesagt werden, beispielsweise “Ja” oder “Nein” oder “Aktiv” oder “Inaktiv” etc.
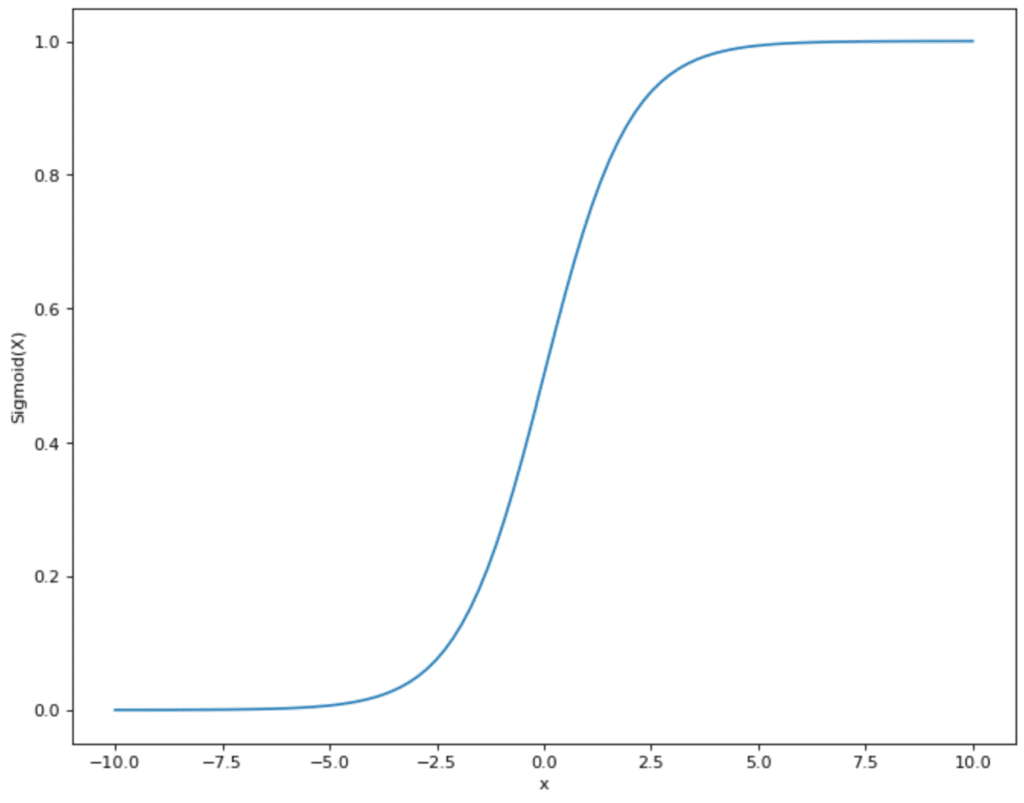
Wenn das Neuron binäre Ausgabewerte hat, wird eine Funktion genutzt, deren Werte auch zwischen 0 und 1 liegen. Ein Beispiel für eine häufig genutzt Aktivierungsfunktion ist die Sigmoid-Funktion. Die Werte der Funktion schwanken zwischen 0 und 1 und nehmen eigentlich auch fast ausschließlich diese Werte an. Ausschließlich bei x = 0 gibt es einen steilen Anstieg und den Sprung von 0 zu 1. Wenn die gewichtete Summe des Perceptrons also x = 0 überschreitet und das Perceptron Sigmoid als Aktivierungsfunktion nutzt, dann ändert sich der Output auch entsprechend von 0 auf 1.
Was ist Overfitting?
Der Begriff Overfitting wird im Zusammenhang mit Vorhersagemodellen genutzt, die zu spezifisch auf den Trainingsdatensatz angepasst sind und dadurch die Streuung der Daten mit erlernen. Dies passiert häufig, wenn das Modell eine zu komplexe Struktur hat für die zugrundeliegenden Daten. Das Problem ist dann, dass das trainierte Modell nur sehr schlecht generalisiert, also nur unzureichende Vorhersagen für neue, ungesehene Daten liefert. Die Performance auf dem Trainingsdatensatz hingegen war sehr gut, weshalb man von einer hohen Modellgüte ausgehen könnte.
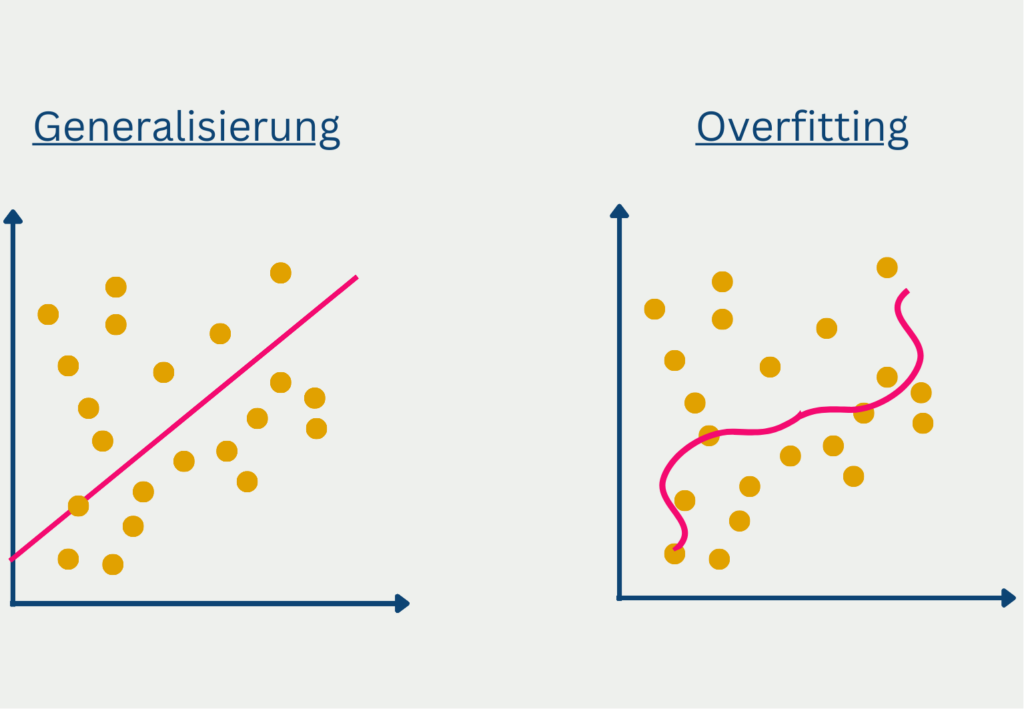
Bei tiefen Neuronalen Netzwerken kann es dazu kommen, dass das komplexe Modell den statistischen Noise des Trainingsdatensatzes erlernt und dadurch gute Ergebnisse im Training liefert. Im Testdatensatz jedoch und vor allem nachher in der Anwendung liegt dieser Noise jedoch nicht mehr vor und deshalb ist die Generalisierung des Modells nur sehr schlecht.
Jedoch wollen wir nicht auf die tiefe und komplexe Architektur des Netzwerkes verzichten, da sich nur so komplexe Zusammenhänge erlernen und somit schwierige Probleme lösen lassen. Vor der Vorstellung der Dropout Layer war dies eine komplizierte Gratwanderung die richtige Architektur zu finden, die noch komplex genug ist für das zugrundeliegende Problem ist, aber auch nicht zum Overfitting neigt.
Wie funktioniert die Dropout Layer?
Beim Dropout werden bestimmte Knoten in einem Trainingsdurchlauf auf den Wert Null gesetzt, also aus dem Netzwerk entfernt. Somit haben sie bei der Vorhersage und auch bei der Backpropagation keinerlei Einfluss. Dadurch wird in jedem Durchlauf eine neue, leicht abgeänderte Netzwerkarchitektur gebaut und das Netzwerk erlernt, auch gute Vorhersagen ohne bestimmte Inputs zu erzeugen.
Beim Einbau der Dropout Layer muss auch eine sogenannte Dropout Wahrscheinlichkeit angegeben werden. Diese legt fest, wie viele der Knoten in der Schicht gleich 0 gesetzt werden. Wenn wir eine Inputschicht mit zehn Eingabewerten haben, bedeutet eine Dropout-Probability von 10 %, dass in jedem Trainingsdurchlauf ein zufälliger Input gleich Null gesetzt wird. Wenn es sich stattdessen um eine Hidden Layer handelt, wird dieselbe Logik auf die Hidden Nodes angewandt. Also eine Dropoutwahrscheinlichkeit von 10 % bedeutet, dass in jedem Durchlauf 10 % der Knoten nicht genutzt werden.
Die optimale Wahrscheinlichkeit hängt auch stark von der Schichtart ab. Wie verschiedene Paper herausgefunden haben, ist bei der Input-Layer eine Dropoutwahrscheinlichkeit nahe der eins optimal. Bei den Hidden Layers hingegen führt eine Wahrscheinlichkeit nahe der 50 % zu besseren Ergebnissen.
Warum verhindert die Dropout Layer Overfitting?
In tiefen Neuronalen Netzwerken entsteht Overfitting meist dadurch, dass bestimmte Neuronen von verschiedenen Schichten sich gegenseitig beeinflussen. Einfach gesagt führt das zum Beispiel dazu, dass gewisse Neuronen die Fehler von vorherigen Knoten ausbessern und somit voneinander abhängen oder die guten Ergebnisse der vorherigen Schicht ohne große Änderungen einfach weiterreichen. Dadurch wird eine vergleichsweise schlechte Generalisierung erreicht.
Durch die Nutzung der Dropout Layer können sich die Neuronen hingegen nicht mehr auf die Knoten von vorherigen oder folgenden Schichten verlassen, da sie nicht davon ausgehen können, dass diese in dem jeweiligen Trainingsdurchlauf überhaupt existieren. Dies führt dazu, dass die Neuronen, nachweislich, grundlegendere Strukturen in Daten erkennt, die nicht von der Existenz einzelner Neuronen abhängen. Diese Abhängigkeiten treten in regulären Neuronalen Netzwerken tatsächlich relativ häufig auf, da dies eine einfache Möglichkeit ist, die Verlustfunktion schnell zu verringern und dadurch dem Ziel des Modells schnell näher zu kommen.
Außerdem verändert, wie bereits erwähnt, der Dropout die Architektur des Netzwerks leicht. Somit ist das austrainierte Modell dann eine Kombination aus vielen, leicht unterschiedlichen Modellen. Diese Vorgehensweise kennen wir bereits aus dem Ensemble Learning, wie beispielsweise in Random Forests. Dabei stellt sich heraus, dass das Ensemble von vielen, relativ ähnlichen Modellen meist bessere Ergebnisse liefert, als ein einziges Modell. Dieses Phänomen ist unter dem Namen “Wisdom of the Crowds” bekannt.
Wie baut man Dropout in ein bestehendes Netzwerk ein?
In der Praxis wird die Dropout Layer oft nach einer Fully-Connected Layer verwendet, da diese vergleichsweise viele Parameter hat und somit die Wahrscheinlichkeit der sogenannten “Co-Adaption”, also der Abhängigkeit von Neuronen untereinander sehr hoch ist. Jedoch kann man theoretisch auch nach jeder beliebigen Schicht eine Dropout Layer einfügen, jedoch kann es dann auch zu schlechteren Ergebnissen führen.
Praktisch gesehen wird die Dropout Layer einfach nach der gewünschten Schicht eingefügt und nutzt dann die Neuronen der vorhergehenden Schicht als Inputs. Je nach Wert der Wahrscheinlichkeit wird ein Teil dieser Neuronen dann auf Null gesetzt und an die darauffolgende Schicht weitergegeben.
Es bietet sich dabei vor allem an, die Dropout Layer in größeren Neuronalen Netzwerken zu nutzen. Denn eine Architektur mit vielen Schichten tendiert deutlich stärker zum Overfitting als kleinere Netzwerke. Dabei ist es auch wichtig, die Anzahl der Nodes entsprechend zu erhöhen, wenn eine Dropout Layer hinzugefügt wird. Als Daumenregel wird dazu die Anzahl der Nodes vor Einführung des Dropouts durch die Dropout Rate geteilt.
Was passiert mit dem Dropout während der Prediction?
Wie wir nun festgestellt haben, ist die Nutzung einer Dropout Layer während des Trainings ein wichtiger Faktor zur Vermeidung von Overfitting. Jedoch stellt sich noch die Frage, ob diese Systematik auch genutzt wird, wenn das Modell fertig trainiert wurde und dann für Vorhersagen für neue Daten genutzt wird.
Tatsächlich werden die Dropout Schichten nach dem Training nicht mehr für Vorhersagen genutzt. Das bedeutet, dass alle Neuronen für die schlussendliche Vorhersage bleiben. Jedoch hat das Modell nun mehr Neuronen zur Verfügung, als es während dem Training der Fall war. Dadurch sind jedoch die Gewichtungen in der Ausgabeschicht deutlich höher als dies während dem Training erlernt wurde. Deshalb werden die Gewichte mit der Höhe der Dropout Rate skaliert, damit das Modell trotzdem weiterhin gute Vorhersagen macht.
Wie kann man die Dropout Layer in Python nutzen?
Für Python gibt es bereits viele vordefinierte Implementierungen mit denen man Dropout Layers nutzen kann. Die bekannteste ist wahrscheinlich die von Keras bzw. TensorFlow. Diese kann man, wie andere Schichtarten auch, über “tf.keras.layers” importieren:

Anschließend übergibt man die Parameter, also zum einen die Größe des Inputvektors und die Dropoutwahrscheinlicht, die man abhängig von der Schichtart und dem Netzwerkaufbau wählen sollte. Die Schicht kann man dann mit der Übergabe von tatsächlichen Werten in der Variable “data” nutzen. Außerdem gibt es noch den Parameter “training”, der angibt, ob die Dropout Layer lediglich im Training und nicht bei der Vorhersage von neuen Werten, der sogenannte Inference, genutzt wird.
Wenn der Parameter nicht explizit gesetzt wird, wird die Dropout Layer lediglich bei “model.fit()”, also dem Training, aktiv und nicht bei “model.predict()”, also der Vorhersage von neuen Werten.
Was sind die Vorteile einer Dropout Layer?
Die Dropout-Layer ist eine zusätzliche Schicht in einem neuronalen Netzwerk, die für die Regularisierung genutzt wird. Die Integration dieser Schicht bietet einige Vorteile, die wir in diesem Abschnitt genauer beleuchten wollen. Ursprünglich wurde sie größtenteils verwendet, um Overfitting zu verhindern, jedoch ist sie mittlerweile zu einem wichtigen Bestandteil im Deep Learning geworden.
- Verbesserte Generalisierung: Der wichtigste Vorteil der Dropout Layer ist, dass sie die Generalisierungsleistung des Modell verbessert, indem die Überanpassung verhindert wird. Durch. Die zufällige Deaktivierung von Neuronen während des Trainings wird die sogenannte Koadaption verhindert und dadurch das Modell gezwungen wirklich robuste Merkmale in den Daten zu finden und zu nutzen. Durch diese Eigenschaft schneidet das Modell bei neuen, ungesehenen Daten besser ab und hat eine bessere Gesamtleistung.
- Effektive Regularisierung ohne komplexe Architekturen: Des Weiteren bietet die Dropout Layer eine effektive Architektur, die zur Regularisierung des Modells führt ohne, dass die Rechenleistung stark zunimmt. Traditionelle Regularisierungsmethode, wie beispielsweise L1 und L2 Regularisierung, führen zusätzliche Parameter ein, die wiederum rechenintensiv und möglicherweise auch schwierig abzustimmen sind. Die Dropout Layer hingegen ist einfach zu implementieren und verändert die Netzwerkarchitektur nur sehr leicht. Dadurch ist es eine beliebte Option bei Deep Learning Modellen geworden.
- Verringerung der Überanpassung: Ein Overfitting des Modells findet statt, wenn es sich im Training zu sehr auf die Trainingsdaten spezialisiert und diese auswendig lernt. Dadurch performt das Modell dann nur schlecht auf neue, ungesehene Daten. Dropout reduziert das Risiko des Overfittings, indem es zufällige Neuronen in jeder Iteration rauswirft und dadurch ein gewisses Rauschen in den Lernprozess integriert. Dadurch ist das Modell gezwungen robustere Repräsentationen zu erlernen und dadurch besser zu generalisieren.
- Einfachheit und rechnerische Effizienz: Auch bei der Umsetzung in TensorFlow oder PyTorch lässt sich die Dropout Layer sehr leicht integrieren. Durch diese Einfachheit können Forscher schnell verschiedene Experimente durchführen und testen, ob sich die Leistung des Modells verbessert oder nicht. Zusätzlich ist es eine beliebte Wahl, da die Rechenleistung nicht wirklich erhöht wird, sodass die Dropout Layer eine sehr effiziente Regularisierungstechnik ist.
- Robustheit gegenüber verrauschten Daten: Schließlich ermöglicht die Dropout Layer auch das Training mit verrauschten Daten, also Datensätze die keine optimale Datenqualität haben. Ohne das Dropout wäre die Gefahr hoch, dass das Modell sich an dieses Rauschen anpasst und dadurch overfitted, weil es sich zu stark an die Trainingsdaten anpasst. Durch das Auslassen der Neuronen hingegen wird dieses Risiko verringert, da sich das Netzwerk nicht zu stark an das vorhandene Rauschen anpassen kann. Dies ist besonders dann von Vorteil, wenn die Datenqualität von realen Informationen nicht immer optimal ist.
Abschließend ist die Dropout Layer eine wertvolle Regularisierungstechnik, die vor allem für Deep Learning Anwendungen von großer Bedeutung ist und Vorteile gegenüber etablierten Regularisierungsmethoden bietet. Die positiven Hauptmerkmale sind hierbei die Verhinderung von Overfitting und das Erlernen einer guten Regularisierung. Diese Fähigkeiten machen die Dropout Layer zu einem Standardwerkzeug bei der Arbeit mit neuronalen Netzen.
Welche Tipps sollte man bei der Nutzung von Dropout Layers beachten?
Die Dropout Layer ist ein wichtiger Bestandteil für nahezu jedes neuronale Netzwerk. In diesem Abschnitt beschäftigen wir uns mit Best Practices zur Einbindung dieser Schicht in bestehende Netzwerke und wie sie genutzt werden kann, um robuste Modelle zu erstellen.
Bei der Implementierung muss die sogenannte Dropout-Rate festgelegt werden, die festlegt wie viele Neuronen in jedem Schritt übergangen werden. Hierbei gilt es einen geeigneten Wert zu finden. Eine zu niedrige Dropout-Rate führt unter Umständen nicht zu einer geeigneten Regularisierung und landet im Overfitting. Eine zu hohe Dropout-Rate hingegen kann dazu führen, dass das Modell nicht effektiv lernen kann und entsprechend nicht konvergiert.
Anschließend muss die Dropout Schicht richtig im Netzwerk platziert werden. Es gibt verschiedene Möglichkeiten diese nach fully-connected oder nach Convolutional Layern einzubinden. Hierbei gibt es keine Daumenregel, welche Implementierung am sinnvollsten ist. Vielmehr sollte in mehreren Trainingsdurchläufen damit experimentiert werden, um die optimale Position zu finden.
Eine Regel gibt es jedoch bei der Platzierung der Schicht nämlich, dass die Dropout Layer auf der Ausgabeschicht vermieden werden sollte, vor allem bei Klassifizierungsaufgaben. Dies kann zu einer ungewünschten Zufälligkeit in den Vorhersagen führen und somit die Leistung des Gesamtmodells negativ beeinflussen.
Zusätzlich ist es wichtig, dass die Dropout Layer sowohl in der Trainings- als auch der Testphase konsequent genutzt wird, um die Architektur konstant zu halten. Der Unterschied hierbei ist jedoch, dass in der Testphase die Dropout-Rate auf 0 gesetzt wird, um genaue Vorhersagen treffen zu können.
Durch die ständige Überwachung der Leistung des Modells stellst Du sicher, dass die Dropout Schicht optimal genutzt wurde und auch die Dropout Rate richtig gewählt wurde. Dadurch kann auch frühzeitig eingegriffen werden, wenn das Modell nicht ausreichend konvergiert oder ins Overfitting rutscht. In TensorFlow kann beispielsweise TensorBoard dafür genutzt werden, die Entwicklung der Verlustfunktion durchgehend zu beobachten, um Abweichungen frühzeitig festzustellen.
Anschließend sollte auch geprüft werden, ob es sinnvoll ist, die Dropout Layer mit anderen Regularisierungstechniken, wie L1 oder L2, zu kombinieren. Dies kann in manchen Fällen durchaus sinnvoll sein und sollte deshalb immer in Erwägung gezogen werden.
Der Aufbau von Deep Learning Modellen ist immer ein iterativer Prozess, der möglicherweise Experimentieren und Feinabstimmung benötigt. Dasselbe gilt natürlich auch für die Nutzung von Dropout Schichten. Hierbei muss geprüft werden, welche Dropout Rate optimal ist oder an welcher Stelle die Schicht eingebaut wird.
Das solltest Du mitnehmen
- Als Dropout bezeichnet man eine Schicht in einem Neuronalen Netzwerk, die mit einer definierten Wahrscheinlichkeit Neuronen auf Null setzt, also diese in einem Trainingsdurchlauf nicht beachtet.
- Dadurch lässt sich in tiefen Neuronalen Netzwerken die Gefahr des Overfittings verringern, da die Neuronen untereinander keine sogenannte Adaption bilden, sondern tieferliegende Strukturen in den Daten erkennen.
- Die Dropout Layer lässt sich sowohl in der Eingabeschicht als auch in den verborgenen Schichten verwenden. Jedoch hat sich gezeigt, dass je nach Schichttyp unterschiedliche Dropoutwahrscheinlichkeiten genutzt werden sollten.
- Sobald das Training austrainiert wurde, wird die Dropout Layer jedoch nicht mehr für Vorhersagen genutzt. Damit das Modell jedoch weiterhin gute Ergebnisse liefert werden die Gewichte mithilfe der Dropout Rate skaliert.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.

Was ist die Singular Value Decomposition?
Erkenntnisse und Muster freilegen: Lernen Sie die Leistungsfähigkeit der Singular Value Decomposition (SVD) in der Datenanalyse kennen.

Was ist die Poisson Regression?
Lernen Sie die Poisson-Regression kennen, ein statistisches Modell für die Analyse von Zähldaten, inkl. einem Beispiel in Python.

Was ist blockchain-based AI?
Entdecken Sie das Potenzial der blockchain-based AI in diesem aufschlussreichen Artikel über Künstliche Intelligenz und Blockchain.
Andere Beiträge zum Thema Dropout Layer
Die Dokumentation der TensorFlow Dropout Layer findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.