In der Welt der natürlichen Sprachverarbeitung spielen n-Grams eine zentrale Rolle beim Verstehen und Analysieren von Texten. Diese Wortfolgen sind für Aufgaben wie Sprachmodellierung und Stimmungsanalyse unverzichtbar und bieten Einblicke in die Struktur und den Kontext der geschriebenen Sprache. In diesem Artikel tauchen wir in das faszinierende Reich der n-Grams ein und untersuchen ihre verschiedenen Arten, Anwendungen und die entscheidende Rolle, die sie im Bereich des NLP spielen.
Was sind n-Grams?
In der natürlichen Sprachverarbeitung sind n-Grams zusammenhängende Sequenzen von n Elementen, bei denen es sich im Kontext der Textanalyse in der Regel um Wörter handelt. Das “n” steht für die Anzahl der Elemente in der Sequenz und kann von 1 (Unigramme) bis 2 (Bigramme), 3 (Trigramme) und darüber hinaus variieren. N-Grams sind ein grundlegendes Konzept in NLP und Textanalyse, da sie die Modellierung der sequenziellen Struktur und des Kontexts eines Textes ermöglichen.
Schauen wir uns die verschiedenen Typen an:
- Unigramme (1-Gramme): Hierbei handelt es sich um einzelne Wörter, die jeweils isoliert betrachtet werden. Unigramme sind nützlich für grundlegende Worthäufigkeitsanalysen und die Kategorisierung von Texten.
- Bigramme (2-Gramme): Bigramme bestehen aus Paaren von aufeinander folgenden Wörtern. Sie erfassen einfache Wortassoziationen und sind für Aufgaben wie Textvorhersage und automatische Vervollständigung nützlich.
- Trigramme (3-Gramme): Trigramme sind Folgen von drei Wörtern. Sie bieten mehr Kontext und Informationen über die Beziehungen zwischen Wörtern in einem Text.
- N-Gramme höherer Ordnung: Das “n” kann größer sein und mehr Wörter in einer Sequenz umfassen. Mit zunehmendem “n” steigen jedoch auch die Komplexität und der Rechenaufwand der N-Gramm-Analyse.
N-Grams sind für verschiedene NLP-Aufgaben unerlässlich, z. B. für die Sprachmodellierung, die maschinelle Übersetzung, die Stimmungsanalyse und das Information Retrieval. Sie helfen zu verstehen, wie Wörter zusammen verwendet werden und wie sich die Reihenfolge der Wörter auf die Bedeutung auswirkt. Durch die Analyse von Wortfolgen können NLP-Modelle wertvolle Erkenntnisse und Muster aus Textdaten extrahieren, was sie zu einem wichtigen Werkzeug für die Textanalyse und das Textverständnis macht.
Was sind die verschiedenen Arten von n-Grams?
N-Grams, d. h. zusammenhängende Sequenzen von n Elementen (im Kontext der natürlichen Sprachverarbeitung in der Regel Wörter), gibt es in verschiedenen Formen, die auf dem Wert von “n” basieren. Die verschiedenen Typen bieten eine Möglichkeit, verschiedene Ebenen von Kontext und Bedeutung in Textdaten zu erfassen.
- Unigramme (1-Gramme): Unigramme stellen einzelne Wörter in einem Text dar. Jedes Wort wird unabhängig betrachtet, und Unigramme werden häufig für die grundlegende Textanalyse verwendet, einschließlich der Zählung der Worthäufigkeit und der Kategorisierung von Texten. Obwohl ihnen der Kontext fehlt, sind Unigramme ein Ausgangspunkt für viele NLP-Aufgaben.
- Bigramme (2-Gramme): Bigramme bestehen aus Paaren von aufeinander folgenden Wörtern. Diese Wortfolgen erfassen einfache Wortassoziationen und bieten mehr Kontext als Unigramme. Bigramme sind für Aufgaben wie die Textvorhersage, die automatische Vervollständigung und die Identifizierung gemeinsamer Phrasen im Text unerlässlich.
- Trigramme (3-Gramme): Trigramme sind Folgen von drei aufeinanderfolgenden Wörtern. Sie bieten einen umfassenderen Kontext und können helfen, Beziehungen zwischen Wörtern in einem Text zu verstehen. Trigramme sind wertvoll für Aufgaben wie Sprachmodellierung und Part-of-Speech-Tagging.
- 4-Gramme und darüber hinaus: N-Grams können Werte von “n” größer als 3 haben, z. B. 4-Gramme, 5-Gramme und so weiter. Diese Versionen höherer Ordnung erfassen einen noch umfangreicheren Kontext und Nuancen im Text. Mit zunehmendem “n” steigen jedoch auch die Rechenkomplexität und die Spärlichkeit der Daten. Wortfolgen höherer Ordnung werden für spezielle Aufgaben verwendet, die ein tiefes Kontextverständnis erfordern.
- Skip-Gramme: Skip-grams sind eine Variante, bei der die Wörter nicht unbedingt aufeinander folgen. Stattdessen wird eine bestimmte Anzahl von Wörtern zwischen ihnen übersprungen. Skip-Gramme werden häufig in Wort-Einbettungs-Techniken verwendet und sind wertvoll für das Verständnis von Wortassoziationen und Ähnlichkeiten.
- Kontinuierliche N-Grams: Hierbei handelt es sich um Wortfolgen, die sich überschneidende Wortfolgen zulassen. Bei einer kontinuierlichen Trigramm-Analyse des Satzes “Der schnelle braune Fuchs springt” würde man beispielsweise “Der schnelle braune”, “der schnelle braune Fuchs” und “der braune Fuchs springt” als kontinuierliche Trigramme haben. Kontinuierliche N-Grams sind nützlich für die Erfassung von feinkörnigem Kontext.
- Zeichen-N-Gramme: Während traditionelle N-Gramme wortbasiert sind, behandeln Zeichen-N-Gramme Zeichen als Analyseeinheiten. Sie werden in verschiedenen NLP-Anwendungen verwendet, z. B. zur Textklassifizierung, Handschrifterkennung und Rechtschreibkorrektur.
Jede Art von n-Gram bietet eine einzigartige Perspektive auf den Text und seine zugrunde liegende Struktur. Die Wahl des N-Gram-Typs hängt von der spezifischen NLP-Aufgabe und dem erforderlichen Grad an Kontext und Detailgenauigkeit ab. Wortfolgen sind ein vielseitiges Werkzeug in der Textanalyse, das die Extraktion wertvoller Informationen und Muster aus Textdaten ermöglicht.
Wie werden N-Grams in der Textanalyse verwendet?
N-Gramme spielen eine zentrale Rolle in der Textanalyse und ermöglichen ein tieferes Verständnis von sprachlichen Strukturen, Kontext und Bedeutung. Ihre Anwendungen erstrecken sich auf ein breites Spektrum von Aufgaben der natürlichen Sprachverarbeitung und tragen zu einer genaueren und differenzierteren Textanalyse bei. Im Folgenden werden einige der wichtigsten Anwendungen in der Textanalyse untersucht:
- Stimmungsanalyse:
- N-Grams spielen eine wichtige Rolle bei der Stimmungsanalyse, bei der es darum geht, den emotionalen Ton eines Textes zu bestimmen, z. B. ob er positiv, negativ oder neutral ist.
- Durch die Analyse der Häufigkeit und des gemeinsamen Auftretens von Wortfolgen können Stimmungsanalysemodelle gefühlstragende Phrasen und Ausdrücke identifizieren.
- Maschinelle Übersetzung:
- In maschinellen Übersetzungssystemen werden Wortfolgen verwendet, um die Übersetzungsgenauigkeit und den Sprachfluss des generierten Textes zu verbessern.
- N-Grams helfen dabei, den Kontext von Wörtern und Phrasen zu verstehen und unterstützen die Übersetzung von idiomatischen Ausdrücken und Kollokationen.
- Texterstellung:
- N-Grams sind wertvoll für die Texterstellung, z. B. für Chatbots, Auto-Suggest-Funktionen und kreatives Schreiben.
- Durch die Analyse der Wahrscheinlichkeiten von Wortfolgen können Textgenerierungsmodelle kohärente und kontextuell relevante Texte erstellen.
- Häufige Phrasen und Kollokationen:
- Wortfolgen sind hervorragend geeignet, um häufige Phrasen und Kollokationen im Text zu identifizieren.
- Sie können häufig vorkommende Wortkombinationen aufdecken, die für Aufgaben wie die Extraktion von Schlüsselwörtern und die Zusammenfassung von Inhalten entscheidend sind.
- Sprachmodellierung:
- N-Grams sind ein grundlegender Bestandteil von Sprachmodellen, die in der Spracherkennung, dem natürlichen Sprachverständnis und der Textvervollständigung eingesetzt werden.
- Sprachmodelle nutzen sie, um die Wahrscheinlichkeit von Wortfolgen vorherzusagen und die Genauigkeit der Texterstellung zu verbessern.
- Erkennung von benannten Entitäten:
- Wortfolgen können bei der Identifizierung von benannten Einheiten, wie Namen von Personen, Organisationen und Orten, in einem Text helfen.
- Durch die Erkennung gemeinsamer Muster können Modelle zur Erkennung benannter Entitäten wertvolle Informationen aus unstrukturiertem Text extrahieren.
- Text-Klassifizierung:
- Bei Textklassifizierungsaufgaben dienen N-Grams als Merkmale zur Darstellung von Textdokumenten.
- Durch die Erfassung des Vorhandenseins und der Häufigkeit von Wortfolgen in Dokumenten können Klassifikatoren zwischen Kategorien unterscheiden und genaue Vorhersagen machen.
- Informationsbeschaffung:
- Suchmaschinen und Information Retrieval Systeme verwenden N-Grams, um die Relevanz der Suchergebnisse zu verbessern.
- N-Grams helfen dabei, Benutzeranfragen zu verstehen und sie mit relevanten Dokumenten abzugleichen, selbst wenn es Tippfehler oder unterschiedliche Schreibweisen gibt.
- Stilistische Analyse:
- Wortfolgen können stilistische Muster und Autorenschaft in Texten aufzeigen.
- Forscher verwenden n-Grams, um die sprachlichen Merkmale verschiedener Autoren zu analysieren oder um Veränderungen im Schreibstil im Laufe der Zeit zu verfolgen.
Durch die Identifizierung von gemeinsamen Phrasen, Kollokationen und sprachlichen Mustern verbessern N-Grams die Analysetiefe in verschiedenen NLP-Anwendungen. Sie ermöglichen ein tieferes Verständnis des Kontexts und der Beziehungen zwischen den Wörtern im Text und tragen so zur Genauigkeit und Effizienz von Textanalyseaufgaben bei.
Wie werden N-Grams in der statistischen Sprachmodellierung verwendet?
Die statistische Sprachmodellierung ist eine grundlegende Komponente der Verarbeitung natürlicher Sprache, und n-Grams spielen in diesem Bereich eine zentrale Rolle. Sprachmodelle zielen darauf ab, die zugrundeliegende Struktur der Sprache zu verstehen und Vorhersagen darüber zu treffen, welches Wort oder welche Phrase in einem bestimmten Kontext wahrscheinlich folgen wird. N-Grams, d.h. zusammenhängende Sequenzen von n Elementen, sind für die Erstellung probabilistischer Modelle unerlässlich.
N-Gram-Modelle sind eine Klasse von statistischen Sprachmodellen, die Wortfolgen als Grundlage für das Sprachverständnis verwenden. Diese Modelle beruhen auf der einfachen, aber wirkungsvollen Idee, dass die Wahrscheinlichkeit, dass ein Wort in einem Satz vorkommt, von den vorangehenden n-1 Wörtern abhängt. In einem Bigram-Modell (2-Gramm) hängt die Wahrscheinlichkeit eines Wortes beispielsweise nur von dem vorhergehenden Wort ab, während sie in einem Trigram-Modell (3-Gramm) von den beiden vorhergehenden Wörtern abhängt.
Der Hauptzweck dieser Modelle besteht darin, die Wahrscheinlichkeit von Wortfolgen in einem bestimmten Text zu schätzen. Dies wird erreicht, indem die Häufigkeit von Wortfolgen in einem großen Textkorpus gezählt wird. So würde beispielsweise ein Trigramm-Modell die Wahrscheinlichkeit eines Wortes in Abhängigkeit von den beiden vorangehenden Wörtern berechnen, indem es zählt, wie oft dieses Trigramm in den Trainingsdaten vorkommt.
Eine der wichtigsten Anwendungen der statistischen Sprachmodellierung ist die Vorhersage des nächsten Wortes in einer Folge. Bei einer Folge von n-1 Wörtern kann das Modell die Wahrscheinlichkeitsverteilung über alle möglichen Wörter im Wortschatz für das n-te Wort berechnen. Diese Vorhersage wird von den n-Gram-Wahrscheinlichkeiten geleitet, die aus den Trainingsdaten gelernt wurden.
Betrachten wir das Beispiel eines Bigram-Modells. Bei dem Satz “Er öffnete die _” kann das Modell das nächste Wort vorhersagen, indem es die Wahrscheinlichkeit für jedes Wort im Vokabular auf der Grundlage der beobachteten Bigramme in den Trainingsdaten berechnet. Das vorhergesagte Wort ist dasjenige mit der höchsten bedingten Wahrscheinlichkeit, was oft als “Maximum-Likelihood-Schätzung” bezeichnet wird.
Markov-Modelle:
N-Gram-Modelle sind ein spezieller Typ von Markov-Modellen, die als “speicherlose” Markov-Modelle bezeichnet werden. Der “gedächtnislose” Aspekt bedeutet, dass diese Modelle nur die unmittelbare Vergangenheit (n-1 Wörter) berücksichtigen und keinen umfassenderen Kontext einbeziehen. Diese Vereinfachung funktioniert zwar in vielen Fällen gut, erfasst aber möglicherweise keine weitreichenden Abhängigkeiten in der Sprache.
Durch die Verwendung von n-Grams höherer Ordnung, z. B. 4-Gramme oder 5-Gramme, kann das Modell jedoch einen umfassenderen Kontext berücksichtigen und längerfristige Abhängigkeiten in der Sprache erfassen. Dies ist besonders wertvoll bei der Analyse komplexer Texte oder bei der Erstellung kohärenter und kontextuell korrekter Texte.
Zusammenfassend lässt sich sagen, dass n-Grams in der statistischen Sprachmodellierung von grundlegender Bedeutung sind, insbesondere bei der Entwicklung von Wortfolgenmodellen und Markov-Modellen. Diese Modelle bieten Einblicke in die Struktur und die prädiktive Natur der Sprache und ermöglichen Anwendungen wie Textvorhersage, Autokorrektur und Spracherkennung. Wortfolgen bieten ein Mittel, um die probabilistischen Beziehungen zwischen Wörtern in der natürlichen Sprache zu verstehen und zu nutzen, und tragen so zur Effektivität verschiedener NLP-Aufgaben bei.
Was sind die Herausforderungen und Grenzen der Verwendung von n-Grams?
N-Grams sind zwar ein wertvolles Werkzeug für die Sprachverarbeitung, aber sie haben auch ihre Tücken und Grenzen. Diese Herausforderungen können die Effektivität von N-Grams-Modellen beeinträchtigen und müssen bei der Arbeit mit Textdaten sorgfältig berücksichtigt werden. Im Folgenden gehen wir auf einige der wichtigsten Herausforderungen ein und erörtern Strategien zur Entschärfung dieser Probleme.
- Spärlichkeit der Daten:
- Herausforderung: Je größer der Wert von “n” in n-Grams ist, desto ausgeprägter wird das Problem der Datenarmut. Wortfolgen höherer Ordnung erfordern immer größere Mengen an Trainingsdaten, um genaue und zuverlässige Schätzungen des gemeinsamen Auftretens von Wörtern zu liefern.
- Abhilfe: Ein Ansatz zur Behebung des Problems der Datenarmut ist die Verwendung von Glättungsverfahren, wie z. B. die Add-one-Glättung (Laplace-Glättung) oder die Good-Turing-Glättung, bei der die Wortfolgenwahrscheinlichkeiten angepasst werden, um nicht gesehene oder seltene n-Grams zu berücksichtigen. Darüber hinaus kann die Verwendung eines umfangreicheren und vielfältigeren Korpus von Trainingsdaten dazu beitragen, die Probleme der Sparsamkeit zu mildern.
- Dimensionalität:
- Herausforderung: N-Grams können zu hochdimensionalen Merkmalsräumen führen, die eine Herausforderung für die Recheneffizienz und die Modellkomplexität darstellen können, insbesondere bei der Arbeit mit langen Wortfolgen.
- Abhilfe: Techniken zur Dimensionalitätsreduktion, wie z. B. Merkmalsauswahl und Hauptkomponentenanalyse (PCA), können angewandt werden, um die Dimensionalität des Merkmalsraums zu reduzieren. Ein weiterer Ansatz ist die Verwendung von Wortfolgen niedrigerer Ordnung, die weniger rechenintensiv sind.
- Empfindlichkeit gegenüber der Wortreihenfolge:
- Herausforderung: N-Grams berücksichtigen die Wortreihenfolge, haben aber nur ein begrenztes kontextuelles Verständnis, was sie empfindlich für Variationen in der Wortreihenfolge macht.
- Abhilfe: Um der Empfindlichkeit gegenüber der Wortreihenfolge zu begegnen, kann die Verwendung von Wortfolgen höherer Ordnung, wie Trigramme oder 4-Gramme, helfen, einen umfassenderen Kontext zu erfassen. Alternativ können fortgeschrittene Techniken wie rekurrente neuronale Netze (RNNs) und Transformer-Modelle weitreichende Abhängigkeiten in der Sprache besser erfassen.
4. Kontextuelle Mehrdeutigkeit:
- Herausforderung: Wortfolgen berücksichtigen nicht von sich aus kontextuelle Mehrdeutigkeit. Eine einzelne n-Gram-Sequenz kann je nach dem umgebenden Kontext mehrere Interpretationen haben.
- Abhilfe: Um der kontextuellen Mehrdeutigkeit zu begegnen, ist es von Vorteil, einen umfangreicheren Kontext einzubeziehen oder kontextuelle Einbettungen wie Word2Vec oder BERT (Bidirectional Encoder Representations from Transformers) zu verwenden, die ein umfassenderes Verständnis der Wortbedeutungen im Kontext ermöglichen.
- Geringe Generalisierung:
- Herausforderung: N-Gramme, insbesondere bei höheren Ordnungen, können zu einer Überanpassung der Trainingsdaten und einer geringen Generalisierung auf ungesehene oder unterschiedliche Texte führen.
- Abhilfe: Um die Generalisierung zu verbessern, können Techniken zur Auswahl von Merkmalen und zur Glättung angewendet werden. Die Kombination von Wortfolgen mit anderen linguistischen Merkmalen oder der Einsatz von Modellen auf der Grundlage neuronaler Netze kann zu einem robusteren Sprachverständnis führen.
Obwohl n-Gramme vielseitig sind, eignen sie sich möglicherweise nicht für alle Sprachverarbeitungsaufgaben. So können beispielsweise Aufgaben, die ein tiefes kontextuelles Verständnis erfordern, oder solche, die Sprachen mit flexibler Wortreihenfolge betreffen, von fortschrittlicheren Modellen, wie etwa transformatorbasierten Architekturen, profitieren. Außerdem sind in Szenarien, in denen die Datenarmut überwältigend ist, Wortfolgen möglicherweise nicht die effektivste Lösung.
Zusammenfassend lässt sich sagen, dass n-Grams zwar wertvolle Werkzeuge für die Sprachverarbeitung und die statistische Sprachmodellierung sind, dass es aber wichtig ist, ihre Herausforderungen und Grenzen zu verstehen. Durch die Anwendung geeigneter Abschwächungsstrategien und das Erkennen, wann Wortfolgen möglicherweise nicht die beste Lösung sind, können Praktiker fundiertere Entscheidungen bei der Arbeit mit Textdaten und der Entwicklung von NLP-Modellen treffen.
Welche Techniken werden für die Extraktion von N-Grams verwendet?
Die Extraktion von N-Grams aus Textdaten ist ein grundlegender Schritt bei vielen Aufgaben der natürlichen Sprachverarbeitung. N-Grams erfassen Wortfolgen und ihre Beziehungen und ermöglichen so eine tiefere Textanalyse. In diesem Abschnitt werden wir Techniken zur Extraktion von Wortfolgen, einschließlich Tokenisierung, Stemming und Filterung, untersuchen und praktische Tipps und Codebeispiele geben.
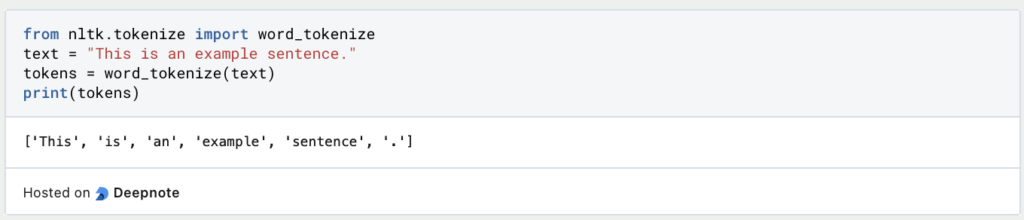
1. Tokenization:
- Unter Tokenisierung versteht man die Zerlegung von Text in einzelne Einheiten wie Wörter oder Unterwörter. Dies ist ein wichtiger Schritt bei der Extraktion von n-Grammen, da aus diesen Einheiten Wortfolgen gebildet werden.
- Zu den gängigen Tokenisierungsverfahren gehört die Aufteilung von Text in Leerzeichen oder Satzzeichen. Bibliotheken wie NLTK und spaCy bieten effiziente Tokenisierungswerkzeuge.
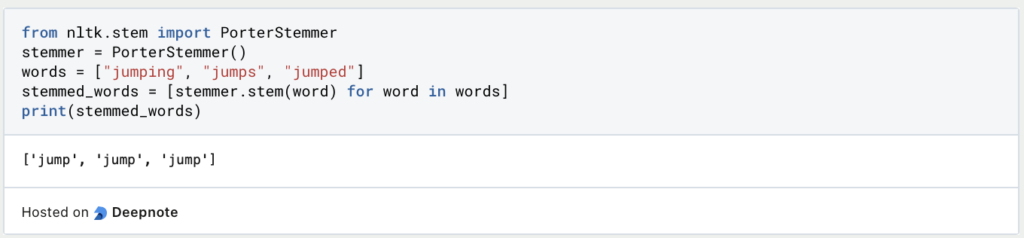
2. Stemming:
- Beim Stemming werden Wörter auf ihre Wurzelform reduziert, um sicherzustellen, dass verschiedene Flexionen eines Wortes als dasselbe Token behandelt werden. Dies kann helfen, ähnliche n-Grams zu erfassen.
- Beliebte Stemming-Algorithmen sind der Porter-Stemming-Algorithmus und der Snowball-Stemmer.
3. Filtering:
- Beim Filtern werden Wörter oder Teile von Wörtern entfernt, die nicht relevant sind oder bestimmte Kriterien nicht erfüllen. Zu den gängigen Filtern gehören das Entfernen von Stoppwörtern und Mindesthäufigkeitsschwellen.
- Das Entfernen von Stoppwörtern (gebräuchliche Wörter wie “und” oder “der”) kann dazu beitragen, das Rauschen in n-Grams zu reduzieren. Durch das Festlegen eines Häufigkeitsschwellenwerts wird sichergestellt, dass sie häufig genug vorkommen, um berücksichtigt zu werden.

Praktische Tipps:
- Experimentiere mit verschiedenen Reihenfolgen (z. B. Bigramme, Trigramme), um die informativsten N-Gramme für Deine spezielle Aufgabe zu finden.
- Verarbeite die Textdaten vor, indem Du Sonderzeichen entfernst, den Text in Kleinbuchstaben umwandelst und Interpunktion behandelst, um die Extraktion von N-Grammen zu verbessern.
- Erwäge die Verwendung von Bibliotheken wie scikit-learn oder NLTK für eine effiziente Extraktion und Analyse.
- Visualisiere Wortfolgen mit Tools wie Wortwolken oder Häufigkeitsdiagrammen, um Einblicke in die häufigsten Beispiele in Ihren Textdaten zu erhalten.
Die Extraktion von N-Grams ist eine vielseitige Technik, die für verschiedene NLP-Aufgaben wie Textklassifikation, Stimmungsanalyse und Information Retrieval eingesetzt wird. Eine effektive Extraktion, kombiniert mit einer geeigneten Vorverarbeitung und Filterung, kann die Qualität und Relevanz von N-Grammen für die Textanalyse erheblich verbessern.
Wie werden N-Grams beim maschinellen Lernen verwendet?
N-Grams sind nicht nur ein Eckpfeiler der natürlichen Sprachverarbeitung, sondern auch ein leistungsfähiges Werkzeug im Bereich des maschinellen Lernens. Sie dienen als wesentliche Merkmale für verschiedene Modelle des maschinellen Lernens, insbesondere bei textbasierten Aufgaben wie der Textklassifizierung und der Stimmungsanalyse. In diesem Abschnitt wird untersucht, wie sie als Merkmale beim maschinellen Lernen verwendet werden, und es werden Techniken zur Entwicklung und Auswahl von Merkmalen erörtert.
Eine der wichtigsten Anwendungen des maschinellen Lernens ist ihre Verwendung als Merkmale in Vorhersagemodellen. N-Gramme, die Sequenzen von Wörtern darstellen, erfassen den Kontext und die Struktur von Textdaten.
- Text-Klassifizierung: Bei Aufgaben wie der Spam-Erkennung, der Themenklassifizierung oder der Stimmungsanalyse werden Textdokumente häufig als Matrix dargestellt, wobei die Zeilen den Dokumenten und die Spalten den N-Grammen entsprechen. Das Vorhandensein oder die Häufigkeit eines jeden Gramms in einem Dokument wird als Merkmal verwendet. Algorithmen des maschinellen Lernens, wie Naïve Bayes, Support Vector Machines oder Deep Learning-Modelle, können dann aus diesen Merkmalen Muster lernen, um Vorhersagen zu treffen.
- Stimmungsanalyse: N-Grams spielen eine wichtige Rolle bei der Stimmungsanalyse, bei der es darum geht, den emotionalen Ton eines Textes zu bestimmen. Positive und negative sentimentale Wortfolgen können zusammen mit ihrer Häufigkeit als Merkmale für Sentiment-Klassifizierungsaufgaben dienen.
Merkmalstechnik und -auswahl
Der wirksame Einsatz dieser Technik beim maschinellen Lernen erfordert eine durchdachte Entwicklung und Auswahl von Merkmalen:
- Auswahl der N-Gramm-Reihenfolge: Die Wahl der Reihenfolge hängt von der jeweiligen Aufgabe ab. Unigramme (1-Gramm) eignen sich für die grundlegende Textanalyse, während Bigramme (2-Gramm) und Trigramme (3-Gramm) mehr Kontext erfassen. Wortfolgen höherer Ordnung bieten ein noch tieferes Kontextverständnis. Die Merkmalsauswahl kann helfen, die informativste Reihenfolge zu bestimmen.
- Merkmalstechnik: Unter Feature Engineering versteht man den Prozess der Auswahl, Umwandlung oder Erstellung von Features zur Verbesserung der Modellleistung. Zu den Techniken gehören:
- TF-IDF (Term Frequency-Inverse Document Frequency): Diese Technik gewichtet die Bedeutung eines n-Grams in einem Dokument im Verhältnis zu seiner Häufigkeit im gesamten Datensatz. Sie kann dazu beitragen, häufige Wortfolgen herunter zu gewichten und gleichzeitig seltene, potenziell informativere Wortfolgen hervorzuheben.
- Merkmalsskalierung: Die Skalierung von n-Gramm-Merkmalen auf einen gemeinsamen Bereich, z. B. [0, 1] oder [-1, 1], kann Probleme im Zusammenhang mit der Merkmalsgröße abmildern und faire Vergleiche zwischen verschiedenen n-Grammen fördern.
- Einbettungen: Für fortgeschrittene Aufgaben kann man die Verwendung von Worteinbettungen wie Word2Vec oder fastText in Betracht ziehen, um Wortfolgen als dichte Vektoren darzustellen.
Zusammenfassend lässt sich sagen, dass n-Gramme eine wertvolle Ressource für maschinelle Lernmodelle bei textbasierten Aufgaben sind. Sie liefern den Kontext und die sprachliche Struktur, die für das Verständnis und die Vorhersage von Textdaten erforderlich sind. Durch sorgfältige Entwicklung und Auswahl von n-Gramm-Merkmalen können maschinelle Lernmodelle die Leistung von Wortfolgen nutzen, um die Genauigkeit und Leistung in verschiedenen NLP-Anwendungen zu verbessern.
Das solltest Du mitnehmen
- N-Gramme, von Unigrammen bis hin zu N-Grammen höherer Ordnung, sind von grundlegender Bedeutung für die Verarbeitung natürlicher Sprache, da sie Einblicke in den Kontext und die Struktur von Textdaten bieten.
- Sie finden Anwendung in verschiedenen NLP-Aufgaben, einschließlich Stimmungsanalyse, Textklassifizierung, Informationsgewinnung und Sprachmodellierung.
- Sie ermöglichen es uns, Wortassoziationen, Kollokationen und linguistische Muster zu erfassen und so das Sprachverständnis und die Textanalyse zu verbessern.
- N-Gramme sind für die statistische Sprachmodellierung unerlässlich und tragen zu Modellen wie N-Gramm-Modellen und Markov-Modellen bei, die die Wahrscheinlichkeit von Wortfolgen vorhersagen.
- Wortfolgen bringen Herausforderungen mit sich, wie z. B. die Spärlichkeit der Daten, die Dimensionalität und die Empfindlichkeit gegenüber der Wortreihenfolge, die durch Techniken wie Glättung und Dimensionalitätsreduktion angegangen werden können.
- N-Gramme dienen als Merkmale in Modellen des maschinellen Lernens und verbessern Aufgaben wie Textklassifizierung und Stimmungsanalyse.

Was ist Representation Learning?
Entdecken Sie die Leistungsfähigkeit des Representation Learnings: Erforschen Sie Anwendungen, Algorithmen und Auswirkungen.

Was ist Manifold Learning?
Entdecken Sie die Welt des Manifold Learning - Ein tiefer Einblick in die Grundlagen, Anwendungen und die Programmierung.

Was ist die Grid Search?
Optimieren Sie Ihre Modelle für maschinelles Lernen mit Grid Search. Erforschen Sie die Abstimmung von Hyperparametern mit Python.

Was ist die Lernrate?
Entfalten Sie die Kraft der Lernraten beim maschinellen Lernen: Tauchen Sie ein in Strategien, Optimierung und Feinabstimmung für Modelle.

Was ist die Random Search?
Optimieren Sie Modelle für maschinelles Lernen: Lernen Sie, wie die Random Search Hyperparameter effektiv abstimmt.

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.
Andere Beiträge zum Thema N-Grams
Hier findest Du den Google N-gram viewer.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.