In the world of natural language processing, n-grams play a pivotal role in understanding and analyzing text. These sequences of words are essential for tasks like language modeling and sentiment analysis, offering insights into the structure and context of written language. In this article, we delve into the fascinating realm of n-grams, exploring their various types, applications, and the critical role they play in the field of NLP.
What are N-grams?
In natural language processing, n-grams are contiguous sequences of n items, which are typically words in the context of text analysis. The “n” represents the number of items in the sequence, and it can vary from 1 (unigrams) to 2 (bigrams), 3 (trigrams), and beyond. N-grams are a fundamental concept in NLP and text analysis, as they enable the modeling of the sequential structure and context of a text.
Let’s break down the different types:
- Unigrams (1-grams): These are single words, each considered in isolation. Unigrams are useful for basic word frequency analysis and text categorization.
- Bigrams (2-grams): Bigrams consist of pairs of consecutive words. They capture simple word associations and are valuable in tasks like text prediction and autocomplete.
- Trigrams (3-grams): Trigrams are sequences of three words. They provide more context and information about the relationships between words in a text.
- Higher-order N-grams: The “n” can be larger, encompassing more words in a sequence. However, as “n” increases, the complexity and computational demands of n-gram analysis also grow.
N-grams are essential for various NLP tasks, including language modeling, machine translation, sentiment analysis, and information retrieval. They help in understanding how words are used together and how the order of words impacts meaning. By analyzing word sequences, NLP models can extract valuable insights and patterns from text data, making them a critical tool for text analysis and understanding.
What are the different types of N-grams?
N-grams, or contiguous sequences of n items (typically words in the context of natural language processing), come in various forms based on the value of “n.” The different types provide a way to capture different levels of context and meaning in text data.
- Unigrams (1-grams): Unigrams represent individual words in a text. Each word is considered independently, and unigrams are often used for basic text analysis, including word frequency counts and text categorization. While they lack context, unigrams are a starting point for many NLP tasks.
- Bigrams (2-grams): Bigrams consist of pairs of consecutive words. These word sequences capture simple word associations and provide more context than unigrams. Bigrams are essential for tasks like text prediction, autocomplete, and identifying common phrases in text.
- Trigrams (3-grams): Trigrams are sequences of three consecutive words. They offer a more extensive context and can help in understanding relationships between words in a text. Trigrams are valuable for tasks like language modeling and part-of-speech tagging.
- 4-grams and Beyond: N-grams can have values of “n” greater than 3, such as 4-grams, 5-grams, and so on. These higher-order versions capture even more extensive context and nuances in the text. However, as “n” increases, the computational complexity and data sparsity also grow. Higher-order word sequences are used in specialized tasks that require deep context understanding.
- Skip-grams: Skip-grams are a variation where the words are not necessarily consecutive. Instead, they skip a specified number of words between them. Skip-grams are often used in word embedding techniques and are valuable for understanding word associations and similarities.
- Continuous N-grams: These are word sequences that allow overlapping sequences of words. For instance, in a continuous trigram analysis of the sentence “The quick brown fox jumps,” you would have “The quick brown,” “quick brown fox,” and “brown fox jumps” as continuous trigrams. Continuous n-grams are useful for capturing fine-grained context.
- Character N-grams: While traditional n-grams are word-based, character n-grams treat characters as the units of analysis. They are used in various NLP applications, such as text classification, handwriting recognition, and spelling correction.
Each type of n-gram offers a unique perspective on the text and its underlying structure. The choice of n-gram type depends on the specific NLP task and the level of context and detail required. Word sequences are a versatile tool in text analysis, enabling the extraction of valuable information and patterns from textual data.
How are N-grams used in Text Analysis?
N-grams play a pivotal role in text analysis, enabling a deeper understanding of linguistic structures, context, and meaning. Their applications extend to a wide range of natural language processing tasks, contributing to more accurate and nuanced text analysis. Here, we explore some of the key applications in text analysis:
- N-grams are instrumental in sentiment analysis, where the goal is to determine the emotional tone of a text, such as positive, negative, or neutral.
- By analyzing the frequency and co-occurrence of word sequences, sentiment analysis models can identify sentiment-bearing phrases and expressions.
2. Machine Translation:
- In machine translation systems, word sequences are used to improve the translation accuracy and fluency of the generated text.
- Ngrams help in understanding the context of words and phrases, aiding the translation of idiomatic expressions and collocations.
3. Text Generation:
- N-grams are valuable for text-generation tasks, such as chatbots, auto-suggest features, and creative writing.
- By analyzing the probabilities of word sequences, text generation models can produce coherent and contextually relevant text.
4. Common Phrases and Collocations:
- Word sequences are excellent at identifying common phrases and collocations in text.
- They can reveal frequently occurring word combinations that are critical for tasks like keyword extraction and content summarization.
5. Language Modeling:
- N-grams are a fundamental component of language models used in speech recognition, natural language understanding, and text completion.
- Language models leverage them to predict the likelihood of word sequences and improve the accuracy of text generation.
6. Named Entity Recognition:
- word sequences can aid in the identification of named entities, such as names of people, organizations, and locations, within a text.
- By recognizing common patterns, named entity recognition models can extract valuable information from unstructured text.
7. Text Classification:
- In text classification tasks, ngrams serve as features to represent text documents.
- By capturing the presence and frequency of word sequences in documents, classifiers can differentiate between categories and make accurate predictions.
8. Information Retrieval:
- Search engines and information retrieval systems use ngrams to improve the relevance of search results.
- N-grams help in understanding user queries and matching them to relevant documents, even when there are typographical errors or variant spellings.
9. Stylistic Analysis:
- Word sequences can reveal stylistic and authorship patterns in text.
- Researchers use n-grams to analyze the linguistic characteristics of different authors or to track changes in writing style over time.
By identifying common phrases, collocations, and linguistic patterns, n-grams enhance the depth of analysis in various NLP applications. They provide a more profound understanding of the context and relationships between words in the text, contributing to the accuracy and effectiveness of text analysis tasks.
How are N-grams used in Statistical Language Modeling?
Statistical language modeling is a fundamental component of natural language processing, and n-grams play a central role in this domain. Language models aim to understand the underlying structure of language, making predictions about which word or phrase is likely to follow a given context. N-grams, which are contiguous sequences of n items, are essential in building probabilistic models that power language understanding and text generation.
N-gram models are a class of statistical language models that use word sequences as the basis for language understanding. These models are based on the simple but powerful idea that the probability of a word occurring in a sentence depends on the preceding n-1 words. For example, in a bigram model (2-gram), the probability of a word is conditioned only on the previous word, whereas in a trigram model (3-gram), it’s conditioned on the previous two words.
The primary purpose of these models is to estimate the likelihood of word sequences in a given text. This is achieved by counting the frequency of word sequences in a large corpus of text. For instance, a trigram model would calculate the probability of a word given the two preceding words by counting how many times that trigram appears in the training data.
One of the key applications in statistical language modeling is predicting the next word in a sequence. Given a sequence of n-1 words, the model can calculate the probability distribution over all possible words in the vocabulary for the nth word. This prediction is guided by the n-gram probabilities learned from the training data.
Consider the example of a bigram model. Given the sentence, “He opened the _,” the model can predict the next word by calculating the likelihood of each word in the vocabulary based on the observed bigrams in the training data. The predicted word is the one with the highest conditional probability, often referred to as the “maximum likelihood estimate.”
Markov Models:
N-gram models are a specific type of Markov model, known as a “memoryless” Markov model. The “memoryless” aspect implies that these models consider only the immediate past (n-1 words) and do not account for more extensive context. While this simplification works well in many cases, it may not capture long-range dependencies in language.
However, by using higher-order n-grams, such as 4-grams or 5-grams, the model can consider a more extended context and capture longer-range dependencies in language. This is especially valuable when analyzing complex texts or generating coherent and contextually accurate text.
In summary, n-grams are fundamental in statistical language modeling, particularly in the development of word sequences models and Markov models. These models offer insights into the structure and predictive nature of language, enabling applications like text prediction, auto-correction, and speech recognition. Word sequences provide a means to understand and harness the probabilistic relationships between words in natural language, contributing to the effectiveness of various NLP tasks.
What are the challenges and limitations of using N-grams?
N-grams, while a valuable tool in language processing, are not without their set of challenges and limitations. These challenges can impact the effectiveness of n-gram models and need to be carefully considered when working with text data. Here, we delve into some of the primary challenges and discuss strategies for mitigating these issues.
1. Data Sparsity:
- Challenge: As the value of “n” in n-grams increases, the data sparsity problem becomes more pronounced. Higher-order word sequences require increasingly large amounts of training data to provide accurate and reliable estimates of word co-occurrence.
- Mitigation: To address data sparsity, one approach is to use smoothing techniques, such as add-one (Laplace) smoothing or Good-Turing smoothing, which adjusts word sequence probabilities to account for unseen or infrequent n-grams. Additionally, using a more extensive and diverse corpus of training data can help mitigate sparsity issues.
2. Dimensionality:
- Challenge: N-grams can lead to high-dimensional feature spaces, which can pose challenges for computational efficiency and model complexity, particularly when working with long word sequences.
- Mitigation: Dimensionality reduction techniques, such as feature selection and Principal Component Analysis (PCA), can be applied to reduce the dimensionality of the feature space. Another approach is to use lower-order word sequences, which are computationally less demanding.
3. Sensitivity to Word Order:
- Challenge: N-grams consider word order but have limited contextual understanding, making them sensitive to variations in word order.
- Mitigation: To address the sensitivity to word order, employing higher-order word sequences, such as trigrams or 4-grams, can help capture more extended context. Alternatively, advanced techniques like recurrent neural networks (RNNs) and transformer models can better capture long-range dependencies in language.
4. Contextual Ambiguity:
- Challenge: Word sequences do not inherently account for contextual ambiguity. A single n-gram sequence may have multiple interpretations based on the surrounding context.
- Mitigation: To address contextual ambiguity, it’s beneficial to incorporate more extensive context or use contextual embeddings like Word2Vec or BERT (Bidirectional Encoder Representations from Transformers), which provide a richer understanding of word meanings in context.
5. Low Generalization:
- Challenge: N-grams, especially at higher orders, can lead to overfitting of the training data and low generalization to unseen or diverse texts.
- Mitigation: To improve generalization, feature selection and smoothing techniques can be applied. Combining word sequences with other linguistic features or employing neural network-based models can lead to more robust language understanding.
While n-grams are versatile, they may not be suitable for all language-processing tasks. For instance, tasks that require deep contextual understanding or those involving languages with flexible word order may benefit from more advanced models, such as transformer-based architectures. Additionally, in scenarios where data sparsity is overwhelming, word sequences may not be the most effective solution.
In conclusion, while n-grams are valuable tools in language processing and statistical language modeling, understanding their challenges and limitations is essential. By applying appropriate mitigation strategies and recognizing when word sequences may not be the best fit, practitioners can make more informed decisions when working with text data and designing NLP models.
Which techniques are used for N-gram extraction?
Extracting n-grams from text data is a fundamental step in many natural language processing tasks. N-grams capture word sequences and their relationships, enabling deeper text analysis. In this section, we’ll explore techniques for extracting word sequences, including tokenization, stemming, and filtering, and provide practical tips and code examples.
1. Tokenization:
- Tokenization is the process of splitting text into individual units, such as words or subwords. It’s a crucial step in n-gram extraction since word sequences are formed from these units.
- Common tokenization techniques include splitting text into spaces or punctuation marks. Libraries like NLTK and spaCy offer efficient tokenization tools.
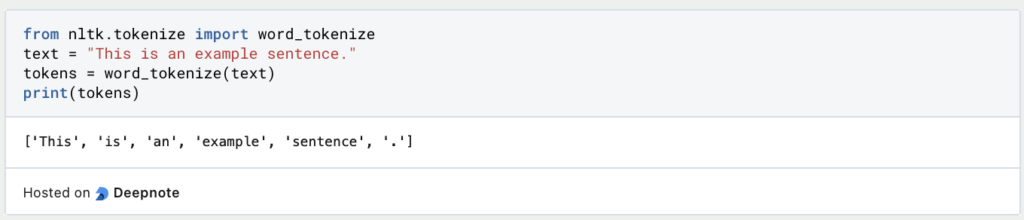
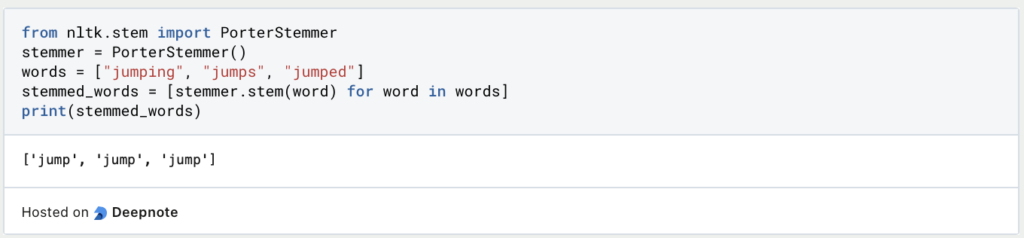
2. Stemming:
- Stemming is the process of reducing words to their root form to ensure that different inflections of a word are treated as the same token. This can help in capturing similar n-grams.
- Popular stemming algorithms include the Porter stemming algorithm and the Snowball stemmer.
3. Filtering:
- Filtering involves removing words or part of words that are not relevant or do not meet specific criteria. Common filters include stop-word removal and minimum frequency thresholds.
- Removing stop words (common words like “and” or “the”) can help reduce noise in n-grams. Setting a frequency threshold ensures that they occur frequently enough to be considered.

Practical Tips:
- Experiment with different orders (e.g., bigrams, trigrams) to find the most informative n-grams for your specific task.
- Preprocess the text data by removing special characters, converting text to lowercase, and handling punctuation to improve n-gram extraction.
- Consider using libraries like scikit-learn or NLTK for efficient extraction and analysis.
- Visualize word sequences using tools like word clouds or frequency plots to gain insights into the most common examples in your text data.
N-gram extraction is a versatile technique with applications in various NLP tasks, such as text classification, sentiment analysis, and information retrieval. Effective extraction, combined with appropriate preprocessing and filtering, can significantly enhance the quality and relevance of n-grams for text analysis.
How are N-grams used in Machine Learning?
N-grams are not only a cornerstone of natural language processing but also a powerful tool in the field of machine learning. They serve as essential features for various machine learning models, particularly in text-based tasks such as text classification and sentiment analysis. In this section, we explore how they are used as features in machine learning and discuss feature engineering and selection techniques.
One of the primary applications of machine learning is their use as features in predictive models. N-grams, representing sequences of words, capture the context and structure of text data.
- Text Classification: In tasks like spam detection, topic classification, or sentiment analysis, text documents are often represented as a matrix where rows correspond to documents and columns to n-grams. The presence or frequency of each gram in a document is used as a feature. Machine learning algorithms, such as Naïve Bayes, Support Vector Machines, or deep learning models, can then learn patterns from these features to make predictions.
- Sentiment Analysis: N-grams are instrumental in sentiment analysis, where the goal is to determine the emotional tone of a piece of text. Positive and negative sentiment-bearing word sequences, along with their frequency, can serve as features for sentiment classification tasks.
Feature Engineering and Selection:
Effective use of this technique in machine learning involves thoughtful feature engineering and selection techniques:
- N-gram Order Selection: The choice of n-gram order depends on the specific task. Unigrams (1-grams) are suitable for basic text analysis, while bigrams (2-grams) and trigrams (3-grams) capture more context. Higher-order word sequences provide even deeper context understanding. Feature selection can help determine the most informative n-gram order.
- Feature Engineering: Feature engineering is the process of selecting, transforming, or creating features to improve model performance. Techniques include:
- TF-IDF (Term Frequency-Inverse Document Frequency): This technique weighs the importance of an n-gram in a document relative to its frequency in the entire dataset. It can help downweight common word sequences while highlighting rare, potentially more informative ones.
- Feature Scaling: Scaling n-gram features to a common range, such as [0, 1] or [-1, 1], can mitigate issues related to feature magnitude and promote fair comparisons between different n-grams.
- Embeddings: For more advanced tasks, consider using word embeddings like Word2Vec or fastText to represent word sequences as dense vectors.
In conclusion, n-grams are a valuable resource for machine learning models in text-based tasks. They provide the context and linguistic structure necessary for understanding and making predictions about text data. By careful engineering and selecting n-gram features, machine learning models can leverage the power of word sequences to improve accuracy and performance in various NLP applications.
This is what you should take with you
- N-grams, ranging from unigrams to higher-order n-grams, are fundamental in natural language processing, providing insights into the context and structure of text data.
- They find applications in various NLP tasks, including sentiment analysis, text classification, information retrieval, and language modeling.
- They enable us to capture word associations, collocations, and linguistic patterns, improving language understanding and text analysis.
- N-grams are essential in statistical language modeling, contributing to models like n-gram models and Markov models, which predict the likelihood of word sequences.
- Word sequences come with challenges such as data sparsity, dimensionality, and sensitivity to word order, which can be addressed through techniques like smoothing and dimensionality reduction.
- N-grams serve as features in machine learning models, enhancing tasks like text classification and sentiment analysis.

What is a Boltzmann Machine?
Unlocking the Power of Boltzmann Machines: From Theory to Applications in Deep Learning. Explore their role in AI.

What is the Gini Impurity?
Explore Gini impurity: A crucial metric shaping decision trees in machine learning.

What is the Hessian Matrix?
Explore the Hessian matrix: its math, applications in optimization & machine learning, and real-world significance.

What is Early Stopping?
Master the art of Early Stopping: Prevent overfitting, save resources, and optimize your machine learning models.

What is RMSprop?
Master RMSprop optimization for neural networks. Explore RMSprop, math, applications, and hyperparameters in deep learning.

What is the Conjugate Gradient?
Explore Conjugate Gradient: Algorithm Description, Variants, Applications and Limitations.
Other Articles on the Topic of N-grams
Here you can find the Google N-gram viewer.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.