Q-Learning ist ein Algorithmus aus dem Bereich des Reinforcement Learnings, der versucht, anhand der aktuellen Umwelt des Agenten die nächstbeste Aktion vorherzusagen. Er wird vor allem zum Erlernen von Spielen genutzt, in der eine erfolgsversprechende Strategie herausgebildet werden soll.
Was ist Reinforcement Learning?
Reinforcement Learning Modelle sollen darauf trainiert werden, eine Reihe von Entscheidungen selbstständig zu treffen. Angenommen wir wollen einen solchen Algorithmus, den sogenannten Agenten, darauf trainieren das Spiel PacMan möglichst erfolgreich zu spielen. Der Agent startet auf einer beliebigen Stelle im Spielfeld und hat eine begrenzte Anzahl an möglichen Aktionen, die er ausführen kann. In unserem Fall wären das die vier Richtungen (oben, unten, rechts oder links), die er auf dem Spielfeld gehen kann.
Die Umwelt in der sich der Algorithmus in diesem Spiel befindet ist das Spielfeld und die Bewegung der Geister, denen man nicht begegnen darf. Nach jeder Aktion, beispielsweise gehe nach oben, erhält der Agent ein direktes Feedback, den Reward. Bei PacMan sind dies entweder das Erhalten von Punkten oder die Begegnung mit einem Geist. Es kann auch vorkommen, dass nach einer Aktion kein direkter Reward erfolgt, sondern dieser erst in Zukunft stattfindet, also beispielsweise erst in ein oder zwei weiteren Zügen. Für den Agenten sind Rewards, die in der Zukunft liegen, weniger wert als unmittelbare Rewards.
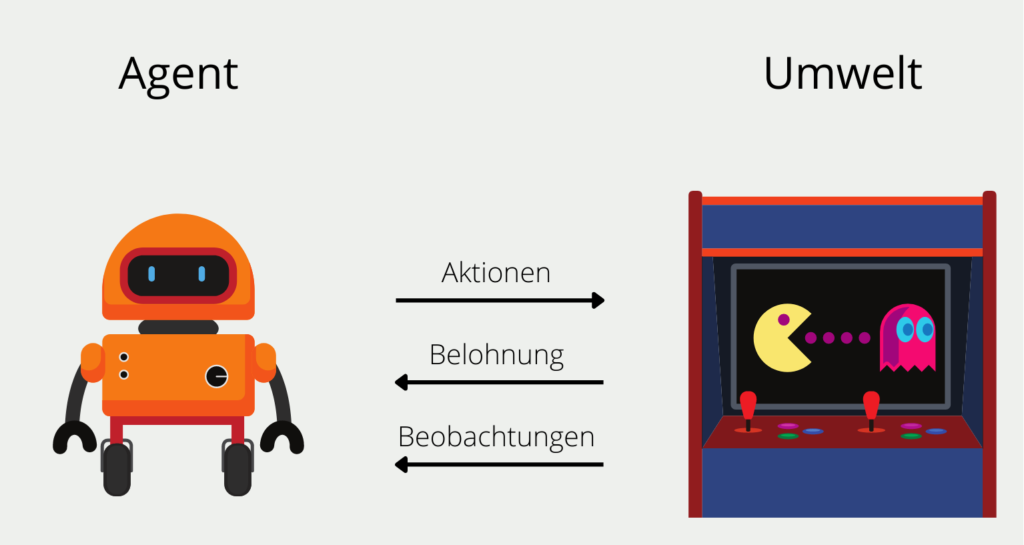
Über die Zeit bildet der Agent eine sogenannte Policy aus, also eine Strategie von Aktionen, die ihm langfristig den höchsten Reward versprechen. In den ersten Runden wählt der Algorithmus komplett zufällige Aktionen aus, da er noch keinerlei Erfahrungen sammeln konnte. Mit der Zeit jedoch bildet sich eine erfolgsversprechende Strategie heraus.
Was ist Q-Learning?
Q-Learning ist ein Reinforcement Learning Algorithmus, der in jedem Schritt versucht den Reward in Abhängigkeit von möglichen Aktionen zu maximieren. Man spricht bei diesem Algorithmus davon, dass er “model-free” und “off-policy”.
“model-free” bedeutet, dass der Algorithmus nicht auf die Modellierung einer Wahrscheinlichkeitsverteilung zurückgreift, also versucht die Antwort der Umgebung vorherzusagen. Ein “model-based” Ansatz in einem Spiel, wie beispielsweise PacMan, würde versuchen zu lernen, welchen Reward und welchen neuen State er erwarten kann, bevor er sich für eine Aktion entscheidet. Ein “model-free” Algorithmus hingegen, blendet das komplett aus und lernt vielmehr nach dem “Trial and Error” Prinzip, indem eine zufällige Aktion gewählt wird und erst danach bewertet wird, ob sie erfolgreich war oder nicht.
Die Eigenschaft “off-policy” meint dabei, dass das Modell erstmal keiner Policy folgt. Das heißt das Modell entscheidet zu jedem Zeitpunkt, welche Aktion bei der aktuellen Umwelt die beste ist, unabhängig, ob das zur bisher verfolgten Policy passt oder nicht. Das bedeutet, dass sich keine Strategien ergeben, die mehrere Züge involvieren, sondern lediglich in Schritten gedacht wird, die nur eine einzige Aktion beinhalten.
Wie läuft der Prozess ab?
Im Verlauf des Q-Learning Algorithmus werden verschiedene Schritte durchlaufen. Im Mittelpunkt steht dabei die q-Tabelle, die dem Algorithmus bei der Auswahl der richtigen Aktionen hilft. Die Anzahl der Reihen sind dabei die möglichen Zustände des Spiels, also für PacMan beispielsweise, dass man einem Geist begegnet oder Punkte sammelt. Die Anzahl der Spalten sind die Aktionen, die vorgenommen werden können, also die Richtungen in die man die Figur bewegen kann.
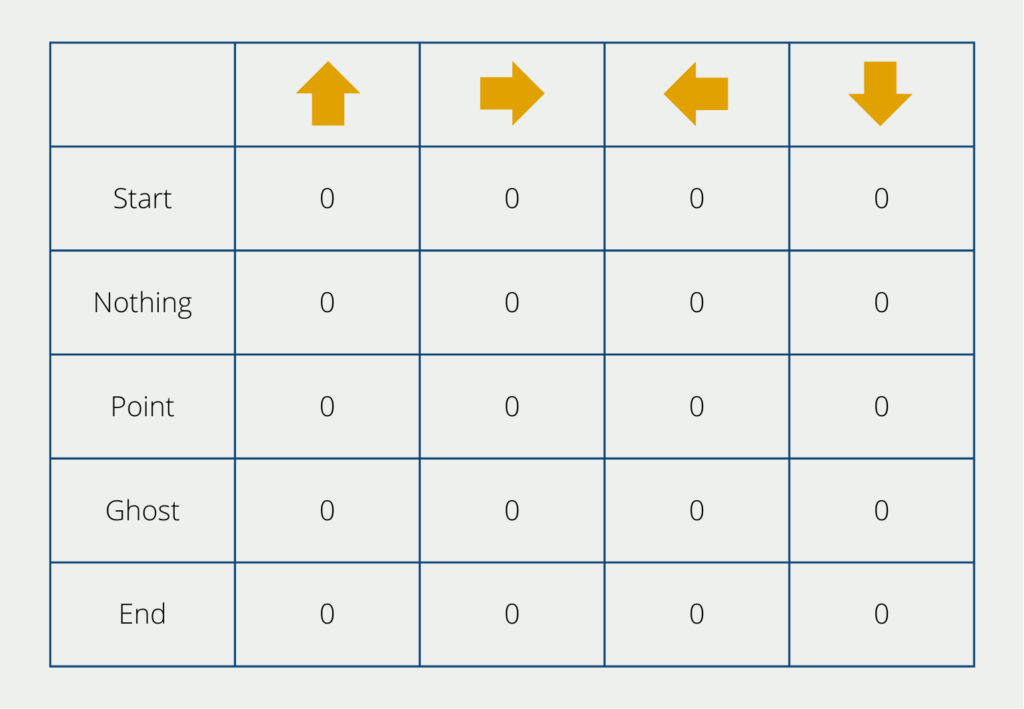
Am Anfang werden die Werte der Tabelle auf 0 gestellt. Im Laufe des Trainings verändern sich diese Werte ständig. Folgende Schritte werden während des Lernens durchlaufen:
Erstellen der q-Tabelle
Die Tabelle, wie wir sie bereits gesehen haben, wird erstellt und die einzelnen Werte müssen befüllt, also initialisiert, werden. In unserem Fall schreiben wir dafür in jedes Feld eine 0. Es können jedoch auch andere Methoden genutzt werden, um die Felder zu initialisieren.
Wahl einer Aktion
Nun beginnt der Algorithmus in seinem jeweiligen Status (am Anfang also Start) eine der möglichen Aktionen auszuwählen. Dabei nutzt der Algorithmus zwei verschiedene Herangehensweisen:
- Exploration: Am Anfang kennt das Modell noch keine Q-Werte und wählt die Aktionen zufällig aus. Dadurch erkundet es die einzelnen Statuse und erkennt neue Vorgehensweisen, die ansonsten unentdeckt geblieben wären.
- Exploitation: Während der Exploitation-Phase wird versucht, das Wissen aus der Exploration-Phase auszunutzen. Wenn also in der q-Tabelle schon belastbare Werte vorhanden sind, wählt der Algorithmus für jeden State genau die Aktion aus, die den höchsten, zukünftigen Reward verspricht.
Wie oft sich das Modell in der Exploration oder Exploitation befinden soll, kann über den sogenannten Epsilon-Wert eingestellt werden. Er entscheidet über das Verhältnis der beiden Wahlarten von Aktionen.
Überschreiben der q-Werte
Mit jeder Aktion, die der Agent während des Q-Learnings wählt, verändern sich auch die Werte in der q-Tabelle. Dies passiert so lange, bis ein vorgegebener Endpunkt erreicht wird und somit das Spiel zu einem Ende kommt. In PacMan ist dieser Punkt entweder erreicht, wenn man einem Geist begegnet oder wenn man alle Punkte im Spielfeld aufgesammelt hat. Das nächste Spiel kann dann schon mit den bereits erlernten q-Werten gestartet werden.
Nachdem der Agent eine Aktion in seinem Ausgangsstatus gewählt hat, erhält er einen Reward. Der q-Wert für das Feld des entsprechenden Status und der Aktion berechnet man dann mithilfe der folgenden Formel:
\(\) \[Q(S_{t}, A_{t}) = (1 – \alpha) \cdot Q(S_{t}, A_{t}) + \alpha \cdot (R_{t} + \lambda \cdot max_{\alpha} Q(S_{t + 1}, \alpha))\]
Dies sind die Bedeutungen der einzelnen Bestandteile:
- S steht für den State. Der Index t ist dabei der aktuelle State und der Index t+1 der zukünftige Status.
- A ist die Aktion, die der Algorithmus wählt.
- R ist der Reward, also die Auswirkung der getätigten Aktion. Dieser kann entweder positiv, wie beispielsweise ein zusätzlicher Punkt, oder negativ, wie beispielsweise die Begegnung mit einem Geist, sein.
- α ist die Lernrate, wie wir sie bereits aus anderen Modellen im Bereich Machine Learning kennen. Sie entscheidet wie stark der jetzt errechnete Wert, den bereits vorhandenen Wert der Tabelle überschreibt.
- λ ist der Discount Factor, also ein Faktor, der zukünftige Ereignisse weniger stark wertet wie gegenwärtige. Dieser Faktor führt dazu, dass der Algorithmus kurzfristige Rewards höher gewichtet, als zukünftige.
Diese Schleife wird so oft durchgeführt, wie im Code definiert ist oder bei Erreichnung eines Kriteriums auch frühzeitig beendet. Die dadurch entstehende q-Tabelle ist dann das Ergebnis des Q-Learnings Algorithmus und kann dann befragt werden.
Woher kommt der Name?
Das Q in Q-Learning steht für Qualität. Diese misst, wie wertvoll die nächste Aktion ist, um im darauffolgenden Schritt oder in der Zukunft einen Reward zu erhalten. Die q-Werte stammen aus der sogenannten q-Tabelle und werden anhand einer gegebenen Formel errechnet. Der q-Wert entscheidet darüber, ob eine Aktion als nächstes ausgeführt wird.
Was ist der Unterschied zwischen Q-Learning und G-Learning?
Sowohl Q-Learning als auch G-Learning sind Algorithmen, die im Bereich des Reinforcement Learnings eingesetzt werden, um optimale Strategien für sequenzielle, also aufeinanderfolgende Entscheidungen zu finden. In diesem Abschnitt wollen wir uns die Gemeinsamkeiten und Unterschiede der beiden Ansätze genauer anschauen.
Beim Q-Learning rücken die sogenannten Zustands-Aktions-Paare in den Mittelpunkt, für die ein sogenannter Q-Wert geschätzt wird, um eine optimale Strategie zu finden. Dafür wird eine Aktionswertfunktion \(Q(s,a)\) erlernt, die für jedes Paar aus Zustand und Aktion eine erwartete, kumulative Belohnung zurückgibt. Durch einen iterativen Prozess werden die Q-Werte aktualisiert, basierend auf den beobachteten Belohnungen und den darauffolgenden Zuständen des Systems. Dafür wird die Methode der zeitlichen Differenz verwendet.
Im Fokus des Q-Learnings steht also die Bewertung des aktuellen Zustands zusammen mit der optimalen nächsten Aktion. Dadurch erhält der Agent Informationen darüber, welche optimale Aktion er oder sie als nächstes ausführen sollte. Dazu wird einfach die Aktion mit dem höchsten Q-Wert gewählt. Diese Vorgehensweise bietet sich vor allem dann an, wenn eine konkrete Strategie erlernt werden soll und es außerdem einen diskreten Aktionsraum gibt, also eine wohldefinierte Menge an Aktionen bereitstehen, wie beispielsweise die Bewegungsmöglichkeiten bei Pacman. In der Praxis wird Q-Learning vor allem in der Robotik oder beim Erlernen von Spielen eingesetzt.
Das G-Learning hingegen versucht den Wert eines Zustands direkt zu schätzen, ohne dabei die möglichen Aktionen zu berücksichtigen. Die Zustandswertfunktion hat hier lediglich einen Inputparameter nämlich den Zustand, also \(G(s)\). Sie gibt für jeden Zustand die erwartete kumulative Belohung zurück. Analog zum Q-Learning wird für die Schätzung der Funktion die TD-Methode für iterative Aktualisierungen verwendet. Jedoch nutzt es für diese Aktualisierungen eben nur die Werte der Zustände und nicht die Aktionen. Das G-Learning eignet sich besonders für Anwendungen, die keine wohldefinierten Aktionsraum haben und bei denen die Belohnung des Zustands eine größere Rolle spielt, wie beispielsweise bei der Finanzanalyse oder bei medizinischen Entscheidungen.
Wie wir gesehen haben hängt die Wahl zwischen G-Learning und Q-Learnning von der Anwendung ab und von den Zielen, die das Modell erreichen soll. Wenn das Finden einer optimalen Strategie und die Bestimmung einer optimalen Aktion für jeden Zustand im Vordergrund steht, sollte das Q-Learning bevorzugt werden. Wenn hingegen verschiedene Zustände beurteilt und verglichen werden sollen ist das G-Learning besser geeignet.
Das solltest Du mitnehmen
- Q-Learning ist ein leistungsfähiger Verstärkungslernalgorithmus, der zur Lösung sequentieller Entscheidungsprobleme eingesetzt wird.
- Er lernt eine Aktionswertfunktion (Q-Werte), um die erwarteten kumulativen Belohnungen von Zustands-Aktionspaaren zu schätzen.
- Q-Learning nutzt die temporale Differenzmethode (TD), um die Q-Werte auf der Grundlage der beobachteten Belohnungen und der nachfolgenden Zustände iterativ zu aktualisieren.
- Der Algorithmus ermöglicht es den Agenten, optimale Entscheidungen zu treffen, indem sie in jedem Zustand die Aktionen mit den höchsten Q-Werten auswählen.
- Q-Learning eignet sich gut für Anwendungen mit diskreten Aktionsräumen, wie z. B. Spiele oder Robotik.
- Es wurde bereits erfolgreich in verschiedenen Bereichen eingesetzt, darunter autonomes Fahren, künstliche Intelligenz im Spiel und Robotik.
- Q-learning bietet einen Rahmen für das Lernen und Optimieren von Strategien in komplexen Umgebungen.
- Durch ein Gleichgewicht zwischen Erkundung und Ausbeutung ermöglicht Q-Learning den Agenten, ihre Entscheidungsfindung im Laufe der Zeit zu verbessern.
- Das Verständnis des Q-Learnings und der ihm zugrundeliegenden Prinzipien ist entscheidend für die Beherrschung von Reinforcement-Learning-Techniken.
- Weitere Forschungen und Fortschritte im Bereich des Q-Learnings werden seine Anwendungsmöglichkeiten erweitern und seine Leistung verbessern.

Was ist die Grid Search?
Optimieren Sie Ihre Modelle für maschinelles Lernen mit Grid Search. Erforschen Sie die Abstimmung von Hyperparametern mit Python.

Was ist die Lernrate?
Entfalten Sie die Kraft der Lernraten beim maschinellen Lernen: Tauchen Sie ein in Strategien, Optimierung und Feinabstimmung für Modelle.

Was ist die Random Search?
Optimieren Sie Modelle für maschinelles Lernen: Lernen Sie, wie die Random Search Hyperparameter effektiv abstimmt.

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.

Was ist der Omitted Variable Bias?
Verständnis des Omitted Variable Bias: Ursachen, Konsequenzen und Prävention. Erfahren Sie, wie Sie diese Falle vermeiden.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.
Andere Beiträge zum Thema Q-Learning
Dieser Beitrag der Publikation Towards Data Science erklärt den Q-Learning Algorithmus ausführlich und implementiert ihn in Python.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.