Das Reinforcement Learning (Deutsch: Bestärkendes Lernen) ist neben Supervised, Unsupervised und Semi-Supervised Learning die vierte, große Lernmethode im Bereich des Machine Learnings. Der Hauptunterschied besteht darin, dass das Modell wenig Datenmaterial zum Trainieren benötigt. Es erlernt Strukturen, indem es für gewünschte Verhaltensweisen belohnt und für schlechte bestraft wird.
Was sind Anwendungsfälle für Reinforcement Learning?
Bevor wir uns im Detail anschauen können, wie der Ablauf eines Trainings bei solchen Modellen aussieht, sollten wir verstehen, in welchen Situationen diese Modelle helfen können:
- Bestärkendes Lernen wird genutzt, wenn man einem Computer beibringen will Spiele zu spielen. Es soll gelernt werden, welche Taktiken zum Sieg führen und welche nicht.
- Beim Autonomen Fahren kommen diese Lernalgorithmen auch zum Einsatz, damit das Fahrzeug von selbst entscheiden kann, welche Handlungsoption die Beste ist.
- Für die Klimatisierung von Server Räumen werden auch Reinforcement Learning Modelle genutzt, die entscheiden, wann und wie stark man den Raum herunterkühlen muss.
Die Anwendungen von Reinforcement Learning sind im Allgemeinen dadurch gekennzeichnet, dass eine Vielzahl von aufeinanderfolgenden Entscheidungen getroffen werden müssen. Diese könnte der Programmierer auch konkret dem Computer vorschreiben (Beispiel Raumtemperatur: “Wenn die Temperatur über 24 °C steigt, dann kühle runter auf 20 °C”).
Mithilfe von Bestärkendem Lernen will man jedoch verhindern eine Kette von Wenn-Dann-Bedingungen zu formulieren. Zum einen kann dies in vielen Anwendungsfällen, wie beispielsweise dem Autonomen Fahren, schlicht unmöglich sein, da der Programmierer nicht alle Eventualitäten absehen kann. Zum anderen erhofft man sich durch diese Modelle auch die Entwicklung von neuen Strategien für komplexe Fragestellungen, zu denen ein Mensch möglicherweise auch gar nicht in der Lage wäre.
Wie funktioniert Reinforcement Learning?
Reinforcement Learning Modelle sollen darauf trainiert werden, eine Reihe von Entscheidungen selbstständig zu treffen. Angenommen wir wollen einen solchen Algorithmus, den sogenannten Agenten, darauf trainieren das Spiel Pac-Man möglichst erfolgreich zu spielen. Der Agent startet auf einer beliebigen Stelle im Spielfeld und hat eine begrenzte Anzahl an möglichen Aktionen, die er ausführen kann. In unserem Fall wären das die vier Richtungen (oben, unten, rechts oder links), die er auf dem Spielfeld gehen kann.
Die Umwelt in der sich der Algorithmus in diesem Spiel befindet ist das Spielfeld und die Bewegung der Geister, denen man nicht begegnen darf. Nach jeder Aktion, beispielsweise gehe nach oben, erhält der Agent ein direktes Feedback, den Reward. Bei Pac-Man sind dies entweder das Erhalten von Punkten oder eine Begegnung mit einem Geist. Es kann auch vorkommen, dass nach einer Aktion kein direkter Reward erfolgt, sondern dieser erst in Zukunft stattfindet, also beispielsweise erst in ein oder zwei weiteren Aktionen. Für den Agenten sind Rewards, die in der Zukunft liegen, weniger wert als unmittelbare Rewards.
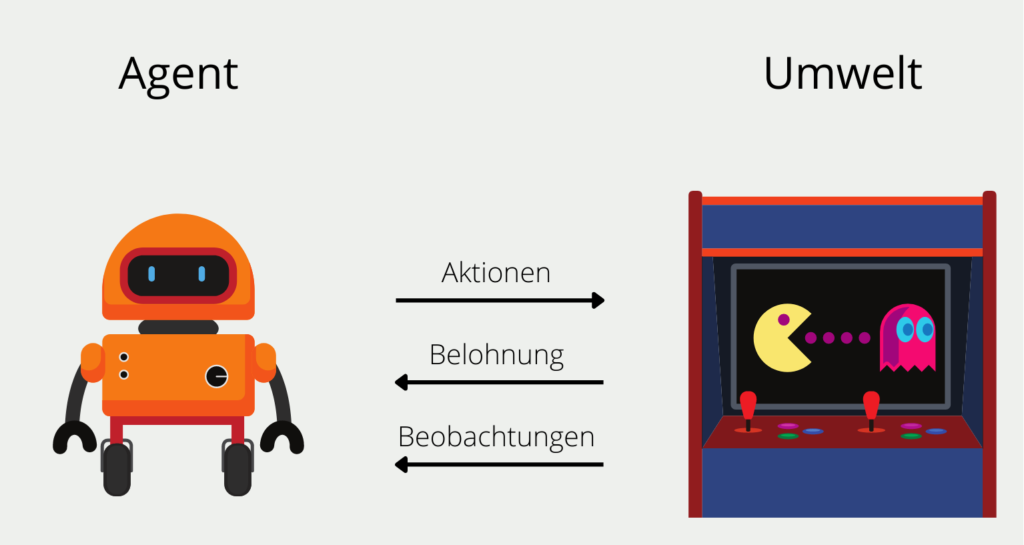
Über die Zeit bildet der Agent eine sogenannte Policy aus, also eine Strategie von Aktionen, die ihm langfristig den höchsten Reward versprechen. In den ersten Runden wählt der Algorithmus komplett zufällige Aktionen aus, da er noch keinerlei Erfahrungen sammeln konnte. Mit der Zeit jedoch bildet sich eine erfolgsversprechende Strategie heraus.
Welche Konzepte gibt es im Reinforcement Learning?
Neben den Begrifflichkeiten, die bereits in der Erklärung genannt wurden, gibt es noch andere Konzepte, die im Bereich des Reinforcement Learnings von Bedeutung sind:
- Agent: Das Modell, welches trainiert werden soll, und Stück für Stück Entscheidungen trifft, für die es entweder bestraft oder belohnt wird.
- Environment: Die Szenarios oder das Spielfeld, welches der Agent im Laufe des Spiels erkundet und welches über die Konsequenzen der Handlungen entscheidet.
- Reward: Das Ergebnis einer Handlung, welches nach jedem Schritt erfolgt. Der Reward muss nicht unbedingt positiv sein, sondern kann auch eine “Bestrafung” für das Modell bedeuten.
- State: Aktuelle Situation in der sich der Agent befindet, beispielsweise die Position auf dem Spielfeld.
- Policy: Dies ist die Strategie, die der Agent mit der Zeit entwickelt, um über die nächste Aktion zu entscheiden. Am Anfang ist dies meist eine reine Zufallsentscheidung und gegen Ende des Trainings hat sich daraus eine richtige Strategie entwickelt.
- Value Function: Diese Funktion legt fest, wie hoch oder niedrig der Reward nach einer Aktion ausfällt. In vielen Fällen sind darin die Regeln des Spiels abgebildet, das erlernt werden soll.
- Q-Value: Dieser Wert ist genauer gesagt eine Funktion, die als Eingabe ein Zustands-Aktions-Paar nimmt und die erwartete kumulative Belohnung ausgibt, die ein Agent erhält, wenn er diese Aktion in diesem Zustand ausführt. Die Funktion ist somit die Entscheidungshilfe für den Agenten, wie er sich in der jeweiligen Situation am Besten verhält, um eine möglichst hohe Wahrscheinlichkeit des Erfolgs zu haben.
Welche Unterschiede gibt es zwischen den Machine Learning Lernmethoden?
Im Bereich des Machine Learning unterscheidet man insgesamt vier verschiedene Lernmethoden:
- Supervised Learning Algorithmen erlernen Zusammenhänge mithilfe eines Datensatzes, der bereits das Label enthält, welches das Modell vorhersagen soll. Sie können jedoch nur Strukturen erkennen und erlernen, die in den Trainingsdaten enthalten sind. Supervised Modelle werden beispielsweise in der Klassifizierung von Bildern eingesetzt. Mithilfe von Bildern, die bereits einer Klasse zugeordnet sind, lernen Sie Zusammenhänge zu erkennen, die sie dann auf neue Bilder anwenden können.
- Unsupervised Learning Algorithmen lernen aus einem Datensatz, der diese Labels jedoch noch nicht hat. Sie versuchen eigene Regeln und Strukturen zu erkennen, um die Daten in Gruppen einteilen zu können, die möglichst gleiche Eigenschaften aufweisen. Unsupervised Learning kann beispielsweise genutzt werden, wenn man Kunden in Gruppen aufteilen will, anhand gemeinsamer Merkmale. Dazu können zum Beispiel die Bestellhäufigkeit oder die Bestellhöhe genutzt werden. Welche Eigenschaften das Modell konkret nutzt, entscheidet es selbst.
- Semi-Supervised Learning ist die Mischung aus Supervised Learning und Unsupervised Learning. Das Modell hat einen relativ kleinen Datensatz mit Labels zur Verfügung und einen deutlich größeren Datensatz mit unbeschrifteten Daten. Das Ziel ist es, aus den wenigen beschrifteten Daten Zusammenhänge zu lernen und diese in dem unbeschrifteten Datensatz zu testen, um daraus zu lernen.
- Das Reinforcement Learning unterscheidet sich zu den bisherigen Methoden darin, dass es keine Trainingsdaten braucht, sondern lediglich über das beschriebene Belohnungssystem funktioniert und lernt.

Benötigt Reinforcement Learning viele Trainingsdaten?
Ja, auch Reinforcement Learning Modelle benötigen zum Trainieren Daten. Doch im Vergleich zu anderen Machine Learning Methoden müssen diese Informationen nicht in einem externen Datensatz gegeben sein, sondern können während des Trainings erstellt werden.
In der Welt des Machine Learnings sind Daten unabdingbar, um gute und robuste Modelle zu trainieren. Beim Supervised Learning werden dazu von Menschen gelabelte Daten verwendet, die am Besten in großer Menge vorhanden sind. Das ist meist teuer und die Datensätze sind nur sehr schwierig zu bekommen oder zu erstellen. Beim Unsupervised Learning hingegen werden zwar auch viele Daten benötigt, diese müssen aber nicht ein konkretes Label besitzen. Das macht die Beschaffung von Informationen deutlich günstiger und einfacher.
Reinforcement Learning ist wie wir bereits gesehen komplett konträr zum Supervised und Unsupervised Learning. Nichtsdestotrotz gilt auch hier der Grundsatz, dass eine größere Datenmenge im Allgemeinen auch zu besseren Trainingsergebnissen führt. Der Unterschied zu den anderen Arten von Machine Learning Modellen ist jedoch, dass diese Daten nicht unbedingt extern zugeführt werden, sondern vom Modell selbst erzeugt werden.
Nehmen wir als Beispiel das Erlernen eines Spiels: Ein Machine Learning Modell wird darauf trainiert das Spiel zu gewinnen, d.h. Züge die zu einem Sieg führen werden als positiv gewertet und Züge, die zu einer Niederlage führen als negativ. In diesem Szenario kann das Modell viele Spieldurchläufe als Trainingsdaten nutzen, da das Ziel “Spiel gewinnen” eindeutig definiert ist. Mit jedem neuen Spiel in dem das Modell lernt, werden neue Trainingsdaten erzeugt und das Modell wird besser.
Ist Reinforcement Learning die Zukunft von Deep Learning?
Reinforcement Learning wird Deep Learning auch in Zukunft nicht ersetzen können. Diese zwei Teilbereiche sind zwar stark miteinander verbunden sind jedoch nicht dasselbe. Deep Learning Algorithmen sind sehr gut geeignet, Strukturen in großen Datensätzen zu erkennen und auf neue, unbekannte Daten anzuwenden. Reinforcement Learning Modelle hingegen führen Entscheidungen herbei, auch ohne Trainingsdatensätze.
In vielen Teilbereichen werden auch weiterhin Machine Learning und Deep Learning Modell ausreichend sein, um ein gutes Ergebnis zu erzielen. Der Erfolg von Reinforcement Learning führt hingegen dazu, dass nun auch neue Bereiche von Künstlicher Intelligenz erschlossen werden können, die vorher undenkbar werden. Es gibt jedoch auch Anwendungen, wie beispielsweise das Handeln von Aktien, in denen das Bestärkende Lernen Deep Learning Modelle ablösen wird, da es bessere Ergebnisse liefert.
In diesem Bereich wurde bisher versucht, das Erkennen und Handeln von neuen Aktien aus vergangenen Marktdaten erlernen zu können. Für das Aktiengeschäft kann es jedoch deutlich vielversprechender sein einen Reinforcement Learning Algorithmus darauf zu trainieren eine konkrete Strategie zu entwickeln, unabhängig von vergangenen Daten.
Das solltest Du mitnehmen
- Reinforcement Learning bezeichnet eine Lernmethode im Bereich des Machine Learnings.
- Es bezeichnet Modelle, die darauf trainiert werden eine Abfolge von Entscheidungen vorhersagen zu können, die eine möglichst hohe Erfolgsquote versprechen.
- Neben dem Reinforcement Learning gibt es noch das Supervised Learning, das Unsupervised Learning und das Semi-Supervised Learning.
- Als Vorteil des Reinforcement Learnings wird oft gesehen, dass keine großen Datensätze im Vorhinein benötigt werden, sondern diese während dem Training selbst erstellt werden.
- Reinforcement Learning wird beispielsweise genutzt, um Computern Spiele beizubringen oder die richtigen Entscheidungen beim Autonomen Fahren zu treffen.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.

Was ist die Singular Value Decomposition?
Erkenntnisse und Muster freilegen: Lernen Sie die Leistungsfähigkeit der Singular Value Decomposition (SVD) in der Datenanalyse kennen.

Was ist die Poisson Regression?
Lernen Sie die Poisson-Regression kennen, ein statistisches Modell für die Analyse von Zähldaten, inkl. einem Beispiel in Python.

Was ist blockchain-based AI?
Entdecken Sie das Potenzial der blockchain-based AI in diesem aufschlussreichen Artikel über Künstliche Intelligenz und Blockchain.
Andere Beiträge zum Thema Reinforcement Learning
- Dieses interessante Video zeigt, wie man einer Künstlichen Intelligenz das Parken eines Autos mithilfe von Reinforcement Learning beibringen kann.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.