Gibbs-Sampling ist eine grundlegende und vielseitige Technik in der Bayes’schen Statistik und im maschinellen Lernen. Sie wird häufig zur Lösung komplexer Probleme eingesetzt, bei denen herkömmliche Methoden versagen können. In diesem umfassenden Leitfaden wird das Gibbs-Sampling eingehend erläutert, wobei seine Prinzipien, Anwendungen, Vorteile und seine Implementierung untersucht werden.
Was ist Gibbs-Sampling?
Gibbs-Sampling ist eine Markov-Chain-Monte-Carlo-Methode (MCMC), die verwendet wird, um Stichproben aus komplexen Wahrscheinlichkeitsverteilungen zu ziehen, insbesondere aus solchen mit vielen Variablen. Sie ist nach dem Physiker Josiah Willard Gibbs benannt. Die Grundidee des Gibbs-Sampling besteht darin, jede Variable einer multivariaten Verteilung in Abhängigkeit von den Werten aller anderen Variablen zu ziehen. Durch die iterative Aktualisierung einer Variablen nach der anderen konvergiert diese Stichprobe schließlich zur Zielverteilung.
Warum ist Gibbs-Sampling für die Bayes’sche Inferenz von Bedeutung?
Die Bayes’sche Inferenz, ein grundlegender Ansatz im Bereich der Statistik und der probabilistischen Modellierung, konzentriert sich auf die Konstruktion von Modellen, die die Beziehungen zwischen beobachteten Daten, latenten Variablen und Modellparametern ausdrücken. Bei komplexen Modellen, für die es keine analytischen Lösungen zur Parameterschätzung gibt, erweist sich das Gibbs-Sampling als eine vielseitige und leistungsstarke Technik zur Schätzung der posterioren Wahrscheinlichkeitsverteilungen.
Im Kern geht es bei der Bayes’schen Inferenz um die Schätzung der posterioren Verteilung der Modellparameter, die die aktualisierten Überzeugungen über diese Parameter nach der Assimilation der beobachteten Daten darstellt. An dieser Stelle kommt das Gibbs-Sampling ins Spiel, das eine systematische Methodik zur Ziehung von Stichproben aus der gemeinsamen Posteriorverteilung aller Modellparameter bietet. Im Gegensatz zu einigen anderen Markov-Chain-Monte-Carlo-Methoden (MCMC) verfolgt Gibbs Sampling einen besonderen Ansatz: Es aktualisiert einen Parameter nach dem anderen, abhängig von den aktuellen Werten aller anderen Parameter. Dieser sequentielle, iterative Prozess verwandelt sie in eine Markov-Kette, in der jede Variable auf der Grundlage ihrer Posterior-Verteilung unter Berücksichtigung der anderen Variablen sequentielle Aktualisierungen erfährt.
Um Gibbs-Sampling effektiv durchführen zu können, müssen die Praktiker die bedingten Posterior-Verteilungen für jeden Parameter oder jede latente Variable im Modell unter Berücksichtigung aller anderen Variablen ableiten. Diese bedingten Verteilungen können durch analytische oder numerische Methoden ermittelt werden. Mit diesen Verteilungen in der Hand geht der Gibbs-Sampling-Algorithmus iterativ vor. Mit zunehmender Anzahl der Iterationen konvergieren die aus der Kette gezogenen Stichproben schrittweise gegen die wahre Posteriorverteilung.
Gibbs-Sampling eignet sich besonders gut für die Verwaltung komplexer Modelle, die durch zahlreiche Parameter und komplizierte Abhängigkeiten gekennzeichnet sind. Es vereinfacht die schwierige Aufgabe des Samplings aus hochdimensionalen Posterior-Verteilungen, indem es sie in eine Sequenz von sequentiellen Aktualisierungen aufteilt, einen Parameter nach dem anderen. Dies ist ein entscheidender Vorteil, wenn es um Modelle geht, die komplizierte strukturelle oder bedingte Beziehungen umfassen.
In der Praxis findet das Gibbs-Sampling in verschiedenen Bereichen Anwendung, z. B. beim maschinellen Lernen, der Bayes’schen Datenanalyse, der Bildverarbeitung und der Verarbeitung natürlicher Sprache. Es befähigt Bayesianer, eine breite Palette von Problemen zu bewältigen, indem es probabilistische und Unschärfemodelle einführt und letztlich datengesteuerte, probabilistische und kontextbewusste Lösungen ermöglicht. Gibbs Sampling ist ein wesentliches Werkzeug im Bayes’schen Werkzeugkasten, das zum probabilistischen Verständnis komplexer Phänomene beiträgt und eine robuste statistische Entscheidungsfindung ermöglicht.
Wie funktioniert das Gibbs-Sampling-Verfahren?
Gibbs Sampling ist eine Markov Chain Monte Carlo (MCMC) Technik, die zur Schätzung komplexer Wahrscheinlichkeitsverteilungen verwendet wird. Sie ist besonders wertvoll in der Bayes’schen Statistik und beim maschinellen Lernen, wenn die Posterior-Verteilung nur schwer direkt zu berechnen ist. Die Methode ermöglicht es uns, Stichproben aus hochdimensionalen Wahrscheinlichkeitsverteilungen zu ziehen, was sie zu einem vielseitigen Werkzeug in verschiedenen Bereichen macht.
Der Kerngedanke des Sampling-Prozesses besteht darin, jeweils eine Variable zu samplen, während alle anderen Variablen konstant gehalten werden. Durch iterative Aktualisierung der einzelnen Variablen erhalten wir schließlich eine Folge von Stichproben, die gegen die gemeinsame Verteilung aller Variablen konvergiert. Hier eine schrittweise Aufschlüsselung des Stichprobenverfahrens:
- Initialisierung: Beginne mit einer ersten Schätzung für die Werte der Variablen im Modell. Diese Anfangswerte können die Konvergenz des Gibbs-Samplers erheblich beeinflussen.
- Iteratives Sampling: Der Schlüssel ist der iterative Prozess. In jeder Iteration wird eine Variable zur Aktualisierung ausgewählt, während alle anderen Variablen unverändert bleiben. Die Wahl der Reihenfolge, in der die Variablen aktualisiert werden, kann willkürlich sein oder auf bestimmten Kriterien beruhen.
- Bedingte Verteilung: Für die ausgewählte Variable wird eine Stichprobe aus ihrer bedingten Verteilung unter Berücksichtigung der aktuellen Werte aller anderen Variablen gezogen. Dieser Schritt erfordert die Kenntnis der bedingten Verteilung, die in Bayes’schen Modellen oft vorhanden ist.
- Werte aktualisieren: Ersetze den aktuellen Wert der ausgewählten Variable durch den abgetasteten Wert. Jetzt hat das System neue Werte für diese Variable, während alle anderen Variablen unverändert bleiben.
- Wiederholen: Setze diesen iterativen Prozess für eine große Anzahl von Iterationen fort oder bis Konvergenz erreicht ist. Die Konvergenz wird in der Regel durch Untersuchung der Stabilität der Stichprobenfolgen beurteilt.
- Stichproben sammeln: Im Verlauf des Gibbs-Sampling-Prozesses wird für jede Variable eine Folge von Stichproben erzeugt. Diese Sequenzen bilden zusammen eine Annäherung an die gemeinsame Verteilung aller Variablen.
- Analysieren der Ergebnisse: Nach Abschluss des Gibbs-Sampling-Prozesses können die gesammelten Stichproben verwendet werden, um die posteriore Verteilung zu schätzen, posteriore Mittelwerte und Varianzen zu berechnen und probabilistische Schlüsse über die Parameter des Modells zu ziehen.
- Bewertung der Konvergenz: Die Überwachung der Konvergenz des Gibbs-Samplers ist unerlässlich. Konvergenzdiagnosewerkzeuge wie Trace Plots, Autokorrelationsplots und der Geweke-Test können helfen sicherzustellen, dass die generierten Stichproben die wahre Verteilung repräsentieren.
Durch Stichprobenziehung aus der bedingten Verteilung jeder Variablen, während die anderen Variablen konstant gehalten werden, erzeugt Gibbs Sampling eine Markov-Kette, die schließlich zur Zielverteilung konvergiert. Die Effektivität dieser Technik zeigt sich besonders in Situationen, in denen die gemeinsame Verteilung komplex und mehrdimensional ist oder in denen exakte Lösungen schwierig abzuleiten sind.
Die Fähigkeit, Bayes’sche Schlüsse zu ziehen, Posterior-Verteilungen zu untersuchen und komplexe Modelle zu schätzen, macht Gibbs Sampling zu einem wertvollen Hilfsmittel in der statistischen Analyse, dem maschinellen Lernen und der Datenwissenschaft. Seine Anpassungsfähigkeit an benutzerdefinierte Modelle und hierarchische Strukturen unterstreicht seine Bedeutung zusätzlich.
Was sind Konvergenz und Vermischung beim Gibbs-Sampling?
Konvergenz und Mischen sind entscheidende Faktoren bei der Anwendung von Gibbs Sampling, da sie die Zuverlässigkeit und Effizienz der durch diese MCMC-Methode erzeugten Markov-Kette bestimmen. Im Zusammenhang mit Gibbs-Sampling bezieht sich Konvergenz auf die Vorstellung, dass sich die erzeugten Stichproben mit dem Fortschreiten des Algorithmus der wahren zugrunde liegenden Verteilung annähern. Die Vermischung hingegen bezieht sich darauf, wie gut die Markov-Kette den Parameterraum erkundet und effizient Stichproben aus verschiedenen Regionen zieht. Gehen wir nun näher auf diese Konzepte ein:
- Bewertung der Konvergenz:
Konvergenz ist die zentrale Voraussetzung dafür, dass eine MCMC-Methode zuverlässige Ergebnisse liefert. Beim Gibbs-Sampling geht es bei der Bewertung der Konvergenz darum, festzustellen, ob die Markov-Kette einen Zustand erreicht hat, in dem die gesampelten Werte nahe genug an der wahren Posterior-Verteilung liegen.
Gängige Methoden zur Beurteilung der Konvergenz sind:
- Visuelle Inspektion: Aufzeichnung von Trace-Plots und Autokorrelationsplots, um zu prüfen, ob ein unregelmäßiges Verhalten vorliegt, und um sicherzustellen, dass sich die abgetasteten Werte im Laufe der Zeit stabilisieren.
- Gelman-Rubin-Statistik (R-Hat): Diese Statistik vergleicht die Varianz innerhalb und zwischen mehreren Ketten, um zu beurteilen, ob sie zur gleichen Verteilung konvergiert haben. Ein R-Hat-Wert nahe bei 1 weist auf Konvergenz hin.
- Effektiver Stichprobenumfang (ESS): Der ESS-Wert gibt an, wie viele unabhängige Stichproben den von der Markov-Kette erzeugten autokorrelierten Stichproben entsprechen. Höhere ESS-Werte deuten auf eine bessere Konvergenz hin.
- Kernel-Dichte-Schätzung: Aufzeichnung der Kernel-Dichte-Schätzungen von Stichproben aus verschiedenen Ketten zur Visualisierung der Konvergenz.
2. Vermischung bei Gibbs Sampling:
Die Vermischung misst die Effizienz der Markov-Kette bei der Erkundung des Parameterraums. Eine gut gemischte Kette nimmt effizient Stichproben aus allen Regionen von Interesse und vermeidet Situationen, in denen die Kette in lokalen Optima stecken bleibt oder den Raum zu langsam erkundet.
Zu den Faktoren, die das Mischen beeinflussen, gehören:
- Parametrisierung: Die Wahl einer geeigneten Parametrisierung kann das Mischen erheblich beeinflussen. Es ist wichtig, Parametrisierungen zu wählen, die effiziente Übergänge zwischen den Zuständen fördern.
- Anfangswerte: Die Wahl der Anfangswerte kann die Durchmischung beeinflussen. Wenn die Kette weit entfernt von Regionen mit hoher Wahrscheinlichkeitsdichte beginnt, kann eine längere Einlaufphase erforderlich sein, um die stationäre Verteilung zu erreichen.
- Adaptives Sampling: Einige adaptive Gibbs-Sampling-Algorithmen passen das Sampling-Schema während der Entwicklung der Kette an, um die Durchmischung zu verbessern. Beispielsweise kann der Metropolis-angepasste Gibbs-Sampler verwendet werden, um vorgeschlagene Stichproben adaptiv zu akzeptieren oder zurückzuweisen und so die Durchmischung zu verbessern.
- Ausdünnen: Manchmal kann die Ausdünnung der Markov-Kette, d. h. die Entnahme von nur jeder “k”-Stichprobe, die Autokorrelation verringern und die Durchmischung verbessern. Dadurch kann sich jedoch der effektive Stichprobenumfang verringern.
- Verbesserung der Konvergenz und Vermischung:
Um Konvergenz- und Mischungsprobleme zu lösen, solltest Du folgende Strategien in Betracht ziehen:
- Erhöhung der Anzahl der Iterationen (Stichproben), um der Markov-Kette mehr Zeit zur Erkundung und Konvergenz zu geben.
- Experimentieren mit verschiedenen Initialisierungsstrategien, um sicherzustellen, dass die Kette in einer Region mit hoher Wahrscheinlichkeitsdichte beginnt.
- Wähle anspruchsvollere Vorschlagsverteilungen, die eine effiziente Mischung und Konvergenz fördern.
- Ziehe alternative MCMC-Methoden wie Hamiltonian Monte Carlo (HMC) oder Sequential Monte Carlo (SMC) in Betracht, wenn Gibbs Sampling Probleme mit der Konvergenz hat.
Zusammenfassend lässt sich sagen, dass Konvergenz und Mischen wichtige Aspekte des Gibbs-Sampling sind. Die Bewertung der Konvergenz gewährleistet die Zuverlässigkeit der erzeugten Stichproben, während eine gute Durchmischung garantiert, dass die Markov-Kette den Parameterraum effizient erforscht. Das Verständnis dieser Konzepte und die Anwendung geeigneter Diagnosen ist für die praktische Anwendung von Gibbs-Sampling entscheidend.
Was sind die Anwendungen von Gibbs-Sampling?
Gibbs Sampling hat ein breites Spektrum an Anwendungen in verschiedenen Bereichen. Hier sind ein paar bemerkenswerte Beispiele:
- Probabilistische grafische Modelle: Gibbs Sampling wird in grafischen Modellen wie Markov Random Fields (MRFs) und Bayes’schen Netzen für Aufgaben wie Bildentrauschung, Bildsegmentierung und Strukturlernen verwendet.
- Modelle für latente Variablen: In Fällen, in denen einige Variablen unbeobachtet (latent) sind, hilft es bei der Schätzung der Werte der verborgenen Variablen.
- Textanalyse: Bei der Verarbeitung natürlicher Sprache kann Gibbs-Sampling auf Themenmodellierung, Dokumentenklassifizierung und Stimmungsanalyse angewendet werden.
- Bayes’sche Regression: Sie wird zur Durchführung der Bayes’schen linearen Regression verwendet, die eine Modellierung der Unsicherheit der Regressionskoeffizienten ermöglicht.
- Ising-Modell: In der statistischen Physik hilft das Gibbs-Sampling bei der Simulation des Ising-Modells, das die magnetischen Eigenschaften von Materialien beschreibt.
Was sind die Vor- und Nachteile von Gibbs-Sampling?
Gibbs-Sampling ist eine leistungsstarke Markov-Chain-Monte-Carlo-Technik (MCMC) mit mehreren Vorteilen, die sie zu einem wertvollen Werkzeug für verschiedene Anwendungen machen. Wie jede Methode hat sie jedoch auch gewisse Einschränkungen. Im Folgenden werden sowohl die Vorteile als auch die Nachteile untersucht:
Vorteile:
- Einfachheit und Flexibilität: Gibbs-Sampling ist konzeptionell einfach, insbesondere wenn es um hierarchische Modelle geht. Es bietet einen einheitlichen Rahmen für die Bayes’sche Analyse und vereinfacht komplexe Probleme in überschaubare bedingte Verteilungen.
- Angleichung komplexer Verteilungen: Gibbs-Sampling zeichnet sich in Situationen aus, in denen direkte Stichproben oder analytische Lösungen für komplexe Posterior-Verteilungen nicht durchführbar sind. Es geht effektiv mit hochdimensionalen Räumen um.
- Bayes’sche Inferenz: Sie ist ein Eckpfeiler der Bayes’schen Statistik. Sie ermöglicht die Schätzung von Posterior-Verteilungen, was für probabilistische Schlussfolgerungen, die Aktualisierung von Überzeugungen und das Verständnis von Unsicherheiten von entscheidender Bedeutung ist.
- Anpassbar: Die Methode ist sehr anpassungsfähig an verschiedene Modelle und Verteilungen. Praktiker können Gibbs-Sampling leicht für Modelle implementieren, die nicht mit Standardverteilungen übereinstimmen, was es zu einem vielseitigen Werkzeug in der Bayes’schen Analyse macht.
- Konvergenz: Bei richtiger Einstellung und Bewertung konvergieren Gibbs-Sampling-Ketten in der Regel zur wahren Posterior-Verteilung, was sie zu einem zuverlässigen Ansatz für die Schätzung unbekannter Parameter macht.
- Bedingte Unabhängigkeit: Die Methode nutzt bedingte Verteilungen, was oft zu schnellerer Konvergenz und effizientem Sampling führen kann. Diese Eigenschaft ist besonders nützlich, wenn die Variablen in einem Modell bedingte Unabhängigkeit aufweisen.
Nachteile:
- Erfordert Kenntnis der bedingten Verteilungen: Gibbs Sampling setzt die Kenntnis der bedingten Verteilungen der interessierenden Variablen voraus. Bei komplexen Modellen kann es schwierig sein, diese Verteilungen zu bestimmen, und es kann beträchtliche Fachkenntnisse erfordern.
- Berechnungsintensität: Bei hochdimensionalen Problemen kann der Gibbs Sampler rechenintensiv sein. Er kann eine große Anzahl von Iterationen erfordern, um Konvergenz zu erreichen, was den Sampling-Prozess verlangsamen kann.
- Probleme bei der Durchmischung: In bestimmten Situationen kann es zu einer schlechten Durchmischung kommen, bei der die Markov-Kette den Parameterraum zu langsam erkundet. Dies kann die Konvergenz behindern und zu ineffizienten Stichproben führen.
- Empfindlichkeit der Initialisierung: Die Qualität der Anfangswerte kann die Leistung des Gibbs-Samplers beeinflussen. Eine schlechte Initialisierung kann zu einer langsamen Konvergenz oder sogar Divergenz führen. Die Auswahl geeigneter Anfangswerte ist oft eine nicht triviale Aufgabe.
- Ist möglicherweise nicht für alle Szenarien geeignet: Obwohl diese Sampling-Methode eine leistungsstarke Technik ist, gibt es Fälle, in denen andere MCMC-Methoden, wie Metropolis-Hastings oder Hamiltonian Monte Carlo, besser abschneiden, insbesondere bei stark korrelierten oder nicht standardisierten Verteilungen.
Zusammenfassend lässt sich sagen, dass das Gibbs-Sampling ein wertvolles MCMC-Verfahren ist, das die Bayes’sche Analyse vereinfacht, komplexe Verteilungen handhabt und Posterior-Inferenzen liefert. Sie ist jedoch nicht ohne Einschränkungen, insbesondere in Bezug auf den Rechenaufwand, die Empfindlichkeit gegenüber der Initialisierung und die Herausforderungen in Szenarien mit multimodalen Verteilungen. Bei umsichtiger Anwendung und in Verbindung mit einer Konvergenzdiagnose ist das Gibbs-Sampling nach wie vor eine leistungsstarke Methode zur Bewältigung eines breiten Spektrums statistischer und maschineller Lernprobleme.
Wie kann man das Gibbs-Sampling in Python implementieren?
Hier ist ein einfaches Beispiel für die Implementierung von Gibbs-Sampling in Python. Wir verwenden zur Veranschaulichung eine bivariate Normalverteilung:
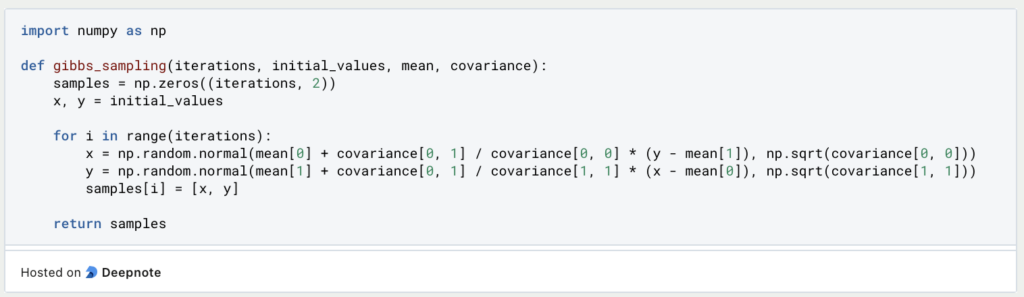
In diesem Beispiel führen wir Gibbs Sampling durch, um Stichproben aus einer bivariaten Normalverteilung zu erzeugen.
Was sind gängige Variationen und Erweiterungen von Gibbs Sampling?
Gibbs-Sampling ist eine leistungsstarke Markov-Chain-Monte-Carlo-Technik (MCMC), die jedoch verschiedene Variationen und Erweiterungen aufweist, um spezifische Herausforderungen zu bewältigen und die Effizienz in verschiedenen Szenarien zu verbessern.
- Blockiertes Gibbs-Sampling: Beim Standard-Gibbs-Sampling werden die Variablen der Reihe nach einzeln abgetastet. Beim Blocked Gibbs Sampling hingegen werden die Variablen in Blöcken gruppiert und alle Variablen innerhalb eines Blocks gleichzeitig abgetastet. Dies kann zu einer schnelleren Konvergenz führen, insbesondere in Fällen, in denen die Variablen stark voneinander abhängig sind.
- Adaptives Gibbs-Sampling: Bei diesem Ansatz wird die Vorschlagsverteilung für jede Variable während des Sampling-Prozesses auf der Grundlage der vergangenen Stichproben aktualisiert. Diese Anpassungsfähigkeit kann die Durchmischung der Markov-Kette verbessern und zu einer effizienteren Erkundung der Posterior-Verteilung führen.
- Slice Sampling: Slice Sampling ist eine Variante, die sich mit den Herausforderungen bei der Auswahl der Breite der Vorschlagsverteilung befasst. Es macht die Angabe von Vorschlagsbreiten überflüssig und ist damit für den Benutzer einfacher zu handhaben.
- Kollabiertes Gibbs-Sampling: Collapsed Gibbs Sampling wird verwendet, wenn bestimmte Variablen in einem Modell nicht als Stichprobe, sondern integriert werden. Dies reduziert die Dimensionalität des Problems und kann in bestimmten Fällen effizienter sein. Es wird häufig in Modellen mit latenten Variablen wie Latent Dirichlet Allocation (LDA) verwendet.
- Nichtparametrische Bayes’sche Modelle: Dieser Stichprobenansatz kann auf nichtparametrische Bayes’sche Modelle wie den Dirichlet-Prozess, den indischen Buffet-Prozess und den chinesischen Restaurant-Prozess ausgeweitet werden. Diese Modelle erlauben eine flexible Anzahl von Clustern oder Gruppen, so dass Gibbs Sampling in einem breiten Spektrum von Datenclustern und Klassifizierungsproblemen anwendbar ist.
- Hybride Sampling-Methoden: Forscher kombinieren häufig Gibbs-Sampling mit anderen MCMC-Methoden, um hybride Sampler zu erstellen, die die Stärken beider Ansätze nutzen. Gibbs-Sampling kann zum Beispiel innerhalb eines Metropolis-Hastings-Rahmens verwendet werden, um die Untersuchung komplexer Verteilungen zu verbessern.
Die Entscheidung, welche Gibbs-Sampling-Variante oder -Erweiterung verwendet werden soll, hängt von dem spezifischen Problem und seinen Merkmalen ab. Praktiker müssen bei der Auswahl des am besten geeigneten Gibbs-Sampling-Ansatzes die Art der Daten, des Modells und der Rechenbeschränkungen berücksichtigen. Diese Variationen und Erweiterungen veranschaulichen die Anpassungsfähigkeit von Gibbs-Sampling bei der Bewältigung eines breiten Spektrums von Herausforderungen und machen es zu einem vielseitigen Werkzeug bei der Bayes’schen Inferenz und probabilistischen Modellierung.
Das solltest Du mitnehmen
- Gibbs-Sampling ist eine grundlegende Technik der Bayes’schen Statistik, die die Schätzung komplexer Posterior-Verteilungen ermöglicht und einen Rahmen für probabilistische Schlussfolgerungen bietet.
- Die Eleganz der Methode liegt in ihrer Fähigkeit, Stichproben aus bedingten Verteilungen zu ziehen und so hochdimensionale Probleme in überschaubare Schritte zu zerlegen.
- Gibbs-Sampling ist in hohem Maße an verschiedene Modelle und Verteilungen anpassbar, was es zu einem vielseitigen Werkzeug für die Bayes’sche Analyse macht.
- In Fällen, in denen die bedingten Verteilungen konjugiert zu den vorherigen Verteilungen sind, kann Gibbs-Sampling eine hocheffiziente Stichprobenziehung ermöglichen.
- In hochdimensionalen Räumen kann das Gibbs-Sampling rechenintensiv sein und umfangreiche Iterationen zur Konvergenz erfordern.
- Die Qualität der Anfangswerte kann sich erheblich auf die Leistung des Gibbs-Samplers auswirken, was eine sorgfältige Prüfung während der Implementierung erfordert.
- Gibbs-Sampling ist zwar leistungsstark, aber nicht immer die beste Wahl. Bei schlechter Durchmischung, multimodalen Verteilungen oder Nicht-Standardmodellen können andere MCMC-Techniken wie Metropolis-Hastings oder Hamiltonian Monte Carlo besser geeignet sein.

Was ist ein Bias?
Auswirkungen und Maßnahmen zur Abschwächung eines Bias: Dieser Leitfaden hilft Ihnen, den Bias zu verstehen und zu erkennen.

Was ist die Varianz?
Die Rolle der Varianz in der Statistik und der Datenanalyse: Verstehen Sie, wie man die Streuung von Daten messen kann.

Was ist die KL Divergence (Kullback-Leibler Divergence)?
Erkunden Sie die Kullback-Leibler Divergence (KL Divergence), eine wichtige Metrik in der Informationstheorie und im maschinellen Lernen.

Was ist MLE: Maximum-Likelihood-Methode?
Verstehen Sie die Maximum-Likelihood-Methode (MLE), ein leistungsfähiges Werkzeug zur Parameterschätzung und Datenmodellierung.

Was ist der Varianzinflationsfaktor (VIF)?
Erfahren Sie, wie der Varianzinflationsfaktor (VIF) Multikollinearität in Regressionen erkennt, um eine bessere Datenanalyse zu ermöglichen.

Was ist die Dummy Variable Trap?
Entkommen Sie der Dummy Variable Trap: Erfahren Sie mehr über Dummy-Variablen, ihren Zweck und die Folgen der Falle.
Andere Beiträge zum Thema Gibbs-Sampling
Hier findest Du eine Vorlesung der Duke University zum Thema Gibbs-Sampling.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.