Im Bereich der Statistik und der datengesteuerten Entscheidungsfindung ist die Ermittlung der Parameter, die eine gegebene Wahrscheinlichkeitsverteilung am besten beschreiben, von grundlegender Bedeutung, um die zugrunde liegenden Prozesse zu verstehen und genaue Vorhersagen zu treffen. Die Maximum-Likelihood-Methode (MLE, von Maximum Likelihood Estimation) ist ein Eckpfeiler der statistischen Modellierung und bietet einen leistungsstarken Rahmen für das Erreichen dieses Ziels.
Stelle Dir vor, Du wärst in der Lage, die wahrscheinlichsten Werte für die Parameter zu ermitteln, die die Verteilung der Daten bestimmen – MLE ermöglicht genau dies und dient als Richtschnur für statistische Schlussfolgerungen. Diese Methode wird in zahllosen Anwendungen eingesetzt, vom Finanzwesen bis zur Biologie, und dient Entscheidungsträgern in den verschiedensten Bereichen als Leitfaden.
In diesem Artikel begeben wir uns auf eine Reise durch die Feinheiten der Maximum Likelihood Estimation. Wir werden die Kernkonzepte entschlüsseln, ihre mathematischen Grundlagen erforschen, praktische Anwendungen untersuchen und verstehen, wie dieses vielseitige Werkzeug es uns ermöglicht, wertvolle Erkenntnisse aus Daten zu gewinnen. Lass uns MLE entmystifizieren und sein immenses Potenzial im Bereich der statistischen Schlussfolgerungen entdecken.
Was sind Wahrscheinlichkeitsverteilungen?
Wahrscheinlichkeitsverteilungen sind ein grundlegendes Konzept in der Statistik und Wahrscheinlichkeitstheorie und bilden den Eckpfeiler für das Verständnis ungewisser Ereignisse und ihrer Wahrscheinlichkeiten. Eine Wahrscheinlichkeitsverteilung beschreibt die Wahrscheinlichkeit der verschiedenen Ergebnisse eines wahrscheinlichen Ereignisses. Sie ordnet jedem möglichen Ergebnis Wahrscheinlichkeiten zu und gibt an, wie wahrscheinlich jedes Ergebnis eintritt. Diese Wahrscheinlichkeiten folgen bestimmten Regeln und bieten eine strukturierte Möglichkeit zur Quantifizierung der Unsicherheit.
Bei einer diskreten Wahrscheinlichkeitsverteilung sind die möglichen Ergebnisse eindeutig und getrennt, wie z. B. die Ergebnisse eines Würfelwurfs. Eine kontinuierliche Wahrscheinlichkeitsverteilung hingegen befasst sich mit Ergebnissen, die einen kontinuierlichen Bereich bilden, wie z. B. die Höhe von Individuen in einer Population.
Schlüsselkonzepte:
- Wahrscheinlichkeits-Masse-Funktion (PMF): Die PMF definiert die Wahrscheinlichkeiten für jedes diskrete Ergebnis in einer diskreten Wahrscheinlichkeitsverteilung. Sie liefert ein vollständiges Profil des Verhaltens der Verteilung.
- Wahrscheinlichkeitsdichtefunktion (PDF): Bei kontinuierlichen Wahrscheinlichkeitsverteilungen stellt die PDF die mit verschiedenen Intervallen verbundenen Wahrscheinlichkeiten dar. Im Gegensatz zu einer PMF gibt eine PDF nicht die Wahrscheinlichkeit an einem bestimmten Punkt an, sondern innerhalb eines Bereichs.
Allgemeine Wahrscheinlichkeitsverteilungen:
- Gleichmäßige Verteilung: Alle Ergebnisse haben gleiche Wahrscheinlichkeiten. Beim Würfeln eines fairen Würfels zum Beispiel hat jede Seite eine Wahrscheinlichkeit von 1/6.
- Normalverteilung (Gaußsche Verteilung): Eine symmetrische, glockenförmige Verteilung, die in der Statistik weit verbreitet ist. Viele natürliche Phänomene, wie z. B. Körpergrößen oder Prüfungsergebnisse, folgen dieser Verteilung.
- Binomialverteilung: Modelliert die Anzahl der Erfolge bei einer festen Anzahl unabhängiger Bernoulli-Versuche, die jeweils die gleiche Erfolgswahrscheinlichkeit haben.
- Poisson-Verteilung: Beschreibt die Anzahl der Ereignisse, die in einem festen Zeit- oder Raumintervall auftreten, wobei eine konstante durchschnittliche Häufigkeit des Auftretens gegeben ist.
- Exponentialverteilung: Modelliert die Zeit zwischen den Ereignissen eines Poisson-Prozesses, bei dem die Ereignisse kontinuierlich und unabhängig voneinander mit einer konstanten durchschnittlichen Rate auftreten.
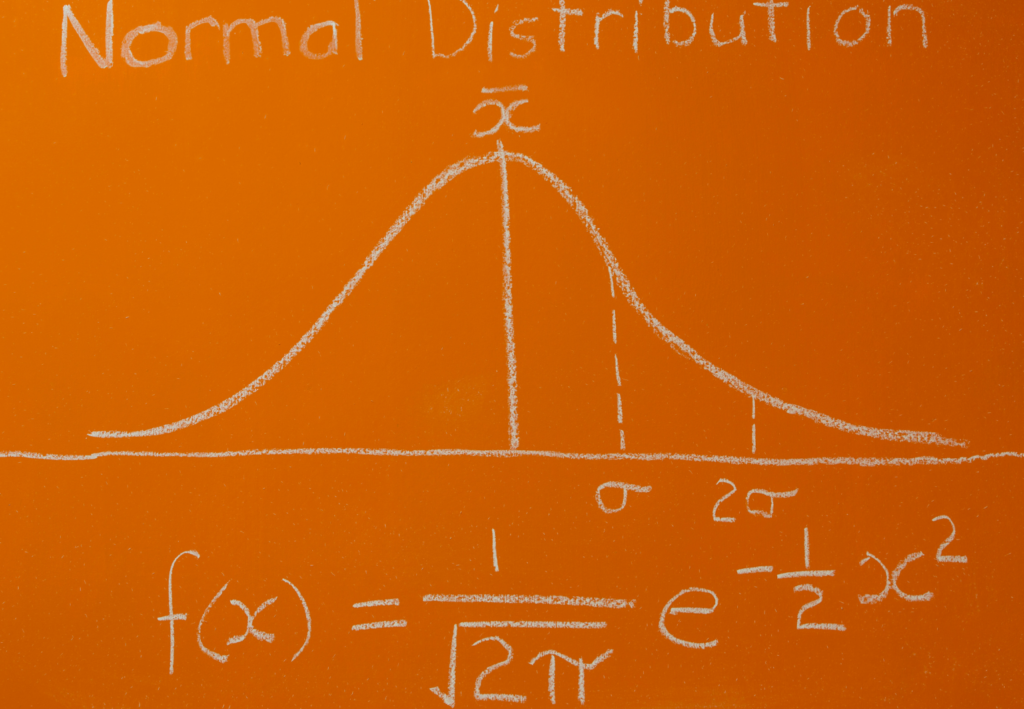
Das Verständnis dieser Wahrscheinlichkeitsverteilungen und ihrer Eigenschaften stattet Statistiker, Datenwissenschaftler und Forscher mit leistungsstarken Werkzeugen aus, um Daten zu analysieren, Vorhersagen zu treffen und wertvolle Einblicke in verschiedene Phänomene zu gewinnen. Wenn wir uns näher mit der Maximum-Likelihood-Methode befassen, wird sich ein festes Verständnis der Wahrscheinlichkeitsverteilungen bei der Erforschung der statistischen Schlussfolgerungen als hilfreich erweisen.
Was ist die Likelihood-Funktion?
Das Verständnis der Likelihood-Funktion ist unerlässlich, um eines der leistungsfähigsten Konzepte in der Statistik zu verstehen – die Maximum-Likelihood-Schätzung. Die Likelihood-Funktion ist ein grundlegendes Instrument zur Schätzung der Parameter eines statistischen Modells, das eine Brücke zwischen den beobachteten Daten und den Parametern schlägt, die die zugrunde liegende Wahrscheinlichkeitsverteilung charakterisieren.
Definition und Kerngedanke:
Die Likelihood-Funktion, oft als \( \mathcal{L}(\theta \mid \mathbf{x}) \) bezeichnet, quantifiziert die Wahrscheinlichkeit der Beobachtung der gegebenen Daten \( \mathbf{x} \) unter einem bestimmten Satz von Modellparametern \( \theta \). Einfacher ausgedrückt, beantwortet sie die Frage: Wie wahrscheinlich sind die beobachteten Daten unter der Annahme einer bestimmten Konfiguration von Modellparametern?
Das Konzept beruht auf dem Grundprinzip der bedingten Wahrscheinlichkeit. Bei gegebenen Parametern \( \theta \) behandelt die Likelihood-Funktion die beobachteten Daten \( \mathbf{x} \) als eine Funktion dieser Parameter. Entscheidend ist jedoch, dass sie die Parameter \( \theta \) als Variablen und die Daten \( \mathbf{x} \) als feststehend behandelt.
Mathematische Formulierung:
Für einen Satz beobachteter Datenpunkte, die als unabhängig und identisch verteilt angenommen werden (eine wichtige Annahme), wird die Likelihood-Funktion häufig als das Produkt der Wahrscheinlichkeiten ausgedrückt, die mit jedem Datenpunkt verbunden sind:
\(\)\[\mathcal{L}(\theta \mid \mathbf{x}) = f(x_1 \mid \theta) \times f(x_2 \mid \theta) \times \ldots \times f(x_n \mid \theta) \]
wobei \( f(x_i \mid \theta) \) die Wahrscheinlichkeitsdichtefunktion (PDF) oder Wahrscheinlichkeitsmassenfunktion (PMF) des statistischen Modells darstellt, das mit jedem Datenpunkt verbunden ist.
Rolle bei der Maximum-Likelihood-Methode:
Das Hauptziel der Maximum-Likelihood-Schätzung besteht darin, die Menge der Modellparameter \( \theta \) zu finden, die die Likelihood-Funktion \( \mathcal{L}(\theta \mid \mathbf{x}) \) bei gegebenen Beobachtungsdaten \( \mathbf{x} \) maximiert. Mathematisch wird dies wie folgt ausgedrückt:
\(\) \[\hat{\theta}_{\text{MLE}} = \arg\max_{\theta} \mathcal{L}(\theta \mid \mathbf{x}) \]
Vereinfacht ausgedrückt, sucht MLE nach den Parameterwerten, die die beobachteten Daten unter Berücksichtigung des angenommenen statistischen Modells am wahrscheinlichsten machen.
Das Verständnis der Likelihood-Funktion ist grundlegend für statistische Schlussfolgerungen, da es die Schätzung von Parametern ermöglicht und Einblicke in das Verhalten verschiedener statistischer Modelle gewährt. Bei der Erforschung der Maximum-Likelihood-Methode wird sich ein gründliches Verständnis der Likelihood-Funktion als entscheidend erweisen, um ihr volles Potenzial in der statistischen Analyse und Modellierung auszuschöpfen.
Was ist die Log-Likelihood-Funktion?
In der statistischen Schätzung ist die Log-Likelihood-Funktion ein wichtiges Instrument, das komplexe Berechnungen vereinfacht und eine effiziente Schätzung der Modellparameter ermöglicht. Die Log-Likelihood-Funktion ist der Logarithmus der Likelihood-Funktion und wird häufig aus Gründen der numerischen Stabilität und der mathematischen Bequemlichkeit verwendet.
Die wichtigsten Punkte dieser Funktion sind:
- Logarithmische Transformation: Die Log-Likelihood-Funktion, bezeichnet als \( \log(\mathcal{L}(\theta \mid \mathbf{x})) \), erhält man, indem man den natürlichen Logarithmus der Likelihood-Funktion nimmt. Diese Transformation ändert das Optimierungsziel nicht, da logarithmische Funktionen die Lage der Maxima beibehalten.
- Vorteile: Die Log-Likelihood bietet rechnerische Vorteile, da sie Produkte (aus der Likelihood) in Summen umwandelt, mathematische Operationen vereinfacht und das Risiko eines numerischen Unterlaufs verringert.
- Maximale Log-Likelihood: Ähnlich wie bei der Likelihood-Funktion besteht das Ziel der maximalen Log-Likelihood-Schätzung (MLLE) darin, die Menge der Modellparameter \( \theta \) zu finden, die die Log-Likelihood-Funktion maximiert.
- Statistische Schätzung: Statistiker und Datenanalysten bevorzugen oft die Arbeit mit der Log-Likelihood-Funktion, da sie einfach zu handhaben ist, insbesondere bei großen Datensätzen und komplexen Modellen.
Wenn man die Log-Likelihood-Funktion und ihre Bedeutung versteht, kann man die statistische Analyse und die Parameterschätzung effizienter handhaben, was bei der Suche nach genauen Modellen und aufschlussreichen Schlussfolgerungen hilfreich ist.
Was ist das MLE-Verfahren?
Die Maximum-Likelihood-Methode ist eine grundlegende Methode, die in der Statistik und beim maschinellen Lernen zur Schätzung der Parameter eines statistischen Modells verwendet wird. Das Verfahren versucht, die Werte dieser Parameter zu finden, die die Likelihood-Funktion maximieren, die die Wahrscheinlichkeit der beobachteten Daten in Abhängigkeit vom Modell misst.
Nachfolgend ein Überblick über das MLE-Verfahren:
- Formuliere die Likelihood-Funktion: Beginne mit der Definition der Likelihood-Funktion \( L(\theta \mid x) \), die die Wahrscheinlichkeit der Beobachtung der gegebenen Daten \(x\) unter Berücksichtigung der Parameter \( \theta \) des Modells darstellt.
- Nehme den Logarithmus: Um die Berechnungen zu vereinfachen, wird häufig der Logarithmus der Wahrscheinlichkeitsfunktion, die so genannte Log-Likelihood-Funktion, \( \log L(\theta \mid x) \), verwendet. Dieser Schritt ändert nichts an der Lage des Maximums, da der Logarithmus eine monoton steigende Funktion ist.
- Ableitung der Score-Funktion: Berechne die Score-Funktion (auch bekannt als Gradient der Log-Likelihood-Funktion) in Bezug auf die Parameter. Die Score-Funktion gibt die Richtung des steilsten Anstiegs an, der auf die Maximum-Likelihood-Schätzung hinweist.
- Setze die Score-Funktion auf Null: Setze die Score-Funktion mit Null gleich, um die kritischen Punkte zu finden. Durch Lösen dieser Gleichung erhält man die Werte der Parameter, die die log-likelihood maximieren.
- Zweite Ableitungen prüfen: Bestätige, dass die gefundenen kritischen Punkte tatsächlich Maxima sind, indem Du die zweiten Ableitungen der Log-Likelihood untersuchst. Die Hessian-Matrix (Matrix der zweiten partiellen Ableitungen) sollte am Maximalpunkt negativ definit sein.
- Schätze die Parameter: Die durch die Lösung des Gleichungssystems aus der Score-Funktion erhaltenen Werte stellen die Maximum-Likelihood-Schätzungen der Parameter \( \hat{\theta} \) dar.
Die Maximum-Likelihood-Schätzungen \( \hat{\theta} \) gelten als die wahrscheinlichsten Werte für die Parameter, wenn die beobachteten Daten vorliegen. MLE wird aufgrund seiner wünschenswerten statistischen Eigenschaften, wie Konsistenz, asymptotische Normalität und Effizienz, häufig verwendet.
Zusammenfassend lässt sich sagen, dass das Verfahren der Maximum-Likelihood-Schätzung darauf abzielt, die Parameterwerte zu finden, die die beobachteten Daten im Rahmen eines bestimmten statistischen Modells am wahrscheinlichsten machen, was es zu einem leistungsstarken Werkzeug für statistische Schlussfolgerungen und maschinelle Analysen macht.
Was sind die Eigenschaften von MLE?
Die Maximum-Likelihood-Methode ist eine leistungsfähige statistische Methode zur Schätzung von Parametern einer Wahrscheinlichkeitsverteilung auf der Grundlage von Beobachtungsdaten. MLE verfügt über mehrere wünschenswerte Eigenschaften, die sie zu einem weit verbreiteten Werkzeug in verschiedenen Bereichen der Statistik und des maschinellen Lernens machen. Hier sind einige Schlüsseleigenschaften von MLE:
- Konsistenz: Mit zunehmender Stichprobengröße konvergiert MLE in der Wahrscheinlichkeit zu den wahren Werten der zu schätzenden Parameter. Einfacher ausgedrückt: Je mehr Daten Du sammelst, desto mehr nähern sich diese Schätzungen den tatsächlichen Parameterwerten auf Bevölkerungsebene an.
- Asymptotische Normalität: Bei einem ausreichend großen Stichprobenumfang haben die MLE-Schätzungen eine annähernde Normalverteilung mit einem Mittelwert, der den wahren Parameterwerten entspricht, und einer Varianz, die mit dem Stichprobenumfang abnimmt. Diese Eigenschaft ist grundlegend für die Konstruktion von Konfidenzintervallen und Hypothesentests.
- Effizienz: Unter den konsistenten Schätzern ist MLE oft der effizienteste, da er die kleinstmögliche Varianz liefert. Statistisch gesehen erreicht MLE die untere Schranke von Cramér-Rao und gewährleistet damit die höchste Genauigkeit bei der Schätzung der Parameter.
- Invarianz: MLE ist invariant unter Transformationen. Wenn \( \hat{\theta} \) das MLE für einen Parameter \( \theta \) ist, dann ist jede Funktion \( g(\hat{\theta}) \) das MLE für \(g(\theta) \). Diese Eigenschaft ist wertvoll, wenn abgeleitete Größen oder Funktionen der Parameter geschätzt werden sollen.
- Suffizienz: MLE führt häufig zu hinreichenden Statistiken, d. h. zu zusammenfassenden Statistiken, die alle Informationen über die Parameter enthalten. Diese Eigenschaft hilft dabei, die Dimensionalität der Daten zu reduzieren und gleichzeitig die wesentlichen Informationen für die Schätzung beizubehalten.
- Abwägung zwischen Verzerrung und Effizienz: Diese Schätzmethode ist tendenziell asymptotisch unvoreingenommen, was bedeutet, dass die Verzerrung der Schätzung mit zunehmendem Stichprobenumfang abnimmt. Allerdings kann MLE bei kleinen Stichprobenumfängen verzerrt sein. Der Kompromiss zwischen Verzerrung und Effizienz bedeutet, dass die Methode häufig die Verzerrung der Effizienz opfert.
- Robustheit: MLE ist bekanntlich asymptotisch robust, d. h. es bleibt auch dann konsistent, wenn die zugrunde liegenden Annahmen der Wahrscheinlichkeitsverteilung leicht verletzt werden. Dies macht MLE zu einer robusten Schätzmethode in realen Szenarien, in denen die Annahmen möglicherweise nicht perfekt eingehalten werden.
Das Verständnis dieser Eigenschaften ist für Praktiker von entscheidender Bedeutung, um MLE in einem breiten Spektrum von statistischen Anwendungen effektiv einsetzen zu können. Diese Eigenschaften bestätigen die Zuverlässigkeit, Genauigkeit und Robustheit der MLE und machen sie zu einem Eckpfeiler der modernen statistischen Schätzung.
Was sind die Vor- und Nachteile von MLE?
Die Maximum-Likelihood-Methode ist eine weit verbreitete statistische Methode zur Schätzung der Parameter einer Wahrscheinlichkeitsverteilung auf der Grundlage von Beobachtungsdaten. Wie jede statistische Technik hat auch die MLE eine Reihe von Vor- und Nachteilen, die bei ihrer Anwendung auf reale Probleme unbedingt zu berücksichtigen sind.
Ein wesentlicher Vorteil von MLE ist seine Effizienz und seine asymptotischen Eigenschaften. Unter einer Klasse von konsistenten Schätzern liefert MLE die effizientesten Schätzungen und erreicht eine hohe Präzision und Genauigkeit, wenn der Stichprobenumfang zunimmt. Darüber hinaus sind MLE-Schätzer konsistent, d. h. sie konvergieren mit zunehmender Datenmenge zu den wahren Parameterwerten, was die Genauigkeit der Schätzung gewährleistet.
Ein weiterer Vorteil ist die Invarianz von MLE bei verschiedenen Transformationen. Diese Flexibilität ermöglicht die Schätzung eines breiten Spektrums von Modellen und macht MLE äußerst anpassungsfähig. Darüber hinaus ist MLE asymptotisch robust, d. h. die Konsistenz bleibt auch dann erhalten, wenn die zugrunde liegenden Verteilungsannahmen leicht verletzt werden.
MLE ist jedoch nicht frei von Nachteilen. Sie kann empfindlich auf Ausreißer oder Anomalien in den Daten reagieren, was zu verzerrten oder ungenauen Schätzungen führen kann, insbesondere bei kleinen Stichprobengrößen. Darüber hinaus stellt die Annahme einer bestimmten Wahrscheinlichkeitsverteilung für die Daten eine Einschränkung dar, und wenn diese Annahme in erheblichem Maße falsch ist, können die Schätzungen unzuverlässig sein. Bei kleinen Stichprobengrößen kann MLE verzerrt sein, was sich auf die Genauigkeit der Schätzungen auswirkt, und bei multivariaten Problemen mit zahlreichen Parametern wird MLE rechnerisch komplex. Schließlich kann die Leistung von MLE in hohem Maße von den für den Optimierungsprozess gewählten Anfangswerten abhängen, was zu unterschiedlichen lokalen Optima führen und die Genauigkeit und Stabilität der Schätzungen beeinträchtigen kann.
Das Verständnis dieser Vor- und Nachteile ist für Forscher und Praktiker von entscheidender Bedeutung, um fundierte Entscheidungen darüber zu treffen, wann und wie MLE effektiv eingesetzt werden kann. Die Berücksichtigung der spezifischen Merkmale der Daten und des vorliegenden Problems ist der Schlüssel zur Maximierung des Nutzens von MLE bei gleichzeitiger Abschwächung seiner Grenzen.
Wie schneidet MLE im Vergleich zu anderen Schätzungsmethoden ab?
Auf dem Gebiet der statistischen Parameterschätzung konkurrieren mehrere Methoden um die Vorherrschaft, jede mit ihren eigenen Stärken und Schwächen. Die Maximum-Likelihood-Methode ist eine beliebte und weit verbreitete Technik, aber wie steht sie im Vergleich zu anderen Schätzmethoden da?
Einer der wesentlichen Unterschiede liegt in der zugrunde liegenden Philosophie. MLE versucht, die Parameterwerte zu finden, die die Likelihood-Funktion angesichts der beobachteten Daten maximieren. Dies steht im Gegensatz zu anderen Methoden wie der Methode der Momente (MoM) oder der Kleinste-Quadrate-Schätzung (LSE), die sich auf die Anpassung der Stichprobenmomente bzw. die Minimierung der Summe der quadratischen Differenzen konzentrieren.
In Bezug auf Effizienz und statistische Eigenschaften übertrifft die MLE häufig andere Methoden. Seine Schätzer sind asymptotisch effizient und erreichen die kleinstmögliche Varianz, wenn der Stichprobenumfang wächst, wobei bestimmte Regularitätsbedingungen vorausgesetzt werden. Diese Effizienz macht den Algorithmus zu einer bevorzugten Wahl, wenn Präzision und Genauigkeit von größter Bedeutung sind.
Der Effizienzvorteil von MLE kann jedoch einen Preis haben, insbesondere im Vergleich zu einfacheren Methoden wie MoM. MLE erfordert die Lösung komplexer Optimierungsprobleme, die rechenintensiv sein können und empfindlich auf die Wahl der Anfangswerte reagieren. Die MoM-Methode hingegen ist in der Regel rechnerisch einfach und weniger anfällig für Konvergenzprobleme.
Wenn die Annahmen über die zugrundeliegende Verteilung korrekt sind, schneidet MLE außergewöhnlich gut ab. Sie kann jedoch sehr empfindlich auf Verteilungsannahmen reagieren, und wenn diese Annahmen verletzt werden, können die Schätzungen verzerrt oder inkonsistent sein. Im Gegensatz dazu sind Methoden wie LSE robust und nachsichtiger gegenüber Verteilungsfehlspezifikationen.
In der Praxis hängt die Wahl der Schätzmethode oft von der spezifischen Problemstellung, den Dateneigenschaften und rechnerischen Überlegungen ab. Forscher und Praktiker wägen bei der Auswahl einer geeigneten Schätzungsmethode die Kompromisse zwischen Genauigkeit, Rechenaufwand und Robustheit gegenüber Verteilungsannahmen ab.
Zusammenfassend lässt sich sagen, dass MLE aufgrund seiner Effizienz und wünschenswerten asymptotischen Eigenschaften eine leistungsstarke und weithin bevorzugte Schätzmethode ist. Die Abhängigkeit von genauen Verteilungsannahmen und die Komplexität der Berechnungen können jedoch dazu führen, dass sich Praktiker je nach den Besonderheiten des vorliegenden Problems für alternative Methoden wie MoM oder LSE entscheiden. Das Verständnis dieser Kompromisse ist entscheidend für die Auswahl der am besten geeigneten Schätztechnik für ein bestimmtes Szenario.
Das solltest Du mitnehmen
- MLE ist eine hocheffiziente Schätzmethode, die bei großen Stichprobenumfängen die kleinstmögliche Varianz erzielt, vorausgesetzt, die Regularitätsbedingungen sind erfüllt.
- Sie hängt stark von genauen Verteilungsannahmen ab. Wenn diese Annahmen nicht korrekt sind, können die Schätzungen verzerrt oder inkonsistent sein.
- Die Schätzungsmethode beinhaltet die Lösung komplexer Optimierungsprobleme, die rechenintensiv sein können und empfindlich auf Anfangswerte reagieren. Diese Komplexität nimmt mit der Dimensionalität des Parameterraums zu.
- MLE ist aufgrund seiner Flexibilität bei der Modellierung verschiedener Arten von Daten und Parametern in verschiedenen Bereichen, von der Finanzwirtschaft bis zur Biologie, weit verbreitet.
- Die Maximum-Likelihood-Methode ist besonders vorteilhaft für große Stichproben, bei denen ihre Effizienzeigenschaften besonders zur Geltung kommen, so dass sie in solchen Szenarien bevorzugt eingesetzt wird.
- Praktiker müssen sorgfältig abwägen zwischen der Komplexität der Berechnungen, der Robustheit gegenüber Annahmen und dem Wunsch nach effizienten Schätzungen, wenn sie sich für die MLE gegenüber alternativen Schätzmethoden entscheiden.
- Trotz seiner Herausforderungen bleibt MLE ein vielseitiges und leistungsstarkes Werkzeug in der Statistik, das eine zentrale Rolle in verschiedenen statistischen Modellierungs- und Inferenzverfahren spielt.

Was ist Gibbs-Sampling?
Erforschen Sie Gibbs-Sampling: Lernen Sie die Anwendungen kennen und erfahren Sie, wie sie in der Datenanalyse eingesetzt werden.

Was ist ein Bias?
Auswirkungen und Maßnahmen zur Abschwächung eines Bias: Dieser Leitfaden hilft Ihnen, den Bias zu verstehen und zu erkennen.

Was ist die Varianz?
Die Rolle der Varianz in der Statistik und der Datenanalyse: Verstehen Sie, wie man die Streuung von Daten messen kann.

Was ist die KL Divergence (Kullback-Leibler Divergence)?
Erkunden Sie die Kullback-Leibler Divergence (KL Divergence), eine wichtige Metrik in der Informationstheorie und im maschinellen Lernen.

Was ist der Varianzinflationsfaktor (VIF)?
Erfahren Sie, wie der Varianzinflationsfaktor (VIF) Multikollinearität in Regressionen erkennt, um eine bessere Datenanalyse zu ermöglichen.

Was ist die Dummy Variable Trap?
Entkommen Sie der Dummy Variable Trap: Erfahren Sie mehr über Dummy-Variablen, ihren Zweck und die Folgen der Falle.
Andere Beiträge zum Thema Maximum-Likelihood-Methode
Hier findest Du einen Artikel über die Durchführung der Maximum-Likelihood-Methode in Python.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.