Im sich ständig weiterentwickelnden Bereich des maschinellen Lernens spielen Optimierungsalgorithmen eine entscheidende Rolle bei der Modellschulung. Unter diesen Algorithmen hat sich der Adam Optimizer aufgrund seiner adaptiven und effizienten Eigenschaften als eine herausragende Wahl etabliert.
In diesem Artikel tauchen wir in die Mechanik des Adam Optimizers ein und erkunden seine Grundlagen, Stärken und realen Anwendungen. Egal, ob du ein erfahrener Maschinenlernpraktiker oder ein Neuling auf diesem Gebiet bist, das Verständnis des Adam Optimizers ist entscheidend, um die Kunst des Modelltrainings zu beherrschen.
Begleite uns auf dieser Reise, während wir den Adam Optimizer entmystifizieren und sein Innenleben sowie seine praktische Nützlichkeit beleuchten. Willkommen in einer Welt, in der Optimierung auf Innovation trifft und den Fortschritt des maschinellen Lernens vorantreibt.
Was sind Optimierungsalgorithmen?
Im Bereich des maschinellen Lernens dienen Optimierungsalgorithmen als treibende Kraft hinter dem Modelltraining. Diese Algorithmen sind die mathematischen Motoren, die die Parameter eines maschinellen Lernmodells feinabstimmen, um seine Leistung bei seiner beabsichtigten Aufgabe zu verbessern.
Im Kern sind Optimierungsalgorithmen mathematische Techniken, die eine spezifische Zielfunktion minimieren oder maximieren. Im Kontext des maschinellen Lernens repräsentiert diese Zielfunktion oft ein Maß dafür, wie gut die Vorhersagen eines Modells mit den tatsächlichen Ergebnissen in einem Datensatz übereinstimmen.
Das Hauptziel von Optimierungsalgorithmen besteht darin, den optimalen Satz von Modellparametern zu finden, der diese Zielfunktion minimiert. Diese Parameter können Gewichte in einem neuronalen Netzwerk, Koeffizienten in einem linearen Regressionsmodell oder andere Variablen sein, die die Vorhersagen des Modells beeinflussen.
Optimierungsalgorithmen arbeiten iterativ und passen die Modellparameter in kleinen Schritten an, um den Wert der Zielfunktion schrittweise zu reduzieren. Dieser iterative Prozess dauert an, bis ein vordefiniertes Abbruchkriterium erreicht ist, wie eine maximale Anzahl von Iterationen oder wenn der Algorithmus feststellt, dass weitere Verbesserungen vernachlässigbar sind.
Die Wahl eines Optimierungsalgorithmus kann den Schulungsprozess und die Leistung des resultierenden Modells erheblich beeinflussen. Unterschiedliche Optimierungsalgorithmen weisen einzigartige Stärken und Schwächen auf, daher ist es wichtig, den am besten geeigneten für eine bestimmte Aufgabe auszuwählen.
Zusammenfassend sind Optimierungsalgorithmen die treibende Kraft, die es maschinellen Lernmodellen ermöglicht, aus Daten zu lernen, sich anzupassen und genaue Vorhersagen zu treffen. Sie sind der Grundpfeiler der Modellschulung und gewährleisten, dass Modelle kontinuierlich ihre Leistung verbessern und in verschiedenen Anwendungen wertvolle Erkenntnisse liefern, von der Bilderkennung bis zur natürlichen Sprachverarbeitung.
Was ist die Motivation für den Adam Optimizer?
Vor dem Aufkommen des Adam Optimizers war die Landschaft der Optimierungsalgorithmen zur Schulung von Machine-Learning-Modellen gespickt mit verschiedenen Methoden, von denen jede ihre Vor- und Nachteile hatte. Traditionelle Optimierer wie Stochastic Gradient Descent (SGD) und Momentum haben in vielen Kontexten ihren Wert bewiesen, waren jedoch nicht ohne Einschränkungen.
Eine der Hauptherausforderungen, denen diese früheren Optimierer gegenüberstanden, war die Notwendigkeit, ein Gleichgewicht zwischen zwei entscheidenden Faktoren in der Optimierung zu finden: der Lernrate und der Schrittgröße. Eine feste Lernrate könnte zu langsamer Konvergenz oder dem Feststecken in lokalen Minima führen, während eine hohe Lernrate zu einem Überschießen der optimalen Lösung oder zu erratic behavior führen könnte.
Zusätzlich erforderten diese Optimierer oft manuelles Tuning von Hyperparametern, was zeitaufwändig und keine triviale Aufgabe sein konnte. Modellpraktiker mussten mit verschiedenen Lernraten und Momentum-Werten experimentieren, um eine optimale Konvergenz zu erreichen, was den Prozess mehr zur Kunst als zur Wissenschaft machte.
Die Motivation für den Adam Optimizer ergab sich aus dem Wunsch, diese Probleme anzugehen. Adam, was für Adaptive Moment Estimation steht, wurde entwickelt, um die Vorteile sowohl adaptiver Lernraten als auch Momentum zu kombinieren.
Hier sind einige wichtige Motivationen für die Entwicklung des Adam-Optimierers:
- Adaptive Lernraten: Adam führt das Konzept adaptiver Lernraten für einzelne Modellparameter ein. Es schätzt die Lernrate dynamisch für jeden Parameter anhand seiner bisherigen Gradienten. Diese Anpassung stellt sicher, dass Parameter mit großen Gradienten kleinere Lernraten erhalten, um Überschießen zu verhindern, während solche mit kleinen Gradienten größere Raten erhalten, um die Konvergenz zu beschleunigen.
- Effizienz: Der Adam Optimizer ist für seine Effizienz in Bezug auf die Konvergenzgeschwindigkeit bekannt. Er ist besonders effektiv in Situationen, in denen die Zielfunktion sparse gradients aufweist, was ihn für Deep Learning und das Training neuronaler Netze gut geeignet macht.
- Automatisches Hyperparameter-Tuning: Adam automatisiert den Prozess des Hyperparameter-Tunings weitgehend. Obwohl es immer noch einige Hyperparameter festlegen muss, wie die anfängliche Lernrate und die Momentum-Koeffizienten, reduziert es die Notwendigkeit für umfangreiches manuelles Tuning im Vergleich zu traditionellen Optimierern erheblich.
- Robustheit: Adam wurde entwickelt, um robust für eine breite Palette von Optimierungsproblemen zu sein und tendiert dazu, out-of-the-box gut zu performen, ohne umfangreiche Hyperparameter-Anpassungen.
Die Entwicklung des Adam-Optimierers war ein bedeutender Meilenstein auf dem Gebiet der Optimierung und bietet einen adaptiven und effizienten Ansatz zur Schulung von maschinellen Lernmodellen. Sein Erfolg und seine Beliebtheit in verschiedenen Deep-Learning-Anwendungen unterstreichen die Bedeutung adaptiver Optimierungsmethoden im modernen maschinellen Lernen.
Was sind die Grundlagen des Adam Optimizers?
Bevor wir uns in die Feinheiten des Adam Optimizers vertiefen, lasse uns einige grundlegende Konzepte erläutern, die die Grundlage dieses Optimierungsalgorithmus bilden. Ob Du neu im Bereich des maschinellen Lernens bist oder gerade erst mit der Optimierung beginnst, das Verständnis dieser grundlegenden Ideen wird es Ihnen erleichtern, zu verstehen, wie Adam das Training von Modellen effizient und effektiv gestaltet.
- Optimierung: Im Kern ist die Optimierung wie das Finden des besten Wegs auf einen Berg. Im maschinellen Lernen repräsentiert der “Berg” die Zielfunktion, einen mathematischen Ausdruck, der misst, wie gut die Vorhersagen unseres Modells mit den tatsächlichen Ergebnissen in einem Datensatz übereinstimmen. Das Ziel der Optimierung besteht darin, die optimalen Modellparameter zu finden, die diese Zielfunktion minimieren. Diese Parameter können Gewichte in einem neuronalen Netzwerk, Koeffizienten in einem linearen Regressionsmodell oder andere Variablen sein, die die Vorhersagen des Modells beeinflussen.
- Gradient Descent: Stelle Dir vor, unser Wanderer klettert den Berg hinauf. Der Gradient ist wie ein Kompass, der in die Richtung des steilsten Anstiegs zeigt. Indem er diesem Kompass folgt und kleine Schritte in diese Richtung unternimmt, erreicht unser Wanderer allmählich den Gipfel (optimale Modellparameter). Das traditionelle Gradientenabstiegsverfahren verwendet für jeden Schritt eine feste Schrittgröße (Lernrate), was in bestimmten Situationen problematisch sein kann.
- Lernrate: Die Lernrate ist die Größe jedes Schrittes, den unser Wanderer unternimmt. Eine kleine Lernrate führt zu vorsichtigen, kleinen Schritten, die den Fortschritt verlangsamen können. Eine große Lernrate kann dazu führen, dass der Wanderer den Gipfel überschreitet und weiter bergab geht. Das Finden der richtigen Lernrate ist entscheidend für eine effiziente Optimierung.
- Momentum: Stelle Dir unseren Wanderer mit etwas Schwung vor. Das bedeutet, dass er sich an seine vorherigen Schritte erinnert und in eine konsistente Richtung beschleunigt. Schwung hilft, kleine Hindernisse zu überwinden und den Fortschritt in Richtung des Gipfels zu beschleunigen. Traditionelle Schwungmethoden haben feste Parameter, die manuell angepasst werden müssen.
- Adaptive Lernraten: Anstatt einer festen Schrittgröße passt er seine Schrittgröße dynamisch an die Steilheit des Geländes an. Steilere Hänge erhalten kleinere Schritte, flachere Bereiche größere Schritte. Diese Anpassung kann zu einer schnelleren Konvergenz führen.
- Exponentielle gleitende Durchschnitte: Denke an diese als Gedächtniszellen im Gehirn unseres Wanderers. Sie speichern Informationen über das Gelände, das sie durchquert haben. Die erste Gedächtniszelle (erster Moment) informiert sie über die durchschnittliche Steilheit des Pfades, und die zweite Zelle (zweiter Moment) informiert sie über die Rauheit des Geländes. Dieses Gedächtnis hilft ihnen, klügere Entscheidungen zu treffen.
- Bias-Korrektur: Manchmal kann das Gedächtnis unseres Wanderers am Anfang der Reise ein wenig voreingenommen sein. Sie korrigieren diese Voreingenommenheit, indem sie ihre Erinnerungen anpassen, damit sie im Laufe der Zeit zuverlässiger werden.
Jetzt, da wir mit diesen Konzepten das Grundgerüst gelegt haben, wirst Du leichter verstehen, wie der Adam Optimizer sie kombiniert, um die Landschaft der maschinellen Lernoptimierung zu durchqueren. Im nächsten Abschnitt werden wir diese Ideen in die Praxis umsetzen und untersuchen, wie Adam das Modelltraining effizient und effektiv macht.
Wie funktioniert der Algorithmus?
Der Adam Optimizer ist wie ein erfahrener Wanderer, der einen mathematischen Berg erklimmt, um die besten Modellparameter zu finden. Lasse uns Schritt für Schritt erläutern, wie er funktioniert:
- Der Start: Stelle Dir vor, Du machst Dich auf ein Wanderabenteuer und möchten den höchsten Gipfel (die besten Modellparameter) auf einem Berg erreichen (die Zielfunktion). Du startest an einem zufälligen Ort auf dem Berg.
- Gradienten und Schritte: In Deinem Rucksack hast Du einen Kompass (Gradienten), der Dir zeigt, in welche Richtung der steilste Anstieg ist. Du machst kleine Schritte in Richtung des Kompasses, um den Berg zu erklimmen. Diese Schritte repräsentieren Aktualisierungen Deiner Modellparameter.
- Adaptive Lernraten: Hier glänzt Adam. Anstatt eine feste Schrittgröße (Lernrate) zu verwenden, passt Du diese dynamisch an, abhängig davon, wie steil das Gelände ist. Steilere Hänge erhalten kleinere Schritte, flachere Bereiche größere Schritte. Diese Anpassung ermöglicht ein effizienteres Aufsteigen.
- Aufbau von Schwung: Du machst nicht nur zufällige Schritte, sondern sammelst auch Schwung, während Du vorankommst. Das bedeutet, Du erinnerst Dich an Deine vorherigen Schritte und setzt Deine Reise in eine konsistente Richtung fort. Schwung hilft Dir, kleine Hindernisse zu überwinden und beschleunigt Deinen Aufstieg.
- Exponentielle gleitende Durchschnitte: Du hast ein Notizbuch, in dem Du einige Informationen über Deine Reise notierst. Eine Seite (der erste Moment) informiert Dich über die durchschnittliche Steilheit des Geländes, das Du bisher durchquert hast. Die zweite Seite (der zweite Moment) informiert Dich über die Rauheit des Geländes. Diese Notizen helfen Dir dabei, klügere Entscheidungen über Deine nächsten Schritte zu treffen.
- Bias-Korrektur: Am Anfang Deiner Wanderung können Deine Notizen ein wenig voreingenommen oder nicht ganz genau sein. Du korrigierst diese Voreingenommenheit, während Du vorankommst, sodass Deine Notizen im Laufe der Zeit zuverlässiger werden.
- Die Adam-Gleichung: Hier ist die Hauptgleichung, die der Adam Optimizer verwendet, um Deine Modellparameter zu aktualisieren:
- Berechne den Gradienten mit Deinem Kompass.
- Passe die Lernrate basierend auf der Steilheit an.
- Kombiniere Deinen Schwung mit der angepassten Lernrate.
- Verwende Deine Notizen (die gleitenden Durchschnitte), um Dein Verständnis für das Gelände zu verbessern.
- Korrigiere eventuelle Voreingenommenheit in Deinen Notizen.
- Mache einen Schritt in die aktualisierte Richtung.
Wiederholung: Du wiederholst diesen Prozess, machst Schritt für Schritt, bis Du glaubst, den höchsten Gipfel (optimale Parameter) erreicht zu haben. Adam stellt sicher, dass Deine Schritte genau die richtige Größe und Richtung haben, um Dir beim effizienten Aufstieg zu helfen.
Im Wesentlichen ist der Adam Optimizer Dein vertrauenswürdiger Führer auf der Reise, um die besten Modellparameter zu finden. Er passt Deine Schritte an, erinnert sich an Deinen Weg und korrigiert Missverständnisse unterwegs. Mit Adams Hilfe kannst Du effizient den Gipfel erreichen und optimale Modellleistungen erzielen.
Wie kann der Optimierer eingestellt werden?
Obwohl der Adam Optimizer für seine Anpassungsfähigkeit und Effizienz bekannt ist, verlässt er sich auf mehrere Hyperparameter, die seine Leistung erheblich beeinflussen können. Das richtige Einstellen dieser Hyperparameter ist entscheidend, um optimale Ergebnisse in Deinen maschinellen Lernaufgaben zu erzielen. Lasse uns die wichtigsten Hyperparameter und deren Anpassungsmöglichkeiten genauer betrachten:
- Lernrate (α): Die Lernrate ist einer der wichtigsten Hyperparameter bei Optimierungsalgorithmen, einschließlich Adam. Sie bestimmt die Größe der Schritte, die Du beim Aufstieg in der Optimierungslandschaft unternimmst. Eine größere Lernrate kann zu einer schnelleren Konvergenz führen, kann jedoch auch die optimale Lösung überschießen. Umgekehrt kann eine kleinere Lernrate den Fortschritt stabiler, aber langsamer machen. Die richtige Lernrate zu finden, ist oft eine Frage von Versuch und Irrtum, und Techniken wie Lernratenpläne können helfen.
- β1 (Exponentieller Abklingfaktor für den ersten Moment): β1 ist ein Hyperparameter, der steuert, wie stark der Algorithmus auf frühere Gradienten angewiesen ist, wenn er den ersten Moment (den gleitenden Durchschnitt der Gradienten) berechnet. Normalerweise hat es einen Standardwert von 0,9. Eine Erhöhung von β1 kann dazu führen, dass der Algorithmus stärker auf frühere Gradienten angewiesen ist, was in rauschigen Optimierungsszenarien nützlich sein kann. Wenn es jedoch zu hoch eingestellt wird, kann dies zu einer langsameren Konvergenz führen.
- β2 (Exponentieller Abklingfaktor für den zweiten Moment): β2 steuert den Einfluss früherer quadrierter Gradienten beim Berechnen des zweiten Moments (des gleitenden Durchschnitts der quadrierten Gradienten). Normalerweise hat es einen Standardwert von 0,999. Ein kleinerer Wert für β2 bedeutet, dass der Algorithmus mehr Gewicht auf kürzlich aufgetretene quadrierte Gradienten legt, was bei der Anpassung an sich ändernde Landschaften hilfreich sein kann. Wie bei β1 hängt die Wahl von β2 vom Problem und den Daten ab.
- ε (Epsilon): Epsilon ist eine kleine Konstante (typischerweise um 1e-7), die zum Nenner hinzugefügt wird, wenn die lernratenabhängigen Lernraten berechnet werden. Sie verhindert eine Division durch null und trägt zur numerischen Stabilität des Algorithmus bei. Der Standardwert ist normalerweise für die meisten Fälle geeignet, und eine Änderung ist selten erforderlich.
- Anfängliche Lernrate: Obwohl es sich nicht um einen intrinsischen Hyperparameter des Adam Optimizers handelt, wird die anfängliche Lernrate oft vor der Anwendung von Adam festgelegt. Sie bestimmt die Größe der anfänglichen Schritte. Viele Lernratenplaner reduzieren die Lernrate während des Trainings, um den Optimierungsprozess zu verfeinern.
- Batch-Größe: Obwohl es sich nicht um einen adam-spezifischen Hyperparameter handelt, kann die während des Trainings verwendete Batch-Größe die Optimierung beeinflussen. Kleinere Batch-Größen können mehr Rauschen in die Gradientenschätzungen einführen, können jedoch dabei helfen, lokale Minima zu vermeiden. Größere Batch-Größen liefern stabilere Gradientenschätzungen, können jedoch zu einer langsameren Konvergenz führen.
- Anzahl der Trainingsepochen: Dieser Hyperparameter repräsentiert die Anzahl der Male, die Dein gesamter Datensatz während des Trainings verwendet wird. Die richtige Anzahl der Epochen hängt von Deinem spezifischen Problem und Ihrem Datensatz ab. Zu wenige Epochen können zu Unteranpassung führen, während zu viele zu Überanpassung führen können.
- Stärke der Regularisierung: Obwohl sie nicht direkt mit Adam zusammenhängt, können Regularisierungstechniken wie L1- oder L2-Regularisierung dazu beitragen, Überanpassung zu kontrollieren. Die Stärke der Regularisierung wird durch ihren Hyperparameter gesteuert, den Du in Kombination mit den Hyperparametern von Adam möglicherweise anpassen musst.
Das Einstellen dieser Hyperparameter erfordert oft Experimente und die Überwachung des Schulungsprozesses, um sicherzustellen, dass das Modell zu einer guten Lösung konvergiert. Es ist wichtig, die spezifischen Eigenschaften Ihres Datensatzes und des Problems bei der Anpassung dieser Hyperparameter zu berücksichtigen. Techniken wie Raster suche
Was sind die Vor- und Nachteile des Adam Optimizers?
Der Adam Optimizer, der für seine adaptive und effiziente Natur bekannt ist, bietet mehrere Vorteile, die ihn zu einer beliebten Wahl in der Gemeinschaft des maschinellen Lernens machen. Wie jeder Optimierungsalgorithmus hat er jedoch auch eine Reihe von Nachteilen mit sich gebracht. Lasse uns beide Seiten untersuchen:
Vorteile:
- Adaptive Lernraten: Der Adam Optimizer passt die Lernraten für jeden Parameter dynamisch an, was ihm ermöglicht, kleinere Aktualisierungen für häufig wechselnde Parameter und größere Aktualisierungen für solche, die sich weniger häufig ändern, durchzuführen. Diese Anpassungsfähigkeit kann zu einer schnelleren Konvergenz führen.
- Effizienz: Die Verwendung von gleitenden Durchschnitten für Gradienteninformationen (erster und zweiter Moment) ermöglicht es Adam, vergangene Gradienteninformationen effizient zu speichern und zu nutzen. Dies bedeutet, dass er große Datensätze und hochdimensionale Räume effektiv verarbeiten kann.
- Geeignet für Rauschige Daten: Adams Abhängigkeit von vergangenen Gradienten kann ihn robust gegenüber rauschigen oder inkonsistenten Gradientenschätzungen machen. Dies ist besonders nützlich in realen Szenarien, in denen die Datenqualität variieren kann.
- Standardparameter: Der Adam Optimizer wird mit Standardwerten für Hyperparameter geliefert (z. B. β1, β2 und ε), die oft gut für eine breite Palette von Problemen funktionieren. Dies macht ihn benutzerfreundlich und einfach zu implementieren, ohne umfangreiche Hyperparameterabstimmungen.
- Effektiv im Deep Learning: Adam hat sich als äußerst erfolgreich beim Training tiefer neuronaler Netzwerke erwiesen, bei denen die Optimierung aufgrund der komplexen, hochdimensionalen Natur der Modelle besonders herausfordernd sein kann.
Nachteile:
- Speicheranforderungen: Der Adam Optimizer erfordert das Speichern und Aktualisieren der Schätzungen für den ersten und zweiten Moment für jeden Parameter, was speicherintensiv sein kann, wenn Modelle eine große Anzahl von Parametern haben. Dies kann in ressourcenbeschränkten Umgebungen eine Einschränkung darstellen.
- Empfindlichkeit gegenüber der Lernrate: Obwohl Adam entwickelt wurde, um sich an unterschiedliche Lernraten für jeden Parameter anzupassen, kann er immer noch empfindlich gegenüber der Wahl der anfänglichen Lernrate sein. Wenn sie zu hoch eingestellt wird, kann dies zu Divergenz führen, während eine zu niedrige Einstellung zu langsamer Konvergenz führen kann.
- Fehlen theoretischer Garantien: Anders als einige andere Optimierungsalgorithmen fehlen dem Adam Optimizer starke theoretische Garantien hinsichtlich der Konvergenz zu globalen Minima. Obwohl er in der Praxis oft effektiv konvergiert, gibt es Szenarien, in denen er nicht zur optimalen Lösung gelangen kann.
- Schwierigkeiten bei der Abstimmung von Hyperparametern: Obwohl die Standardhyperparameter von Adam für viele Probleme gut funktionieren, kann das Finden des optimalen Satzes von Hyperparametern für ein bestimmtes Problem eine Herausforderung darstellen. Dies kann umfangreiche Experimente und Rechenressourcen erfordern.
- Nicht immer die beste Wahl: Trotz seiner weit verbreiteten Verwendung ist der Adam Optimizer nicht immer die beste Wahl für jedes Optimierungsproblem. Es gibt Szenarien, in denen andere Optimierer wie SGD mit Momentum oder RMSprop besser abschneiden können.
Zusammenfassend bietet der Adam Optimizer viele Vorteile, darunter adaptive Lernraten und Effizienz, wodurch er ein wertvolles Werkzeug für viele maschinelle Lernaufgaben ist. Es ist jedoch wichtig, seine Nachteile wie Speicheranforderungen und Empfindlichkeit gegenüber Lernraten zu berücksichtigen, wenn du entscheidest, ob du ihn für ein bestimmtes Problem verwenden möchtest. Sorgfältige Experimente und Bewertungen sind der Schlüssel dazu, die Stärken des Adam Optimizers effektiv zu nutzen.
Wie schneidet der Adam Optimizer im Vergleich mit anderen Optimierungsalgorithmen ab?
In der weiten Landschaft der Optimierungsalgorithmen ist der Adam Optimizer ein herausragender Mitbewerber. Um seine Stärken zu würdigen und seine Leistung in den Kontext zu setzen, ist es wichtig, Adam mit anderen Optimierungsmethoden zu vergleichen.
Gradientenabstieg: Der Adam-Optimierer weist klare Vorteile gegenüber dem einfachen Gradientenabstieg auf. Während der Gradientenabstieg für alle Parameter eine feste Lernrate verwendet, passt Adam die Lernrate individuell für jeden Parameter an. Diese Anpassungsfähigkeit ermöglicht es dem Adam-Optimierer, schneller zu konvergieren, insbesondere in Szenarien des Deep Learnings.
- Stochastischer Gradientenabstieg (SGD): Die adaptiven Lernraten von Adam bieten eine erhebliche Verbesserung gegenüber SGD. SGD bleibt oft in lokalen Minima oder Sattelpunkten stecken, aber die Anpassungsfähigkeit von Adam hilft ihm, diese Probleme zu umgehen. Es ist jedoch zu beachten, dass SGD bei kleinen Datensätzen möglicherweise vergleichbar oder sogar besser als Adam abschneiden kann.
- Momentum: SGD mit Momentum weist einige Ähnlichkeiten mit Adam auf. Beide Algorithmen führen eine Art von “Momentum” in den Optimierungsprozess ein. Die adaptive Lernraten von Adam bieten jedoch eine robustere Konvergenz, insbesondere wenn die Landschaft des Optimierungsproblems komplex oder ungleichmäßig ist.
- RMSprop: RMSprop passt wie Adam die Lernraten basierend auf den vergangenen Gradienten an. RMSprop enthält jedoch keine Bewegungsabschätzungen der Gradientenquadrate, was in bestimmten Situationen zu unruhigeren Aktualisierungen führen kann. Adams Einbeziehung von Schätzwerten des zweiten Moments hilft, den Optimierungsprozess zu stabilisieren.
- AdaGrad: AdaGrad ist ein anderer Optimierer, der die Lernraten anpasst, aber Einschränkungen aufweist. Es neigt dazu, die Lernrate zu stark zu reduzieren, was zu langsamer Konvergenz für tiefe neuronale Netzwerke führen kann. Die zusätzlichen Mechanismen von Adam, wie die Bias-Korrektur und die Schätzwerte des zweiten Moments, mildern dieses Problem.
- Nadam: Nadam kombiniert die Vorteile des Nesterovschen beschleunigten Gradienten (NAG) und von Adam. Obwohl Nadam wettbewerbsfähige Leistungen bieten kann, insbesondere im Deep Learning, hängt die Wahl zwischen Nadam und dem Adam-Optimierer oft von empirischen Tests in einem bestimmten Problem ab.
- LBFGS: In Optimierungsproblemen mit einer begrenzten Anzahl von Parametern kann der LBFGS (Limited-memory Broyden-Fletcher-Goldfarb-Shanno) ein starker Mitbewerber sein. LBFGS hält eine Approximation der Hessematrix aufrecht und kann effizient konvergieren. Es skaliert jedoch möglicherweise nicht gut in hochdimensionalen Problemen, in denen die Anpassungsfähigkeit von Adam glänzen kann.
Die Wahl des Optimierungsalgorithmus hängt von den Merkmalen des vorliegenden Problems ab. Adams Anpassungsfähigkeit, Effizienz und Robustheit machen ihn zu einer beliebten Wahl, insbesondere im Deep Learning. Es ist jedoch entscheidend, empirische Bewertungen durchzuführen und die spezifischen Anforderungen deiner Aufgabe zu berücksichtigen, wenn du den am besten geeigneten Optimierungsalgorithmus auswählst. In vielen Fällen positioniert die Kombination von Eigenschaften des Adam-Optimierers ihn als eine zuverlässige und vielseitige Wahl zur Optimierung komplexer Modelle und neuer maschineller Lernanwendungen.
Wie kann man den Adam Optimizer in Python implementieren?
Um den Adam Optimizer in Python zu implementieren, sind ein paar Schritte erforderlich. Stelle zunächst sicher, dass Du die erforderlichen Bibliotheken installiert hast, wie z. B. NumPy. Du kannst sie ansonsten mit pip installieren:

Lasse uns nun die Hyperparameter für den Adam Optimizer definieren. Dazu gehören die Lernrate (alpha), beta1, beta2 und ein kleines Epsilon (epsilon), um eine Division durch Null zu verhindern:
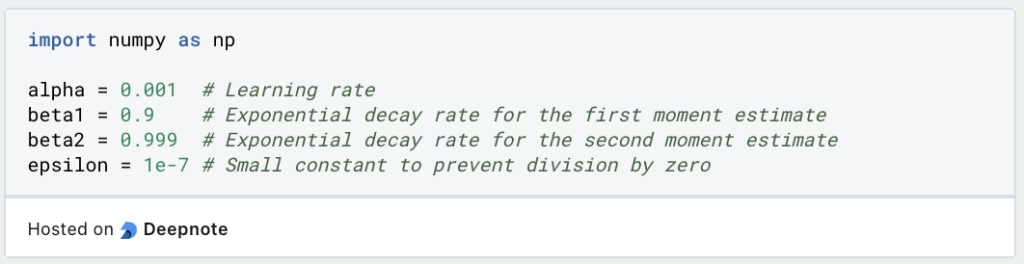
Als nächstes initialisierst Du die Variablen für das erste und zweite Moment (m und v) und eine Variable t, um den Zeitschritt zu verfolgen. Initialisiere auch Deinen Parametervektor theta, der von Deinem individuellen Projekt abhängt:
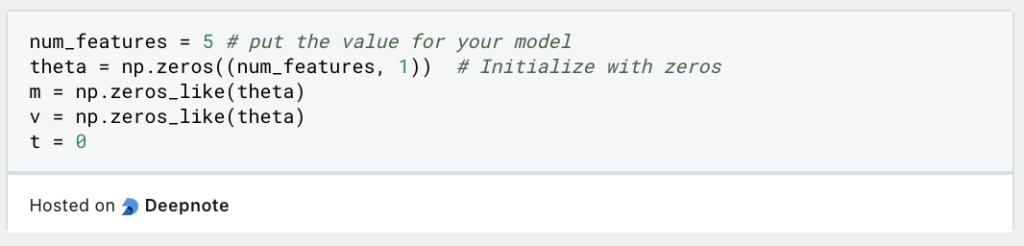
Jetzt kannst Du die Optimierungsschleife implementieren. Iteriere durch Deine Trainingsdaten und aktualisiere bei jedem Schritt Deine Parameter auf der Grundlage der Adam-Optimierungsformel:
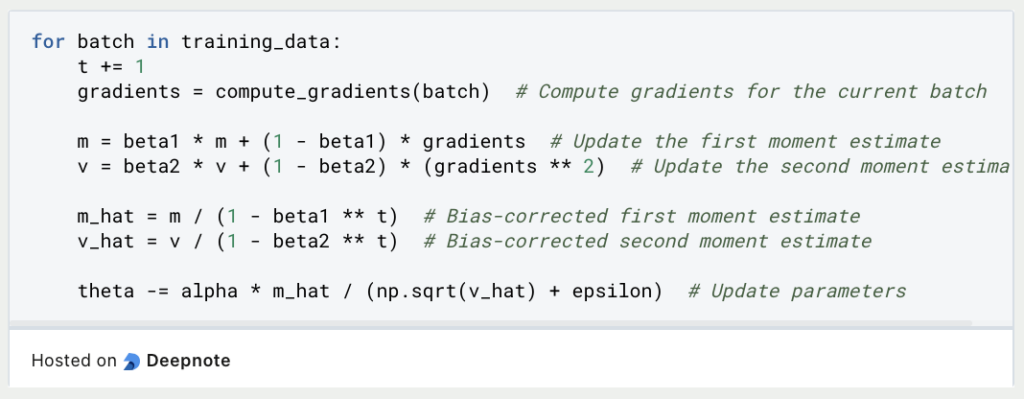
Wiederhole diese Optimierungsschleife, bis Dein Modell zu einer zufriedenstellenden Lösung konvergiert oder bis eine vordefinierte Anzahl von Iterationen erreicht ist. Nach der Optimierung kannst Du die optimierten Parameter (theta) für Vorhersagen mit Deinem maschinellen Lernmodell verwenden.
Dies ist zwar ein vereinfachtes Beispiel, aber bei realen Implementierungen werden oft zusätzliche Komplexitäten und Überlegungen angestellt, wie z. B. Mini-Batch-Training und Regularisierung. Für praktische Anwendungen empfiehlt sich die Verwendung von Bibliotheken für maschinelles Lernen wie TensorFlow oder PyTorch, die hochoptimierte Implementierungen des Adam Optimizers und anderer Optimierungsalgorithmen bieten.
Das solltest Du mitnehmen
- Der Adam Optimizer hat sich als leistungsfähiges Werkzeug im Bereich des maschinellen Lernens und des Deep Learning etabliert. Seine adaptiven Lernraten und effiziente Konvergenz machen ihn zu einer beliebten Wahl für die Optimierung komplexer Modelle.
- Der Adam Optimizer ist vielseitig einsetzbar und kann auf verschiedene maschinelle Lernaufgaben angewendet werden, von der Schulung neuronaler Netzwerke bis zur Optimierung von Regressionsmodellen. Seine Anpassungsfähigkeit ermöglicht es ihm, verschiedene Datenverteilungen und Problemkomplexitäten effektiv zu bewältigen.
- Im Gegensatz zu einigen anderen Optimierern erzielt Adam auch in Szenarien mit dünnen Gradienten gute Leistungen. Dies macht ihn für Aufgaben im Bereich der natürlichen Sprachverarbeitung und Empfehlungssysteme geeignet.
- Obwohl der Adam Optimizer mit seinen Standardhyperparametern gut funktioniert, kann das Feintuning dieser Parameter die Leistung erheblich beeinflussen. Praktiker sollten mit verschiedenen Werten experimentieren, um die besten Ergebnisse für ihre spezifischen Aufgaben zu erzielen.
- Adam kann mit Regularisierungstechniken wie L1- und L2-Regularisierung kombiniert werden, um Überanpassung zu verhindern und die Verallgemeinerung zu verbessern.
- Der Adam Optimizer unterstützt Parallelität und eignet sich daher für verteiltes Training auf mehreren GPUs oder TPUs, was die Modellschulung für große Datensätze beschleunigt.
- Praktiker sollten das Training anhand von Metriken wie Verlust und Validierungsleistung überwachen. Das vorzeitige Beenden kann Überanpassung verhindern und Schulungszeit sparen.
- Obwohl Adam ein robuster Optimierer ist, ist es wichtig, potenzielle Probleme wie verschwindende oder explodierende Gradienten im Auge zu behalten, da diese die Konvergenz beeinflussen können.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.

Was ist die Singular Value Decomposition?
Erkenntnisse und Muster freilegen: Lernen Sie die Leistungsfähigkeit der Singular Value Decomposition (SVD) in der Datenanalyse kennen.

Was ist die Poisson Regression?
Lernen Sie die Poisson-Regression kennen, ein statistisches Modell für die Analyse von Zähldaten, inkl. einem Beispiel in Python.

Was ist blockchain-based AI?
Entdecken Sie das Potenzial der blockchain-based AI in diesem aufschlussreichen Artikel über Künstliche Intelligenz und Blockchain.

Was ist Boosting im Machine Learning?
Boosting: Eine Ensemble-Technik zur Modellverbesserung. Lernen Sie in unserem Artikel Algorithmen wie AdaBoost, XGBoost, uvm. kennen.
Andere Beiträge zum Thema Adam Optimizer
Diese Dokumentation beschreibt, wie man den Adam Optimizer in TensorFlow benutzt.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.