In the ever-evolving landscape of Machine Learning, optimization algorithms play a pivotal role in model training. Among these algorithms, the Adam optimizer has emerged as a prominent choice for its adaptive and efficient characteristics.
In this article, we delve into the mechanics of the Adam optimizer, exploring its fundamentals, strengths, and real-world applications. Whether you’re a seasoned machine learning practitioner or a newcomer to the field, understanding the Adam optimizer is crucial for mastering the art of model training.
Join us on this journey as we demystify the Adam optimizer, shedding light on its inner workings and practical utility. Welcome to a world where optimization meets innovation, driving the progress of machine learning.
What are Optimization Algorithms?
In the realm of Machine Learning, optimization algorithms serve as the guiding force behind model training. These algorithms are the mathematical engines that fine-tune the parameters of a Machine Learning model to make it perform better at its intended task.
At their core, optimization algorithms are mathematical techniques that minimize or maximize a specific objective function. In the context of Machine Learning, this objective function often represents a measure of how well a model’s predictions match the actual outcomes in a dataset.
The primary goal of optimization algorithms is to find the optimal set of model parameters that minimize this objective function. These parameters might include weights in a neural network, coefficients in a linear regression model, or any other variables that affect the model’s predictions.
Optimization algorithms operate iteratively, adjusting the model parameters in small steps to gradually reduce the value of the objective function. This iterative process continues until a predefined stopping criterion is met, such as a maximum number of iterations or when the algorithm determines that further improvement is negligible.
The choice of an optimization algorithm can significantly impact the training process and the performance of the resulting model. Different optimization algorithms have unique strengths and weaknesses, making it essential to select the most suitable one for a particular task.
In summary, optimization algorithms are the driving force that enables Machine Learning models to learn from data, adapt, and make accurate predictions. They are the cornerstone of model training, ensuring that models continuously improve their performance and deliver valuable insights in various applications, from image recognition to natural language processing.
What is the motivation for the Adam Optimizer?
Before the advent of the Adam optimizer, the landscape of optimization algorithms for training Machine Learning models was dotted with various methods, each with its advantages and shortcomings. Traditional optimizers like Stochastic Gradient Descent (SGD) and Momentum have proven their worth in many contexts, but they weren’t without limitations.
One of the key challenges these earlier optimizers faced was the need to find a balance between two critical factors in optimization: the learning rate and the step size. A fixed learning rate might lead to slow convergence or getting stuck in local minima, while a high learning rate could result in overshooting the optimal solution or erratic behavior.
Additionally, these optimizers often required manual tuning of hyperparameters, which could be a time-consuming and non-trivial task. Model practitioners had to experiment with various learning rates and momentum values to achieve optimal convergence, making the process more art than science.
The motivation for the Adam optimizer stemmed from a desire to address these issues. Adam, which stands for Adaptive Moment Estimation, was designed to combine the benefits of both adaptive learning rates and momentum.
Here are some key motivations for the development of the Adam optimizer:
- Adaptive Learning Rates: Adam introduces the concept of adaptive learning rates for individual model parameters. It estimates the learning rate dynamically for each parameter based on its past gradients. This adaptability ensures that parameters with large gradients receive smaller learning rates, preventing overshooting, while those with small gradients receive larger rates to speed up convergence.
- Efficiency: Adam optimizer is known for its efficiency in terms of convergence speed. It is particularly effective in situations where the objective function has sparse gradients, making it well-suited for deep learning and neural network training.
- Automatic Hyperparameter Tuning: Adam automates the process of hyperparameter tuning to a great extent. While it still requires some hyperparameters to be set, such as the initial learning rate and momentum coefficients, it reduces the need for extensive manual tuning compared to traditional optimizers.
- Robustness: Adam is designed to be robust to a wide range of optimization problems and tends to perform well out-of-the-box without extensive hyperparameter adjustments.
The development of the Adam optimizer was a significant milestone in the field of optimization, offering a more adaptive and efficient approach to training machine learning models. Its success and popularity in various deep learning applications underscore the importance of adaptive optimization methods in modern machine learning.
What are the basics of the Adam Optimizer?
Before diving into the intricacies of the Adam optimizer, let’s break down some essential concepts that form the foundation of this optimization algorithm. Whether you’re new to Machine Learning or just getting started with optimization, grasping these fundamental ideas will make understanding Adam much easier:
1. Optimization: At its core, optimization is like finding the best path up a mountain. In Machine Learning, the “mountain” represents the objective function, a mathematical expression that measures how well our model is performing. The goal of optimization is to adjust our model’s parameters (like tuning the knobs on a radio) to reach the highest point on this mathematical mountain, indicating the best model performance.
2. Gradient Descent: Think of gradient descent as our hiker climbing the mountain. The gradient is like a compass, pointing in the direction of the steepest uphill climb. By following this compass and taking small steps in the direction, our hiker gradually reaches the peak (optimal model parameters). Traditional gradient descent uses a fixed step size (learning rate) for every step, which can be problematic in certain situations.
3. Learning Rate: The learning rate is the size of each step our hiker takes. A small learning rate makes cautious, tiny steps, which can slow down progress. A large learning rate can cause the hiker to overshoot the peak and keep going downhill. Finding the right learning rate is crucial for efficient optimization.
4. Momentum: Imagine our hiker with a bit of momentum. This means that they remember their previous steps and build up speed in a consistent direction. Momentum helps overcome small obstacles and accelerates progress towards the peak. Traditional momentum methods have fixed parameters that need manual tuning.
5. Adaptive Learning Rates: Now, picture our hiker equipped with adaptive learning rates. Instead of a fixed step size, they dynamically adjust their step size based on the steepness of the terrain. Steeper slopes get smaller steps, and flatter areas get larger steps. This adaptability can lead to faster convergence.
6. Exponential Moving Averages: Think of these as memory cells in our hiker’s brain. They store information about the terrain they’ve encountered. The first memory cell (first moment) tells them about the average steepness of the path, and the second cell (second moment) informs them about the roughness of the terrain. This memory helps them make smarter decisions.
7. Bias Correction: Sometimes, our hiker’s memory can be a bit biased at the beginning of the journey. They correct this bias by adjusting their memories, so they become more reliable over time.
Now that we’ve laid the groundwork with these concepts, you’ll find it easier to grasp how the Adam optimizer combines them to navigate the landscape of machine learning optimization. In the next section, we’ll put these ideas into action and explore how Adam makes model training efficient and effective.
How does the Adam Algorithm work?
The Adam optimizer is like a savvy hiker climbing a mathematical mountain to find the best model parameters. Let’s break down how it works, step by step:
1. Getting Started: Imagine you’re on a hiking adventure, and you want to reach the highest peak (the best model parameters) on a mountain (the objective function). You start at a random location on the mountain.
2. Gradients and Steps: In your backpack, you have a compass (gradients) that tells you which direction is steepest uphill. You take small steps in the direction of the compass to climb the mountain. These steps represent updates to your model’s parameters.
3. Adaptive Learning Rates: Here’s where Adam shines. Instead of using a fixed step size (learning rate), you dynamically adjust it based on how steep the terrain is. Steeper slopes get smaller steps, and flatter areas get larger steps. This adaptability helps you climb more efficiently.
4. Building Momentum: You’re not just taking random steps; you’re also building momentum as you go. This means you remember your previous steps and continue in a consistent direction. Momentum helps you overcome small obstacles and accelerates your climb.
5. Exponential Moving Averages: You have a notebook where you jot down some information about your journey. One page (the first moment) tells you about the average steepness of the terrain you’ve encountered so far. The second page (the second moment) informs you about the roughness of the terrain. These notes help you make smarter decisions about your next steps.
6. Correcting Bias: At the beginning of your hike, your notes might be a bit biased or not entirely accurate. You correct this bias as you go along, so your notes become more reliable over time.
7. The Adam Equation: Here’s the main equation that the Adam optimizer uses to update your model parameters:
- Calculate the gradients using your compass.
- Adjust the learning rate based on the steepness.
- Combine your momentum with the adjusted learning rate.
- Use your notes (the moving averages) to improve your understanding of the terrain.
- Correct any bias in your notes.
- Take a step in the updated direction.
8. Repeat: You keep repeating this process, taking step after step until you believe you’ve reached the highest peak (optimal parameters). Adam ensures that your steps are just the right size and direction, helping you climb efficiently.
In essence, the Adam optimizer is your trusty guide on the journey to find the best model parameters. It adjusts your steps, remembers your path, and corrects any misunderstandings along the way. With Adam’s help, you can efficiently reach the summit and achieve optimal model performance.
How can the Optimizer be tuned?
While the Adam optimizer is known for its adaptability and efficiency, it relies on several hyperparameters that can significantly influence its performance. Tuning these hyperparameters correctly is essential to achieve optimal results in your machine learning tasks. Let’s explore the key hyperparameters and how they can be adjusted:
1. Learning Rate (α): The learning rate is one of the most critical hyperparameters in optimization algorithms, including Adam. It determines the size of the steps you take while climbing the optimization landscape. A larger learning rate can lead to faster convergence, but it might overshoot the optimal solution. Conversely, a smaller learning rate can make progress more stable but slower. Finding the right learning rate is often a matter of trial and error, and techniques like learning rate schedules can help.
2. β1 (Exponential Decay Rate for the First Moment): β1 is a hyperparameter that controls how much the algorithm relies on past gradients when computing the first moment (the moving average of gradients). It typically has a default value of 0.9. Increasing β1 can make the algorithm rely more on past gradients, which can be useful in noisy optimization scenarios. However, setting it too high may lead to slower convergence.
3. β2 (Exponential Decay Rate for the Second Moment): β2 controls the influence of past squared gradients when computing the second moment (the moving average of squared gradients). It often has a default value of 0.999. A smaller β2 value means the algorithm gives more importance to recent squared gradients, potentially helping in adapting to changing landscapes. Like β1, the choice of β2 depends on the problem and the data.
4. ε (Epsilon): Epsilon is a small constant (typically around 1e-7) added to the denominator when calculating the per-parameter learning rates. It prevents division by zero and adds numerical stability to the algorithm. The default value is usually suitable for most cases, and changing it is rarely necessary.
5. Initial Learning Rate: While not an intrinsic hyperparameter of the Adam optimizer, the initial learning rate is often set before applying Adam. It determines the size of the initial steps. Many learning rate schedulers reduce the learning rate during training to fine-tune the optimization process.
6. Batch Size: Although not an Adam-specific hyperparameter, the batch size used during training can influence optimization. Smaller batch sizes can introduce more noise into gradient estimates but may help escape local minima. Larger batch sizes provide more stable gradient estimates but may lead to slower convergence.
7. Number of Training Epochs: This hyperparameter represents the number of times your entire dataset is used during training. The right number of epochs depends on your specific problem and dataset. Too few epochs can result in underfitting, while too many can lead to overfitting.
8. Regularization Strength: While not directly related to Adam, regularization techniques like L1 or L2 regularization can help control overfitting. The strength of regularization is controlled by its hyperparameter, which you may need to tune in combination with Adam’s hyperparameters.
Tuning these hyperparameters often involves experimentation and monitoring the training process to ensure the model converges to a good solution. It’s important to consider the specific characteristics of your dataset and the problem when adjusting these hyperparameters. Techniques like grid search or random search can be helpful in finding the right combination for your particular use case.
What are the advantages and disadvantages of the Adam Optimizer?
The Adam optimizer, known for its adaptive and efficient nature, offers several advantages that make it a popular choice in the machine learning community. However, like any optimization algorithm, it also comes with its own set of disadvantages. Let’s explore both sides:
Advantages:
- Adaptive Learning Rates: Adam dynamically adjusts the learning rates for each parameter, allowing it to make smaller updates for frequently changing parameters and larger updates for those that change less frequently. This adaptability can lead to faster convergence.
- Efficiency: The use of moving averages for gradient information (first and second moments) allows Adam to store and utilize past gradient information efficiently. This means it can handle large datasets and high-dimensional spaces effectively.
- Suitable for Noisy Data: Adam’s reliance on past gradients can make it robust to noisy or inconsistent gradient estimates. This is particularly useful in real-world scenarios where data quality may vary.
- Default Parameters: The Adam optimizer comes with default values for hyperparameters (e.g., β1, β2, and ε), which often work well for a wide range of problems. This makes it user-friendly and easy to implement without extensive hyperparameter tuning.
- Effective in Deep Learning: Adam has shown significant success in training deep neural networks, where optimization can be particularly challenging due to the complex, high-dimensional nature of the models.
Disadvantages:
- Memory Requirements: The Adam optimizer requires storing and updating the first and second moment estimates for each parameter, which can be memory-intensive for models with a large number of parameters. This can be a limitation in resource-constrained environments.
- Sensitivity to Learning Rate: While Adam is designed to adapt to different learning rates for each parameter, it can still be sensitive to the choice of the initial learning rate. Setting it too high can lead to divergence, while setting it too low can result in slow convergence.
- Lack of Theoretical Guarantees: Unlike some other optimization algorithms, Adam lacks strong theoretical guarantees in terms of convergence to global minima. While it often converges effectively in practice, there are scenarios where it may not reach the optimal solution.
- Difficulty in Hyperparameter Tuning: While Adam’s default hyperparameters work well for many problems, finding the optimal set of hyperparameters for a specific problem can be challenging. This can require significant experimentation and computational resources.
- Not Always the Best Choice: Despite its widespread use, the Adam optimizer is not always the best choice for every optimization problem. There are scenarios where other optimizers, such as SGD with momentum or RMSprop, may outperform Adam.
In conclusion, the Adam optimizer offers many advantages, including adaptive learning rates and efficiency, making it a valuable tool for many machine learning tasks. However, it’s essential to consider its disadvantages, such as memory requirements and sensitivity to learning rates, when deciding whether to use it for a specific problem. Careful experimentation and evaluation are key to leveraging the strengths of the Adam optimizer effectively.
How does this algorithm compare to other Optimizers?
In the vast landscape of optimization algorithms, the Adam optimizer stands as a prominent contender. To appreciate its strengths and contextualize its performance, it’s essential to compare Adam with other optimization methods.
Gradient Descent: The Adam optimizer exhibits clear advantages over vanilla gradient descent. While gradient descent uses a fixed learning rate for all parameters, Adam adapts the learning rate individually for each parameter. This adaptability enables the Adam optimizer to converge faster, especially in deep learning scenarios.
Stochastic Gradient Descent (SGD): Adam’s adaptive learning rates offer a significant improvement over SGD. SGD can often become stuck in local minima or saddle points, but Adam’s adaptability helps it escape these pitfalls. However, it’s worth noting that for small datasets, SGD might perform comparably or even better than Adam.
Momentum: SGD with momentum shares some similarities with Adam. Both algorithms introduce a notion of “momentum” to the optimization process. However, Adam’s adaptive learning rates provide more robust convergence, particularly when the landscape of the optimization problem is complex or uneven.
RMSprop: RMSprop, like Adam, adapts learning rates based on the past gradients. However, RMSprop doesn’t incorporate moving averages of gradient squares, which can lead to more erratic updates in certain situations. Adam’s inclusion of second-moment estimates helps stabilize the optimization process.
AdaGrad: AdaGrad is another optimizer that adapts learning rates but has limitations. It tends to decrease the learning rate too aggressively, resulting in slow convergence for deep neural networks. Adam’s additional mechanisms, such as bias correction and second-moment estimates, mitigate this issue.
Nadam: Nadam combines the benefits of Nesterov’s accelerated gradient (NAG) and Adam. While Nadam can offer competitive performance, particularly in deep learning, the choice between Nadam and Adam optimizer often comes down to empirical testing on a specific problem.
LBFGS: In optimization problems with a limited number of parameters, limited-memory Broyden-Fletcher-Goldfarb-Shanno (LBFGS) can be a strong contender. LBFGS maintains an approximation of the Hessian matrix and can converge efficiently. However, it may not scale well to high-dimensional problems, where Adam’s adaptability can shine.
The choice of optimization algorithm depends on the characteristics of the problem at hand. Adam’s adaptability, efficiency, and robustness make it a popular choice, especially in deep learning. Still, it’s crucial to conduct empirical evaluations and consider the specific requirements of your task when selecting the most suitable optimization algorithm. In many cases, Adam’s combination of features positions it as a reliable and versatile choice for optimizing complex models and neural networks.
How can you implement the Adam Optimizer in Python?
To implement the Adam optimizer in Python, you’ll need a few steps. First, make sure you have the necessary libraries installed, such as NumPy. You can install it using pip:

Now, let’s define the hyperparameters for the Adam optimizer. These include the learning rate (alpha), beta1, beta2, and a small epsilon (epsilon) to prevent division by zero:
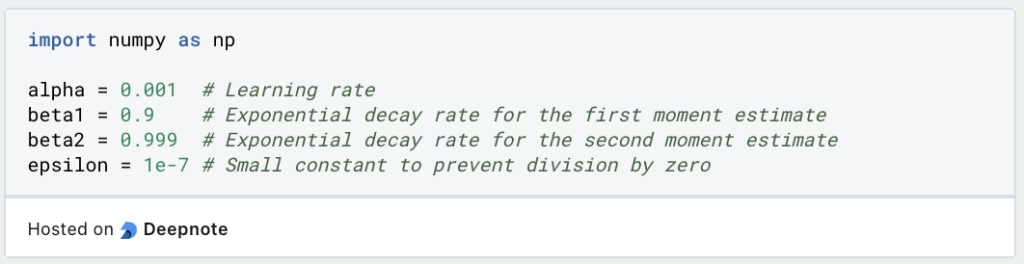
Next, initialize variables for the first and second moments (m and v) and a variable t to keep track of the time step. Also, initialize your parameter vector theta that depends on your individual project:
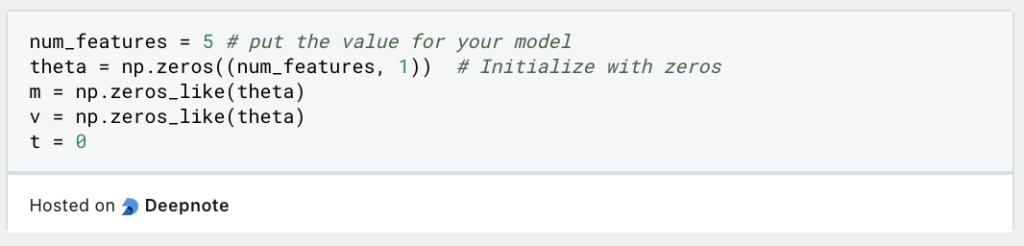
Now, you’re ready to implement the optimization loop. Iterate through your training data, and at each step, update your parameters based on the Adam optimization formula:
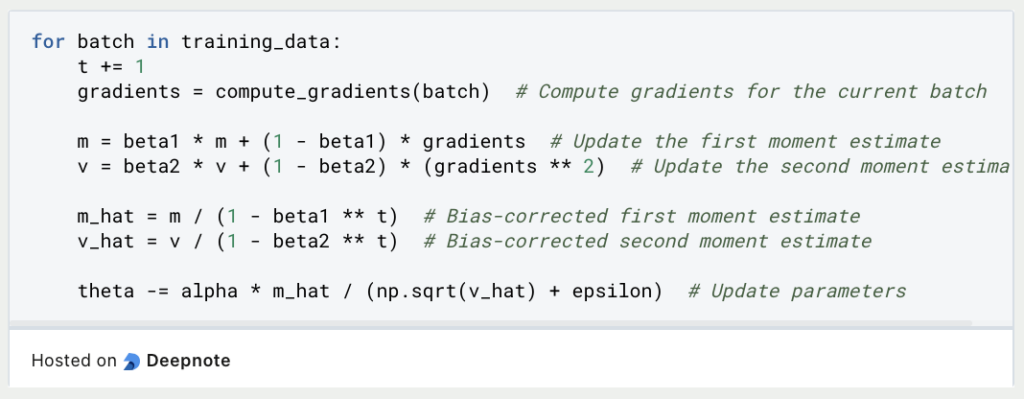
Repeat this optimization loop until your model converges to a satisfactory solution or until a predefined number of iterations. After optimization, you can use the optimized parameters (theta) for making predictions with your machine learning model.
While this is a simplified example, real-world implementations often involve additional complexities and considerations, such as mini-batch training and regularization. For practical applications, it’s recommended to use machine learning libraries like TensorFlow or PyTorch, which offer highly optimized implementations of the Adam optimizer and other optimization algorithms.
This is what you should take with you
- The Adam optimizer has emerged as a powerful tool in the realm of machine learning and deep learning. Its adaptive learning rates and efficient convergence make it a popular choice for optimizing complex models.
- Adam is versatile and can be applied to various machine learning tasks, from training neural networks to optimizing regression models. Its adaptability allows it to handle different data distributions and problem complexities effectively.
- Unlike some other optimizers, Adam performs well even in scenarios with sparse gradients. This makes it suitable for tasks involving natural language processing and recommendation systems.
- While Adam performs well with its default hyperparameters, fine-tuning these parameters can significantly impact its performance. Practitioners should experiment with different values to achieve the best results for their specific tasks.
- Adam can be combined with regularization techniques like L1 and L2 regularization to prevent overfitting and improve generalization.
- The Adam optimizer is conducive to parallelism, making it suitable for distributed training on multiple GPUs or TPUs, speeding up model training for large datasets.
- Practitioners should monitor training using metrics like loss and validation performance. Early stopping can prevent overfitting and save training time.
- While Adam is a robust optimizer, it’s essential to keep an eye on potential issues like vanishing or exploding gradients, which can affect convergence.

What is One-Shot Learning?
Mastering one shot learning: Techniques for rapid knowledge acquisition and adaptation. Boost AI performance with minimal training data.

What is the Bellman Equation?
Mastering the Bellman Equation: Optimal Decision-Making in AI. Learn its applications & limitations. Dive into dynamic programming!

What is the Singular Value Decomposition?
Unlocking insights and patterns: Learn the power of Singular Value Decomposition (SVD) in data analysis. Discover its applications.

What is the Poisson Regression?
Learn about Poisson regression, a statistical model for count data analysis. Implement Poisson regression in Python for accurate predictions.

What is blockchain-based AI?
Discover the potential of Blockchain-Based AI in this insightful article on Artificial Intelligence and Distributed Ledger Technology.

What is Boosting?
Boosting: An ensemble technique to improve model performance. Learn boosting algorithms like AdaBoost, XGBoost & more in our article.
Other Articles on the Topic of Adam Optimizer
This documentation describes how to use the Adam Optimizer in TensorFlow.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.