Boosting ist eine beliebte Technik des maschinellen Lernens, die sich bei der Verbesserung der Genauigkeit verschiedener Modelltypen als wirksam erwiesen hat. Es handelt sich um eine Art von Ensemble-Lernen, bei dem mehrere schwache Modelle zu einem starken Modell kombiniert werden. Boosting-Algorithmen werden häufig in Bereichen wie dem maschinellen Sehen, der Verarbeitung natürlicher Sprache und der Spracherkennung eingesetzt.
In diesem Artikel werden wir das Konzept des Boosting im Bereich des maschinellen Lernens, seine Funktionsweise und seine verschiedenen Anwendungen untersuchen. Außerdem werden wir die Vor- und Nachteile von Boosting sowie einige beliebte Algorithmen in diesem Bereich erörtern.
Was ist Boosting?
Beim maschinellen Lernen werden nicht immer nur einzelne Modelle verwendet. Um die Leistung des gesamten Programms zu verbessern, werden manchmal mehrere Einzelmodelle zu einem so genannten Ensemble kombiniert. Ein Random Forest zum Beispiel besteht aus vielen einzelnen Entscheidungsbäumen, deren Ergebnisse zu einem Ergebnis zusammengefasst werden.
Boosting beschreibt das Verfahren, mehrere Modelle zu einem Ensemble zu kombinieren. Am Beispiel der Entscheidungsbäume werden die Trainingsdaten zum Trainieren eines Baumes verwendet. Für alle Daten, für die der erste Entscheidungsbaum schlechte oder falsche Ergebnisse liefert, wird ein zweiter Entscheidungsbaum gebildet. Dieser wird dann nur mit den Daten trainiert, die der erste Baum falsch klassifiziert hat. Diese Kette wird fortgesetzt, und der nächste Baum verwendet wiederum die Informationen, die in den ersten beiden Bäumen zu falschen Ergebnissen geführt haben.
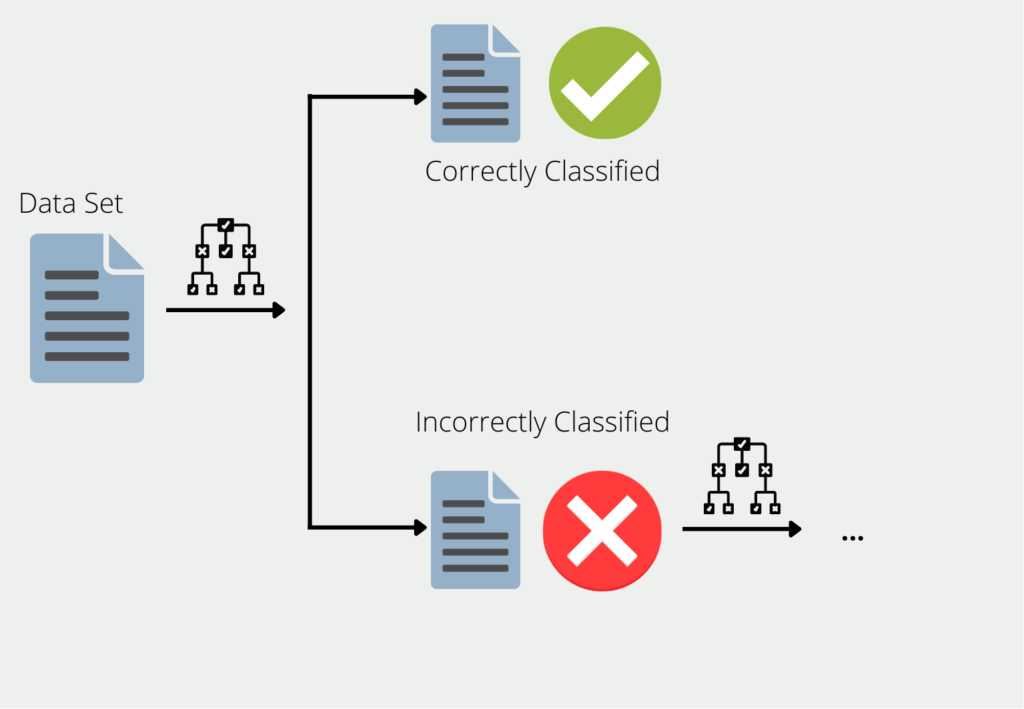
Das Ensemble aus all diesen Entscheidungsbäumen kann dann gute Ergebnisse für den gesamten Datensatz liefern, da jedes einzelne Modell die Schwächen der anderen ausgleicht. Dies wird auch als Kombination vieler “schwacher Lerner” zu einem “starken Lerner” bezeichnet.
Welche verschiedenen Algorithmen gibt es für Boosting?
Es gibt mehrere beliebte Algorithmen, die im Laufe der Jahre entwickelt wurden. Hier sind einige der am häufigsten verwendeten:
AdaBoost
Adaptive Boosting, oder kurz AdaBoost, ist eine spezielle Variante des Boosting. Es versucht, mehrere schwache Lerner zu einem starken Modell zu kombinieren. In seiner Grundform funktioniert Adaptive Boost am besten mit Entscheidungsbäumen. Allerdings verwenden wir nicht die “ausgewachsenen” Bäume mit teilweise mehreren Ästen, sondern nur die Stümpfe, d.h. Bäume mit nur einem Ast. Diese werden “Entscheidungsstümpfe” genannt.

In unserem Beispiel wollen wir eine Klassifikation trainieren, die vorhersagen kann, ob eine Person gesund ist oder nicht. Hierfür verwenden wir insgesamt drei Merkmale: Alter, Gewicht und die Anzahl der Stunden Sport pro Woche. In unserem Datensatz gibt es insgesamt 20 untersuchte Personen. Der Adaptive-Boost-Algorithmus arbeitet nun in mehreren Schritten:
- Schritt 1: Für jedes Merkmal wird ein Entscheidungsstumpf mit dem gewichteten Datensatz trainiert. Zu Beginn haben alle Datenpunkte noch das gleiche Gewicht. In unserem Fall bedeutet das, dass wir einen einzigen Stumpf für Alter, Gewicht und Sportstunden haben, der die Gesundheit direkt anhand des Merkmals klassifiziert.
- Schritt 2: Aus den drei Entscheidungsstümpfen wählen wir das Modell aus, das die beste Erfolgsquote aufweist. Nehmen wir an, der Stumpf mit den Sportstunden hat am besten abgeschnitten. Von den 20 Personen konnte er bereits 15 richtig klassifizieren. Die fünf falsch klassifizierten erhalten nun eine höhere Gewichtung im Datensatz, um sicherzustellen, dass sie im nächsten Modell richtig klassifiziert werden.
- Schritt 3: Der neu gewichtete Datensatz wird nun verwendet, um wieder drei neue Decision Stumps zu trainieren. Mit dem “neuen” Datensatz” schnitt diesmal der Stumpf mit dem Merkmal “Alter” am besten ab und klassifizierte nur drei Personen falsch.
- Schritt 4: Die Schritte zwei und drei werden nun so lange wiederholt, bis entweder alle Datenpunkte richtig klassifiziert wurden oder die maximale Anzahl der Iterationen erreicht wurde. Dies bedeutet, dass das Modell die neue Gewichtung des Datensatzes und das Training neuer Entscheidungsstümpfe wiederholt.
Jetzt verstehen wir, woher der Name “Adaptive” in AdaBoost kommt. Durch die Neugewichtung des ursprünglichen Datensatzes “passt” sich das Ensemble mehr und mehr an den konkreten Anwendungsfall an.
Gradient Boosting
Gradient Boosting wiederum ist eine Teilmenge vieler verschiedener Algorithmen. Die Grundidee dahinter ist, dass das nächste Modell so aufgebaut werden sollte, dass es die Ensemble-Verlustfunktion weiter minimiert.
In den einfachsten Fällen beschreibt die Verlustfunktion einfach die Differenz zwischen der Vorhersage des Modells und dem tatsächlichen Wert. Nehmen wir an, wir trainieren eine KI für die Vorhersage eines Hauspreises. Die Verlustfunktion könnte dann einfach der mittlere quadratische Fehler zwischen dem tatsächlichen Preis des Hauses und dem vorhergesagten Preis des Hauses sein. Im Idealfall nähert sich die Funktion im Laufe der Zeit der Null und unser Modell kann die richtigen Preise vorhersagen.
Neue Modelle werden so lange hinzugefügt, bis Vorhersage und Realität nicht mehr voneinander abweichen, d. h. die Verlustfunktion das Minimum erreicht hat. Jedes neue Modell versucht, den Fehler des vorherigen Modells vorherzusagen.
Kehren wir zu unserem Beispiel mit den Hauspreisen zurück. Nehmen wir an, ein Haus hat eine Wohnfläche von 100 m², vier Zimmer und eine Garage und kostet 200.000 €. Das Gradient-Boosting-Verfahren würde dann wie folgt aussehen:
Training einer Regression zur Vorhersage des Kaufpreises mit den Merkmalen Wohnfläche, Anzahl der Zimmer und Garage. Dieses Modell sagt einen Kaufpreis von 170.000 € statt der tatsächlichen 200.000 € voraus, der Fehler beträgt also 30.000 €.
Training einer weiteren Regression, die den Fehler des vorherigen Modells mit den Merkmalen Wohnfläche, Anzahl der Zimmer und Garage vorhersagt. Dieses Modell sagt eine Abweichung von 23.000 € statt der tatsächlichen 30.000 € voraus. Der verbleibende Fehler beträgt also 7.000 €.
XGBoost
XGBoost (Extreme Gradient Boosting) ist eine leistungsstarke Implementierung des Boosting-Algorithmus, der beim maschinellen Lernen weit verbreitet ist. Er wurde von Tianqi Chen und Kollegen an der University of Washington entwickelt und hat sich aufgrund seiner Effizienz und Genauigkeit sowohl in der Wissenschaft als auch in der Industrie durchgesetzt.
XGBoost ist ein entscheidungsbaumbasierter Boosting-Algorithmus, bei dem iterativ schwache Modelle zum Ensemble hinzugefügt werden, um die Gesamtleistung zu verbessern. Er wurde entwickelt, um Verlustfunktionen zu minimieren und gleichzeitig die Komplexität des Modells zu berücksichtigen. Er verwendet den Gradientenabstieg zur Optimierung der Verlustfunktion und beschneidet die Entscheidungsbäume, um eine Überanpassung zu vermeiden.
Eines der wichtigsten Merkmale von XGBoost ist die Fähigkeit, mit fehlenden Daten umzugehen. Dazu werden fehlende Werte als ein weiteres Merkmal behandelt und es wird gelernt, wie sie optimal genutzt werden können. Dazu werden die Daten in zwei Gruppen aufgeteilt: eine mit fehlenden Werten und eine ohne. Der Algorithmus lernt dann, wie er die fehlenden Werte am besten verwenden kann, indem er die Muster in den Daten und deren Beziehung zur Zielvariablen berücksichtigt.
XGBoost ermöglicht auch die parallele Verarbeitung, was bedeutet, dass es die Vorteile mehrerer CPU-Kerne nutzen kann, um den Trainingsprozess noch weiter zu beschleunigen. Außerdem verfügt es über eine Vielzahl von Hyperparametern, die zur Verbesserung der Leistung bei bestimmten Aufgaben angepasst werden können.
Insgesamt ist XGBoost ein leistungsfähiger und flexibler Boosting-Algorithmus, der für viele Anwendungen des maschinellen Lernens eine beliebte Wahl geworden ist. Dank seiner Fähigkeit, mit fehlenden Daten, großen Datensätzen und paralleler Verarbeitung umzugehen, ist er für eine Vielzahl von Aufgaben gut geeignet.
Was sind die Vor- und Nachteile von Boosting?
Der allgemeine Vorteil von Boosting ist, dass viele schwache Lerner zu einem starken Modell kombiniert werden. Trotz einer großen Anzahl kleiner Modelle sind diese Boosting-Algorithmen in der Regel einfacher zu berechnen als vergleichbare neuronale Netze. Das bedeutet aber nicht unbedingt, dass sie auch schlechtere Ergebnisse liefern. In einigen Fällen können Ensemble-Modelle die komplexeren Netze in Bezug auf die Genauigkeit sogar übertreffen. Daher sind sie auch interessante Kandidaten für Text- oder Bildklassifizierungen.
Darüber hinaus sind Boosting-Algorithmen wie AdaBoost auch weniger anfällig für Overfitting. Das bedeutet einfach, dass sie nicht nur mit dem Trainingsdatensatz gut abschneiden, sondern auch mit neuen Daten eine gute Klassifizierung mit hoher Genauigkeit vornehmen. Es wird angenommen, dass die mehrstufige Modellberechnung von Boosting-Algorithmen nicht so anfällig für Abhängigkeiten ist wie die Schichten in einem neuronalen Netz, da die Modelle nicht zusammenhängend optimiert werden, wie es bei Backpropagation im Modell der Fall ist.
Aufgrund des schrittweisen Trainings der einzelnen Modelle haben Boosting-Modelle oft eine relativ langsame Lernrate und benötigen daher mehr Iterationen, um gute Ergebnisse zu liefern. Außerdem benötigen sie sehr gute Datensätze, da die Modelle sehr sensibel sind.
Was sind die Unterschiede zwischen Boosting und Ensemble Learning?
Boosting und Ensemble Learning sind zwei beliebte Techniken, die beim maschinellen Lernen zur Verbesserung der Genauigkeit von Modellen eingesetzt werden. Ensemble-Lernen bezieht sich auf den Prozess der Kombination mehrerer Modelle, um eine endgültige Vorhersage zu erstellen. Boosting ist eine spezielle Art des Ensemble-Lernens, bei der nacheinander Modelle zum Ensemble hinzugefügt werden, wobei sich jedes neue Modell darauf konzentriert, die Fehler des vorherigen Modells zu korrigieren.
Hier sind einige wichtige Unterschiede zwischen Boosting und Ensemble-Lernen:
- Sequentiell vs. Parallel: Beim Boosting werden Modelle sequentiell hinzugefügt, während beim Ensemble-Lernen Modelle parallel kombiniert werden.
- Fehlerkorrektur: Beim Boosting liegt der Schwerpunkt auf der Korrektur der Fehler früherer Modelle, während beim Ensemble-Lernen die Stärken mehrerer Modelle kombiniert werden sollen, um ein besseres Gesamtergebnis zu erzielen.
- Komplexität der Modelle: Beim Boosting werden in der Regel schwache Modelle verwendet, wie z. B. Entscheidungsbäume mit geringer Tiefe, während beim Ensemble-Lernen komplexere Modelle verwendet werden können.
- Trainingsdaten: Beim Boosting werden für jedes Modell dieselben Trainingsdaten verwendet, aber die Gewichte der falsch klassifizierten Proben angepasst, während beim Ensemble-Lernen unterschiedliche Trainingsdaten für jedes Modell verwendet werden können.
- Vorhersagezeit: Boosting kann langsamer sein als Ensemble-Lernen, da jedes neue Modell auf dem gesamten Datensatz trainiert werden muss, während beim Ensemble-Lernen nur das Training mehrerer Modelle parallel erforderlich ist.
Insgesamt sind sowohl Boosting als auch Ensemble-Learning wirksame Techniken zur Verbesserung der Genauigkeit von Modellen des maschinellen Lernens. Die Wahl der zu verwendenden Methode hängt von dem jeweiligen Problem und den verfügbaren Ressourcen ab. Boosting wird häufig eingesetzt, wenn eine große Menge an Trainingsdaten vorhanden ist und ein hohes Maß an Genauigkeit erforderlich ist, während Ensemble-Learning möglicherweise besser geeignet ist, wenn nur begrenzte Ressourcen zur Verfügung stehen oder wenn ein Gleichgewicht zwischen Genauigkeit und Einfachheit angestrebt wird.
Das solltest Du mitnehmen
- Boosting ist eine leistungsstarke Technik des maschinellen Lernens, die die Leistung schwacher Lerner verbessern kann.
- Boosting-Algorithmen wie AdaBoost, Gradient Boosting und XGBoost unterscheiden sich in ihren Ansätzen für die Aktualisierung der Gewichte, die Auswahl der Merkmale und die Komplexität des Modells.
- XGBoost ist ein weit verbreiteter und leistungsstarker Boosting-Algorithmus, der viele Data-Science-Wettbewerbe gewonnen hat und für seine Geschwindigkeit und Genauigkeit bekannt ist.
- Boosting kann mit dem Ensemble-Lernen verglichen werden, bei dem ebenfalls mehrere Modelle kombiniert werden. Der Unterschied zwischen Boosting und Ensemble-Lernen besteht jedoch darin, dass die Gewichte iterativ aktualisiert werden und der Schwerpunkt auf schwierigen Beispielen liegt.
- Boosting kann für eine Vielzahl von Aufgaben effektiv sein, neigt aber auch zur Überanpassung und erfordert eine sorgfältige Abstimmung der Hyperparameter.
- Insgesamt ist Boosting ein wertvolles Verfahren im Werkzeugkasten des maschinellen Lernens und kann die Leistung von Modellen erheblich verbessern.

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.

Was ist der Omitted Variable Bias?
Verständnis des Omitted Variable Bias: Ursachen, Konsequenzen und Prävention. Erfahren Sie, wie Sie diese Falle vermeiden.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.

Was ist die Singular Value Decomposition?
Erkenntnisse und Muster freilegen: Lernen Sie die Leistungsfähigkeit der Singular Value Decomposition (SVD) in der Datenanalyse kennen.
Andere Beiträge zum Thema Boosting
Amazon Web Services bietet einen interessanten Artikel zu diesem Thema.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.