Die Batch- oder Stapelverarbeitung ist ein Begriff aus dem Bereich der Datenverarbeitung und beschreibt Prozesse, die immer direkt für eine Gruppe von Daten ausgeführt werden, statt für jeden Datensatz einzeln. Dadurch können Ressourcen gespart werden, da die Verarbeitung nicht jedes mal einzeln gestartet werden muss und dadurch in den Zwischenzeiten der Computer inaktiv sein kann.
Was ist die Stapelverarbeitung?
Bei der Batchverarbeitung werden Daten immer erst dann verarbeitet, wenn sich eine gewisse Menge angesammelt hat. Der Trigger für den Start des Prozesses kann entweder ein bestimmter Zeitpunkt sein, wie beispielsweise einmal am Tag, oder über die Datenmenge reguliert werden, beispielsweise wenn sich 100 Datensätze angesammelt haben.
Ein Alltagsbeispiel für die Stapelverarbeitung ist die Kreditkartenabrechnung. Dabei werden alle Zahlungen, die mit der Kreditkarte getätigt wurden, lediglich einmal im Monat verarbeitet und dem Kunden in Rechnung gestellt, statt jede Zahlung einzeln zu verarbeiten. Dadurch werden die Ressourcen für die Verarbeitung lediglich einmal im Monat benötigt, anstatt rund um die Uhr sobald eine Zahlung passiert.
Weitere Alltagsbeispiele für die batchweise Verarbeitung von Daten sind:
- Lohnabrechnungen für Mitarbeiter: Die Mitarbeiter von Unternehmen bekommen ein- oder zweimal im Monat eine Lohnabrechnung anstatt täglich oder stündlich die Arbeitszeit zu verrechnen.
- Versandhandel: Im Versand werden, wenn möglich, alle Produkte eines Auftrags in einem einzelnen Paket versendet und über eine Rechnung kassiert. Es wäre viel umständlicher, die Produkte einzeln abzurechnen und auszusenden. Dafür kann es jedoch passieren, dass Produkte, die eigentlich schon auf Lager wären, warten müssen bis alle Produkte des Auftrages vorrätig sind.
Was sind Vor- und Nachteile der Stapelverarbeitung?
Zu den Vorteilen von Batchverarbeitungssystemen zählt die hohe Planbarkeit und damit einhergehende Effizienz, da genau geplant werden kann, wann die Batches zur Verarbeitung kommen und in welchem Zeitraum dann vermehrt Computerressourcen benötigt werden. In der restlichen Zeit lässt sich die Rechenleistung für andere Projekte nutzen.
Zusätzlich wird nur wenig Wartungsarbeit benötigt, da die Pipeline lediglich ein einziges Mal eingerichtet werden muss und, falls keine Fehler auftreten, ungestört weiterläuft. Durch die Vermeidung von manueller Arbeit und dem Automatisieren des Prozesses wird auch die Datenqualität erhöht, da es zu keinen ungewollten Änderungen der Daten kommen kann. Diese erhöhte Datenqualität führt auch zu besseren Ergebnissen bei der Nutzung von Künstlicher Intelligenz.
Ein Nachteil der Stapelverarbeitung ist die Aktualität der Daten. Wenn ein Datenjob lediglich einmal am Tag läuft, können keine Echtzeitdaten bereitgestellt werden. Diese werden jedoch in vielen Anwendungen heutzutage eingefordert. Es muss daher abhängig vom Anwendungsfall entschieden werden, wie wichtig die Datenaktualität ist.
Zusätzlich ist die Einführung von Batchverarbeitung mit einem gewissen Know-How verbunden, das entweder eingekauft oder durch Schulungen von Mitarbeitern erarbeitet werden muss. Auch hier gilt es eine Kosten-Nutzen-Analyse durchzuführen, um herauszufinden, ob sich die Einführung der Batchverarbeitung finanziell lohnt.
Warum nutzen Unternehmen Batchverarbeitung von Daten?
In der Realität gibt es einige Datenjobs, die keinen Anspruch auf die Echtzeit der Daten erheben und trotzdem automatisiert werden sollten. Dafür nutzen viele Unternehmen Batchverarbeitung, um Kosten einzusparen. Zu diesen Prozessen können beispielsweise zählen:
- Die monatliche Abrechnung der Gehälter.
- Das Laden von produktiven Datenbanken in das Data Warehouse, was auch nur einmal am Tag ausreichend ist.
- Das Tracking von ausstehenden Lieferungen kann auch über eine Batchverarbeitung stattfinden, wenn die Liefertermine nicht häufig aktualisiert werden.
Wie können Architekturen für das Batch Processing aussehen?
Stapelverarbeitungsarchitekturen beziehen sich auf die zugrundeliegenden Frameworks und Systeme, die für den Entwurf, die Implementierung und die Verwaltung von Stapelverarbeitungsabläufen verwendet werden. Es gibt verschiedene Stapelverarbeitungsarchitekturen, die jeweils ihre eigenen Vorteile und Einschränkungen haben. Zu den gängigsten Stapelverarbeitungsarchitekturen gehören:
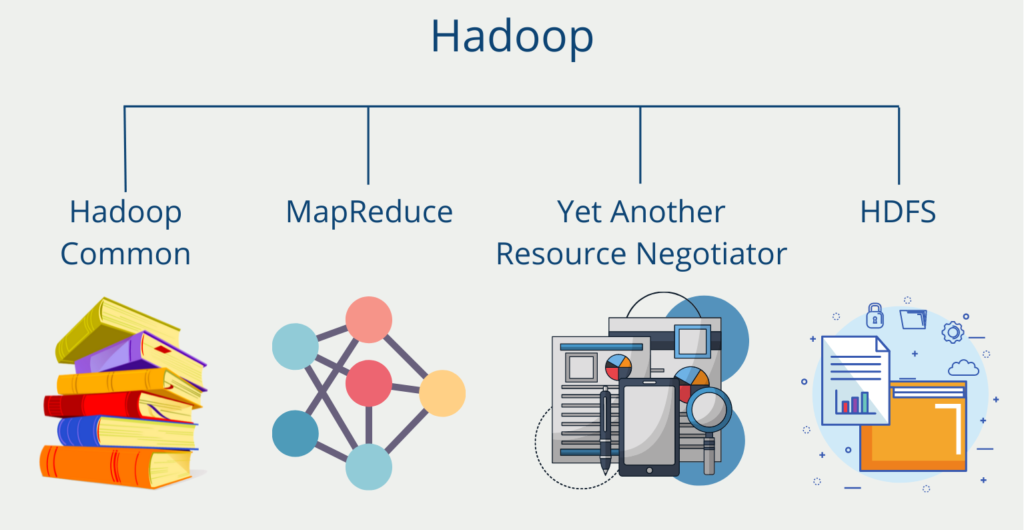
- Hadoop: Hadoop ist ein Open-Source-Framework, das für die Verarbeitung großer Datenmengen in verteilten Rechenclustern konzipiert ist. Hadoop verwendet das Hadoop Distributed File System (HDFS) zum Speichern und Verteilen von Daten auf mehrere Knoten in einem Cluster. Hadoop umfasst auch das MapReduce-Programmiermodell für die parallele Verarbeitung von Daten im gesamten Cluster.
- Apache Spark: Apache Spark ist ein schnelles und universell einsetzbares Cluster-Computing-System, das für die Verarbeitung großer Datenmengen konzipiert ist. Spark umfasst eine Stapelverarbeitungs-Engine, die für die parallele Verarbeitung großer Datenmengen verwendet werden kann. Spark bietet darüber hinaus eine Reihe weiterer Funktionen, wie Stream-Verarbeitung in Echtzeit, SQL-Abfragen und maschinelles Lernen.
- Apache Flink: Apache Flink ist ein Open-Source-Framework für die Stream-Verarbeitung, das auch Unterstützung für die Stapelverarbeitung bietet. Flink wurde für die Hochleistungsdatenverarbeitung entwickelt und unterstützt sowohl Batch- als auch Stream-Verarbeitungsanwendungen.
- Apache Beam: Apache Beam ist ein quelloffenes, einheitliches Programmiermodell, das sowohl für die Stapel- als auch für die Stream-Verarbeitung verwendet werden kann. Beam bietet eine Reihe von APIs, die zum Schreiben von Datenverarbeitungspipelines verwendet werden können, die auf einer Vielzahl von Batch- und Stream-Verarbeitungsmaschinen ausgeführt werden können.
- Apache Airflow: Apache Airflow ist eine Open-Source-Plattform zum Entwerfen, Planen und Überwachen von Datenverarbeitungs-Workflows. Airflow bietet eine Reihe von Funktionen für die Verwaltung von Workflows, einschließlich Unterstützung für Aufgabenabhängigkeiten, Fehlerbehandlung und parallele Ausführung.
Insgesamt hängt die Wahl der Stapelverarbeitungsarchitektur von den spezifischen Anforderungen des jeweiligen Anwendungsfalls sowie von Faktoren wie Skalierbarkeit, Leistung und Benutzerfreundlichkeit ab.
Welche Alternativen gibt es?
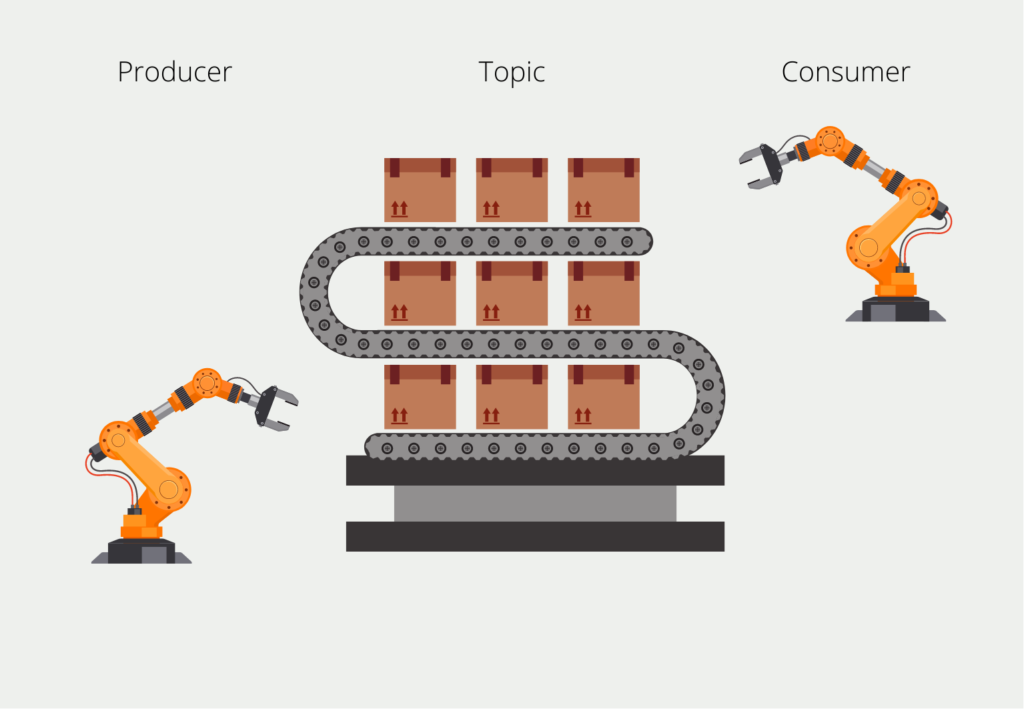
Die Alternative zur Batchverarbeitung ist die sogenannte Streamverarbeitung, bei der die Daten verarbeitet werden, sobald sie eintreffen. Dadurch lassen sich Daten in Echtzeit auswerten und weitergeben. Die Informationen kommen dabei als sogenannter Datenstream, beispielsweise in Apache Kafka, an und werden direkt beim Eintreffen verarbeitet.
Diese Art bietet sich vor allem dann an, wenn eine hohe Datenaktualität gewährleistet sein muss und die benötigten Computerressourcen eine untergeordnete Rolle spielen. Zusätzlich macht es auch mehr Sinn Daten in Streams zu verarbeiten, wenn die Anwendung besonders viele und große Daten handhaben muss. Dann ist die Batchverarbeitung meist aufgrund der hohen, punktuellen Belastungen nicht möglich oder deutlich kostenintensiver.
Was ist der Unterschied zwischen Streamverarbeitung und Batchverarbeitung?
Die Entscheidung für eine Architektur bei der Datenverarbeitung ist relativ schwierig und vom Einzelfall abhängig. Gleichzeitig kann es auch dazu kommen, dass heute noch keine Echtzeitdatenverarbeitung gefordert ist und sich das jedoch in naher Zukunft schon wieder ändert. Wichtig ist deshalb herauszufinden, welcher Zeithorizont bei der jeweiligen Anwendung nötig ist.
Die Batchverarbeitung eignet sich dabei für die Prozessierung von großen Datenmenge, die meist in regelmäßigen Abständen anfallen. In diesen Fällen biete eine batchweise Verarbeitung eine hohe Effizienz und die Automatisierung des Prozesses bei vergleichsweise niedrigen Kosten.
Wenn die Echtzeitverarbeitung der Daten im Vordergrund steht, sollte streamweise gearbeitet werden. Das bietet sich auch dann an, wenn kontinuierlich neue Datensätze entstehen, wie beispielsweise bei Sensordaten. Jedoch ist dafür der Umsetzungs- und Wartungsaufwand deutlich höher, da das System durchgehend erreichbar sein muss und somit die ganze Zeit Computerressourcen blockiert werden.
Welche Grenzen gibt es bei der Stapelverarbeitung?
Die Stapelverarbeitung hat trotz ihrer Vorteile einige Einschränkungen, die es zu beachten gilt:
- Latenzzeit: Eine der größten Einschränkungen der Stapelverarbeitung ist die Latenzzeit. Da die Stapelverarbeitung nicht in Echtzeit erfolgt, gibt es oft eine Verzögerung zwischen der Datenerfassung und der Verarbeitung. Diese Verzögerung kann sich als Nachteil erweisen, wenn es um zeitkritische Daten geht, z. B. bei Finanztransaktionen oder Echtzeitüberwachung.
- Unflexibilität: Die Stapelverarbeitung ist unflexibel in dem Sinne, dass es schwierig sein kann, Änderungen an einem einmal eingerichteten Prozess vorzunehmen. Alle vorgenommenen Änderungen können sich auf den gesamten Stapel auswirken, was problematisch sein kann, wenn die Daten zeitkritisch sind oder bereits verarbeitet wurden.
- Komplexität: Die Datenverarbeitung kann sehr komplex sein, vor allem wenn es um große Datenmengen oder komplexe Umwandlungen geht. Diese Komplexität kann die Wartung und Fehlerbehebung von Stapelverarbeitungssystemen erschweren.
- Ressourcenintensiv: Die Stapelverarbeitung kann ressourcenintensiv sein, sowohl in Bezug auf die Hardware- als auch auf die Softwareanforderungen. Die Verarbeitung großer Datenmengen erfordert leistungsfähige Hardware und Software, deren Anschaffung und Wartung teuer sein kann.
- Probleme mit der Datenqualität: Die Stapelverarbeitung kann auch zu Problemen mit der Datenqualität führen, wenn die Daten fehlerhaft sind oder die Verarbeitungsschritte nicht gut durchdacht sind. Diese Datenqualitätsprobleme können schwer zu erkennen und zu korrigieren sein, was sich auf die Genauigkeit und Zuverlässigkeit der Ergebnisse auswirken kann.
Zusammenfassend lässt sich sagen, dass die Stapelverarbeitung zwar ein wertvolles Instrument für die Verarbeitung großer Datenmengen ist, jedoch einige Einschränkungen aufweist, die berücksichtigt werden müssen. Eine sorgfältige Planung und Gestaltung kann dazu beitragen, einige dieser Einschränkungen zu mildern und sicherzustellen, dass die Verarbeitung effektiv genutzt wird.
Das solltest Du mitnehmen
- Die Batch- oder Stapelverarbeitung ist ein Begriff aus dem Bereich der Datenverarbeitung und beschreibt Prozesse, die immer direkt für eine Gruppe von Daten ausgeführt werden, statt für jeden Datensatz einzeln.
- Sie bietet sich vor allem dann an, wenn die Daten unregelmäßig und in großen Datenmengen entstehen.
- Falls hingegen die Informationen in Echtzeit verarbeitet werden müssen, sollte man auf die sogenannte Streamverarbeitung zurückgreifen.

Was ist der Conjugate Gradient?
Erforschen Sie den Conjugate Gradient: Algorithmusbeschreibung, Varianten, Anwendungen und Grenzen.

Was ist ein Elastic Net?
Entdecken Sie Elastic Net: Die vielseitige Regularisierungstechnik beim Machine Learning für bessere Modellbalance und Vorhersagen.

Was ist Adversarial Training?
Sicheres maschinelles Lernen: Erklärung von Adversarial Training, dessen Anwendungen und Probleme.

Was sind Echo State Networks?
Verstehen Sie Echo State Networks: Dynamic Time-Series Modeling, Applikationen und wie man sie in Python implementiert.

Was sind Faktorgraphen?
Entdecken Sie die Vielseitigkeit von Faktorgraphen bei der grafischen Modellierung und bei praktischen Anwendungen.

Was ist Unsupervised Domain Adaptation?
Beherrschen Sie die Unsupervised Domain Adaptation: Überbrücken Sie die Lücke zwischen Quell- und Zieldomänen für Lernmodelle.
Andere Beiträge zum Thema Stapelverarbeitung
- Eine Anleitung zur Batchverarbeitung in Microsoft Azure findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.