Hadoop ist ein Softwareframework mit dem sich große Datenmengen auf verteilten Systemen schnell verarbeiten lassen. Es verfügt über Mechanismen, welche eine stabile und fehlertolerante Funktionalität sicherstellen, sodass das Tool für die Datenverarbeitung im Big Data Umfeld bestens geeignet ist.
Welche Bestandteile gehören zu Hadoop?
Das Softwareframework selbst ist eine Zusammenstellung aus insgesamt vier Komponenten.
Hadoop Common ist eine Sammlung aus verschiedenen Modulen und Bibliotheken, welche die anderen Bestandteile unterstützt und deren Zusammenarbeit ermöglicht. Unter anderem sind hier die Java Archive Dateien (JAR Files) abgelegt, die zum Starten von Hadoop benötigt werden. Darüber hinaus ermöglicht die Sammlung die Bereitstellung von grundlegenden Services, wie beispielsweise das File System.
Der Map-Reduce Algorithmus geht in seinen Ursprüngen auf Google zurück und hilft komplexe Rechenaufgaben in überschaubarere Teilprozesse aufzuteilen und diese dann über mehrere Systeme zu verteilen, also horizontal zu skalieren. Dadurch verringert sich die Rechenzeit deutlich. Am Ende müssen die Ergebnisse der Teilaufgaben wieder zu seinem Gesamtresultat zusammengefügt werden.
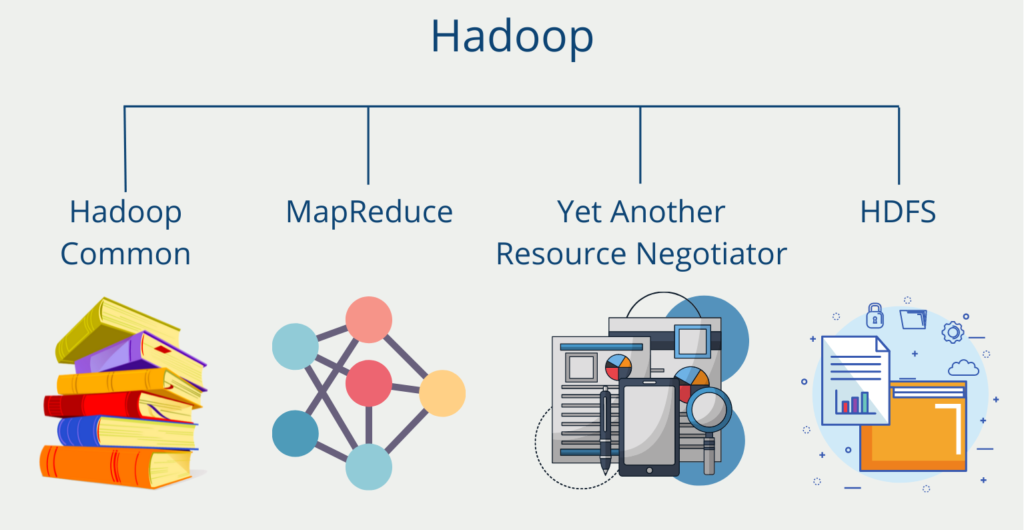
Der Yet Another Resource Negotiator (YARN) unterstützt den Map-Reduce Algorithmus, indem er die Ressourcen innerhalb eines Computer Clusters im Auge behält und die Teilaufgaben auf die einzelnen Rechner verteilt. Darüber hinaus ordnet er den einzelnen Prozessen die Kapazitäten dafür zu.
Das Hadoop Distributed File System (HDFS) ist ein skalierbares Dateisystem zur Speicherung von Zwischen- oder Endergebnissen. Innerhalb des Clusters ist es über mehrere Rechner verteilt, um große Datenmengen schnell und effizient verarbeiten zu können. Die Idee dahinter war, dass Big Data Projekte und Datenanalysen auf großen Datenmengen beruhen. Somit sollte es ein System geben, welches die Daten auch stapelweise speichert und dadurch schnell verarbeitet. Das HDFS sorgt auch dafür, dass Duplikate von Datensätzen abgelegt werden, um den Ausfall eines Rechners verkraften zu können.
Wie funktioniert Hadoop?
Angenommen wir wollen aus einer Million deutschen Büchern die Wortverteilung auswerten. Für einen einzelnen Computer wäre das eine gewaltige Aufgabe. Der Map-Reduce Algorithmus würde in diesem Beispiel erst die Gesamtaufgabe in überschaubarere Teilprozesse unterteilen. Das könnte beispielsweise so aussehen, dass man zuerst die Bücher einzeln betrachtet und für jedes Buch das Wortvorkommen und die -verteilung bestimmt. Die einzelnen Bücher würden somit auf die Knoten verteilt werden und für die einzelnen Werke die Ergebnistabellen erstellt werden.
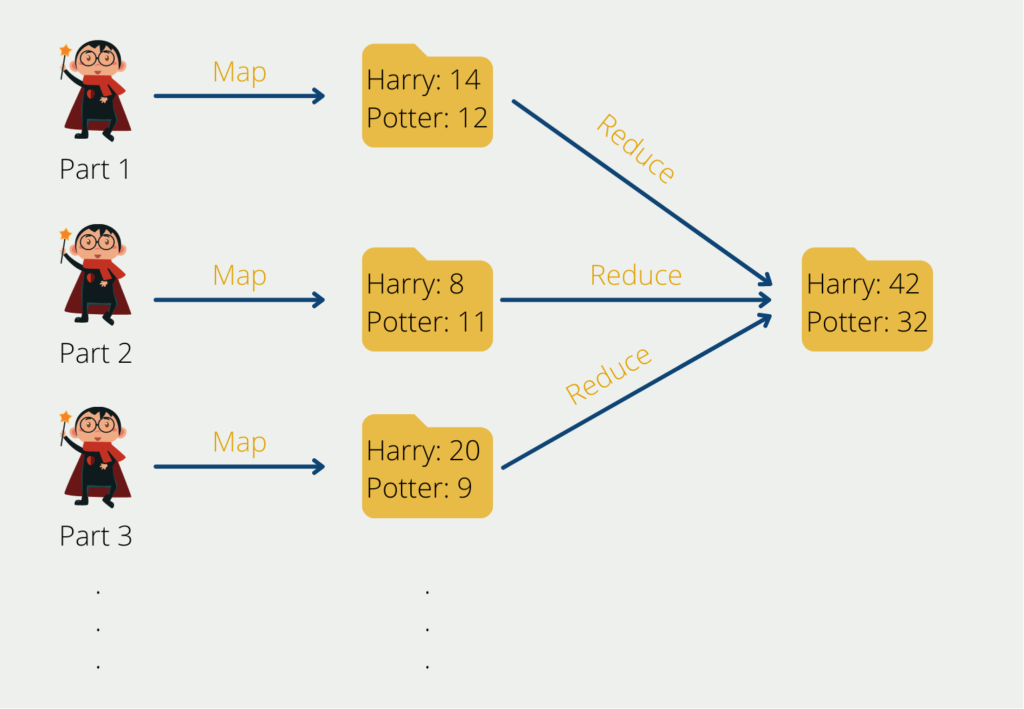
Innerhalb des Computerclusters haben wir einen Knoten, der die Rolle des sogenannten Masters übernimmt. Dieser führt in unserem Beispiel keine direkte Berechnung durch, sondern verteilt lediglich die Aufgaben auf die sogenannten Slave Knoten und koordiniert den ganzen Prozess. Die Slave Knoten wiederum lesen die Bücher aus und speichern die Worthäufigkeit und die Wortverteilung.
Sobald dieser Schritt abgeschlossen ist, kann nur noch mit den Ergebnistabellen weitergearbeitet werden und wir benötigen die speicherintensiven Ausgangsbücher nicht mehr. Die finale Aufgabe, also die Zwischentabellen zu aggregieren und das Endergebnis zu berechnen, kann anschließend auch wieder parallelisiert werden oder, je nach Aufwand, von einem einzigen Knoten übernommen werden.
Was sind die Vor- und Nachteile des Programms?
Hadoop ist ein leistungsfähiges Open-Source-Software-Framework, das zur Speicherung und Verarbeitung großer Datenmengen in einer verteilten Umgebung verwendet wird. Es ist für die Verarbeitung riesiger Datenmengen ausgelegt und daher eine beliebte Wahl für die Verarbeitung großer Datenmengen.
Im Überblick ergeben sich die folgenden Vorteile:
- Skalierbarkeit: Das Framework kann leicht skaliert werden, um große Datenmengen zu verarbeiten. Dem Cluster können Knoten hinzugefügt werden, um die Verarbeitungsleistung zu erhöhen, und es können Daten verarbeitet werden, die die Kapazität eines einzelnen Rechners übersteigen.
- Kosteneffizienz: Hadoop ist eine Open-Source-Software, d. h., sie kann kostenlos genutzt und verbreitet werden. Außerdem läuft es auf Standard-Hardware, die weniger teuer ist als proprietäre Hardware.
- Flexibilität: Das Framework kann eine Vielzahl von Datentypen verarbeiten, darunter strukturierte, unstrukturierte und halbstrukturierte Daten. Außerdem kann es mit einer Reihe von Tools und Technologien integriert werden, um eine individuelle Datenverarbeitungsumgebung zu schaffen.
- Fehlertoleranz: Hadoop ist fehlertolerant, d. h. es kann mit Hardware- oder Softwarefehlern umgehen, ohne dass Daten verloren gehen oder die Verarbeitung unterbrochen wird.
- Hohe Verfügbarkeit: Das Programm bietet hohe Verfügbarkeit durch sein verteiltes Dateisystem, das Daten über mehrere Knoten im Cluster repliziert. Dadurch wird sichergestellt, dass die Daten immer verfügbar sind, auch wenn ein oder mehrere Knoten ausfallen.
Außerdem sollten diese Nachteile beachtet werden.
- Komplexität: Das Programm ist ein komplexes System, für dessen Einsatz und Verwaltung spezielle Kenntnisse erforderlich sind. Es kann schwierig sein, es einzurichten und zu konfigurieren, und es kann erhebliche Investitionen in Hardware und Infrastruktur erfordern.
- Latenzzeit: Hadoop ist für die Stapelverarbeitung optimiert, was bedeutet, dass es sich möglicherweise nicht für Anwendungen eignet, die eine geringe Latenzzeit oder Echtzeitverarbeitung erfordern.
- Overhead: Das Framework führt aufgrund des verteilten Charakters des Systems zu zusätzlichem Overhead. Dies kann zu langsameren Verarbeitungszeiten und höherem Ressourcenverbrauch führen.
- Datenverwaltung: Hadoop enthält keine integrierten Tools für die Datenverwaltung, wie z. B. die Kontrolle der Datenqualität oder die Verfolgung der Datenabfolge. Diese müssen separat implementiert werden, was die Komplexität und die Kosten des Systems erhöhen kann.
Zusammenfassend lässt sich sagen, dass Hadoop ein leistungsstarkes Tool für die Verarbeitung und Analyse großer Datenmengen ist. Seine Skalierbarkeit, Kosteneffizienz, Flexibilität, Fehlertoleranz und hohe Verfügbarkeit machen es zu einer beliebten Wahl für die Verarbeitung großer Datenmengen. Allerdings gibt es auch einige Einschränkungen, darunter die Komplexität, die Latenzzeit, der Overhead und das Fehlen integrierter Datenverwaltungstools. Unternehmen, die den Einsatz von Hadoop in Erwägung ziehen, sollten diese Faktoren sorgfältig prüfen, um festzustellen, ob es die richtige Lösung für ihre Anforderungen ist.
Welche Anwendungen lassen sich mit Hadoop umsetzen?
Der Einsatz von Hadoop ist mittlerweile in sehr vielen Unternehmen verbreitet. Daruntern sind auch namhafte Vertreter, wie Adobe, Facebook, Google oder Twitter. Der Hauptgrund für die weite Verbreitung ist dabei vor allem die Möglichkeit große Datenmengen mithilfe von Clustern verarbeiten zu können. Diese können auch aus relativ leistungsschwachen Geräten bestehen.
Darüber hinaus lassen sich mithilfe der verschiedenen Komponenten auch spezialisierte Anwendungen bauen, die speziell auf den Use Case angepasst sind. In den meisten Fällen wird Apache Hadoop vor allem für die Speicherung von großen Datenmengen genutzt, die nicht unbedingt im Data Warehouse abliegen sollen.
Bei Facebook beispielsweise werden Kopien von internen Protokollen abgelegt, um diese zu einem späteren Zeitpunkt wieder verwenden zu können, beispielsweise zum Trainieren von Machine Learning Modellen. EBay hingegen nutzt den Apache MapReduce Algorithmus, um ihre Website Suche weiter optimieren zu können.
Unterschiede zwischen Hadoop und einer relationalen Datenbank
Hadoop unterscheidet sich in einigen grundlegenden Eigenschaften von einer vergleichbaren relationalen Datenbank.
| Eigenschaft | Relationale Datenbank | Apache Hadoop |
| Datentypen | ausschließlich strukturierte Daten | alle Datentypen (strukturiert, semi-strukturiert und unstrukturiert) |
| Datenmenge | wenig bis mittel (im Bereich von einigen GB) | große Datenmengen (im Bereich von Terrabyte oder Petabyte) |
| Abfragesprache | SQL | HQL (Hive Query Language) |
| Schema | Statisches Schema (Schema on Write) | Dynamisches Schema (Schema on Read) |
| Kosten | Lizenzkosten je nach Datenbank | Kostenlos |
| Datenobjekte | Relationale Tabellen | Key-Value Pair |
| Skalierungstyp | Vertikale Skalierung (Computer muss hardwaretechnisch besser werden) | Horizontale Skalierung (mehr Computer können dazugeschaltet werden, um Last abzufangen) |
Wie sieht die Zukunft von Hadoop aus?
Die Zukunft von Hadoop ist ein Thema, das in der Branche immer wieder diskutiert und erörtert wird. Hier sind einige Punkte zu beachten:
- Hadoop ist seit über einem Jahrzehnt eine beliebte Technologie für die Verarbeitung großer Datenmengen, aber seine Nutzung ist in den letzten Jahren aufgrund des Aufkommens von Cloud Computing und anderen verteilten Rechentechnologien zurückgegangen.
- Trotz dieses Rückgangs wird Hadoop immer noch von vielen Unternehmen verwendet und wird wahrscheinlich noch einige Zeit weiter verwendet werden.
- Hadoop ist eine Open-Source-Technologie mit einer großen Gemeinschaft von Entwicklern, was bedeutet, dass sie im Laufe der Zeit wahrscheinlich immer wieder aktualisiert und verbessert werden wird.
- Einige Experten sind der Meinung, dass Hadoop auch in Zukunft eine Rolle bei der Datenverarbeitung und -analyse spielen wird, aber eher in Verbindung mit anderen Technologien als als eigenständige Lösung eingesetzt werden wird.
- Da immer mehr Daten generiert und gesammelt werden, wird der Bedarf an skalierbaren und effizienten Datenverarbeitungstechnologien weiter steigen, wodurch sich für Hadoop und ähnliche Technologien in Zukunft neue Möglichkeiten ergeben könnten.
Das solltest Du mitnehmen
- Hadoop ist ein beliebtes Framework für die verteilte Speicherung und Verarbeitung großer Datenmengen.
- Zu seinen Vorteilen gehören Fehlertoleranz, Skalierbarkeit und niedrige Kosten im Vergleich zu herkömmlichen Datenspeicher- und -verarbeitungssystemen.
- Das Framework ermöglicht die parallele Verarbeitung großer Datensätze und kann eine Vielzahl von Datentypen und -formaten verarbeiten.
- Hadoop hat jedoch auch einige Nachteile wie Komplexität, hohe Hardwareanforderungen und eine steile Lernkurve.
- Hadoop wird in Branchen wie dem Finanzwesen, dem Gesundheitswesen und dem elektronischen Handel für Big Data-Analysen, maschinelles Lernen und andere datenintensive Anwendungen eingesetzt.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Hadoop
- Die Dokumentation von Hadoop liefert aufschlussreiche Anleitung zum Download und Einrichten des Systems.
- Die Unterschiedstabelle zwischen Hadoop und einer relationalen Datenbank ist in Anlehnung an die Kollegen von datasolut.com entstanden.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.