Ein Data Warehouse ist ein zentraler Datenspeicher in einem Unternehmen oder einer Organisation, der die relationalen Daten aus verschiedenen Quellen sammelt. Die Informationen werden aus verschiedenen Transaktionssystemen oder anderen relationalen Datenbanken ins Data Warehouse und stehen dort für Analysten und Entscheidungsträger zur Verfügung.
Welche Funktion erfüllt ein Data Warehouse?
Das Data Warehouse wird im geschäftlichen Umfeld in vielen Bereichen genutzt. Die Datenbank wird unternehmensweit genutzt, um datenbasierte Entscheidungen treffen zu können oder Prozesse untersuchen zu können. Da das zentrale Datenlager aus vielen verschiedenen Systemen Informationen bezieht, wird es als Single Point of Truth gesehen. Dadurch soll sichergestellt werden, dass alle im Unternehmen von denselben Daten sprechen und Entscheidungen auf diesen Informationen basieren.
Abteilungsübergreifend kann das Data Warehouse unter anderem für die folgenden Aufgaben genutzt werden:
- Kosten- und Ressourcenanalyse
- Analyse von unternehmensinternen Prozessen (bspw. Produktion, Einstellung, etc.)
- Business Intelligence
- Berechnung und Bereitstellung von unternehmensweiten Key Performance Indikatoren
- Datenquelle für Analysen oder Data Mining
- Vereinheitlichung der unternehmensweiten Daten in ein festes Schema
Welche Eigenschaften hat es?
Bei der Erstellung von zentralen Datenlagern kann man sich an bestimmten Eigenschaften orientieren, die helfen sollen den Aufbau und die nötigen Daten des Warehouses besser eingrenzen zu können.
Themenorientierung
Ein Data Warehouse enthält Informationen zu einem bestimmten Thema und nicht zu einzelnen Geschäftsvorgängen. Diese Themen können zum Beispiel Vertrieb, Einkauf oder Marketing sein.
Das Warehouse zielt darauf ab die Entscheidungsfindung mithilfe von Business Intelligence und gezielten KPIs zu unterstützen. Diese Interpretation wird auch dadurch unterstützt, dass Informationen, die nicht entscheidungsrelevant sind oder für eine Analyse genutzt werden, erst gar nicht in dieser zentralen Datenbank landen.
Integration
Das Warehouse integriert Daten aus verschiedensten System und Quellen. Deshalb muss ein gemeinsames Schema für die Informationen erstellt werden, sodass sie einheitlich und vergleichbar sind. Ansonsten ist eine zentrale Analyse und Kennzahlenerstellung nicht möglich.
Zeitraumbezug
Das Data Warehouse speichert Daten aus einem bestimmten Zeitraum und ist dadurch vergangenheitsbezogen. Des Weiteren werden die Daten meist aggregiert beispielsweise auf Tagesebene übermittelt, damit die Datenmenge begrenzt bleibt. Somit ist die Granularität möglicherweise nicht fein genug, wie man das aus den operativen Systemen gewohnt ist.
Die operativen Systeme hingegen sind zeitpunktbezogen, da sie die gegenwärtig anfallenden Informationen ausgeben. Gleichzeitig können die Informationen sehr detailliert betrachtet werden.
Nicht-Volatilität
Ein weiteres wichtiges Merkmal von zentralen Datenlagern ist die Nicht-Flüchtigkeit der Daten. In operativen Systemen werden die Informationen meist nur für eine kurze Zeitspanne zwischengespeichert und sobald neue Daten anfallen, werde alte überschrieben. In einem Data Warehouse hingegen werden Daten dauerhaft gespeichert und alte Daten bleiben bestehen, auch wenn neuere Daten hinzugefügt werden.
Was sind die Vorteile eines Data Warehouses?
Durch die Einrichtung eines zentralen Datenspeichers können mehr Leute einfacher auf Informationen zugreifen und diese im Entscheidungsfindungsprozess nutzen. Dadurch werden rationalere Entscheidungen getroffen, die nicht nur von der Meinung einzelner abhängen.
Des Weiteren bietet sich die Möglichkeit, Informationen aus verschiedenen Quellen zusammenzuführen und dadurch neue Betrachtungsweisen zu erstellen. Davor war dies durch die physische Trennung der Systeme nicht möglich. Für ein Unternehmen kann es möglicherweise interessant sein, Daten aus dem Webtrackingtool, wie beispielsweise Google Analytics, und Umsatzdaten aus dem Vertriebstool, wie beispielsweise Microsoft Navision, zusammenzuführen und gemeinsam auszuwerten. Dadurch lässt sich die Performance des E-Commerce Shops bewerten und die User-Journey zusammen mit dem tatsächlichen Einkauf betrachten.
Die Datenqualität lässt sich durch die zentrale Speicherung einfacher gewährleisten, da lediglich ein System und die darin enthaltenen Daten bewertet werden müssen. Zersplitterte Datenquellen, die in der Organisation verteilt sind, lassen sich hingegen nur sehr schwierig im Auge behalten. Dasselbe gilt auch für die Zugriffskontrolle von einzelnen Personen. Wenn die Daten im Unternehmen verteilt sind und möglicherweise nicht mal in Datenbanken abgelegt wurden, lässt sich kaum nachvollziehen, wer Zugriff auf Daten hat, die er normalerweise nicht sehen sollte.
Welche Komponenten gehören noch zum Data Warehouse?
Neben dem Data Warehouse selbst, müssen noch andere Systeme und Komponenten in einer Architektur ergänzt werden, um die zentrale Datenspeicherung zu ermöglichen. Dazu zählen:
- ETL-Tool: Um die Abfrage und Konsolidierung aus verschiedenen Datenquellen zu gewährleisten, wird ein Werkzeug benötigt, das in regelmäßigen Abständen die Quellen anfragt, die Daten konsolidiert, also in ein einheitliches Schema bringt und sie schlussendlich im Data Warehouse speichert.
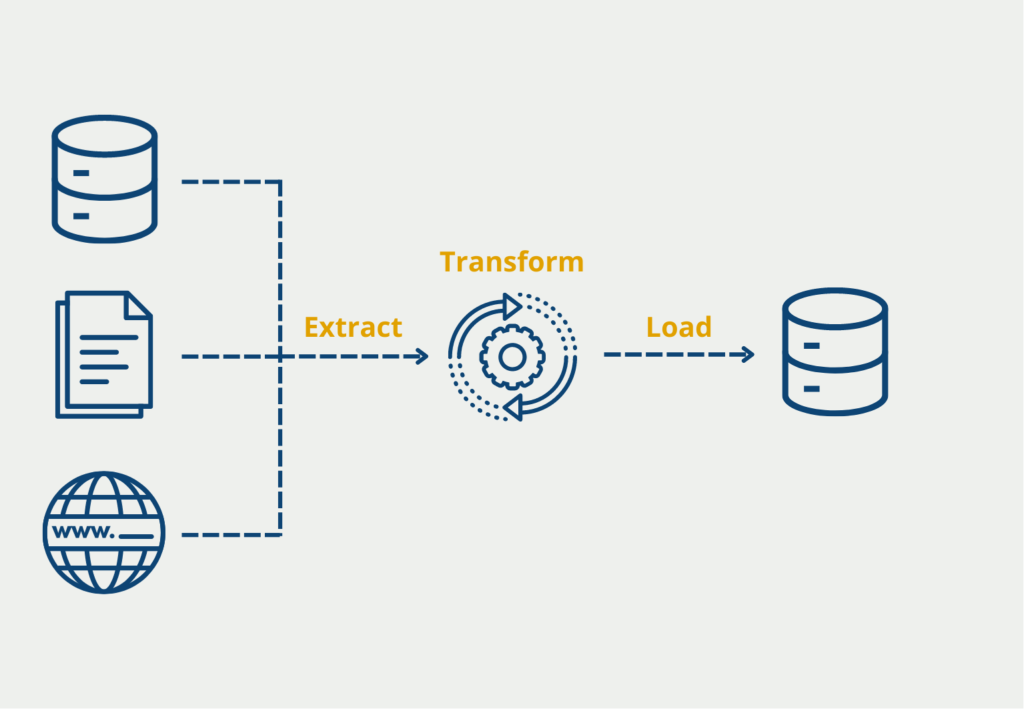
- Metadaten-Speicherung: Neben den tatsächlichen Daten fallen auch sogenannte Metadaten an, die abgelegt werden müssen. Dazu zählen beispielsweise die Nutzerrechte, die definiert welche Änderungen eine Person vornehmen darf, beziehungsweise welche Tabellen eingesehen werden dürfen. Zusätzlich wird darin auch die Daten- und Tabellenstruktur festgehalten, also in welchem Zusammenhang die Tabellen zueinander stehen.
- Weiterführende Tools: Das Vorhandensein der Daten im Data Warehouse allein hilft erstmal noch nicht wirklich weiter. Zusätzlich dazu müssen auch andere Werkzeuge eingebaut sein, die die Informationen daraus verwenden und weiterverarbeiten. Häufig wird beispielsweise noch ein passenden Visualisierungstool, wie Microsoft Power BI, aufgesetzt, damit Datenauswertungen erstellt und Aggregationen durchgeführt werden können. Diese sorgen erst dafür, dass aus den Daten wirklich Wissen generiert werden kann.
Was sind die Unterschiede zum Data Lake?
Das Data Warehouse kann zusätzlich durch einen Data Lake ergänzt werden, in welchem unstrukturierte Rohdaten kostengünstig zwischengespeichert werden können, um sie zu einem späteren Zeitpunkt nutzen zu können. Die beiden Konzepte unterscheiden sich vor allem in den Daten, die sie speichern, und der Art und Weise, wie die Informationen abgelegt werden.
| Merkmale | Data Warehouse | Data Lake |
|---|---|---|
| Daten | Relationale Daten aus produktiven Systemen oder anderen Datenbanken. | Alle Datentypen (strukturiert, semi-strukturiert, unstrukturiert). |
| Datenschema | Können entweder vor der Erstellung des Data Warehouses geplant werden oder erst während der Analyse (Schema-on-Write oder Schema-on-Read) | Ausschließlich zum Analysezeitpunkt (Schema-on-Read) |
| Abfrage | Mit lokalem Speicher sehr schnelle Abfrageergebnisse | – Entkopplung von Berechnungen und Speicher – Schnelle Abfrageergebnisse mit günstigem Speicher |
| Datenqualität | – Vorverarbeitete Daten aus verschiedenen Quellen – Vereinheitlichung – Single Point of Truth | – Rohdaten – Bearbeitet und unbearbeitet |
| Anwendungen | Business Intelligence und grafische Aufbereitung der Daten | Künstliche Intelligenz, Analysen, Business Intelligence, Big Data |
Welche Punkte sollten bei der Einführung eines Data Warehouses beachtet werden?
Die Implementierung eines Data Warehouse ist ein komplexer Prozess, der sorgfältige Planung, Liebe zum Detail und ein tiefes Verständnis für die Datenanforderungen des Unternehmens erfordert. Im Folgenden finden Sie einige wichtige Überlegungen zur Implementierung eines Data Warehouse:
- Definiere den Umfang des Projekts: Lege den Umfang des Data-Warehouse-Projekts klar fest und bestimme die Datenquellen, die verwendet werden sollen. Auf diese Weise kannst Du die Hardware- und Softwareanforderungen für das Projekt bestimmen.
- Entwerfe das Data Warehouse: Entwerfe das Schema, d. h. erstelle ein Stern- oder Schneeflockenschema. Dazu müssen die Faktentabellen, die Dimensionstabellen und die Beziehungen zwischen ihnen festgelegt werden.
- Auswahl eines ETL-Tools: Wähle ein Extraktions-, Transformations- und Ladetool (ETL), das Daten aus den Quellsystemen extrahieren, die Daten so transformieren kann, dass sie in das Data-Warehouse-Schema passen, und die Daten in die Datenbank laden kann.
- Implementiere den ETL-Prozess: Implementiere den ETL-Prozess, indem Du das ETL-Tool konfigurierst und die ETL-Workflows definierst. Dies beinhaltet die Einrichtung der Quell-zu-Ziel-Mappings, Transformationen und Datenqualitätsprüfungen.
- Laden der Daten: Lade die Daten mithilfe des ETL-Tools in das Warehouse. Dabei können die Daten inkrementell oder in Stapeln geladen werden.
- Testing: Teste das Data Warehouse, um sicherzustellen, dass es wie erwartet funktioniert. Dazu werden Abfragen ausgeführt und die Ergebnisse mit den Quelldaten verglichen.
- Abstimmung: Optimiere die Leistung des Data Warehouse, indem Du die Hardware- und Softwarekomponenten abstimmst. Dies kann bedeuten, dass mehr Arbeitsspeicher oder Festplattenplatz hinzugefügt oder die Datenbankindizes optimiert werden.
- Benutzer schulen: Schulung der Benutzer im Umgang mit dem Data Warehouse und den Business Intelligence-Tools, die für den Zugriff auf das Data Warehouse verwendet werden.
- Pflege das Data Warehouse: Pflege das Data Warehouse, indem Du seine Leistung überwachst, auftretende Probleme behebst und das Schema des Data Warehouse bei Bedarf aktualisierst.
Insgesamt erfordert die Implementierung eines Data Warehouse eine sorgfältige Planung, Liebe zum Detail und ein tiefes Verständnis für die Datenanforderungen des Unternehmens. Durch die Befolgung von Best Practices und die Konzentration auf die Datenqualität können Unternehmen ein leistungsfähiges Data Warehouse erstellen, das die datengesteuerte Entscheidungsfindung unterstützt.
Das solltest Du mitnehmen
- Ein zentrales Datenlager speichert unternehmensweite Informationen zentral ab.
- Damit sollen datenbasierte Entscheidungen unterstützt werden und Business Intelligence möglich gemacht werden.
- Die unstrukturierten Rohdaten im Data Lake bieten eine gute Ergänzung zu den relationalen und aufbereiteten Daten im Data Warehouse.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!

Was ist die Bivariate Analyse?
Nutzen Sie die Bivariate Analyse: Erforschen Sie Typen und Streudiagramme und nutzen Sie Korrelation und Regression.
Andere Beiträge zum Thema Data Warehouse
- Eine gute Zusammenfassung bietet Amazon Web Services hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.