Apache Spark ist ein verteiltes Analytics-Framework, welches für viele verschiedene Big Data Anwendungen genutzt werden kann. Dabei setzt es auf In-Memory Datenspeicherung und eine parallele Ausführung von Prozessen, um eine hohe Performance zu gewährleisten. Es ist einer der umfangreichsten Big Data Systeme am Markt und bietet unter anderem Batchverarbeitung, Graphdatenbanken oder Unterstützung für Künstliche Intelligenz.
Was ist Apache Spark?
Das Framework wurde ursprünglich im Jahr 2009 an der University Berkeley entwickelt und kann seitdem Open-Source verwendet werden. Auch deshalb wird es bereits von vielen, großen Unternehmen wie Netflix, Yahoo oder EBay eingesetzt.
Die große Nutzung liegt auch darin begründet, dass Apache Spark ein sehr breit gefächertes Framework für nahezu alle Big Data Anwendungen ist. Dadurch wird sie von Anwendern für Machine Learning Modelle genutzt, zur Erstellung von Graphdatenbanken oder zur Verarbeitung von Streaming-Daten.
Eine grundlegende Eigenschaft von Spark ist die verteilte Architektur, also die Nutzung von Computerclustern, um Lastspitzen umverteilen zu können. Dadurch lassen sich auch große Datenmengen sehr performant und kostengünstig verarbeiten.
Welche Komponenten bietet Spark?
Spark bietet Komponenten für die verschiedensten Data Science Anwendungen. SparkCore ist das Gehirn des Spark Universums. Hier werden die Aufgaben gesteuert und verteilt, sowie grundlegende Funktionalitäten bereitgestellt.
Die Machine Learning Library (MLlib) stellt grundlegende Modelle zur Arbeit mit Künstlicher Intelligenz bereit. Dazu zählen die gängigsten Algorithmen in diesem Bereich wie Random Forest oder K-Means Clustering.
Graphen sind eine moderne Art der Datenspeicherung aus dem Bereich der NoSQL Datenbanken. Damit können beispielsweise soziale Netzwerke gespeichert oder Wissensstrukturen dargestellt werden. Die Erstellung und Verarbeitung solcher Graphen in Spark wird durch GraphX ermöglicht.
Die Datenspeicherung in Apache Spark erfolgt durch die sogenannten RDDs, welche an sich erstmal keine Struktur haben. Jedoch kann man diese in sogenannte Spark DataFrames umwandeln, die sehr ähnlich zu Pandas DataFrames sind. Mithilfe von SparkSQL lassen sich klassische SQL Abfragen auf DataFrames absetzen, sodass ein strukturierter Zugriff auf die Daten möglich ist.
In vielen Anwendungen ist eine Echtzeitdatenverarbeitung gefordert. Dazu werden sogenannte Streams aufgesetzt, in denen die Daten in unregelmäßigen Abständen geschrieben werden. Mithilfe von SparkStreaming lassen sich diese Datenströme verarbeiten, indem sie zu kleineren Datenpaketen zusammengefasst werden.

Was sind Resilient Distributed Datasets?
Die grundlegende Datenstruktur von Apache Spark sind die Resilient Distributed Datasets (RDD) und aufgrund ihrer Struktur ist die Datenverarbeitung in Spark auch so viel schneller als in Hadoop. In Kurzform handelt es sich dabei um eine Sammlung von Datenpartionen auf die man nur einen lesenden Zugriff hat. Diese Partitionen können ohne weiteres auf die verschiedenen Computer des Clusters verteilt werden. Alle Komponenten in Apache Spark sind im Endeffekt darauf ausgerichtet, RDD Dateien zu verarbeiten und weiterzuleiten.
Zu den Charakteristiken zählt auch dass die Dateien nach der Erstellung nicht mehr verändert werden können. Das ist nur möglich, indem eine neue RDD Datei erstellt wird und die veränderten Daten dort hineingeschrieben werden. Die Dateien werden außerdem im Arbeitsspeicher vorgehalten und sind dadurch mit einer der Hauptgründe für die performante Arbeitsweise von Spark. Jedoch können RDD Dateien, wenn gewünscht, auch normal auf der Festplatte gespeichert werden.
Wie programmiert man mit Apache Spark?
Die Programmierung mit Apache Spark umfasst die Verwendung verschiedener Programmierschnittstellen zum Lesen, Umwandeln und Analysieren großer Datensätze. Spark bietet mehrere APIs, einschließlich Scala, Java, Python und R, um mit den Kernfunktionen von Spark zu interagieren.
Hier sind einige wichtige Aspekte der Programmierung mit Apache Spark:
- DataFrames und Datensätze: Die DataFrames- und Datasets-APIs von Spark bieten eine High-Level-Abstraktion für die Arbeit mit strukturierten und halbstrukturierten Daten. Sie bieten eine ähnliche Programmierschnittstelle wie SQL und ermöglichen eine einfache Manipulation und Transformation von Daten.
- RDDs: Resilient Distributed Datasets (RDDs) sind die grundlegenden Bausteine von Spark. RDDs sind eine unveränderliche verteilte Sammlung von Objekten, die parallel verarbeitet werden können. Sie ermöglichen effizientes verteiltes Rechnen, erfordern jedoch mehr Low-Level-Programmierung als DataFrames und Datasets.
- Transformationen und Aktionen: Die APIs von Spark bieten zwei Arten von Operationen: Transformationen und Aktionen. Transformationen sind Operationen, die ein neues RDD erstellen, während Aktionen Operationen sind, die ein Ergebnis an das Treiberprogramm zurückgeben oder Daten in den Speicher schreiben.
- Spark SQL: Spark SQL ist ein Spark-Modul für die strukturierte Datenverarbeitung. Es bietet eine Programmierschnittstelle für die Arbeit mit strukturierten Daten mithilfe von SQL-Abfragen und DataFrames.
- Maschinelles Lernen: Die MLlib-Bibliothek von Spark bietet eine Reihe von Algorithmen für maschinelles Lernen für Clustering, Klassifizierung, Regression und kollaborative Filterung. Sie bietet eine High-Level-API zum Erstellen und Trainieren von Modellen für maschinelles Lernen.
Die Programmierung mit Apache Spark kann eine Herausforderung sein, da sie ein Verständnis für verteiltes Rechnen und Parallelverarbeitung erfordert. Die APIs von Spark bieten jedoch leistungsstarke Abstraktionen für die Arbeit mit großen Datensätzen und ermöglichen es Entwicklern, effiziente, skalierbare und fehlertolerante Anwendungen zu schreiben.
Welche Vorteile bietet der Einsatz von Spark?
Die Vorteile von Spark lassen sich in drei großen Themenblöcken zusammenfassen:
- Performance: Durch die verteilte Architektur ist Spark sehr gut skalierbar und bietet ein herausragende Performance bei der Verarbeitung von großen Datenmengen. Dadurch dass viele Berechnungen In-Memory, also im Arbeitsspeicher, stattfinden, werden die Prozesse nochmals deutlich beschleunigt. In einem Test hat sich sogar herausgestellt, dass Apache Spark in bestimmten Berechnungen 100mal schneller ist als Hadoop.
- Benutzerfreundlichkeit: Auch für Neueinsteiger ist Apache Spark sehr einfach zu bedienen, beispielsweise indem auf bereits bekannte Strukturen, wie der DataFrame, zurückgegriffen wird. Darüber hinaus sind viele der Anwendungen über APIs aufrufbar.
- Einheitlichkeit: Die breite Palette an Anwendungen, welche sich mit Apache Spark umsetzen lassen, ermöglichen es verschiedene Stufen der Datenverarbeitung in einem einzigen Tool vorzunehmen. Dadurch ist die Kompatibilität der verschiedenen Schritte sichergestellt und es müssen nicht unterschiedliche Lizenzen oder Zugänge zu Programmen verwaltet werden.
Welche Anwendungen nutzen Apache Spark?
Aufgrund der vielen Funktionalitäten und Komponenten, die Spark bereits mitbringt, hat sich das Tool zum Quasi-Standard für die meisten Big-Data Anwendungen entwickelt. Dazu zählen alle Use Cases in denen große Datenmengen performant verarbeitet werden sollen. Konkret sind vor allem die folgenden Anwendungen interessant:
- Zusammenführung von verschiedenen Datenquellen und Vereinheitlichung der Informationen, bspw. im ETL-Kontext
- Analyse von großen Datensätzen durch die Möglichkeit der strukturierten SQL Abfrage und der Daten, die In-Memory abliegen
- Aufbau von grundlegenden Machine Learning Modellen, die von Spark bereits unterstützt werden
- Einführung und Verarbeitung Echtzeitdatenströmen mithilfe von SparkStreaming
Wie unterscheidet sich Spark von Hadoop?
Apache Spark wird in den meisten Quellen als Verbesserung von Hadoop angesehen, da es große Datenmengen deutlich schneller verarbeiten kann. Der große Vorteil bei der Einführung von Hadoop war die Nutzung des MapReduce Algorithmus. Dieser spaltet aufwändige Berechnung in eine Map- und eine Reduce-Phase und beschleunigt dadurch den Ablauf des Prozesses. Jedoch greift er dabei auf Dateien zurück, die auf der Festplatte abliegen. An diesem Punkt zieht Spark seinen großen Performance-Vorteil, da die Daten meistens In-Memory gespeichert sind. Unter anderem deswegen ist Spark auch bis zu 100mal schneller als Hadoop abhängig von der Applikation.
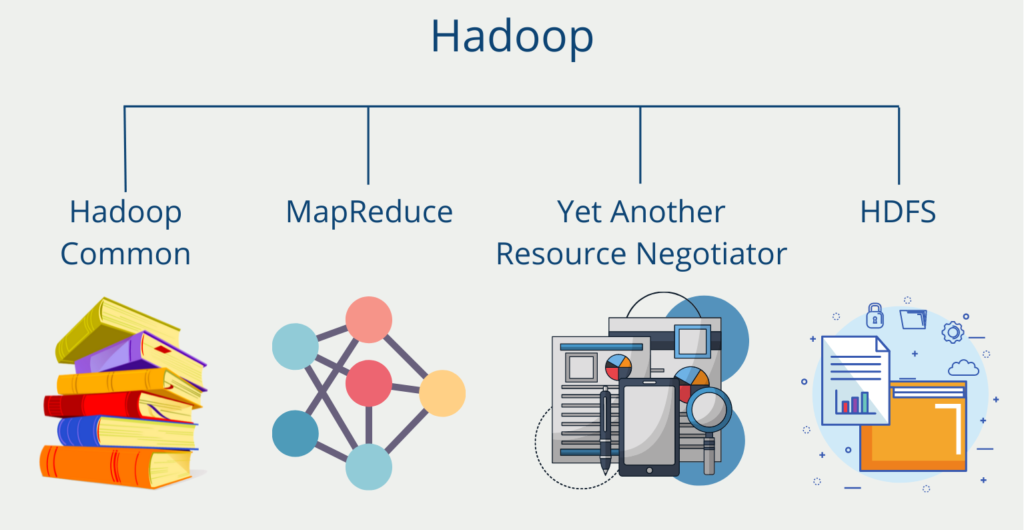
Neben diesem Hauptunterschied gibt es noch andere grundsätzliche Unterschiede zwischen Hadoop und Spark:
- Leistung: Wie bereits gesagt, arbeitet Apache Spark hauptsächlich aus dem Arbeitsspeicher heraus, während Hadoop die Daten auf der Festplatte ablegt und diese batchweise verarbeitet.
- Kosten: Der Leistungsvorteil von Spark schlägt natürlich mit höheren Kosten zu Buche. Der Arbeitsspeicher ist im Vergleich zu Hauptspeicher (SSD oder HDD) deutlich teurer.
- Datenverarbeitung: Beide Systeme basieren auf einer verteilten Architektur. Hadoop ist jedoch optimiert zur Batchverarbeitung und zum einmaligen Verarbeiten von großen Datenmengen. Spark hingegen ist besser geeignet, um Datenströme zu verarbeiten durch die Komponente SparkStreaming.
- Machine Learning: Apache Spark bietet durch die Machine Learning Library eine einfache Möglichkeit, um bewährte Machine Learning Modelle schnell und einfach zu nutzen.
Diese Punkte stammen zum großen Teil von IBM’s ausführlichem Vergleich zwischen Spark und Hadoop. Dort findet man noch weitere Details zu den Unterschieden zwischen Hadoop und Spark.
Was sind die Unterschiede zwischen Presto und Spark?
Apache Presto ist eine Open-Source verteilte SQL-Engine, die sich zur Abfrage von großen Datenmengen eignet. Sie wurde 2012 von Facebook entwickelt und anschließend unter der Apache-Lizenz Open-Source zur Verfügung gestellt. Die Engine bietet kein eigenes Datenbanksystem und wird deshalb oft mit bekannten Datenbanklösungen, wie Apache Hadoop oder MongoDB genutzt.
Es wird oft im Zusammenhang mit Apache Spark genannt bzw. sogar als Konkurrenz dazu verstanden. Jedoch sind die beiden Systeme sehr verschieden und teilen sich nur wenige Gemeinsamkeiten. Beide Programme sind Open-Source verfügbare Systeme bei der Arbeit mit Big Data. Sie können beide eine gute Performance bieten, durch ihre verteilte Architektur und die Möglichkeit der Skalierung. Dementsprechend können sie auch sowohl On-Premise als auch in der Cloud betrieben werden.
Neben diesen (wenn auch eher wenigen) Gemeinsamkeiten unterscheiden sich Apache Spark und Apache Presto jedoch in einigen grundsätzlichen Eigenschaften:
- Der Spark Core unterstützt erstmal keine SQL-Abfragen, dazu benötigt man die zusätzliche Komponente SparkSQL. Bei Presto hingegen handelt es sich um eine reise SQL Query-Engine.
- Spark bietet eine sehr breite Palette an Anwendungsmöglichkeiten, beispielsweise auch durch die Möglichkeit ganze Machine Learning Modelle aufzubauen und zu deployen.
- Apache Presto hingegen hat sich vor allem auf die schnelle Verarbeitung von Datenabfragen bei großen Datenmengen spezialisiert.
Das solltest Du mitnehmen
- Apache Spark ist ein verteiltes Big Data Framework, welches für unterschiedlichste Anwendungsfälle genutzt werden kann.
- Spark besteht aus verschiedenen Komponenten. Dazu zählen unter anderem GraphX mit der Graphen erstellt und verarbeitet werden können und die Machine Learning Library, die verbreitete ML-Algorithmen zur Nutzung bereitstellt.
- Zu den Vorteilen zählen unter anderem die performante Verarbeitung von großen Datenmengen, die Benutzerfreundlichkeit und die Einheitlichkeit der Lösung durch die verschiedenen Komponenten.
- In der Praxis wird Spark vor allem zur Datenverarbeitung im Big Data Bereich genutzt und zum Auslesen von Echtzeitdatenströmen.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Apache Spark

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.