Batch Processing is a term from the field of data processing and describes processes that are always executed directly for a group of data instead of for each data record individually. This can save resources since the processing does not have to be started individually each time and thus the computer can be inactive in the meantime.
What is Batch Processing?
In batch processing, data is always processed only when a certain amount has accumulated. The trigger for starting the process can either be a specific time, such as once a day or regulated by the amount of data, such as when 100 records have accumulated.
An everyday example of batch processing is credit card billing. Here, all payments made with the credit card are processed and billed to the customer only once a month instead of processing each payment individually. This means that resources are only needed for processing once a month, instead of around the clock as soon as a payment happens.
Other everyday examples of batch processing of data include:
- Employee Payroll: Company employees receive a payroll once or twice a month instead of being charged for working time on a daily or hourly basis.
- Mail Order: In the mail order business, if possible, all products in an order are shipped in a single package and collected through one invoice. It would be much more cumbersome to bill and ship products individually. However, it can happen that products that would actually already be in stock have to wait until all products of the order are in stock.
What are the advantages and disadvantages of processing in batches?
One of the advantages of batch processing systems is the high level of plannability and the associated efficiency, as it is possible to plan exactly when the batches are to be processed and during which period increased computer resources are then required. In the remaining time, the computing power can be used for other projects.
In addition, little maintenance work is required, as the pipeline only needs to be set up once and, if no errors occur, continues to run undisturbed. By avoiding manual work and automating the process, data quality is also increased as there can be no unwanted changes to the data. This increased data quality also leads to better results when using Machine Learning.
One disadvantage of batch processing is the timeliness of the data. If a data job runs only once a day, real-time data cannot be provided. However, these are demanded in many applications nowadays. It must therefore be decided, depending on the use case, how important data timeliness is.
In addition, the introduction of batch processing involves a certain amount of know-how, which must either be purchased or acquired through employee training. Here, too, a cost-benefit analysis must be carried out to find out whether the introduction of batch processing is financially worthwhile.
Why do companies use Batch Processing?
In reality, there are some data jobs that don’t claim to be real-time but should still be automated. For this, many companies use batch processing to save costs. These processes can include, for example:
- The monthly accounting of salaries.
- The loading of productive databases into the data warehouse is sufficient even once a day.
- The tracking of outstanding deliveries can also take place via batch processing if the delivery dates are not updated frequently.
What can batch processing architectures look like?
Batch processing architectures refer to the underlying frameworks and systems used to design, implement, and manage batch processing workflows. There are several architectures, each with their own advantages and limitations. The most common ones include:
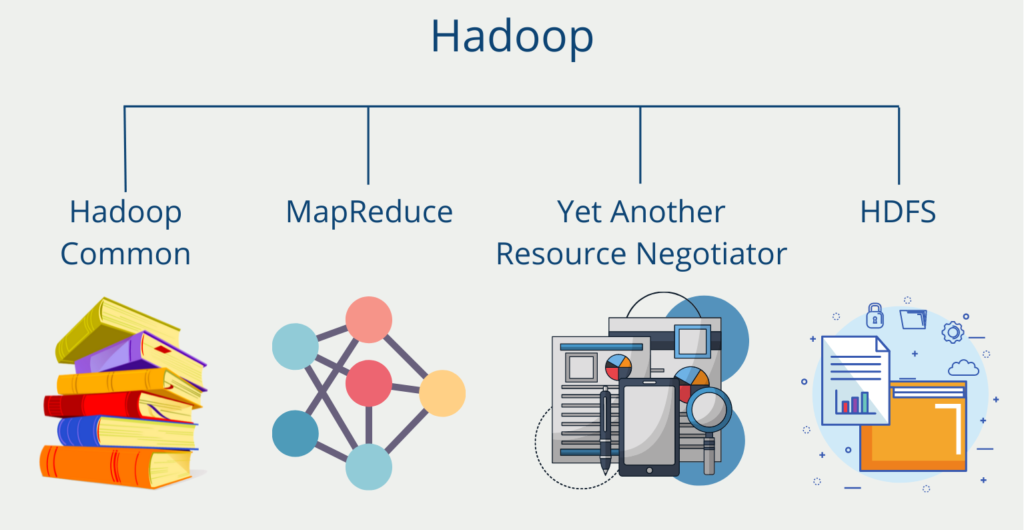
- Hadoop: Hadoop is an open source framework designed for processing large amounts of data in distributed computing clusters. Hadoop uses the Hadoop Distributed File System (HDFS) to store and distribute data across multiple nodes in a cluster. Hadoop also incorporates the MapReduce programming model for the parallel processing of data across the cluster.
- Apache Spark: Apache Spark is a fast and general-purpose cluster computing system designed for big data processing. Spark includes a batch processing engine that can be used to process large amounts of data in parallel. Spark also offers a number of other features, including real-time stream processing, SQL queries, and machine learning.
- Apache Flink: Apache Flink is an open source stream processing framework that also provides support for batch processing. Flink is designed for high-performance data processing and supports both batch and stream processing applications.
- Apache Beam: Apache Beam is an open source unified programming model that can be used for both batch and stream processing. Beam provides a set of APIs that can be used to write data processing pipelines that can run on a variety of batch and stream processing engines.
- Apache Airflow: Apache Airflow is an open source platform for designing, scheduling, and monitoring data processing workflows. Airflow provides a number of features for managing workflows, including support for task dependencies, error handling, and parallel execution.
Overall, the choice of batch processing architecture depends on the specific requirements of the use case, as well as factors such as scalability, performance, and ease of use.
What are the alternatives?
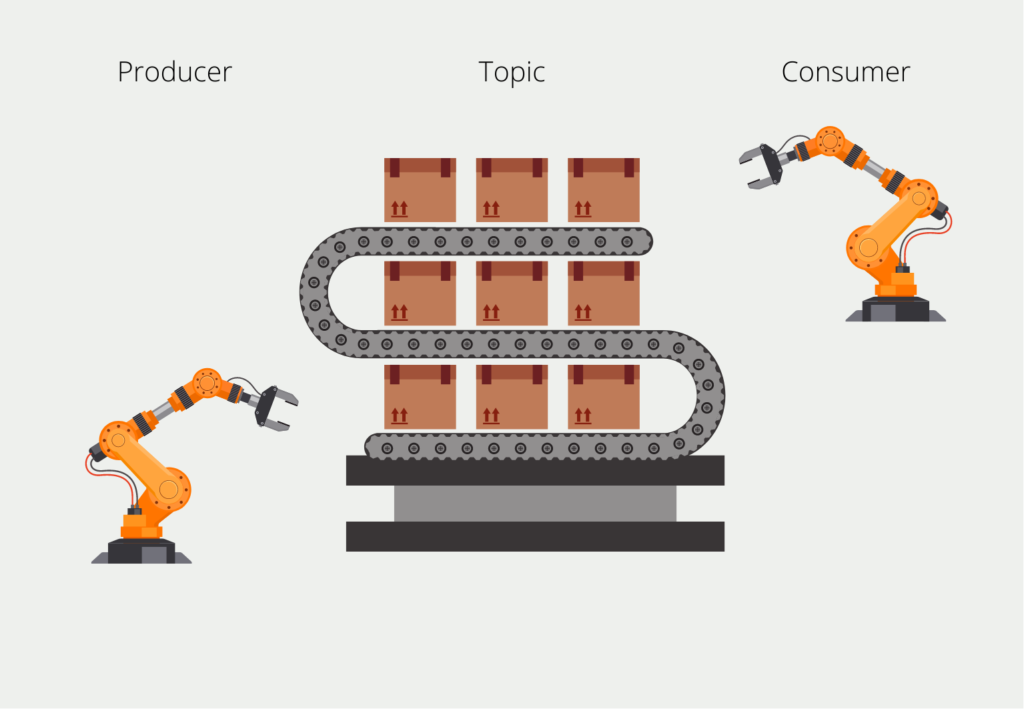
The alternative to batch processing is so-called stream processing, in which data is processed as soon as it arrives. This allows data to be evaluated and forwarded in real-time. The information arrives as a so-called data stream, for example in Apache Kafka, and is processed directly when it arrives.
This type is particularly suitable when high data timeliness must be ensured and the required computer resources play a subordinate role. In addition, it also makes more sense to process data in streams if the application has to handle particularly large amounts of data. In this case, batch processing is usually not possible due to the high, punctual loads or is significantly more cost-intensive.
What is the difference between stream processing and batch processing?
Deciding on architecture for data processing is relatively difficult and depends on the individual case. At the same time, it may also be the case that real-time data processing is not yet required today, but that this will change again in the near future. It is therefore important to find out what time horizon is required for the application in question.
Batch processing is suitable for processing large volumes of data, which usually occur at regular intervals. In these cases, batch processing offers high efficiency and automation of the process at a comparatively low cost.
If the focus is on real-time processing of the data, streamwise processing should be used. This is also a good idea if new data sets are continuously being generated, as is the case with sensor data, for example. However, the implementation and maintenance effort is significantly higher, since the system must be continuously accessible, and thus computer resources are blocked all the time.
What are the limitations of batch processing?
Despite its advantages, batch processing has some limitations that must be considered:
- Latency: One of the biggest limitations of batch processing is latency. Since batch processing is not real-time, there is often a delay between data acquisition and processing. This delay can prove to be a disadvantage when dealing with time-sensitive data, such as financial transactions or real-time monitoring.
- Inflexibility: Batch processing is inflexible in the sense that it can be difficult to make changes to a process once it has been set up. Any changes made can affect the entire batch, which can be problematic if the data is time-sensitive or has already been processed.
- Complexity: Data processing can be very complex, especially when dealing with large amounts of data or complex transformations. This complexity can make batch processing systems difficult to maintain and troubleshoot.
- Resource intensive: Batch processing can be resource intensive, both in terms of hardware and software requirements. Processing large amounts of data requires powerful hardware and software that can be expensive to purchase and maintain.
- Data quality issues: Batch processing can also lead to data quality issues if the data is flawed or the processing steps are not well thought out. These data quality issues can be difficult to detect and correct, which can affect the accuracy and reliability of the results.
In summary, while batch processing is a valuable tool for processing large amounts of data, it has some limitations that must be considered. Careful planning and design can help mitigate some of these limitations and ensure that processing is used effectively.
This is what you should take with you
- Batch Processing is a term from the field of data processing and describes processes that are always executed directly for a group of data instead of for each data record individually.
- It is particularly useful when data is generated irregularly and in large volumes.
- If, on the other hand, the information must be processed in real-time, one should resort to so-called stream processing.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.

What is the Bivariate Analysis?
Unlock insights with bivariate analysis. Explore types, scatterplots, correlation, and regression. Enhance your data analysis skills.
Other Articles on the Topic of Batch Processing
- You can find instructions for batch processing in Microsoft Azure here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.