In the realm of statistics and regression modeling, precision and reliability are paramount. Imagine having a tool that can uncover hidden issues within your models, enhancing the trustworthiness of your insights. This tool is known as the Variance Inflation Factor, or VIF for short. In our journey through this article, we will explore the significance of this measure in detecting multicollinearity, a common but often overlooked problem in regression analysis. Join us as we delve into the world of VIF, decipher its workings, and understand how it can elevate the quality of your data-driven decisions.
What is Multicollinearity?
In the world of regression analysis, one of the key assumptions is that predictor variables (also known as independent variables) should be independent of each other. This means that changes in one predictor should not significantly impact changes in another. However, multicollinearity challenges this assumption.
Multicollinearity refers to a situation where two or more predictor variables in a regression model are highly correlated. In simpler terms, it’s when you have two or more features that are so intertwined that it becomes challenging to disentangle their individual effects on the dependent variable.
Imagine you’re trying to predict house prices, and you include both the number of bedrooms and the total square footage of a house as predictor variables. It’s likely that these two features will be correlated because larger houses tend to have more bedrooms. When multicollinearity is present, it becomes difficult to discern the specific impact of each feature on the outcome, potentially leading to unreliable and unstable regression results.
Multicollinearity isn’t limited to just two variables; it can involve multiple predictors in a model. This phenomenon can obscure the true relationships between predictors and the response variable, making it challenging to draw meaningful conclusions and undermining the interpretability of the regression model.
In essence, understanding multicollinearity is crucial in regression analysis because it can introduce ambiguity and uncertainty into your model’s predictions. Identifying and addressing multicollinearity is essential to ensure the reliability and accuracy of your regression results.
What is the Variance Inflation Factor?
The Variance Inflation Factor is a statistical measure used to assess the severity of multicollinearity in a regression analysis. It quantifies how much the variance of an estimated regression coefficient increases when your predictors are correlated. In essence, it helps you determine how much the standard errors of the regression coefficients are inflated due to multicollinearity.
Here’s how it works:
When you have a multiple linear regression model with several predictor variables, each coefficient estimate is calculated while controlling for the influence of the other predictors. If these predictors are correlated, the coefficient estimates become unstable, leading to larger standard errors. The VIF measures the extent of this instability.
Mathematically, the VIF for a particular predictor variable is calculated as the ratio of the variance of the coefficient estimate when including all predictors to the variance of the coefficient estimate when that particular predictor is excluded from the model. The formula is as follows:
\(\) \[VIF = \frac{1}{(1 – R^2)} \]
Where:
- R² is the coefficient of determination of the predictor variable in a regression model that uses all other predictor variables as predictors.
The VIF value provides valuable insights:
- If the VIF is equal to 1, it indicates no multicollinearity; the predictor is not correlated with any other predictor variables.
- If the value is greater than 1 but less than 5, it suggests moderate multicollinearity, which may not be a major concern.
- If the VIF exceeds 5 or 10, it indicates high multicollinearity, signifying that the predictor variable is strongly correlated with others in the model. High VIF values can lead to unstable coefficient estimates and unreliable p-values, making it challenging to draw meaningful conclusions from the regression analysis.
Analysts typically use VIF values to identify which predictor variables are contributing the most to multicollinearity. By removing or addressing these variables or taking other corrective actions like feature selection, the impact of multicollinearity can be mitigated, resulting in more stable and reliable regression models.
How can you interpret the VIF values?
The Variance Inflation Factor is a crucial tool for assessing multicollinearity in regression models. VIF values provide insights into the degree to which predictor variables are correlated with each other. Understanding how to interpret VIF values is essential for making informed decisions about whether and how to address multicollinearity.
Here’s how to interpret VIF values:
- VIF = 1: A value of 1 indicates no multicollinearity. In this case, the predictor variable is not correlated with any other predictors in the model. This scenario is ideal because it means that each predictor provides unique information about the dependent variable.
- VIF < 5: Values below 5 generally suggest that there is low to moderate multicollinearity among the predictor variables. While some correlation exists, it is typically not problematic for regression analysis. You can proceed with the model without major concerns.
- VIF ≥ 5: A VIF of 5 or higher is often considered a red flag, indicating significant multicollinearity. It implies that the predictor variable is highly correlated with one or more other predictors in the model. High values can lead to unstable coefficient estimates and reduced interpretability of the regression model.
- VIF ≥ 10: The values exceeding 10 are a clear sign of severe multicollinearity. In such cases, the standard errors of the regression coefficients are substantially inflated, making it challenging to trust the coefficient estimates. High VIF values may lead to unreliable predictions and should be addressed.
- Analyzing Specific VIF Values: While assessing overall multicollinearity is essential, it’s also valuable to examine individual VIF values. Identifying which specific predictor variables have high values can help pinpoint the sources of multicollinearity in the model.
Interpreting VIF values requires a balance between statistical significance and practical significance:
- Low statistical significance (low p-values) for predictor variables may suggest that they are essential for the model. In such cases, even if VIF values are moderately high (e.g., between 5 and 10), it might be acceptable to retain these variables in the model, especially if they are theoretically relevant.
- High VIF values, while indicating multicollinearity, do not necessarily mean that a variable should be removed from the model. It depends on the research question, the context, and the trade-offs involved in model simplification.
In practice, addressing multicollinearity often involves a combination of strategies, including removing highly correlated variables, combining them into composite variables, or using regularization techniques like ridge regression. The choice of action should be guided by the specific goals of the analysis and the impact on model interpretability and predictive performance.
How can you detect Multicollinearity in Python?
Detecting collinearity in your dataset is a crucial step before proceeding with statistical analysis or building predictive models. Fortunately, there are several methods and techniques to identify the presence of it among predictor variables:
- Correlation Matrix: The most common approach is to compute the correlation matrix of all predictor variables. Correlation coefficients, such as Pearson’s correlation coefficient, quantify the strength and direction of linear relationships between pairs of variables. High absolute correlation values (close to 1 or -1) between two or more variables suggest potential collinearity.

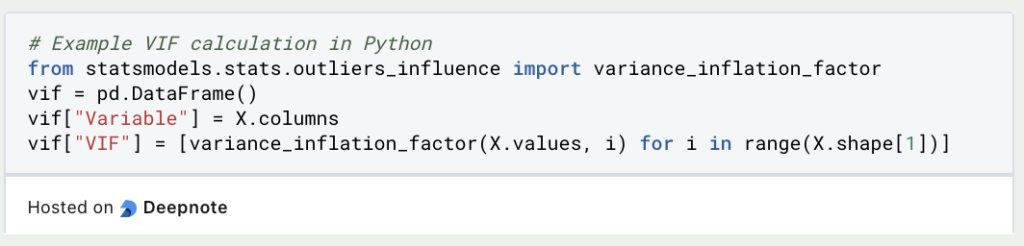
- Variance Inflation Factor: This measures the extent to which the variance of the estimated regression coefficients increases due to collinearity. A high VIF (usually above 5 or 10) for a variable indicates problems with other variables.
- Pairwise Scatterplots: Visual inspection of scatterplots between pairs of variables can reveal linear patterns. Variables that exhibit strong linear trends when plotted against each other may be collinear.

- Eigenvalues of the Correlation Matrix: Eigenvalues indicate the magnitude of variance in the data along specific dimensions. Small eigenvalues (close to zero) suggest that some variables are highly correlated, potentially indicating collinearity.

- Tolerance and Condition Index: These metrics provide additional insights into the collinear variables. Tolerance measures the proportion of variance in a variable that is not explained by other predictor variables, with low tolerance indicating collinearity. The condition index quantifies the severity of multicollinearity; higher values suggest more severe collinear variables.

Once you’ve detected this issue, you can take appropriate steps to address it. This may involve removing one of the correlated variables, transforming variables, or using regularization techniques like ridge regression. Detecting it is a critical part of data preparation.
What are remedies for Multicollinearity?
Multicollinearity, a common issue in regression analysis, can undermine the reliability of predictive models. Fortunately, there are several practical strategies to mitigate its impact:
1. Remove Redundant Variables: The first step in dealing with multicollinearity is identifying and eliminating highly correlated predictor variables. By doing so, you can retain the most informative variables in your model while reducing redundancy.
2. Combine or Transform Variables: Instead of discarding correlated predictors, you can create new variables by combining or transforming them. This approach retains the essential information while reducing multicollinearity.
3. Use Principal Component Analysis (PCA): PCA is a dimensionality reduction technique that can transform correlated variables into a set of uncorrelated principal components. These components can then serve as predictors in your model.
4. Employ Regularization Techniques: Regularization methods like Ridge Regression and Lasso Regression can help address multicollinearity. They add a penalty term to the regression equation, discouraging extreme parameter estimates and effectively mitigating multicollinearity.
5. Consider Partial Least Squares (PLS): PLS is an alternative to PCA. It combines dimensionality reduction with regression, aiming to maximize the covariance between predictors and the target variable while addressing multicollinearity.
Effectively managing multicollinearity enhances the accuracy and interpretability of regression models. The choice of strategy should align with the characteristics of your dataset, the goals of your analysis, and the context of your problem.
What are the practical use cases of VIF?
The Variance Inflation Factor plays a pivotal role in diverse applications, extending its utility beyond its primary function of detecting multicollinearity among predictor variables in regression analysis. Here, we delve into practical scenarios where the VIF proves indispensable:
Identifying Multicollinearity: The foremost application of VIF is its ability to flag multicollinearity—a phenomenon where predictor variables in a regression model exhibit high correlation. When VIF values are high, it indicates strong interdependence between predictors. Identifying multicollinearity is crucial as it can obscure the model’s ability to distinguish the individual effects of these correlated variables on the target variable.
Informed Model Selection: VIF serves as a guide for selecting variables to include in regression models. By examining the values, analysts can make data-driven decisions regarding the retention, exclusion, or transformation of variables. This process optimizes the model’s performance by mitigating issues stemming from multicollinearity.
Enhanced Coefficient Interpretation: Multicollinearity complicates the interpretation of regression coefficients. VIF comes to the rescue by helping generate stable and interpretable coefficient estimates. This clarity empowers analysts to better understand and communicate the influence of each predictor on the target variable.
Improved Model Performance: Multicollinearity can seriously hamper predictive models. By addressing multicollinearity using VIF-driven variable selection or transformation, analysts can develop more accurate models with enhanced predictive performance.
Mitigating Overfitting: Overfitting is a common pitfall in modeling when a model excessively fits the training data, resulting in poor generalization to new data. Multicollinearity exacerbates overfitting. VIF assists in mitigating this problem, ensuring that models generalize effectively.
In essence, the Variance Inflation Factor transcends its role as a multicollinearity detector in regression analysis. Its capacity to uncover and mitigate multicollinearity enhances the robustness and interpretability of regression models. As a fundamental asset in data-driven decision-making, VIF lends its benefits to diverse industries and research fields, enriching the precision and insightfulness of analyses.
What are the limitations of the Variance Inflation Factor?
The Variance Inflation Factor serves as a valuable tool for detecting multicollinearity in regression analysis. However, it’s essential to recognize its limitations to use it effectively:
VIF primarily focuses on identifying multicollinearity, which arises when independent variables in a regression model exhibit high correlations. Nonetheless, it does not address other factors that may affect the model’s performance, such as omitted variable bias or endogeneity.
Another limitation is its assumption of linear relationships between variables. Consequently, in cases with nonlinear associations, VIF may not provide accurate assessments of multicollinearity.
Moreover, VIF values can exhibit significant variation with changes in the dataset’s size. In smaller datasets, this measure might indicate multicollinearity even when its practical impact is minimal.
It’s important to note that while high VIF values suggest multicollinearity, they do not necessarily render the model’s results invalid. In some instances, a high value may be acceptable if multicollinearity doesn’t significantly affect the analysis’s objectives.
Furthermore, VIF exclusively addresses exogenous multicollinearity, wherein predictors correlate with one another. It does not tackle endogeneity, where the dependent variable influences predictors, potentially leading to biased estimates.
To effectively employ the Variance Inflation Factor, it is essential to consider these limitations and utilize complementary techniques and domain knowledge to construct reliable regression models.
This is what you should take with you
- The Variance Inflation Factor is a powerful tool for identifying multicollinearity in regression analysis.
- VIF helps assess the extent to which independent variables in a regression model are correlated with each other.
- High values indicate potential multicollinearity, which can lead to unstable and unreliable regression results.
- Addressing multicollinearity is crucial for producing valid and interpretable regression models.
- By calculating VIF for each predictor variable, analysts can pinpoint problematic relationships between variables.
- VIF values above a certain threshold (commonly 5 or 10) are often considered indicative of high multicollinearity.
- Reducing multicollinearity can involve removing variables, combining them, or collecting additional data.
- While VIF is a valuable tool, it has limitations, such as its focus on linear relationships and inability to address endogeneity.
- It’s important to interpret the values in the context of the specific analysis and consider additional techniques when needed.
- Overall, VIF is a valuable addition to the toolkit of data analysts and statisticians for improving the quality and reliability of regression models.

What is a Nash Equilibrium?
Unlocking strategic decision-making: Explore Nash Equilibrium's impact across disciplines. Dive into game theory's core in this article.

What is ANOVA?
Unlocking Data Insights: Discover the Power of ANOVA for Effective Statistical Analysis. Learn, Apply, and Optimize with our Guide!

What is the Bernoulli Distribution?
Explore Bernoulli Distribution: Basics, Calculations, Applications. Understand its role in probability and binary outcome modeling.

What is a Probability Distribution?
Unlock the power of probability distributions in statistics. Learn about types, applications, and key concepts for data analysis.

What is the F-Statistic?
Explore the F-statistic: Its Meaning, Calculation, and Applications in Statistics. Learn to Assess Group Differences.

What is Gibbs Sampling?
Explore Gibbs sampling: Learn its applications, implementation, and how it's used in real-world data analysis.
Other Articles on the Topic of Variance Inflation Factor
Here you can find an explanation on how to calculate the VIF in the Python library statsmodels.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.