K-nearest neighbors (kurz KNN) beschreibt einen Supervised Learning Algorithmus, der mithilfe von Abstandsberechnungen zwischen Punkten Daten klassifiziert. Dieser kann neuen Datenpunkten eine Klasse zuweisen, indem die k-nächsten Datenpunkte bestimmt werden und deren mehrheitliche Klasse auf den neuen Datenpunkt angewandt wird.
Wie funktioniert der Algorithmus?
Bei einer Klassifizierung wird allgemein versucht, die Punkte in einem Datensatz einer bestimmten Klasse zuzuordnen. Entsprechend soll ein Modell trainiert werden, das dann selbstständig für neue Punkte entscheiden kann, zu welcher Klasse sie am besten gehören sollen. Diese Modelle können entweder im Bereich des supervised oder des unsupervised Learnings liegen. Man unterscheidet damit, ob der Trainingsdatensatz schon eine spezielle Klassenzuordnung hat oder nicht.
Wenn wir beispielsweise die Kunden eines Unternehmens in drei verschiedene Gruppen aufteilen wollen, abhängig von ihrer Kaufkraft und der Anzahl der Einkäufe, unterscheiden wir einen supervised Learning Algorithmus, bei dem die Kunden im Trainingsdatensatz schon einer Kundengruppe zugeordnet wurden und das Modell anhand dieser gegebenen Klassifizierung auf neue Werte schließen soll. Beim unsupervised Learning hingegen sind die Kunden im Trainingsdatensatz noch nicht klassifiziert und das Modell muss anhand der erkannten Strukturen eigenständig Gruppierungen finden.
Angenommen wir nehmen folgende Kunden als Beispiel für die Erklärung des KNN-Algorithmus:
| Kunde | Gesamtumsatz | Anzahl Käufe | Gruppierung |
|---|---|---|---|
| A | 10.000 € | 5 | A |
| B | 1.500 € | 1 | B |
| C | 7.500 € | 3 | A |
Für den k-Nearest Neighbor Algorithmus muss am Anfang erst ein konkreter Wert für k bestimmt werden. Dieser gibt an mit wie vielen Nachbarn wir im Endeffekt den neuen Datenpunkt vergleichen. Für unser Beispiel wählen wir k = 2. Angenommen wir erhalten nun einen neuen Kunden D, der bereits für 9.000 € bei uns eingekauft hat und insgesamt vier Einkäufe getätigt hat. Um dessen Klassifizierung zu bestimmen, suchen wir nun die zwei (k=2) nächsten Nachbarn zu diesem Datenpunkt und bestimmen deren Klasse.

In unserem Fall sind das Kunde A und C, die beide der Klasse “A” angehören. Also klassifizieren wir den neuen Kunden D auch als A-Kunde, da dessen nächste zwei Nachbarn in der Mehrheit der Klasse “A” angehören.
Neben der Wahl des Wertes k bestimmt die Abstandsberechnung zwischen den Punkten über die Qualität des Modells. Dazu gibt es verschiedene Berechnungsweisen.
Wie können Abstände berechnet werden?
Je nach Anwendungsfall und Ausprägung der Daten können verschiedene Abstandsfunktionen genutzt werden zur Ermittlung der nächsten Nachbarn. Diese werden wir in diesem Kapitel genauer unter die Lupe nehmen.
Euklidische Distanz
DIe euklidische Distanz ist die am weit verbreitesten und lässt sich für reelle Vektoren mit vielen Dimensionen anwenden. Dabei werden die Abstände zwischen zwei Punkten in allen Dimensionen berechnet, quadriert und anschließend aufsummiert. Die Wurzel von dieser Summe ist dann das schlussendliche Ergebnis.
\(\) \[d(x,y) = \sqrt{\sum_{i = 1}^{n}(y_{i} – x_{i})^2}\]
Es wird dabei einfach eine direkte Linie zwischen den beiden Punkten x und y gelegt und deren Länge gemessen.
Manhattan Distanz
Die Manhattan Distanz hingegen berechnet die absolute Differenz der Punkte in allen Dimensionen und wird deshalb auch als “Taxi-Distanz” bezeichnet. Das Vorgehen ähnelt nämlich der Fahrt eines Taxis durch die senkrechten Straßen in New York.
\(\) \[d(x,y) = \sum_{i = 1}^{n}|y_{i} – x_{i}|\]
Die Anwendung dieser Distanzfunktion macht vor allem dann Sinn, wenn man Objekte miteinander vergleichen will. Wenn beispielsweise zwei Häuser verglichen werden sollen, indem man sich die Anzahl der Zimmer und die Wohnfläche in Quadratmeter genauer anschaut, macht es keinen Sinn, die euklidische Distanz zu nehmen, sondern getrennt die Differenz in den Zimmern und dann die Differenz in der Wohnfläche zu betrachten. Ansonsten würden diese Dimensionen mit verschiedenen Einheiten durcheinander gebracht.
Andere Distanzen
Darüber hinaus gibt es noch weitere Distanzfunktionen, die sich einsetzen lassen, wenn man spezielle Datenformate nutzt. Die Hamming Distanz bietet sich beispielsweise bei boole’schen Werten, wie True und False an. Der Minkowski Abstand hingegen ist eine Mischung aus der euklischen und der Manhattan Distanz.
Welche Anwendungen nutzen den KNN?
Bei der Arbeit mit großen Datenmengen hilft das Klassifizieren dabei einen ersten Eindruck über die Feature-Ausprägungen und die Verteilung der Datenpunkte zu bekommen. Darüber hinaus gibt es auch viele andere Anwendungen für das Klassifizierungen:
- Marktsegmentierung: Man versucht ähnliche Kundengruppen mit vergleichbarem Kaufverhalten oder sonstigen Eigenschaften zu finden.
- Bildsegmentierung: Es wird versucht innerhalb eines Bildes die Stellen zu finden, die zu einem bestimmten Objekt gehören, bspw. alle Pixel, die Teil eines Autos bzw. der Straße sind.
- Dokumentenclustering: Innerhalb eines Schriftstückes wird versucht Passagen mit ähnlichen Inhaltsschwerpunkten zu finden.
- Recommendation Engine: Bei der Empfehlung von Produkten werden mithilfe des k-Nearest Neighbors ähnliche Kunden gesucht und deren gekaufte Produkte dem jeweils anderen Kunden vorgeschlagen, sofern er diese noch nicht gekauft hat.
- Gesundheitswesen: Bei der Erprobung von Medikamenten und deren Wirksamkeit werden mithilfe von KNN besonders ähnliche Patienten gesucht und dann einer Patientin das Medikament verabreicht und der anderen Person nicht. Dadurch kann man vergleichen, welche Effekte vom Medikament ausgelöst wurden und welche möglicherweise sowieso eingetreten wären.
Was sind die Vor- und Nachteile des k-Nearest Neighbor Algorithmus?
Das k-Nearest Neighbor Modell erfreut sich großer Beliebtheit, weil es einfach zu verstehen und anzuwenden ist. Außerdem gibt es nur zwei Hyperparameter, die sich variieren lässt, nämlich zum einen die Anzahl der Nachbarn k und die Abstandsmetrik. Auf der anderen Seite ist dies natürlich auch ein Nachteil, da sich der Algorithmus nur wenig bis gar. nicht auf den konkreten Anwendungsfall anpassen lässt.
Aufgrund der einfachen Vorgehensweise benötigt der k-Nearest Neighbors Algorithmus jedoch bei großen Datensätzen auch viel Zeit und Arbeitsspeicher, was bei größeren Projekten schnell zu einem Kostenfaktor wird. Deshalb setzen größere Datenprojekte gerne zu aufwändigeren Modellen, wie beispielsweise dem k-Means Clustering.
Was ist der Unterschied zwischen k-nearest neighbors und k-Means?
Obwohl die Namen des k-Nearest Neighbors Algorithmus und des k-Means Clusterings im ersten Moment sehr ähnlich klingen, haben sie in Wirklichkeit relativ wenige Gemeinsamkeiten und werden für komplett unterschiedliche Anwendungen genutzt. Das k in k-Means Clustering beschreibt die Anzahl an Klassen, in die der Algorithmus einen Datensatz aufteilt. Bei den k-Nearest Neighbors hingegen steht das k für die Anzahl der Nachbarn, die genutzt werden, um die Klasse des neuen Datenpunktes zu bestimmen.
Außerdem ist das k-Nearest Neighbors Modell ein Supervised Learning Modell, da es die Zuteilung in Gruppen benötigt, um daraus neue ableiten zu können. Das k-Means Clustering hingegen zählt zu den Unsupervised Learning Algorithmen, da es im Stande ist aufgrund der Strukturen in den Daten verschiedene Gruppen eigenständig zu erkennen und die Daten diesen Klassen zuzuordnen.
Wie kann man k-nearest neighbor in Python implementieren?
Das k-nearest neighbor Matching ist ein hilfreicher Algorithmus, um ähnliche Daten zu klassifizieren und zu finden. Dieser kann relativ einfach in Python umgesetzt werden, wie wir in diesem Abschnitt mithilfe des IRIS-Datensatzes zeigen werden.
Schritt 1: Importiere Bibliotheken
Als erstes müssen die benötigten Python Bibliotheken importiert werden. Wir benötigen dafür numpy, sowie scikit-learn aus deren Bibliothek wir zum einen den Datensatz laden, als auch das hinterlegte Modell für k-nearest neighbor nutzen.

Schritt 2: Lade einen öffentlichen Datensatz
In diesem Beispiel verwenden wir den Iris-Datensatz, der ein bekannter und öffentlich zugänglicher Datensatz für Machine Learning Anwendungen ist. Er ist bereits in der Bibliothek scikit-learn verfügbar.

Schritt 3: Erstelle ein K-NN-Modell
Nachdem der Datensatz abgelegt wurde, kann nun das eigentliche Modell mithilfe der NereastNeighbors Klasse erstellt werden. Dazu muss noch die Anzahl der zu suchenden Nachbarn angegeben werden, sowie das Messverfahren für den Abstand.

Schritt 4: Führe die K-NN-Übereinstimmung durch
Nachdem das Modell trainiert wurde, kann es verwendet werden, um für einen beliebigen Datenpunkt die nahe gelegensten Nachbarn zu finden. In unserm Beispiel wird dafüfr ein beliebiger Punkt erstellt und die Nachbarn im Datensatz dafür gesucht.
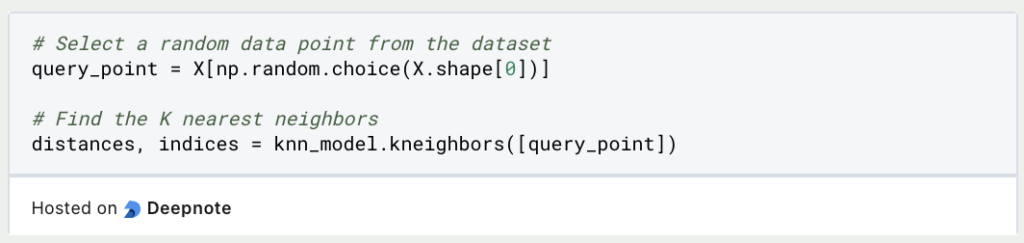
Schritt 5: Ergebnisse überprüfen
Die Ergebniss aus Schritt 4 können nun ausgegeben werden und die Punkte der nächsten Nachbarn ausgegeben werden:

Schritt 6: Interpretation und weitere Analyse
Neben den tatsächlichen Punkten werden auch die Abstände zu diesen Nachbarn zurückgegeben. Dadurch lässt sich erkennen, wie nahe die Punkte wirklich aneinander liegen. Anschließend kann man entscheiden, ob eine Interpretation möglich ist oder, ob die Punkte zu weit entfernt voneinander liegen.
Mithilfe dieser grundlegenden Schritte kann ein einfacher k-nearest neighbor Algorithmus in Python trainiert und genutzt werden. Dieselben Prinzipien und Schritte können auch auf Deinen eigenen Datensatz angwendet werden.
Wie kann das k-nearest neighbor Matching verbessert werden?
Das k-nearest Neighbor Matching ist ein einfacher Algorithmus, der schnell trainiert und genutzt werden kann. Jedoch können einige Optimierung vorgenommen werden, um ein möglichst gutes Ergebnis zu erreichen. Die folgenden Punkte sollten vor der Nutzung entschieden werden:
- Optimale Auswahl des K-Werts: Die Auswahl der Anzahl von gesuchten Nachbarn ist ein entscheidender Faktor für gute Ergebnisse. Ein zu großes k kann zu Verzerrungen führen, während ein zu kleines k zu rauschhaften Vorhersagen führt. Das ideale k kann beispielsweise mit Techniken wie der Kreuzvalidierung bestimmt werden und dadurch an den Datensatz angepasst werden.
- Auswahl und Konstruktion von Merkmalen: Die Qualität der Vorhersage ist entscheidend von den Merkmalen im Datensatz abhängig. Deshalb sollten die relevantesten Features identifiziert und genutzt werden. Außerdem kann über Feature Engineering nachgedacht werden, um neue Merkmale zu erstellen, die eine Kombination der vorhandenen Attribute sind.
- Abstandsmetriken: Die Abstandsmetrik spielt eine entscheidende Rolle bei der Suche der nächsten Nachbarn, da sie beeinflusst wie die Merkmalsskalen interpretiert werden. Die gängigsten Abstandsmaße sind der Euklidische oder Manhattener Abstand. Am besten experimentierst Du mit verschiedenen Metriken, um das optimale Ergebnis zu erzielen.
- Skalierung von Merkmalen: Die verschiedenen Skalen von numerischen Merkmalen können die Leistung von k-NN erheblich beeinflussen. Deswegen sollten diese nach Möglichkeit normalisiert werden, zum Beispiel mit dem MinMax Scaler oder der Z-Score Normalisierung. Dadurch wird sichergestellt, dass einzelne Merkmale keine überproportionale Wirkung auf die Nachbarsfindung haben.
- Datenverarbeitung: Wenn der Datensatz fehlende Werte enthält sollten diese aufgefüllt werden, beispielsweise durch Techniken wie die Imputation. Ansonsten kann es zu falschen Vorhersagen kommen bei Datenpunkten mit Ausreißern oder fehlenden Werten.
- Gewichtetes K-NN: Das Standard k-nearest neighbor Matching behandelt alle Nachbarn identisch, egal wie nah oder fern sie vom Datenpunnkt liegen. Ein gewichtetes k-NN stellt sicher, dass näher gelegene Nachbarn mehr Einfluss auf Vorhersagen haben. Dies kann in vielen Anwendungen sinnvoll sein.
- Dimensionsreduktion: Vor dem Training des Modell kann es sinnvoll sein, Techniken zu nutzen, die die Anzahl der Dimensionen reduziert, wie beispielsweise PCA oder tSNE. Dadurch kann die Effizienz des k-nearest neighbor Matchings verbessert und gleichzeitig der Fluch der Dimensionalität umgangen werden.
Mithilfe dieser Strategien kann ein k-NN Modell auf deinen spezifischen Datensatz und Anwendung angepasst werden, um die Leistung und Zuverlässigkeit der Vorhersagen zu gewährleisten.
Das solltest Du mitnehmen
- k-Nearest Neighbors ist ein Supervised Learning Algorithmus, der mithilfe von Distanzberechnungen zwischen Datenpunkten diese in Gruppen aufteilt.
- Ein neuer Punkt kann einer Gruppe zugeordnet werden, indem die k Nachbar Datenpunkte betrachtet werden und deren Mehrheitsklasse genutzt wird.
- Ein solches Clusteringverfahren kann sinnvoll sein, um sich in großen Datensätzen zurechtzufinden, Produktempfehlungen für neue Kunden auszusprechen oder für die Einteilungen in Test- und Kontrollgruppen in medizinischen Versuchen.

Was ist eine Boltzmann Maschine?
Die Leistungsfähigkeit von Boltzmann Maschinen freisetzen: Von der Theorie zu Anwendungen im Deep Learning und deren Rolle in der KI.

Was ist die Gini-Unreinheit?
Erforschen Sie die Gini-Unreinheit: Eine wichtige Metrik für die Gestaltung von Entscheidungsbäumen beim maschinellen Lernen.

Was ist die Hesse Matrix?
Erforschen Sie die Hesse Matrix: Ihre Mathematik, Anwendungen in der Optimierung und maschinellen Lernen.

Was ist Early Stopping?
Beherrschen Sie die Kunst des Early Stoppings: Verhindern Sie Overfitting, sparen Sie Ressourcen und optimieren Sie Ihre ML-Modelle.

Was sind Gepulste Neuronale Netze?
Tauchen Sie ein in die Zukunft der KI mit Gepulste Neuronale Netze, die Präzision, Energieeffizienz und bioinspiriertes Lernen neu denken.

Was ist RMSprop?
Meistern Sie die RMSprop-Optimierung für neuronale Netze. Erforschen Sie RMSprop, Mathematik, Anwendungen und Hyperparameter.
Andere Beiträge zum Thema k-Nearest Neighbor
IBM hat einen interessanten Beitrag zum k-Nearest Neighbor Modell geschrieben.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.