Das Perceptron ist ein Algorithmus aus dem Bereich des Supervised Learnings und stellt den Grundbaustein eines Neuronalen Netzwerks dar. In der einfachsten Form besteht es aus einem einzigen Neuron, das mithilfe von gewichteten Input-Werten einen Output-Wert errechnet.
Wie funktioniert ein Perceptron?
Das Perceptron ist ein ursprünglich mathematisches Modell und wurde erst später in der Informatik und im Machine Learning genutzt, aufgrund der Eigenschaft komplexe Zusammenhänge erlernen zu können. In der einfachsten Form besteht es aus genau einem sogenannten Neuron, das den Aufbau des menschlichen Gehirns nachahmt.
Das Perceptron hat dabei mehrere Eingänge, die sogenannten Inputs, an denen es numerische Informationen, also Zahlenwärte erhält. Je nach Anwendung kann sich die Zahl der Inputs unterscheiden. Die Eingaben haben verschiedene Gewichte, die angeben, wie einflussreich die Inputs für die schlussendliche Ausgabe sind. Während des Lernprozesses werden die Gewichte so geändert, dass möglichst gute Ergebnisse entstehen.
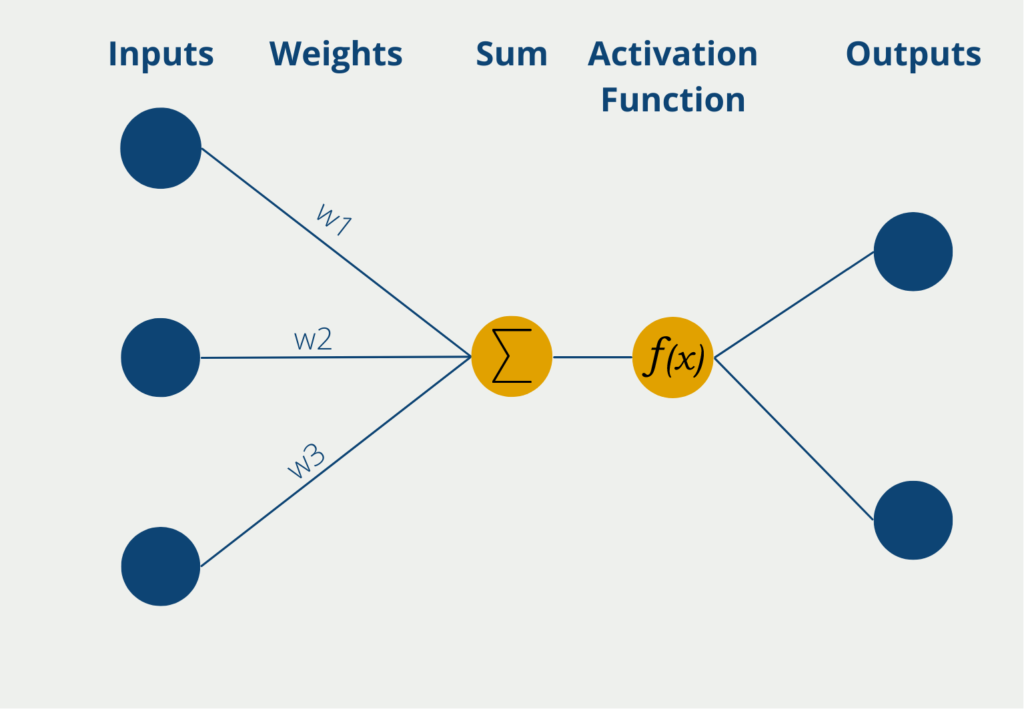
Das Neuron selbst bildet dann die Summe der Inputwerte multipliziert mit den Gewichten der Inputs. Diese gewichtete Summe wird weitergeleitet an die sogenannte Aktivierungsfunktion. In der einfachsten Form eines Neurons gibt es genau zwei Ausgaben, es können also nur binäre Outputs vorhergesagt werden, beispielsweise “Ja” oder “Nein” oder “Aktiv” oder “Inaktiv” etc.
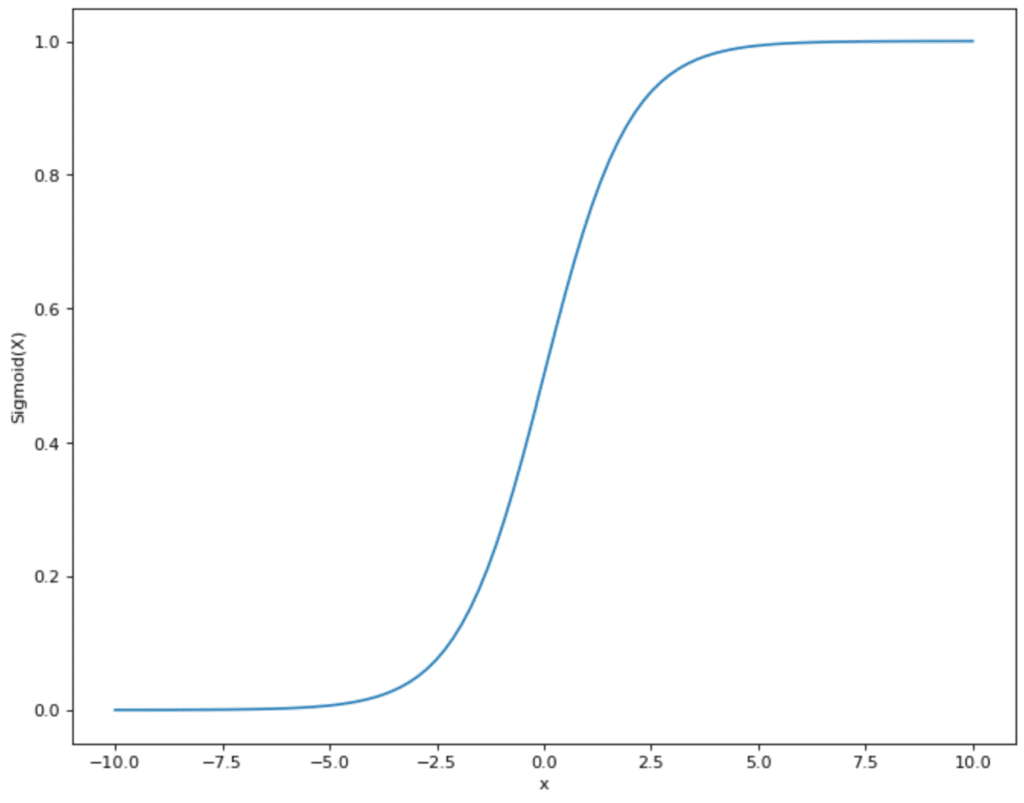
Wenn das Neuron binäre Ausgabewerte hat, wird eine Funktion genutzt, deren Werte auch zwischen 0 und 1 liegen. Ein Beispiel für eine häufig genutzt Aktivierungsfunktion ist die Sigmoid-Funktion. Die Werte der Funktion schwanken zwischen 0 und 1 und nehmen eigentlich auch fast ausschließlich diese Werte an. Außer bei x = 0 gibt es einen steilen Anstieg und den Sprung von 0 zu 1. Wenn die gewichtete Summe des Perceptrons also x = 0 überschreitet und das Perceptron Sigmoid als Aktivierungsfunktion nutzt, dann ändert sich der Output auch entsprechend von 0 auf 1.
Welches Beispiel veranschaulicht die Funktionsweise eines Perceptrons?
Als Beispiel für die Funktionsweise eines Perceptrons schauen wir uns die Arbeit einer Politikerin genauer an. Sie ist Mitglied des Parlaments und es muss über ein neues Gesetz abgestimmt werden. Somit muss die Politikerin entscheiden, ob sie dem Gesetzesvorschlag zustimmt oder ihn ablehnt (eine Enthaltung ist in unserem Beispiel nicht möglich). Das Perceptron hat also einen binären Output, nämlich Zustimmung oder Ablehnung.
Als Inputs für Ihre Entscheidung stehen der Politikerinnen verschiedene Informationsquellen zur Verfügung. Zum einen gibt es ein Informationspapier mit Hintergründen, das vom Parlament ausgegeben wurde. Des Weiteren kann sich die Abgeordnete im Internet über verschiedene Sachverhalte informieren oder mit anderen Kollegen darüber diskutieren. Die Politikerin gewichtet ihre Eingaben, also ihre Informationsquellen, je nachdem wie vertrauenswürdig sie diese ansieht. Dem Informationspapier des Parlaments beispielsweise weist sie ein eher geringes Gewicht zu, da sie fürchtet, dass die Recherche nicht ausführlich genug ist und bereits in eine gewisse Richtung tendieren soll. Sie nimmt dann die Summe der Informationen, die ihr zur Verfügung stehen, zusammen mit den Gewichtungen und gibt sie weiter zur Aktivierungsfunktion.
Diese können wir uns in diesem Beispiel vorstellen, wie der Kopf unserer Politikerin. Diese entscheidet nun, anhand der Inputs, ob sie dem Gesetzesvorschlag zustimmen soll oder nicht. Dabei können bereits Kleinigkeiten in den Inputs zu einer massiven Meinungsänderung der Politikerin führen.
Wie lernt das Perceptron?
In einem Perceptron beinhaltet der Lernprozess die Anpassung der Gewichte der Eingangssignale, um die gewünschte Ausgabe zu erreichen. Die Gewichte werden nach dem Zufallsprinzip initialisiert, und dann werden die Eingangssignale eingespeist, das die Ausgabe anhand einer gewichteten Summe der Eingaben berechnet.
Die berechnete Ausgabe wird dann mit der gewünschten Ausgabe verglichen, und die Differenz zwischen den beiden Werten wird zur Anpassung der Gewichte verwendet. Die Anpassung erfolgt durch Multiplikation der Eingangssignale mit einem Faktor, der proportional zur Differenz zwischen dem berechneten Ausgang und dem gewünschten Ausgang ist. Dieser Faktor wird als Lernrate bezeichnet.
Der Prozess wird für jedes Eingangssignal wiederholt, und bei jeder Iteration werden die Gewichte angepasst, um den Fehler zwischen der berechneten Ausgabe und der gewünschten Ausgabe zu verringern. Der Lernprozess wird so lange fortgesetzt, bis der Fehler minimiert ist und das Perceptron darauf trainiert ist, die Eingangssignale zu erkennen und die gewünschte Ausgabe zu erzeugen.
Es ist wichtig zu wissen, dass Perceptrons auf die Lösung linear trennbarer Probleme beschränkt sind, d. h. sie können nur Datenpunkte klassifizieren, die durch eine gerade Linie oder eine Hyperebene getrennt werden können. Für komplexere Probleme können mehrere Schichten von Perceptrons oder fortschrittlichere neuronale Netzwerkarchitekturen erforderlich sein.
Was ist ein Multi-Layer Perceptron?
Dieses einfache Modell kann bereits für viele Anwendungen genutzt werden, stößt jedoch schnell an Grenzen, wenn es darum geht, kompexere Zusammenhänge zu verstehen und zu erlernen. Deshalb wird in der Praxis vor allem auf mehrere Schichten von Perceptrons gesetzt, die dann zu einem sogenannten Künstlichen Neuronalen Netzwerk zusammengebaut werden.
Diese sogenannten Multi-Layer Perceptrons sind so mit einander verbunden, dass lediglich die erste Schicht an Neuronen Inputs von außerhalb des Netzwerks bekommt. Bei den darauffolgenden Schichten hingegen dienen die Outputs der vorherigen Schichten als Inputwerte für die aktuelle Schicht. Lediglich die Neuronen in der letzten Ebene des Neuronalen Netzwerks sind Outputs, die dann als tatsächliches Ergebnis genutzt werden.
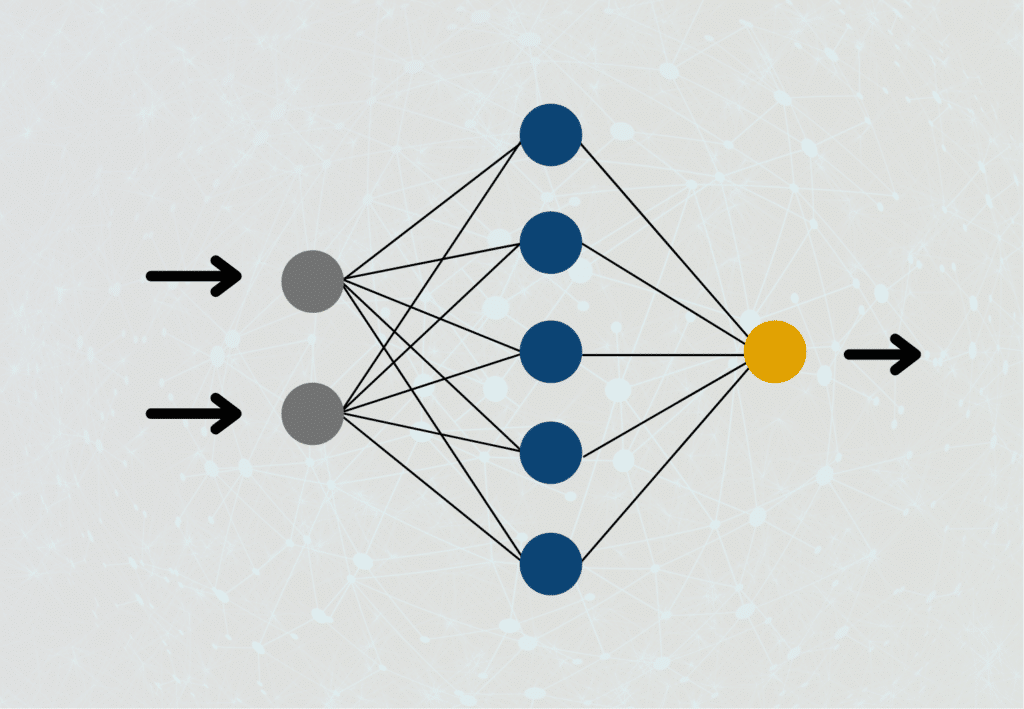
Bezogen auf unser Politikbeispiel könnten wir uns noch genauer mit den Informationsquellen der Politikerin beschäftigen. Das Informationsdokument des Parlaments setzt sich beispielsweise aus der Arbeit von verschiedenen wissenschaftlichen Mitarbeitern zusammen deren gewichtete Arbeit in das Endprodukt eingeflossen sind. Diese Mitarbeiter könnten wiederum auch als einzelne Perceptrons im Netzwerk dargestellt werden.
Was sind die Bias-Neuronen?
Bei Multi-Layer Perceptrons kommen sogenannte Bias-Neuronen zum Einsatz. Dies sind spezielle Inputneuronen, die jedoch keine externe Bedeutung haben, sondern einen konstanten Wert annehmen, der sich auch während des Lernprozesses ändern kann. Dadurch lässt sich die Kurve der Aktivierungsfunktion nach unten oder oben verschieben.
Der Bias ist ähnlich zu der Konstanten, die beispielsweise bei der Linearen Regression genutzt wird, und hilft dem Modell, es besser an die Outputwerte anzupassen und somit das Ergebnis zu verbessern.
Welche Anwendungen nutzen Perceptrons?
Die Neuronalen Netzwerke basieren auf den Perceptrons und werden vor allem im Bereich des Machine Learnings genutzt. Das Ziel dabei ist vor allem das Erlernen von Strukturen in vorherigen Daten und die anschließende Vorhersage von neuen Werten. Einige Beispiele dafür sind:
- Objekterkennung in Bildern: Künstliche Neuronale Netzwerke können Objekte in Bildern erkennen oder Bilder einer Klasse zu zuzuordnen. Unternehmen nutzen diese Eigenschaft beispielsweise beim Autonomen Fahren, um Objekte zu erkennen, auf die das Auto reagieren sollte. Ein anderes Einsatzgebiet gibt es in der Medizin, wenn Röntgenbilder untersucht werden sollen, um beispielsweise ein frühes Stadium von Krebs zu erkennen.
- Vorhersage: Wenn Unternehmen in der Lage sind zukünftige Szenarien oder Zustände sehr genau vorhersagen zu können, können sie verschiedene Entscheidungsmöglichkeiten gut gegeneinander abwägen und die beste Option wählen. Eine qualitativ hochwertige Regressionsanalyse für den zu erwartenden Umsatz im nächsten Jahr kann beispielsweise genutzt werden, um zu entscheiden, wie viel Budget für das Marketing eingeplant werden soll.
- Kundenstimmungsanalyse: Durch das Internet haben Kunden viele Kanäle, um ihre Bewertungen der Marke oder eines Produktes öffentlich zu machen. Unternehmen müssen deshalb den Überblick darüber behalten, ob die Kunden größtenteils zufrieden sind oder nicht. Mit wenigen Rezensionen, welche als gut oder schlecht klassifiziert sind, können effiziente Modelle trainiert werden, die dann automatische eine Vielzahl von Kommentaren einordnen können.
- Spamerkennung: In vielen Mailprogrammen gibt es die Möglichkeit konkrete E-Mails als Spam zu kennzeichnen. Diese Daten werden genutzt um Machine Learning Modelle zu trainieren, die zukünftige Mails direkt als Spam kennzeichnen, sodass sie der Endnutzer gar nicht erst angezeigt bekommt.
- Analyse von Aktienkursen: Neuronale Netzwerke können auch genutzt werden, um anhand von früheren Aktienkursen die Entwicklung einer Aktie vorhersagen zu können. Dabei spielen verschiedene Einflussgrößen eine Rolle, wie beispielsweise die gesamtwirtschaftliche Lage oder neue Informationen über das Unternehmen.
Was sind die Vor- und Nachteile von Perceptrons?
Die Nutzung von Perceptrons zeichnet sich durch die folgenden Vor- und Nachteile aus.
Vorteile
- Mithilfe von Single-Layer Perceptrons und vor allem Multi-Layer Perceptrons, den sogenannten Neuronalen Netzwerken, lassen sich komplexe Vorhersagen im Bereich des Supervised Learnings erlernen.
- Die Zahl der Inputs kann je nach Datenlage einfach erhöht werden, um verschiedene, relevante Werte mit in die Vorhersage einzubeziehen.
- Ein trainiertes Perceptron lässt sich relativ einfach interpretieren und die erlernten Gewichte können genutzt werden, um eine Aussage darüber zu treffen, wie wichtig die Inputs sind.
Nachteile
- Einzelne Perceptrons liefern nur selten wirklich gute Ergebnisse. Für leistungsfähige Modelle müssen meist verschiedene Schichten mit vielen Neuronen aufgebaut werden.
- Vor allem Multi-Layer Perceptrons funktionieren erst mit großen Datensätzen wirklich gut.
- Das Training von vielschichtigen Perceptrons ist meist zeitaufwändig und ressourcenintensiv.
- In vielen Schichten geht die Interpretierbarkeit der Gewichte verloren und es entwickelt sich eine “Blackbox”, deren gute Vorhersagen nicht wirklich erklärbar sind.
Das solltest Du mitnehmen
- Das Perceptron ist ein Algorithmus aus dem Bereich des Supervised Learnings und stellt den Grundbaustein eines Neuronalen Netzwerks dar.
- Wenn einzelne Perceptrons in mehreren Schichten aufgebaut und verbunden werden, spricht man von einem Multi-Layer Perceptron oder einem Neuronalen Netzwerk.
- Das Perceptron besteht aus den Inputs, den Gewichten, der Aktivierungsfunktion und den Outputs.
- Es kann genutzt werden, um komplexe Zusammenhänge in Daten zu erlernen und auf neue, bisher ungesehene Daten anzuwenden.

Was ist die Random Search?
Optimieren Sie Modelle für maschinelles Lernen: Lernen Sie, wie die Random Search Hyperparameter effektiv abstimmt.

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.

Was ist der Omitted Variable Bias?
Verständnis des Omitted Variable Bias: Ursachen, Konsequenzen und Prävention. Erfahren Sie, wie Sie diese Falle vermeiden.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.
Andere Beiträge zum Thema Perceptron
- Eine ausführliche Erklärung zu Perceptrons und deren Umsetzung in JavaScript findest du bei w3schools.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.