The perceptron is an algorithm from the supervised learning field and represents a Neural Network‘s basic building block. In its simplest form, it consists of a single neuron that calculates an output value using weighted input values.
How does a Perceptron work?
The perceptron is originally a mathematical model and was only later used in computer science and Machine Learning due to its ability to learn complex relationships. In its simplest form, it consists of exactly one so-called neuron, which imitates the structure of the human brain.
The perceptron has several inputs at which it receives numerical information, i.e. numerical values. Depending on the application, the number of inputs can differ. The inputs have different weights, which indicate how influential the inputs are for the final output. During the learning process, the weights are changed to produce the best possible results.
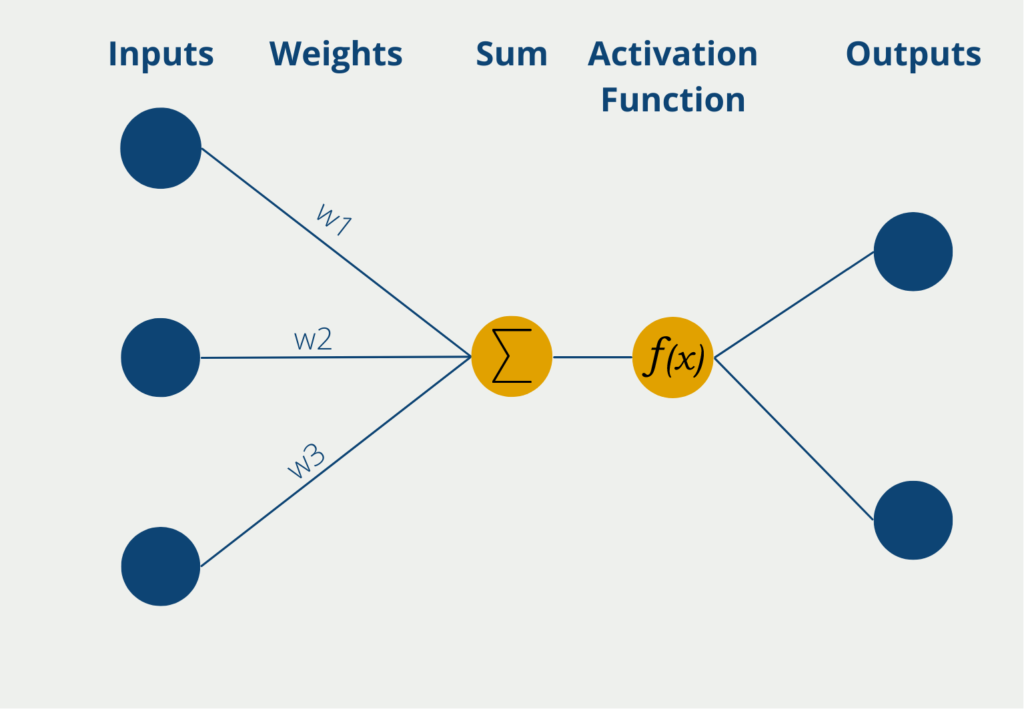
The neuron itself then forms the sum of the input values multiplied by the weights of the inputs. This weighted sum is passed on to the so-called activation function. In the simplest form of a neuron, there are exactly two outputs, so only binary outputs can be predicted, for example, “Yes” or “No” or “Active” or “Inactive”, etc.
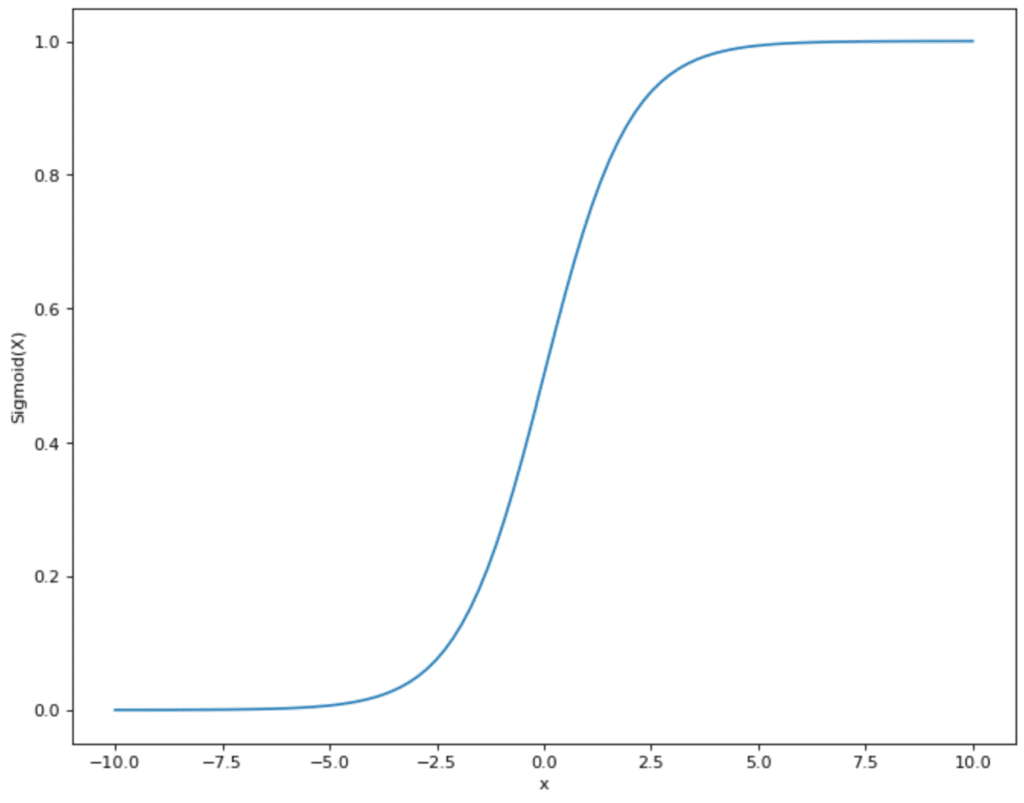
If the neuron has binary output values, a function is used whose values also lie between 0 and 1. An example of a frequently used activation function is the sigmoid function. The values of the function vary between 0 and 1 and actually take these values almost exclusively. Except for x = 0, there is a steep increase and a jump from 0 to 1. Thus, if the weighted sum of the perceptron exceeds x = 0 and the perceptron uses sigmoid as an activation function, the output also changes accordingly from 0 to 1.
Which Example illustrates how a Perceptron works?
As an example of how a perceptron works, let’s take a closer look at the work of a politician. She is a member of parliament and a new law has to be voted on. Thus, the politician has to decide whether she agrees or disagrees with the bill (abstention is not possible in our example). The perceptron thus has a binary output, namely approval or rejection.
There are various sources of information available to politicians as inputs for their decision. On the one hand, there is an information paper with background information issued by the parliament. Furthermore, the politician can inform herself about various issues on the Internet or discuss them with colleagues. The politician weights her input, i.e. her sources of information, according to how trustworthy she considers them to be. She assigns a relatively low weight to the parliamentary information paper, for example, because she fears that the research is not detailed enough and should already tend in a certain direction. She then takes the sum of the information available to her, along with the weights, and passes it on to the activation function.
In this example, we can imagine this as the head of our politician. She now decides, on the basis of the inputs, whether she should agree to the proposed law or not. Even small details in the inputs can lead to a massive change in the politician’s opinion.
How does the perceptron learn?
In a perceptron, the learning process involves adjusting the weights of the input signals to achieve the desired output. The weights are initialized randomly, and then the input signals are fed in, which calculates the output based on a weighted sum of the inputs.
The calculated output is then compared to the desired output, and the difference between the two values is used to adjust the weights. The adjustment is done by multiplying the input signals by a factor proportional to the difference between the calculated output and the desired output. This factor is called the learning rate.
The process is repeated for each input signal, and at each iteration, the weights are adjusted to reduce the error between the calculated output and the desired output. The learning process continues until the error is minimized and the perceptron is trained to recognize the input signals and produce the desired output.
It is important to note that perceptrons are limited to solving linearly separable problems, meaning they can only classify data points that can be separated by a straight line or hyperplane. More complex problems may require multiple layers of perceptrons or more advanced neural network architectures.
What is a Multi-Layer Perceptron?
This simple model can already be used for many applications but quickly reaches its limits when it comes to understanding and learning more complex relationships. Therefore, in practice, the focus is primarily on several layers of perceptrons, which are then assembled to form a so-called Artificial Neural Network.
These so-called multi-layer perceptrons are connected to each other in such a way that only the first layer of neurons receives inputs from outside the network. In the subsequent layers, on the other hand, the outputs of the previous layers serve as inputs for the current layer. Only the neurons in the last layer of the Neural Network are outputs, which are then used as the actual result.
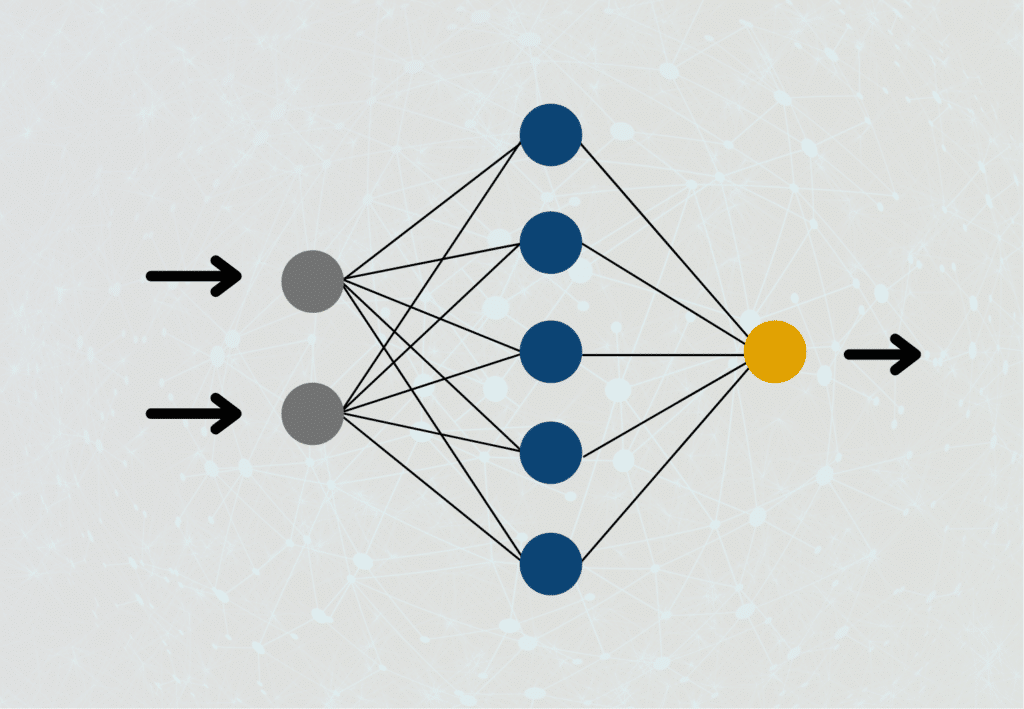
Related to our policy example, we could look more closely at the politician’s sources of information. For example, the parliament’s information document is composed of the work of various research assistants whose weighted work has been incorporated into the final product. In turn, these collaborators could also be represented as individual perceptrons in the network.
What are the Bias Neurons?
In multi-layer perceptrons, so-called bias neurons are used. These are special input neurons, which, however, have no external meaning, but assume a constant value that can also change during the learning process. This allows the curve of the activation function to be shifted downward or upward.
The bias is similar to the constant used in linear regression, for example, and helps the model to fit better to the output values and thus improve the result.
Which Applications use Perceptrons?
Neural Networks are based on perceptrons and are mainly used in the field of Machine Learning. The goal here is mainly to learn structures in previous data and then predict new values. Some examples are:
- Object Recognition in Images: Artificial Neural Networks can recognize objects in images or assign images to a class. Companies use this property in autonomous driving, for example, to recognize objects to which the car should react. Another area of application is in medicine when X-ray images are to be examined to detect an early stage of cancer, for example.
- Prediction: If companies are able to predict future scenarios or states very accurately, they can weigh different decision options well against each other and choose the best option. For example, high-quality regression analysis for expected sales in the next year can be used to decide how much budget to allocate to marketing.
- Customer Sentiment Analysis: Through the Internet, customers have many channels to make their reviews of the brand or a product public. Therefore, companies need to keep track of whether customers are mostly satisfied or not. With a few reviews, which are classified as good or bad, efficient models can be trained, which can then automatically classify a large number of comments.
- Spam Detection: In many mail programs there is the possibility to mark concrete emails as spam. This data is used to train Machine Learning models that directly mark future emails as spam so that the end user does not even see them.
- Analysis of Stock Prices: Neural Networks can also be used to predict the development of a stock based on previous stock prices. Various influencing variables play a role here, such as the overall economic situation or new information about the company.
What are the Advantages and Disadvantages of Perceptrons?
The use of perceptrons is characterized by the following advantages and disadvantages.
Advantages
- With the help of single-layer perceptrons and especially multi-layer perceptrons, the so-called Neural Networks, complex predictions can be learned in the field of supervised learning.
- Depending on the data, the number of inputs can be easily increased to include different, relevant values in the prediction.
- A trained perceptron is relatively easy to interpret and the learned weights can be used to make a statement about how important the inputs are.
Disadvantages
- Single perceptrons rarely provide really good results. For powerful models, different layers with many neurons usually have to be built up.
- Especially multi-layer perceptrons only work really well with large data sets.
- Training multi-layer perceptrons is usually time-consuming and resource-intensive.
- In many layers, the interpretability of the weights is lost and a “black box” develops whose good predictions cannot really be explained.
This is what you should take with you
- The perceptron is an algorithm from the field of supervised learning and represents the basic building block of a neural network.
- When individual perceptrons are built and connected in multiple layers, it is called a multi-layer perceptron or a neural network.
- The perceptron consists of the inputs, the weights, the activation function, and the outputs.
- It can be used to learn complex relationships in data and apply them to new, previously unseen data.

What is a Boltzmann Machine?
Unlocking the Power of Boltzmann Machines: From Theory to Applications in Deep Learning. Explore their role in AI.

What is the Gini Impurity?
Explore Gini impurity: A crucial metric shaping decision trees in machine learning.

What is the Hessian Matrix?
Explore the Hessian matrix: its math, applications in optimization & machine learning, and real-world significance.

What is Early Stopping?
Master the art of Early Stopping: Prevent overfitting, save resources, and optimize your machine learning models.

What is RMSprop?
Master RMSprop optimization for neural networks. Explore RMSprop, math, applications, and hyperparameters in deep learning.

What is the Conjugate Gradient?
Explore Conjugate Gradient: Algorithm Description, Variants, Applications and Limitations.
Other Articles on the Topic of Perceptrons
- A detailed explanation of perceptrons and their implementation in JavaScript can be found at w3schools.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.