Deep Learning ist eine Methode aus der Informationsverarbeitung, die große Datenmengen mithilfe von Neuronalen Netzen analysiert. Diese Vorgehensweise ist in großen Teilen den biologischen Prozessen im menschlichen Gehirn nachempfunden, mit dem Unterschied, dass die Verarbeitung solcher Datensätze für unser Gehirn nur sehr schwierig möglich wäre.
Wie funktioniert Deep Learning?
Deep Learning umfasst Algorithmen, die so programmiert sind, dass sie ohne menschliches Zutun lernen können. Die technische Grundlage dieser Programme sind die Neuronalen Netze. Diese bestehen aus vielen Schichten von Neuronen, genau wie unser Gehirn. In der Eingabeschicht kommen alle Informationen an, die verarbeitet werden sollen. In unserem biologischen Beispiel wären das die Sinneseindrücke von Augen, Fingern, etc. Am Ende des Netzwerkes werden eine oder mehrere Reaktionen ausgegeben, abhängig von den Eingaben. Wenn wir beispielsweise einen Löwe in unmittelbarer Nähe sehen ist unsere Reaktion uns schnell in Sicherheit zu bringen.
Damit es zu dieser angemessenen Reaktion kommt, müssen wir die Eingaben richtig verarbeiten. Dies passiert in den Schichten zwischen Eingabe- und Ausgabeschicht, den sogenannten verborgenen Schichten. Aufgrund von vergangenen Erfahrungen bilden sich stärkere oder schwächere Verbindungen zwischen den Neuronen aus verschiedenen Schichten aus. Umso mehr Zwischenschichten ein Netzwerk hat, umso “tiefer” ist es. Daher stammt auch der Begriff “Deep” Learning.
Dieses Beispiel lässt sich fast eins zu eins auf den technischen Algorithmus übertragen. Wir definieren ein Neuronales Netzwerk mit einer gewissen Anzahl an Schichten und Neuronen. In den meisten Fällen können mithilfe von mehr Neuronen auch komplexere Sachverhalte gelernt werden. Also umso komplexer der Anwendungsfall, umso größer das Neuronale Netzwerk. Mithilfe von Trainingsdaten lernt das Modell dann die richtigen Neuronen miteinander zu verknüpfen, sodass der richtige Zusammenhang zwischen Modelleingabe und -ausgabe entsteht. Von außen geben wir dabei nur vor, wie die richtige Vorhersage aussehen soll. Die richtigen Verbindungen innerhalb des Netzwerkes zu setzen, lernt das Modell hingegen von selbst.
Welche Arten von Neuronalen Netzwerken gibt es?
Es gibt verschiedene Arten von neuronalen Netzen, die für unterschiedliche Zwecke beim Deep Learning verwendet werden. Einige der am häufigsten verwendeten neuronalen Netzwerktypen sind:
- Feedforward Neural Networks: Neuronale Netze mit Vorwärtskopplung sind die einfachste Art von neuronalen Netzen, die über eine Eingabeschicht, eine oder mehrere versteckte Schichten und eine Ausgabeschicht verfügen. Sie werden für Regressions- und Klassifizierungsaufgaben verwendet, bei denen die Eingabe- und Ausgabedaten klar definiert sind.
- Neuronale Faltungsnetzwerke (CNNs): CNNs werden für Aufgaben der Bild- und Videoerkennung verwendet. Sie verfügen über Faltungsschichten, die Merkmale aus den Eingabebildern oder -videos extrahieren können, sowie über Pooling-Schichten, die die Größe der Merkmalskarten reduzieren können.
- Rekurrente Neuronale Netze (RNNs): RNNs werden für die Verarbeitung sequenzieller Daten wie Text oder Sprache verwendet. Sie verfügen über eine Rückkopplungsschleife, die es ihnen ermöglicht, Daten zu verarbeiten, die in einem zeitlichen Zusammenhang stehen.
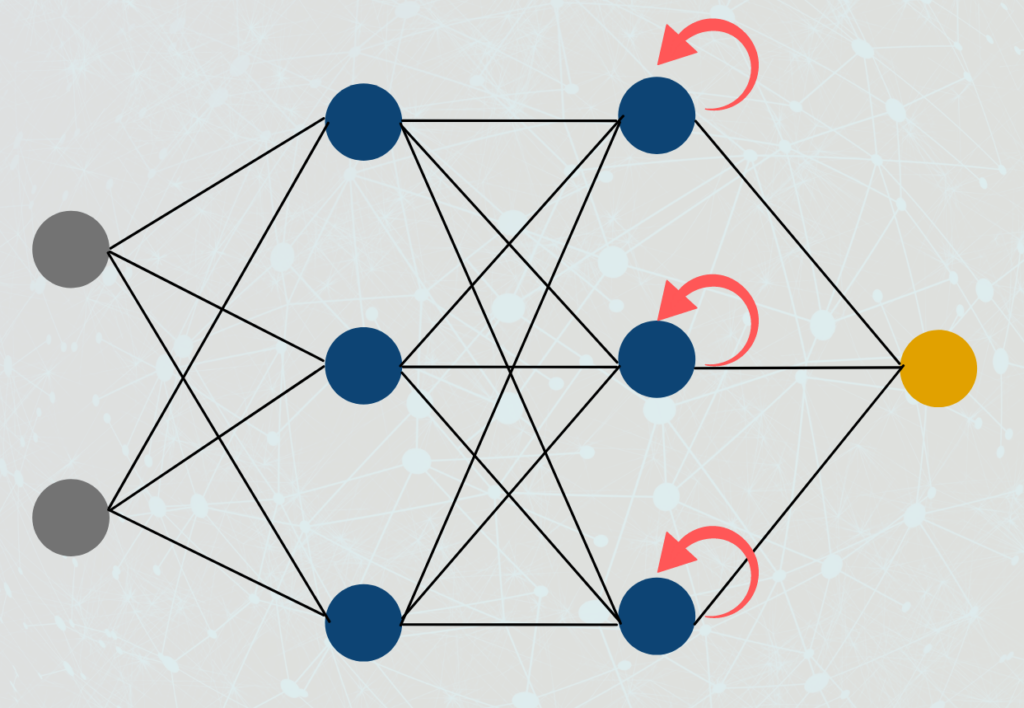
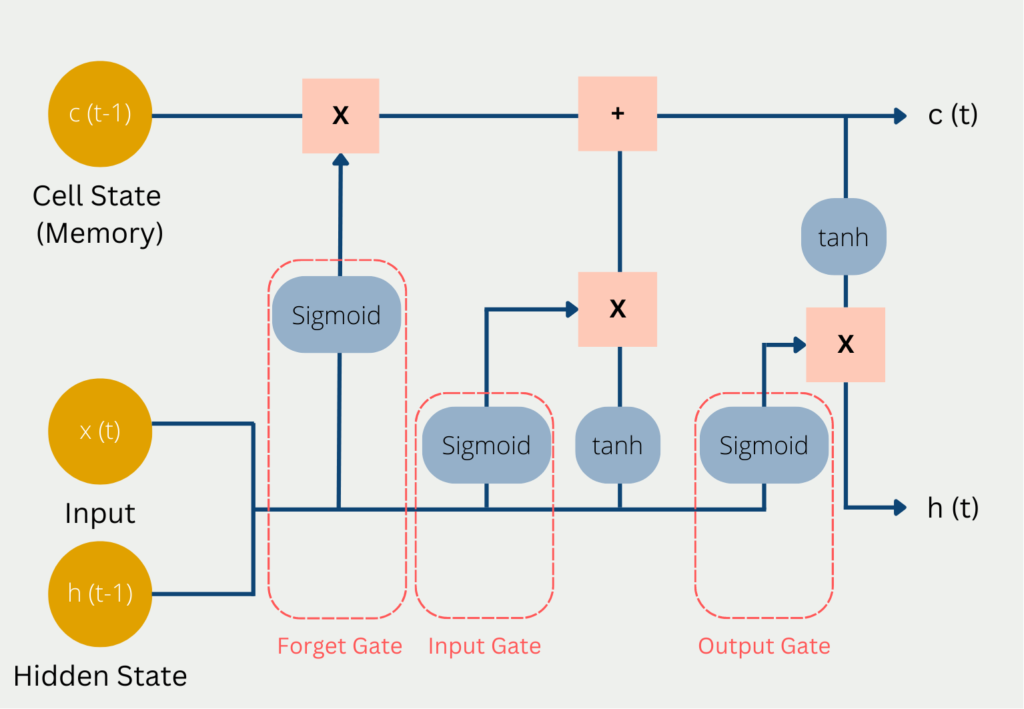
- Long Short-Term Memory (LSTM): LSTMs sind eine Art von RNN, die speziell entwickelt wurden, um das Problem des verschwindenden Gradienten zu vermeiden. Sie werden für die Spracherkennung, die Verarbeitung natürlicher Sprache und die Erstellung von Bildunterschriften verwendet.
- Autoencoder-Neuronale Netze: Neuronale Netze mit Autoencodern werden für unbeaufsichtigte Lernaufgaben wie Dimensionalitätsreduktion, Merkmalsextraktion und Erkennung von Anomalien verwendet. Sie verfügen über einen Kodierer, der die Eingabedaten auf einen niedrigdimensionalen Raum abbilden kann, und einen Dekodierer, der die ursprünglichen Eingabedaten aus der niedrigdimensionalen Darstellung rekonstruieren kann.
- Generative adversarische Netzwerke (GANs): GANs werden zur Erzeugung neuer Daten verwendet, die den Trainingsdaten ähnlich sind. Sie bestehen aus zwei neuronalen Netzen – einem Generator, der neue Daten erzeugen kann, und einem Diskriminator, der zwischen den erzeugten Daten und den realen Daten unterscheiden kann.
Jeder Typ von neuronalen Netzen hat seine eigenen Stärken und Schwächen, und die Wahl des richtigen Typs hängt von der jeweiligen Aufgabe ab.
Was sind praktische Anwendungen für Deep Learning?
Neuronale Netzwerke begegnen uns heute bereits unbewusst im Alltag. Es wird dabei versucht, aus vergangenen Daten Zusammenhänge zu lernen, die man in zukünftigen Situationen anwenden kann.
- Dynamic Pricing: Hierbei geht es darum, spezifische Preise für dasselbe Produkte zu setzen abhängig vom Kunden, Land oder anderen Umständen. Vor ein paar Jahren war dies vor allem auf Fluggesellschaften beschränkt, die Flugpreise entsprechend angepasst haben, um so näher das Abflugdatum gerückt ist. Heutzutage ist diese Strategie in vielen Bereichen denkbar, beispielsweise im E-Commerce, in dem Kunden besonders günstige Bundles angeboten werden, um sie zurück in den Shop zu locken.
- Produktempfehlungen: Dies ist auch wieder ein Use-Case, der vor allem im E-Commerce genutzt wird und darauf abzielt dem Kunden ein passendes Produkt vorzuschlagen, basierend beispielsweise auf dessen Kaufhistorie, Suchverhalten oder anderen Kundeneigenschaften. Darüber hinaus werden solche Algorithmen auch bei Netflix oder Amazon Prime eingesetzt, um eine passende Serie oder einen passend Film zu vorzuschlagen.
- Fraud Detection: Dabei handelt es sich um die automatisierte Erkennung von auffälligem Verhalten aller Art, die meistens auf einen Missbrauch des Systems hinweisen. Der berühmteste Anwendungsfall sind Bankkonten auf denen auffällige Abbuchungen oder Kreditkartentransaktionen stattfinden, die darauf hinweisen könnten, dass die Kreditkarte in falsche Hände geraten ist.
Deep Learning vs. Machine Learning
Deep Learning ist ein Teilbereich von Machine Learning, der sich von Machine Learning darin unterscheidet, dass kein Mensch in den Lernprozess involviert ist. Dies basiert auf der Tatsache, dass nur Deep Learning Algorithmen in der Lage sind unstrukturierte Daten, wie Bilder, Videos oder Audiodateien zu verarbeiten. Andere Machine Learning Modelle hingegen benötigen für die Verarbeitung dieser Daten die Hilfe von Menschen, die ihnen beispielsweise mitteilen, dass in dem Bild ein Auto zu erkennen ist. Deep Learning Algorithmen hingegen können unstrukturierte Daten automatisiert in numerische Werte umwandeln und diese dann in ihre Vorhersagen mit einbeziehen und Strukturen erkennen, ohne dass eine menschliche Interaktion stattgefunden hat.

Darüber hinaus sind Deep Learning Algorithmen in der Lage deutlich größere Datenmengen zu verarbeiten und somit auch komplexere Aufgaben anzugehen, als herkömmliche Machine Learning Modelle. Jedoch geht dies zu Lasten einer deutlich längeren Trainingszeit von Deep Learning Modellen. Gleichzeitig sind diese Modelle auch nur sehr schwierig interpretierbar. Das heißt, wir können nicht verstehen, wie ein Neuronales Netzwerk zu einer guten Vorhersage kam.
Was sind die zukünftigen Themen im Deep Learning?
Deep Learning ist zu einem unverzichtbaren Werkzeug der modernen künstlichen Intelligenz geworden und hat verschiedene Bereiche wie Bilderkennung, Spracherkennung und Verarbeitung natürlicher Sprache revolutioniert. Es gibt jedoch immer noch Herausforderungen, die in diesem Bereich bewältigt werden müssen. Hier sind einige der Herausforderungen und die Zukunft des Deep Learning:
- Daten: Deep Learning Algorithmen benötigen große Mengen an Daten, um Muster zu lernen und genaue Vorhersagen zu treffen. Die Beschaffung und Kennzeichnung von Daten kann jedoch kostspielig und zeitaufwändig sein.
- Interpretierbarkeit: Die Modelle können schwer zu interpretieren sein, was es schwierig macht, die Ursache von Fehlern und Verzerrungen zu ermitteln.
- Überanpassung: Die Deep Learning Modelle können sich manchmal zu stark an die Daten anpassen, was bedeutet, dass sie zu komplex werden und bei neuen Daten schlecht abschneiden.
- Trainingszeit: Die erstellen Vorhersagen benötigen viel Rechenleistung, um trainiert zu werden, was es für kleinere Organisationen und Einzelpersonen schwierig macht, Modelle zu entwickeln.
- Verallgemeinerung: Die Modelle, die auf bestimmten Daten trainiert wurden, können möglicherweise nicht auf andere Datensätze verallgemeinert werden, was zu einer geringeren Leistung führt.
- Angriffe: Deep Learning Modelle können anfällig für Angriffe von außen sein, bei denen böswillige Akteure die Eingabedaten manipulieren, um das Modell zu falschen Vorhersagen zu veranlassen.
Trotz dieser Herausforderungen sieht die Zukunft des Deep Learning vielversprechend aus. Forscher entwickeln ständig neue Techniken, um diese Herausforderungen zu bewältigen und die Genauigkeit und Effizienz von Deep-Learning-Modellen zu verbessern. Einige der Bereiche, in denen Deep Learning in Zukunft voraussichtlich an Bedeutung gewinnen wird, sind:
- Personalisierte Gesundheitsversorgung: Deep-Learning-Modelle können Patientendaten analysieren, um personalisierte Behandlungen und Diagnosen zu erstellen.
- Autonome Fahrzeuge: Deep-Learning-Modelle können autonomen Fahrzeugen helfen, Objekte und Hindernisse in Echtzeit zu erkennen und darauf zu reagieren.
- Fortschrittliche Robotik: Deep-Learning-Modelle können Robotern dabei helfen, zu lernen und sich an neue Umgebungen anzupassen, um ihre Flexibilität und Effektivität zu verbessern.
- Klimamodellierung: Diese Modelle können dabei helfen, die Auswirkungen des Klimawandels vorherzusagen und Strategien zur Eindämmung der Folgen zu ermitteln.
- Finanzen: Deep Learning Modelle können Markttrends analysieren und Vorhersagen treffen und so Investitionsentscheidungen verbessern.
Mit der weiteren Entwicklung und Reifung von Deep Learning wird erwartet, dass es in unserem täglichen Leben noch stärker zum Einsatz kommt und die Art und Weise, wie wir leben, arbeiten und mit der Welt interagieren, verändert.
Das solltest Du mitnehmen
- Deep Learning ist ein Teilbereich von Machine Learning und beschreibt eine Methode der Informationsverarbeitung.
- Es werden vor allem Neuronale Netzwerke genutzt, um Zusammenhänge aus großen Datensätzen nutzen zu können, die man dann in zukünftigen Situationen anwenden kann.
- Deep Learning kommt heute beispielsweise schon bei Produktempfehlungen im E-Commerce oder bei der Betrugserkennung im Bankenbereich zum Einsatz.
- Deep Learning unterscheidet sich von Machine Learning vor allem darin, dass es auch mit unstrukturierten Daten, wie Bildern, Videos oder Audioaufnahmen, umgehen kann.

Was ist die Poisson Regression?
Lernen Sie die Poisson-Regression kennen, ein statistisches Modell für die Analyse von Zähldaten, inkl. einem Beispiel in Python.

Was ist blockchain-based AI?
Entdecken Sie das Potenzial der blockchain-based AI in diesem aufschlussreichen Artikel über Künstliche Intelligenz und Blockchain.

Was ist Boosting im Machine Learning?
Boosting: Eine Ensemble-Technik zur Modellverbesserung. Lernen Sie in unserem Artikel Algorithmen wie AdaBoost, XGBoost, uvm. kennen.

Was ist Feature Engineering?
Meistern Sie die Kunst des Feature Engineering: Steigern Sie die Modellleistung und -genauigkeit mit der Datentransformationen!

Was sind N-grams?
Die Macht des NLP: Erforschen Sie n-Grams in der Textanalyse, Sprachmodellierung und verstehen Sie deren Bedeutung im NLP.

Was ist das No-Free-Lunch Theorem (NFLT)?
Entschlüsselung des No-Free-Lunch-Theorems: Implikationen und Anwendungen in ML und Optimierung.
Andere Beiträge zum Thema Deep Learning
- IBM hat einen spannenden Artikel, in dem auch andere Deep Learning Anwendungen beschrieben werden.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.