Reinforcement learning is the fourth major learning method in Machine Learning, along with supervised, unsupervised, and semi-supervised learning. The main difference is that the model does not need much data to train. It learns structures by being rewarded for desired behaviors and punished for bad ones.
What are the use cases for Reinforcement Learning?
Before we can look in detail at what the training process looks like for such models, we should understand in which situations these algorithms can help:
- Reinforcement learning is used when teaching a computer to play games. The aim is to learn which tactics lead to victory and which do not.
- In autonomous driving, these learning algorithms are also used so that the vehicle can decide on its own which course of action is best.
- For the air conditioning of server rooms, reinforcement learning models decide when and how much to cool down the room to use energy efficiently.
The applications of reinforcement learning are generally characterized by the fact that a large number of successive decisions have to be made. The programmer could also prescribe these concretely to the computer (for example: “If the temperature rises above 24 °C, then cool down to 20 °C”).
With the help of reinforcement learning, however, one wants to avoid formulating a chain of if-then conditions. On the one hand, this may simply be impossible in many use cases, such as autonomous driving, since the programmer cannot foresee all eventualities. On the other hand, it is hoped that these models will also enable the development of new strategies for complex problems, which a human being might not be able to do at all.
How does Reinforcement Learning work?
Reinforcement learning models should be trained to make a series of decisions independently. Suppose we want to train such an algorithm, the so-called agent, to play the game Pac-Man as successfully as possible. The agent starts at an arbitrary position in the game field and has a limited number of possible actions it can perform. In our case, these would be the four directions (up, down, right, or left) that it can go on the playing field.
The environment in which the algorithm finds itself in this game is the playing field and the movement of ghosts, which must not be encountered. After each action, for example, go up, the agent receives direct feedback, the reward. In Pac-Man, these are either getting points or an encounter with a ghost. It can also happen that after an action there is no direct reward, but it takes place in the future, for example in one or two further actions. For the agent, rewards that are in the future are worth less than immediate rewards.
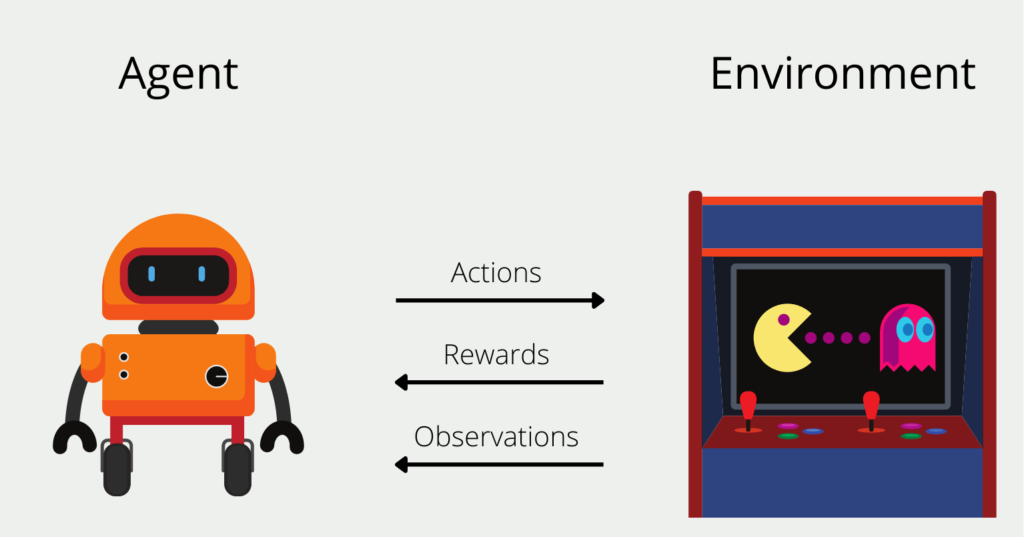
Over time, the agent develops a so-called policy, i.e. a strategy of actions that promises the highest long-term reward. In the first rounds, the algorithm selects completely random actions, since it has not yet been able to gain any experience. Over time, however, a promising strategy emerges.
What are the concepts in Reinforcement Learning?
In addition to the concepts already mentioned in the explanation, there are other concepts that are important in the field of reinforcement learning:
- Agent: the model that is to be trained, making decisions piece by piece for which it is either punished or rewarded.
- Environment: The scenarios or playing field that the agent explores in the course of the game and which decides on the consequences of the actions.
- Reward: The result of an action, which occurs after each step. The reward does not necessarily have to be positive, but can also mean a “punishment” for the model.
- State: Current situation the agent is in, for example, the position on the playing field.
- Policy: This is the strategy that the agent develops over time to decide on the next action. In the beginning, this is mostly a purely random decision and towards the end of the training it has developed into a real strategy.
- Value Function: This function determines how high or low the reward will be after an action. In many cases, it represents the rules of the game that is to be learned.
- Q-Value: More precisely, this value is a function that takes as input a state-action pair and outputs the expected cumulative reward that an agent will receive if it performs that action in that state. The function is thus the decision support for the agent on how best to behave in the given situation to have the highest possible probability of success.
What are the Differences between Machine Learning Methods?
In the field of Machine Learning, a distinction is made between a total of four different learning methods:
- Supervised Learning algorithms learn relationships using a dataset that already contains the label that the model should predict. However, they can only recognize and learn structures that are contained in the training data. Supervised models are used, for example, in the classification of images. Using images that are already assigned to a class, they learn to recognize relationships that they can then apply to new images.
- Unsupervised Learning algorithms learn from a dataset, but one that does not yet have these labels. They try to recognize their own rules and structures in order to be able to classify the data into groups that have the same properties as far as possible. Unsupervised learning can be used, for example, when you want to divide customers into groups based on common characteristics. For example, order frequency or order amount can be used for this purpose. However, it is up to the model itself to decide which characteristics it uses.
- Semi-supervised Learning is a mixture of supervised learning and unsupervised learning. The model has a relatively small data set with labels available and a much larger data set with unlabeled data. The goal is to learn relationships from the small amount of labeled information and test those relationships in the unlabeled data set to learn from them.
- Reinforcement Learning differs from previous methods in that it does not need training data, but simply works and learns via the described reward system.

Does Reinforcement Learning need Training Data?
Yes, reinforcement learning models also require data for training. But compared to other Machine Learning methods, this information does not have to be given in an external data set but can be created during training.
In the world of machine learning, data is essential to train good and robust models. Supervised Learning uses human-labeled data for this purpose, which is best available in large quantities. This is usually expensive and the data sets are very difficult to obtain or create. Unsupervised Learning, on the other hand, also requires a lot of data, but it does not need to have a label. This makes obtaining information much cheaper and easier.
As we have already seen, reinforcement learning is completely contrary to supervised and unsupervised learning. Nevertheless, the principle that a larger amount of data generally leads to better training results also applies here. The difference from the other types of Machine Learning models, however, is that this data is not necessarily supplied externally, but is generated by the model itself.
Let’s take learning a game as an example: A machine learning model is trained to win the game, i.e., moves that lead to a win are considered positive, and moves that lead to a loss are considered negative. In this scenario, the model can use many games runs as training data because the goal of “winning the game” is clearly defined. With each new game, the model learns, new training data is generated and the model gets better.
Is Reinforcement Learning the future of Deep Learning?
Reinforcement learning will not be able to replace Deep Learning in the future. These two sub-areas are strongly connected, but they are not the same. Deep Learning algorithms are very good at recognizing structures in large data sets and applying them to new, unknown data. Reinforcement Learning models, on the other hand, make decisions even without training data sets.
In many areas, Machine Learning and Deep Learning models will continue to be sufficient to achieve good results. The success of Reinforcement Learning, on the other hand, means that new areas of Artificial Intelligence can now be opened up that were previously unthinkable. However, there are also applications, such as stock trading, where Reinforcement Learning will replace Deep Learning models as it provides better results.
In this area, attempts have been made to learn how to recognize and trade new stocks from past market data. For the stock business, however, it can be much more promising to train a Reinforcement Learning algorithm to develop a concrete strategy, independent of past data.
This is what you should take with you
- Reinforcement learning is a learning method in the field of machine learning.
- It describes models that are trained to predict a sequence of decisions that promise the highest possible success rate.
- In addition to reinforcement learning, there is also supervised learning, unsupervised learning, and semi-supervised learning.
- The advantage of reinforcement learning is often seen in the fact that large data sets are not required in advance, but are created during the training itself.
- Reinforcement learning is used, for example, to teach computers to play games or to make the right decisions in autonomous driving.

What is a Boltzmann Machine?
Unlocking the Power of Boltzmann Machines: From Theory to Applications in Deep Learning. Explore their role in AI.

What is the Gini Impurity?
Explore Gini impurity: A crucial metric shaping decision trees in machine learning.

What is the Hessian Matrix?
Explore the Hessian matrix: its math, applications in optimization & machine learning, and real-world significance.

What is Early Stopping?
Master the art of Early Stopping: Prevent overfitting, save resources, and optimize your machine learning models.

What is RMSprop?
Master RMSprop optimization for neural networks. Explore RMSprop, math, applications, and hyperparameters in deep learning.

What is the Conjugate Gradient?
Explore Conjugate Gradient: Algorithm Description, Variants, Applications and Limitations.
Other Articles on the Topic of Reinforcement Learning
- This interesting video shows how to teach artificial intelligence to park a car using Reinforcement Learning.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.