Als Datenbank bezeichnet man eine organisierte und strukturierte Sammlung von Informationen, die im Normalfall in einem Computersystem gespeichert sind (Quelle: Oracle). Der Betrieb und die Verwaltung der Datenbank erfolgt meist in einem Datenbankmanagementsystem (DBMS).
Was versteht man unter einer relationalen Datenbank?
In einer Datenbank werden große Datenmengen meist strukturiert abgespeichert und zur Abfrage verfügbar gemacht. Es handelt sich dabei nahezu immer um ein elektronisches System. Theoretisch handelt es sich jedoch auch bei analogen Informationssammlungen, wie beispielsweise bei einer Bibliothek, um eine Datenbank.
Bereits in den 1960er Jahren entstand die Notwendigkeit für zentrale Datenspeicher, da Dinge, wie die Zugriffsberechtigung auf Daten oder die Datenprüfung, nicht innerhalb einer Anwendungen, sondern gesondert davon erfolgen sollten.
Was ist ein DBMS?
Datenbanken bestehen aus zwei großen Komponenten. Zum einen der tatsächliche Datenspeicher und zum anderen das sogenannten Datenbankmanagementsystem (kurz: DBMS). Es fungiert einfach gesagt als Schnittstelle zwischen den Daten und den Endnutzern. MySQL ist ein Beispiel für ein konkretes DBMS von Oracle.
Zu den zentralen Aufgaben eines DBMS zählen beispielsweise:
- Speicherung, Änderung und das Löschen von Daten
- Definition und Einhaltung des Datenmodells
- Hinzufügen von Nutzern und Anlegen der entsprechenden Rechte
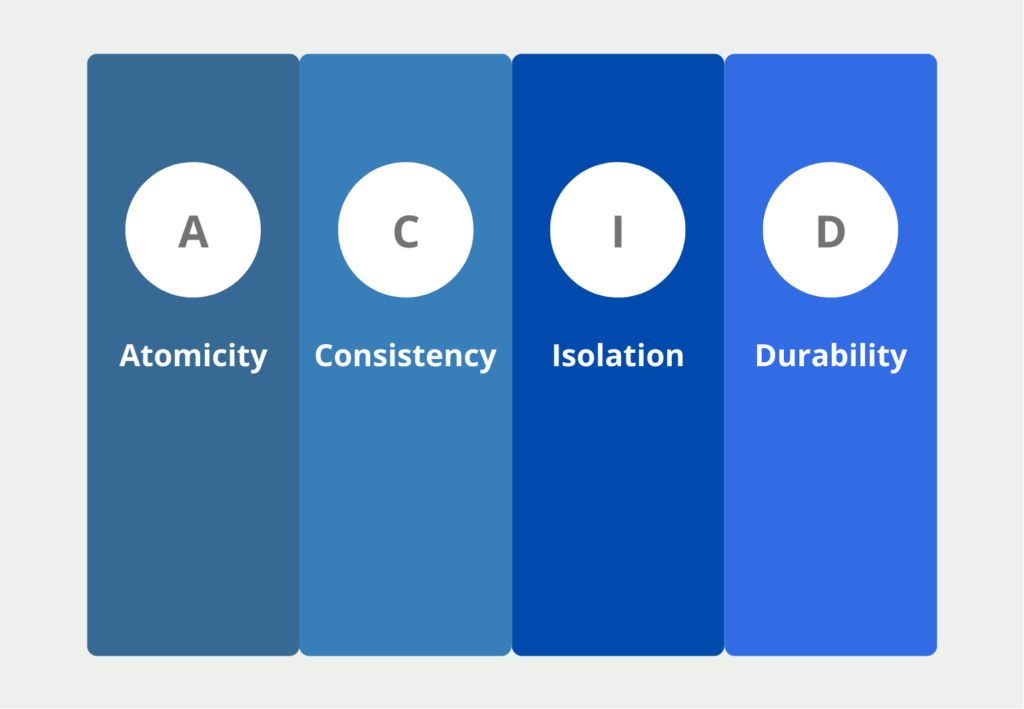
Dieses Managementsystem sorgt weiterhin dafür, dass die sogenannten ACID Eigenschaften innerhalb des Datenspeichers eingehalten werden. Diese umfassen die folgenden Punkte:
- Atomicity (A): Datentransaktionen, bspw. die Eintragung eines neuen Datensatzes oder das Löschen eines alten, sollen entweder ganz oder gar nicht ausgeführt werden. Für andere User ist die Transaktion erst sichtbar, wenn sie vollständig ausgeführt ist. In der Datenbank eines Finanzinstitutes beispielsweise wird die Überweisung von einem Konto auf ein anderes erst sichtbar wenn die Transaktion in beiden Tabellen vollständig ausgeführt ist.
- Consistency (C): Diese Eigenschaft ist erfüllt, wenn jede Datentransaktion den Datenspeicher von einem konsistenten in einen konsistenten Zustand überführt.
- Isolation (I): Wenn mehrere Transaktionen gleichzeitig stattfinden, muss der Endzustand derselbe sein, als wenn die Transaktionen getrennt voneinander stattfinden würden. Das heißt die Datenbank sollte den Stresstest bestehen. Also nicht durch Überlastung zu falschen Datenbanktransaktionen kommen.
- Durability (D): Die Daten dürfen sich nur durch eine Transaktion ändern und nicht durch äußere Einflüsse veränderbar sein. Ein Softwareupdate darf beispielsweise nicht versehentlich dazu führen, dass sich Daten ändern oder womöglich gelöscht werden.
Welche Arten von Datenbanken gibt es?
Es gibt viele verschiedene Arten von Datensammlungen, die auch vor allem von der Nutzungsart innerhalb einer Organisation oder eines Unternehmens abhängig sind. Dabei spielen verschiedene Einflussfaktoren eine Rolle, wie beispielsweise die Anzahl der potenziellen Nutzer und Datenabfragen, sowie die Art der Daten, die abgespeichert werden sollen:
- Relationale Datenbanken: Hierin werden Daten abgespeichert, die sich in einem tabellarischen Format, also mit Zeilen und Spalten, abspeichern lassen.
- Verteilte Datenbanken: Wenn die Daten auf mehreren verschiedenen Computern abgelegt weren sollen, spricht man von verteilten Datenbanken. Dies bietet sich beispielsweise dann an, wenn man die Datensammlung ausfallsicher machen will oder viele Datenabfragen bewältigen soll.
- Data Warehouse: Wenn Daten innerhalb eines Unternehmens zentral zugänglich sein sollen, spricht man von einem Data Warehouse. Hierin werden Daten aus verschiedenen Quellsystemen abgelegt und ein einheitliches Datenformt gebracht.
- NoSQL Datenbank: Wenn die zu speichernden Daten nicht einem relationalen Schema entsprechen, beispielsweise bei unstrukturierten Daten, werden diese in sogenannten NoSQL (“Not only SQL) Datensammlungen gespeichert.
Dies sind nur einige wenige der gängigsten Datenbanktypen. Über die Zeit haben sich hieraus noch deutlich mehr Arten herausgebildet, auf die wir in diesem Artikel jedoch nicht im Detail eingehen können.
Vor welchen Herausforderungen stehen Datenbanken?
Wenn große Data Warehouses in Unternehmen eingeführt werden, haben die Administratoren mit verschiedensten Herausforderungen zu kämpfen. Die folgenden Punkte sollten bereits bei der Erstellung der Datensammlung beachtet werden:
- Möglichkeit zur Steigerung der Datenmenge: Aufgrund der immer wachsenden Menge an Daten, die innerhalb eines Unternehmens anfallen und gespeichert werden sollen, muss das System genügend Ressourcen aufweisen zur Erweiterung der Datenmenge.
- Datensicherheit: Wenn teilweise vertrauliche Informationen an einem zentralen Ort vorliegen, bieten sie natürlich Angriffsfläche für unerlaubte Zugriffe. Dazu zählt nicht nur die Sicherung vor Zugriffen von außen, sondern auch die Verteilung von Berechtigungen für Benutzer innerhalb der Organisation.
- Skalierungsmöglichkeiten: Wenn ein Unternehmen wächst, wächst natürlich auch die Menge der Informationen. Darauf sollte die Datenbanklösung vorbereitet und in der Lage sein, mehr Nutzerabfragen und Daten verarbeiten zu können.
- Datenaktualität: In der heutigen Zeit sind wir es gewohnt, Informationen ohne zeitlichen Verzug zu erhalten, gleiches gilt natürlich auch für Datenspeicher. Deshalb müssen Architekturen aufgebaut werden, die Informationen so schnell wie möglich verarbeiten und zur Verfügung stellen.
Was ist die Structured Query Language?
Die Structured Query Language (SQL) ist die am häufigsten genutzte Sprache bei der Arbeit mit relationalen Datenbanken. Die Sprache ist für weit mehr nutzbar als simple Abfragen, trotz des Namens. Damit können auch alle Operationen durchgeführt werden, die zur Erstellung und Instandhaltung von Datensammlungen nötig sind.
Die strukturierte Abfragesprache bietet viele Funktionen, um Daten zu lesen, zu verändern oder zu löschen. Sie kommt eigentlich in allen gängigen relationalen Datenbanksystemen zum Einsatz und ist weit verbreitet. Darüber hinaus bieten auch nicht-relationale Systeme Erweiterungen an, sodass die Abfragesprache auch trotz der nicht-tabellarischen Anordnung der Daten nutzbar ist. Dies liegt wahrscheinlich an den zahlreichen Vorteilen, die SQL bietet:
- Es ist semantisch sehr einfach zu lesen und zu verstehen. Die Befehle können auch von Anfängern weitestgehend verstanden werden.
- Die Sprache kann direkt innerhalb der Datenbankumgebung genutzt werden. Zur grundlegenden Arbeit mit Informationen müssen die Daten nicht erst aus der Sammlung in ein anderes Tool überführt werden. Einfache Berechnungen und Abfragen sind direkt in der Datensammlung möglich.
- Verglichen mit anderen Tabellentools, wie beispielsweise Excel, können Datenanalysen mit der Structured Query Language einfach repliziert und kopiert werden, da alle Zugriff auf die gleichen Daten in der Sammlung haben. Somit führt dieselbe Abfrage auch immer zum gleichen Ergebnis.
Wie wird die Sicherheit gewährleistet?
Die Aufrechterhaltung der Datenbanksicherheit ist entscheidend für den Schutz sensibler Daten vor unbefugtem Zugriff, Diebstahl oder Beschädigung. Im Folgenden finden Sie einige bewährte Verfahren zur Aufrechterhaltung der Datenbanksicherheit:
- Implementierung einer strengen Zugriffskontrolle: Die Zugriffskontrolle ist die erste Verteidigungslinie gegen unbefugten Zugriff. Durch die Implementierung strenger Zugriffskontrollmaßnahmen wie Authentifizierung, Autorisierung und rollenbasierte Zugriffskontrolle (RBAC) kann sichergestellt werden, dass nur autorisierte Benutzer Zugriff auf die Datenbank haben.
- Verwendung einer Verschlüsselung: Die Verschlüsselung sensibler Daten im Ruhezustand und bei der Übertragung kann helfen, sie vor unberechtigtem Zugriff zu schützen. Durch die Implementierung von Verschlüsselungstechniken wie Advanced Encryption Standard (AES) und Transport Layer Security (TLS) kann sichergestellt werden, dass sensible Daten auch dann geschützt sind, wenn sie gestohlen oder abgefangen werden.
- Regelmäßig Software aktualisieren und patchen: Wenn Sie die Software auf dem neuesten Stand halten und mit Patches versehen, können Sie bekannte Schwachstellen beheben und Angriffe verhindern, die diese Schwachstellen ausnutzen. Es ist wichtig, regelmäßig nach Updates und Patches für die Datenbanksoftware zu suchen und diese umgehend zu installieren.
- Verwendung sicherer Passwörter: Schwache Passwörter sind ein häufiger Einstiegspunkt für Angreifer, um sich Zugang zu einer Datenbank zu verschaffen. Die Durchsetzung von Richtlinien für sichere Passwörter und die Verwendung von Multi-Faktor-Authentifizierung (MFA) können dazu beitragen, dass nur autorisierte Benutzer Zugriff auf die Datenbank haben.
- Überwachung auf verdächtige Aktivitäten: Die Überwachung des Systems auf verdächtige Aktivitäten wie fehlgeschlagene Anmeldeversuche, ungewöhnliche Abfragen und Datenzugriffsmuster kann helfen, Angriffe zu erkennen und zu verhindern. Die Implementierung von Tools wie Intrusion Detection Systems (IDS) und Security Information and Event Management (SIEM) kann bei der Überwachung und Analyse von Aktivitäten in der Datenbank helfen.
- Regelmäßige Datensicherung: Regelmäßige Backups der Datenbank können sicherstellen, dass die Daten im Falle eines Sicherheitsverstoßes oder einer anderen Katastrophe nicht verloren gehen. Die Backups sollten an einem sicheren Ort aufbewahrt und regelmäßig getestet werden, um sicherzustellen, dass sie bei Bedarf wiederhergestellt werden können.
Insgesamt erfordert die Aufrechterhaltung der Datenbanksicherheit eine Kombination aus technischen und verfahrenstechnischen Maßnahmen, um sensible Daten vor unbefugtem Zugriff oder Diebstahl zu schützen. Es ist wichtig, einen mehrschichtigen Sicherheitsansatz zu implementieren, der Zugangskontrolle, Verschlüsselung, Software-Updates, sichere Passwörter, Überwachung und Backups umfasst. Regelmäßige Tests und Überprüfungen der Sicherheitsmaßnahmen können dazu beitragen, dass die Datenbank sicher und vor potenziellen Bedrohungen geschützt ist.
Das solltest Du mitnehmen
- Eine Datenbank ist eine zur organisierten und strukturierten Sammlung von Informationen.
- Das relationale Speichersystem ist kommt noch am Häufigsten vor. Daneben werden aber auch NoSQL Lösungen oder Data Warehouses immer beliebter.
- Bei der Erstellung solcher Datensammlungen gilt es viele, verschiedene Herausforderungen, wie beispielsweise die Skalierungsmöglichkeiten oder die Datensicherheit, zu beachten.
- Zur Abfrage und Instandhaltung wird in vielen Fällen immer noch auf die Structured Query Language (SQL) zurückgegriffen.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Datenbank
- Eine ausführliche Themenseite findest Du bei Oracle, von denen beispielsweise das bekannte DBMS namens “MySQL” stammt.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.