In der Welt der Datenanalyse sind fehlende Werte eine häufige Herausforderung, die genaue Einblicke und Entscheidungen behindern kann. Die Imputation von Daten, eine Technik zum Auffüllen fehlender Werte, spielt eine entscheidende Rolle bei der Verbesserung der Datenqualität und der Gewährleistung robuster Analysen.
In diesem Artikel werden das Konzept der Datenimputation, seine Bedeutung und die verschiedenen Methoden zum Auffüllen fehlender Daten erläutert, um Analysten in die Lage zu versetzen, fundierte Entscheidungen im Umgang mit unvollständigen Datensätzen zu treffen.
Warum sind fehlende Werte ein Problem beim maschinellen Lernen?
Fehlende Werte beim maschinellen Lernen sind ein häufiges Problem, das zu verzerrten oder ungenauen Ergebnissen führen kann. Wenn Daten fehlende Werte enthalten, kann dies die Fähigkeit von Algorithmen des maschinellen Lernens beeinträchtigen, die Beziehungen zwischen Variablen genau zu modellieren, was zu Fehlern in den Vorhersagen und einer geringeren Modellleistung führt. Im Folgenden werden einige der Hauptgründe genannt, warum fehlende Werte beim maschinellen Lernen ein Problem darstellen:
- Geringerer Stichprobenumfang: Fehlende Werte verringern den effektiven Stichprobenumfang des Datensatzes, was zu einer Verringerung der statistischen Aussagekraft und potenziell verzerrten Schätzungen führt. Dies liegt daran, dass die fehlenden Daten möglicherweise nicht zufällig sind, sondern in einem systematischen Zusammenhang mit anderen Variablen im Datensatz stehen.
- Verzerrung der Schätzungen: Wenn fehlende Werte nicht zufällig fehlen (MNAR), was bedeutet, dass die Fehlenden von dem unbeobachteten Wert selbst abhängen, können Schätzungen, die auf den beobachteten Daten basieren, verzerrt sein. Dies kann z. B. der Fall sein, wenn Teilnehmer, die ihr Einkommen nicht angeben wollen, auch ihren Beruf nicht angeben, was zu einer Überrepräsentation von Personen mit niedrigem Einkommen in den beobachteten Daten führt.
- Fehler bei Vorhersagen: Fehlende Werte können zu Fehlern in den Vorhersagen führen, wenn sie in der Zielvariablen oder den Prädiktoren auftreten. In einem Modell zur Vorhersage von Immobilienpreisen könnten fehlende Daten über die Quadratmeterzahl einer Immobilie beispielsweise zu einer erheblichen Unterschätzung des Immobilienwerts führen.
- Unvollständige Datensätze: Unvollständige Datensätze können ebenfalls zu unvollständigen oder fehlerhaften Schlussfolgerungen führen. Dies ist besonders problematisch, wenn die fehlenden Daten nicht zufällig fehlen, was zu verzerrten Schlussfolgerungen über die Beziehungen zwischen den Variablen führen kann.
- Beschränkungen beim Feature Engineering: Beim Feature Engineering werden aus den vorhandenen Daten neue Merkmale erstellt, um die Leistung von Algorithmen für maschinelles Lernen zu verbessern. Fehlende Daten können die Fähigkeit einschränken, sinnvolle neue Merkmale zu erstellen, was die Leistung des Modells verringert.
Zusammenfassend lässt sich sagen, dass fehlende Werte ein Problem darstellen, da sie den Stichprobenumfang verringern, die Schätzungen verzerren, zu Fehlern bei den Vorhersagen führen und die Fähigkeit zur Erstellung neuer Merkmale einschränken. Praktiker im Bereich des maschinellen Lernens müssen die Art der fehlenden Daten sorgfältig berücksichtigen und geeignete Imputationsverfahren anwenden, um das Problem zu lösen und die Genauigkeit ihrer Modelle zu verbessern.
Was sind die verschiedenen Arten der Imputation?
Es gibt verschiedene Arten von Imputationsmethoden, die jeweils eigene Annahmen, Vorteile und Einschränkungen haben. Die Wahl der Imputationsmethode hängt von der Art der fehlenden Daten, der Forschungsfrage und den Merkmalen des Datensatzes ab. Hier sind einige der am häufigsten verwendeten Imputationsmethoden:
- Mittelwert-Imputation: Bei diesem Typ werden fehlende Werte durch den Mittelwert der beobachteten Daten für die betreffende Variable ersetzt. Diese Methode ist einfach zu implementieren, kann aber zu verzerrten Schätzungen führen, wenn die fehlenden Werte nicht zufällig fehlen oder wenn eine große Menge an fehlenden Daten vorhanden ist.
- Hotdeck-Imputation: Bei dieser Methode werden fehlende Werte durch den Wert des nächstgelegenen beobachteten Datenpunkts auf der Grundlage eines Satzes von übereinstimmenden Variablen ersetzt. Bei dieser Methode bleiben die Korrelationen zwischen den Variablen erhalten und das Problem der Imputation des Mittelwerts wird vermieden, sie erfordert jedoch mehr Rechenressourcen und kann empfindlich auf die Wahl der passenden Variablen reagieren.
- Cold-Deck-Imputation: Bei dieser Methode werden fehlende Werte durch Werte aus einer externen Datenquelle, z. B. einem Referenzdatensatz, ersetzt. Diese Methode ist nützlich, wenn die externe Datenquelle ähnliche Merkmale wie der Zieldatensatz aufweist. Sie ist jedoch möglicherweise nicht anwendbar, wenn die externe Datenquelle nicht verfügbar ist oder wenn sich die Merkmale des Referenzdatensatzes erheblich vom Zieldatensatz unterscheiden.
- Regressions-Imputation: Bei der Regressionsimputation wird ein Regressionsmodell verwendet, um die fehlenden Werte auf der Grundlage der beobachteten Daten und anderer Variablen, die mit den fehlenden Werten korreliert sind, zu schätzen. Diese Methode kann komplexe Beziehungen zwischen Variablen erfassen und zu weniger verzerrten Schätzungen führen als die Imputation von Mittelwerten, erfordert jedoch ein umfassendes Verständnis der zugrunde liegenden Beziehungen zwischen Variablen und kann empfindlich sein.
- Mehrfache Imputationen: Bei dieser Methode werden mehrere vollständige Datensätze durch Imputation der fehlenden Werte mit Hilfe einer modellbasierten Methode erstellt. Jeder Datensatz wird dann separat analysiert, und die Ergebnisse werden kombiniert, um eine endgültige Schätzung zu erhalten, die die Unsicherheit im Imputationsprozess berücksichtigt. Diese Methode gilt im Allgemeinen als der Goldstandard für die Datenimputation, da sie unverzerrte Schätzungen und gültige Standardfehler liefert. Sie kann jedoch rechenintensiv sein und erfordert möglicherweise einen größeren Stichprobenumfang, um genaue Schätzungen zu erhalten.
Zusammenfassend lässt sich sagen, dass es verschiedene Arten von Datenimputationsmethoden gibt, die jeweils ihre eigenen Stärken und Grenzen haben. Die Wahl der Methode hängt von der Art der fehlenden Daten und der Forschungsfrage ab, und es ist wichtig, bei der Auswahl eines geeigneten Ansatzes die Annahmen und Grenzen der einzelnen Methoden sorgfältig zu berücksichtigen.
Was sind die Vor- und Nachteile der Imputation?
Die Imputation von Daten ist eine in der Datenanalyse und im maschinellen Lernen weit verbreitete Technik, bei der fehlende Werte in einem Datensatz durch geschätzte Werte ersetzt werden. Die Imputation von Daten hat zwar viele Vorteile, aber auch einige Nachteile, die bei der Entscheidung, ob sie eingesetzt werden soll, beachtet werden sollten. Hier sind einige der wichtigsten Vor- und Nachteile:
Vorteile der Datenimputation:
- Verbessert die statistische Aussagekraft: Sie kann die statistische Aussagekraft eines Datensatzes verbessern, indem sie die effektive Stichprobengröße erhöht, was zu genaueren und zuverlässigeren statistischen Schlussfolgerungen führen kann.
- Erhält die Beziehungen zwischen den Variablen: Diese Methoden können die Beziehungen zwischen den Variablen in einem Datensatz erhalten, was dazu beitragen kann, Verzerrungen zu vermeiden und die Genauigkeit der Vorhersagemodelle zu verbessern.
- Kann Verzerrungen reduzieren: Sie können dazu beitragen, Verzerrungen bei Schätzungen zu verringern, wenn die fehlenden Daten nicht zufällig fehlen, indem sie Informationen aus anderen Variablen einbeziehen, die mit den fehlenden Werten in Beziehung stehen.
- Liefert vollständigere Datensätze: Die Technik kann zu vollständigeren Datensätzen führen, die für explorative Datenanalysen, Modellierung und andere Anwendungen nützlich sein können.
Nachteile der Imputation von Daten:
- Kann zu Verzerrungen führen: Es kann zu Verzerrungen bei den Schätzungen kommen, wenn die Imputationsmethode nicht angemessen ist oder wenn die fehlenden Daten nicht zufällig fehlen.
- Unsicherheit in den Schätzungen: Sie führt zu Unsicherheiten in den Schätzungen, die die Genauigkeit der statistischen Schlussfolgerungen und Vorhersagemodelle beeinträchtigen können.
- Erfordert Annahmen: Die Technik erfordert Annahmen über die Verteilung der Daten und die Art der fehlenden Daten, die in der Praxis schwer zu überprüfen sein können.
- Sie ist möglicherweise nicht für alle Datensätze geeignet: Sie eignet sich möglicherweise nicht für Datensätze mit einem großen Anteil an fehlenden Daten oder wenn die fehlenden Daten nicht ignorierbar sind.
Zusammenfassend lässt sich sagen, dass die Imputation von Daten viele Vorteile hat, darunter eine verbesserte statistische Aussagekraft, erhaltene Beziehungen zwischen den Variablen und vollständigere Datensätze. Sie hat jedoch auch einige Nachteile, darunter das Potenzial für Verzerrungen, Unsicherheiten bei den Schätzungen, die Notwendigkeit von Annahmen und ihre Ungeeignetheit für bestimmte Datensätze. Eine sorgfältige Abwägung dieser Faktoren ist unerlässlich, wenn entschieden wird, ob die Datenimputation in einer bestimmten Analyse verwendet werden soll.
Welche Herausforderungen können beim Ersetzen fehlender Werte auftreten?
Die Imputation von Daten ist eine in der Datenanalyse und beim maschinellen Lernen häufig verwendete Technik zur Behandlung fehlender Daten. Es gibt jedoch mehrere Herausforderungen, die überwunden werden müssen, um sicherzustellen, dass die imputierten Daten genau und zuverlässig sind.
Eine der größten Herausforderungen ist der Umgang mit fehlenden Datenmustern. Verschiedene Arten von fehlenden Datenmustern können unterschiedliche Techniken erfordern, und die Auswahl der geeigneten Technik kann eine Herausforderung darstellen. Wenn beispielsweise fehlende Daten völlig zufällig sind (MCAR), können einfache Techniken wie die Imputation des Mittelwerts oder die Übertragung der letzten Beobachtung (LOCF) angemessen sein. Sind die fehlenden Daten jedoch nicht zufällig (MNAR), können komplexere Techniken wie Regressionsimputation oder Mehrfachimputation erforderlich sein.
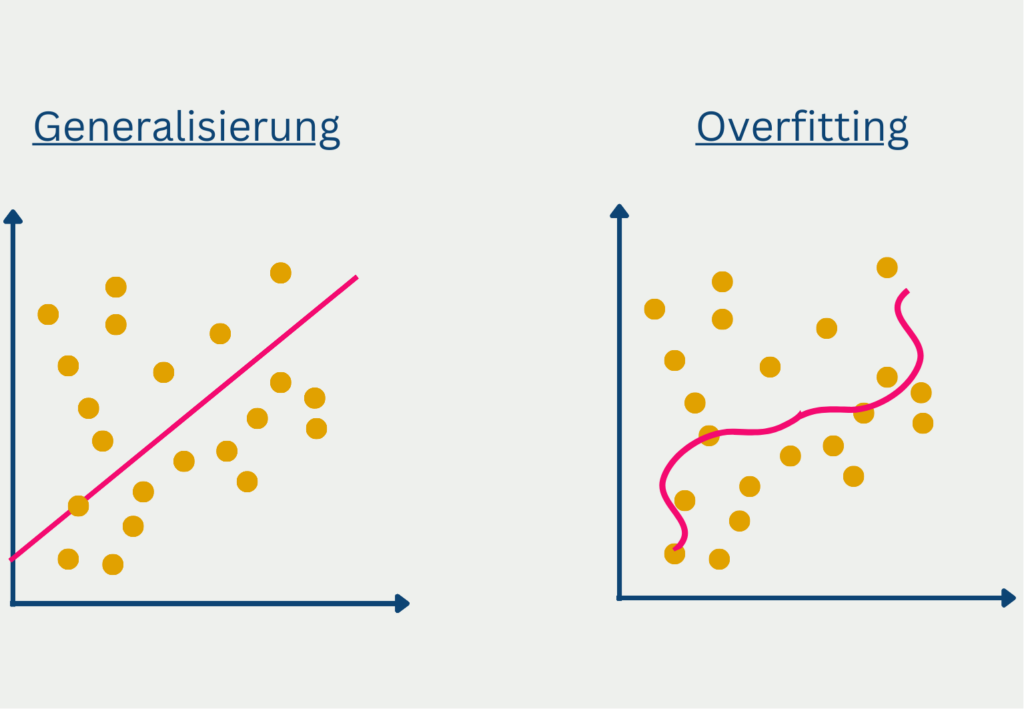
Eine weitere Herausforderung besteht darin, eine Über– oder Unteranpassung der Modelle zu vermeiden. Eine Überanpassung liegt vor, wenn ein Modell zu komplex ist und dem Rauschen in den Daten entspricht, während eine Unteranpassung vorliegt, wenn ein Modell zu einfach ist und die wahre Beziehung zwischen den Variablen nicht erfasst. Dies kann zu ungenauen Imputationsergebnissen und verzerrten Schätzungen führen. Um Overfitting oder Underfitting zu vermeiden, können Techniken wie die Kreuzvalidierung eingesetzt werden, um die Leistung verschiedener Modelle zu bewerten.
Die Interpretation der imputierten Daten kann ebenfalls eine Herausforderung darstellen. Bei den imputierten Werten handelt es sich um Schätzungen und nicht um wahre Werte, und sie können Verzerrungen oder Unsicherheiten in nachgelagerte Analysen einbringen. Es ist wichtig, die Qualität der imputierten Daten anhand von Metriken wie dem mittleren quadratischen Fehler oder Korrelationskoeffizienten zu bewerten und den Prozess transparent zu machen.
Trotz dieser Herausforderungen hat die Imputation von Daten viele Vorteile und kann zu genaueren und zuverlässigeren Analysen führen. Um die damit verbundenen Herausforderungen zu meistern, ist es wichtig, die Art der fehlenden Daten sorgfältig zu berücksichtigen und geeignete Techniken anzuwenden, die für den spezifischen Datensatz und die Forschungsfrage geeignet sind. Mit Hilfe der explorativen Datenanalyse lassen sich Muster in den fehlenden Daten erkennen, und Techniken wie die Kreuzvalidierung können verwendet werden, um eine Über- oder Unteranpassung der Modelle zu vermeiden. Letztendlich sollte die Wahl der Technik von einer sorgfältigen Abwägung der Stärken und Schwächen der einzelnen Methoden und ihrer Eignung für den spezifischen Datensatz und die Forschungsfrage bestimmt werden.
Das solltest Du mitnehmen
- Die Imputation von Daten ist eine nützliche Technik zur Behandlung fehlender Daten in Datensätzen.
- Sie kann die statistische Aussagekraft verbessern, Beziehungen zwischen Variablen erhalten und vollständigere Datensätze liefern.
- Die Imputation von Daten kann jedoch auch zu Verzerrungen und Unsicherheiten bei den Schätzungen führen.
- Sie erfordert Annahmen über die Verteilung der Daten und die Art der fehlenden Daten.
- Die Datenimputation eignet sich möglicherweise nicht für Datensätze mit einem großen Anteil fehlender Daten oder wenn die fehlenden Daten nicht ignorierbar sind.
- Um die Datenimputation effektiv zu nutzen, ist es wichtig, die Art der fehlenden Daten sorgfältig zu berücksichtigen und geeignete Imputationsverfahren zu verwenden, die für den spezifischen Datensatz und die Forschungsfrage geeignet sind.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!

Was ist die Bivariate Analyse?
Nutzen Sie die Bivariate Analyse: Erforschen Sie Typen und Streudiagramme und nutzen Sie Korrelation und Regression.
Andere Beiträge zum Thema der Datenimputation
Die Scikit-Learn-Dokumentation bietet Anleitungen zur praktischen Durchführung von Datenimputationen in Python.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.