NoSQL (“Not Only SQL”) beschreibt Datenbanken, welche im Gegensatz zu SQL nicht-relational sind, also unter anderem nicht in Tabellen organisiert werden können. Diese Ansätze lassen sich auch über verschiedene Computersysteme verteilen und sind dadurch höchst skalierbar. NoSQL Lösungen sind deshalb sehr interessant für viele Big Data Anwendungen.
Die Datenbanken zeichnen sich vor allem durch zwei Kriterien aus, die sehr weit gefasst sind. Zum einen werden Daten nicht in Tabellen gespeichert und zum anderen ist die Abfragesprache nicht SQL, was auch durch den Namen Not Only SQL deutlich wird.
Was sind die Vorteile von NoSQL Lösungen?
Diese Datenbanksysteme bieten einige Vorteile gegenüber traditionellen SQL Lösungen, die im Big Data Umfeld ausschlaggebend sind. Die folgenden Faktoren sind in nahezu allen NoSQL Datenbanken umgesetzt:
- Wir können NoSQL-Datenbanken höher skalieren als vergleichbare relationale Datenspeicher, da diese Systeme gekennzeichnet sind durch eine sehr schnelle Datenverarbeitung, auch deshalb, weil sie keine so hohen Ansprüche an Datenschemata haben und somit die Daten schneller speichern können.
- Die meisten NoSQL-Datenbanken sind Open-Source und können somit (bis auf die Speicherkapazität natürlich) komplett kostenlos genutzt werden, inklusive des Datenbankmanagements.
- In der Praxis gibt es verschiedene Datenabfragen, die herkömmliche relationale Datenbanken nicht oder nur mit sehr viel Aufwand unterstützen.
- Durch die niedrigen Ansprüche von NoSQL-Lösungen an das Datenschema sind diese nicht so restriktiv gegenüber dem Datenmodell. Eine relationale Datenstruktur hingegen kann das Datenmodell sehr stark einschränken.
ACID Eigenschaften von SQL Datenbanken
Klassische relationale Datenbanken erfüllen die vier sogenannten ACID Eigenschaften. Diese besagen, dass die wichtigste Anforderung an eine Datenbank ist, den Wahrheitsgehalt und die Aussagekraft der Daten zu erhalten. In vielen Fällen werden Datenspeicher als “Single Point of Truth” gesehen, somit wäre es fatal, wenn fehlerhafte Informationen gespeichert und weitergegeben werden. Die vier Eigenschaften umfassen folgende Punkte:
- Atomicity (A): Datentransaktionen, bspw. die Eintragung eines neuen Datensatzes oder das Löschen eines alten, sollen entweder ganz oder gar nicht ausgeführt werden. Für andere User ist die Transaktion erst sichtbar, wenn sie vollständig ausgeführt ist. In der Datenbank eines Finanzinstitutes beispielsweise wird die Überweisung von einem Konto auf ein anderes erst sichtbar wenn die Transaktion in beiden Tabellen vollständig ausgeführt ist.
- Consistency (C): Diese Eigenschaft ist erfüllt, wenn jede Datentransaktion die Datenbank von einem konsistenten in einen konsistenten Zustand überführt.
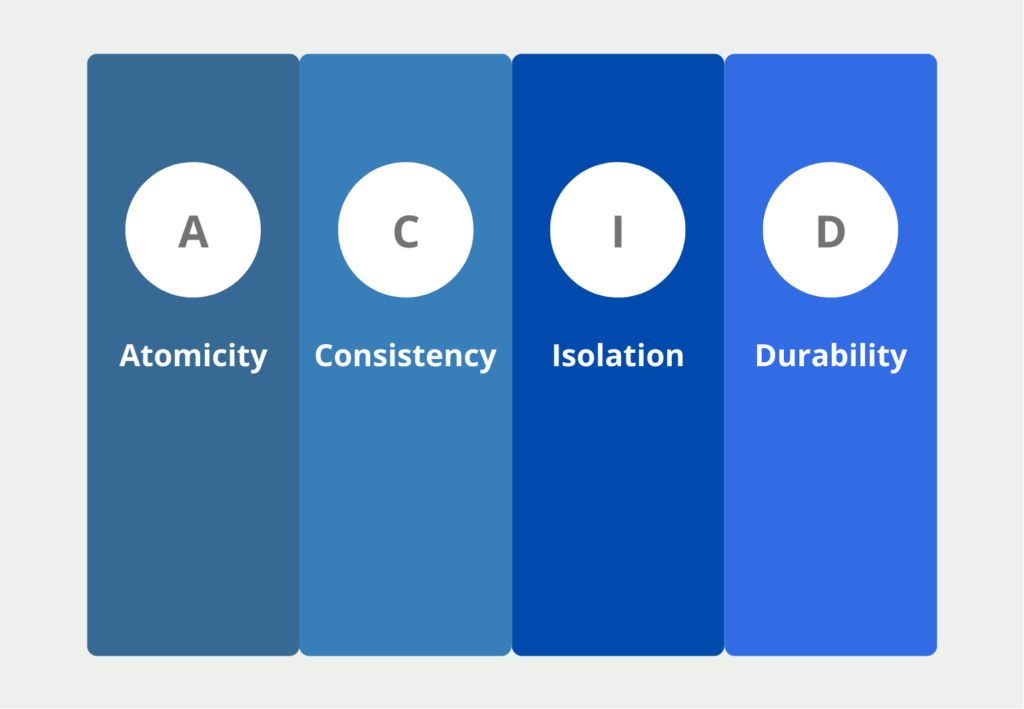
- Isolation (I): Wenn mehrere Transaktionen gleichzeitig stattfinden, muss der Endzustand derselbe sein, als wenn die Transaktionen getrennt voneinander stattfinden würden. Das heißt die Datenbank sollte den Stresstest bestehen. Also nicht durch Überlastung zu falschen Datenbanktransaktionen kommen.
- Durability (D): Die Daten innerhalb der Datenbank dürfen sich nur durch eine Transaktion ändern und nicht durch äußere Einflüsse veränderbar sein. Ein Softwareupdate darf beispielsweise nicht versehentlich dazu führen, dass sich Daten ändern oder womöglich gelöscht werden.
Erfüllt NoSQL die ACID Eigenschaften?
NoSQL Lösungen können generell die ACID Eigenschaften nicht einhalten, obwohl es Ausnahmen gibt, wie beispielsweise die Graphdatenbanken, die alle Konzepte erfüllen. NoSQL Datenbanken werden in vielen Fällen über mehrere Geräte und Server verteilt. Dadurch können deutlich größere Datenmengen gleichzeitig verarbeitet und gespeichert werden, was eine Hauptanforderung an diese Systeme ist. Dadurch erfüllen sie jedoch die Eigenschaft der Konsistenz nicht.
Angenommen wir haben eine NoSQL Datenbank auf zwei physischen Servern realisiert, von denen einer in Deutschland und der andere in den USA steht. Die Datenbanken enthalten die Kontostände und -transaktionen von deutschen und amerikanischen Kunden. Dabei sind die deutschen Konten in Deutschland und die amerikanischen Konten auf dem amerikanischen Server gespeichert.
Es kann nun zu Fall kommen, dass ein deutscher Kunde eine Überweisung auf ein amerikanisches Konto vornimmt. Dann werden beide Datenspeicher verändert und sind in diesem Bearbeitungszeitraum inkonsistent. Es kann beispielsweise zu dem Fall kommen, dass wir eine Datenbankabfrage starten während die Verarbeitung in Deutschland bereits abgeschlossen ist, aber die in den USA noch nicht. In diesem Zeitfenster, dem “Inconsistency Window”, stimmen die Daten in der Datenbank nicht und sind inkonsistent. So etwas würde in einer relationalen Datenbank nicht vorkommen.
Welche verschiedenen NoSQL Kategorien gibt es?
NoSQL Lösungen lassen sich in eine der vier Kategorien einteilen:
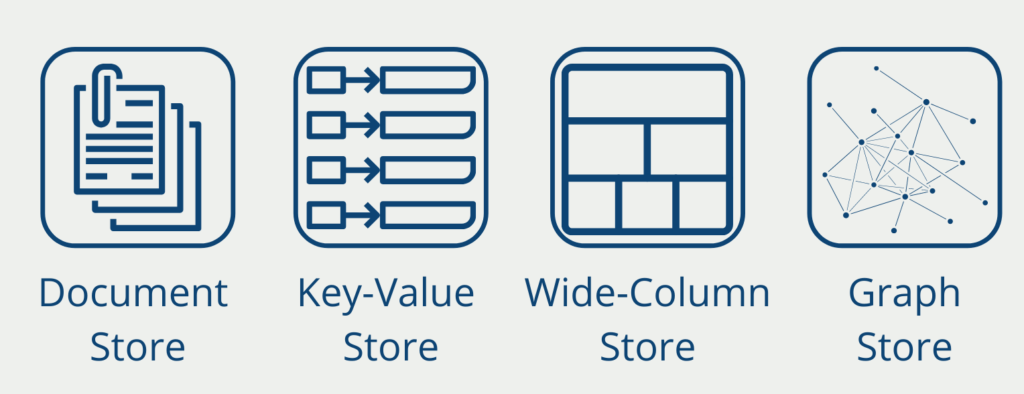
- Document Stores speichern eine Vielzahl von Informationen innerhalb eines Dokumentes. Ein Dokument könnte beispielsweise alle Daten eines Tages enthalten.
- Key-Value Store sind eine sehr einfach Datenstruktur in der jeder Datensatz als Wert mit einem einzigartigen Schlüssel abgespeichert ist. Über diesen Schlüssel können die Informationen gezielt abgefragt werden.
- Wide-Column Store speichern einen Datensatz in einer Spalte ab und nicht wie sonst in einer Zeile. Sie sind dafür optimiert worden schnell Daten in großen Datensätzen zu finden.
- Graphdatenbanken speichern Informationen in sogenannten Knoten und Kanten ab. Dadurch lassen sich beispielsweise soziale Netzwerke sehr gut darstellen, in denen die Personen einzelne Knoten sind und die Beziehung untereinander als Kante dargestellt werden.
Welche Beispiele für Not Only SQL Datenbanken gibt es?
Die bekanntesten Beispiele von NoSQL-Datenbanken sind Apache Cassandra, MongoDB, Redis oder Neo4j. Diese gehören auch den verschiedenen NoSQL Datenbankkategorien an:
- MongoDB gehört den Document Stores an. Die einzelnen Datensätze werden in sogenannten Dokumenten abgespeichert, wobei man sich einen Datensatz, wie eine Zeile in einer relationalen Datenbank vorstellen kann. Alle Dokumente mit einem vergleichbaren Aufbau werden in den sogenannten Collections zusammengefasst, welche wiederum mit einer Datenbank im relationalen Umfeld vergleichbar sind.
- Redis ist ein Key-Value Store, der vor allem mit Streaming Lösungen, wie Apache Kafka, genutzt wird. Darin werden Echtzeit-Daten zwischengespeichert und für Analysen oder Berechnungen zur Verfügung gestellt. Durch die sehr kurzen Latenzzeiten bietet es die optimale Lösung für Chats, Spiele oder Caching Anwendungen.
- Apache Cassandra ist ein Open-Source Wide-Column Store. Diese Lösung ist dafür gemacht, große Datenmengen auf verteilten Systemen zu speichern und dadurch eine hohe Erreichbarkeit zu gewährleisten.
- Neo4j ist eine Graphdatenbank, die bis zu einem gewissen Grad kostenlos genutzt werden. Mithilfe von Knoten und Kanten lassen sich beispielsweise Knowledge Graphs organisieren oder soziale Netzwerke abbilden.
Warum benötigen wir NoSQL Datenbanken?
NoSQL Lösungen eignen sich vor allem dann, wenn die Vorteile dieser Datenbanken ein Hauptbestandteil der Anwendung sind. Die wichtigsten Faktoren in solchen Projekten sind meistens, dass man kein einheitliches Datenschema hat, eine sehr große Datenmenge erwartet wird, die man über verschiedene Systeme verteilen will und Daten sehr schnell verarbeitet werden müssen. In solchen Fällen nimmt man auch eine kurzzeitige Inkonsistenz der Informationen in Kauf.
Ein klassisches Beispiel hierfür sind Webbewegungsdaten, also alle Informationen, die wir über einen User sammeln, der sich auf unserer Website befindet. Bei einer etablierten Seite können hier sehr schnell viele Daten in kurzer Zeit anfallen, vor allem dann, wenn wir sehr granular die Aktionen des User tracken wollen. Gleichzeitig haben wir eine große und undurchschaubare Datenstruktur mit Logins, dem Besuch verschiedener Seiten und viele Buttons, welche potenziell geklickt werden können. In diesem Fall bietet es sich an auf eine Graphdatenbank zurückzugreifen, in der wir dieses Bewegungsmuster über die Kanten sehr gut nachzeichnen können.
Wie findet man die richtige NoSQL Datenbank?
Die Auswahl einer geeigneten NoSQL Datenbank hängt von verschiedenen Faktoren ab und nicht immer muss von einer klassischen relationalen Datenbank weggewechselt werden. Hier sind einige Punkte, die bei der Auswahl berücksichtigt werden sollten:
- Datenmodell: NoSQL Datenbanken gibt es für verschiedenste Datenmodelle, wie Dokument-, Schlüssel-Wert-, Spalten- der Graphdaten. Es sollte eine Datenbank gewählt werden, die zum eigenen Datenmodell passt, um die vollen Vorteile der Datenbank nutzen zu können.
- Skalierbarkeit: Not-Only SQL Datenbanken sind dafür bekannt, horizontal skalierbar zu sein, um auch bei großen Datenmengen und vielen Abfragen noch schnelle Antwortzeiten gewährleisten zu können. Vor der Einrichtung einer Datenbank sollte sich vergewissert werden, dass die Skalierbarkeit einfach möglich ist und vom eigenen Team und der Hardware ohne weiteres umgesetzt werden kann.
- Leistung: Je nach Art der Anwendung wird die Leistung einer Datenbank unterschiedlich bewertet. Bei der einen Anwendung, werden sehr häufig kleine Datenmengen in die Datenbank geschrieben, während bei anderen Anwendungen einmal am Tag große Mengen aufgenommen werden müssen. Vor Auswahl der Datenbank sollte der Leistungsumfang definiert werden, um eine möglichst passende Datenbank auszuwählen und anschließend zu prüfen, ob die Performance auch umgesetzt werden kann.
- Konsistenz: Abhängig von der Anforderung an die Datenkonsistenz schränkt sich die Auswahl an Datenbanken massiv ein. Bei der Wahl der NoSQL-Datenbank sollte berücksichtigt werden, welchen Konsistenzgrad die Daten aufweisen sollten, damit es zu keinen Problemen in der Praxis kommt.
- Dauerhaftigkeit: Im Bereich der Dauerhaftigkeit sollte bewertet werden, wie stark die Daten vor Verlust geschützt werden sollten. Dabei sollte geprüft werden, wie sich die Datenbank bei einem Systemausfall verhält und welche Daten anschließend wiederhergestellt werden.
- Einfachheit der Nutzung: Die Benutzerfreundlichkeit spielt auch eine wichtige Rolle bei der Auswahl einer geeigneten Datenbank. Es sollte darauf geachtet werden, wie selbstständig die Nutzer die neue Datenbank bedienen können und geprüft werden, ob möglicherweise Schulungen nötig sind. Bei der Graphdatenbank Neo4j beispielsweise wird eine eigene Abfragesprache genutzt, die möglicherweise nicht allen Nutzern geläufig ist. Außerdem sollte geprüft werden, wie sich die Datenbank an die bestehenden Systeme, beispielsweise über APIs, anbinden lässt.
- Kosten: Abschließend dürfen auch die Lizenz- und Nutzungskosten nicht vergessen werden, die über die Gesamtbetriebszeit entstehen können. Zusätzlich zu den reinen Nutzungskosten sollten hier auch Kosten für das Hosting und die Wartung mit berücksichtigt werden.
Wenn diese Faktoren bei der Auswahl einer NoSQL Datenbank berücksichtigt werden, lässt sich eine geeignete Datenbank für die jeweilige Anwendung finden und die wesentlichen Kriterien der Anwendung können erfüllt werden.
Das solltest Du mitnehmen
- NoSQL-Datenbanken sind eine beliebte Alternative zu herkömmlichen relationalen Datenbanken.
- Sie sind für die Verarbeitung großer Mengen unstrukturierter oder halbstrukturierter Daten konzipiert.
- NoSQL-Datenbanken bieten hohe Skalierbarkeit, Verfügbarkeit und Fehlertoleranz.
- Die Wahl der richtigen NoSQL-Datenbank hängt von dem spezifischen Anwendungsfall und Deinen Anforderungen ab.
- Zu den wichtigsten Faktoren, die zu berücksichtigen sind, gehören Datenmodellierung, Skalierbarkeit, Konsistenz, Verfügbarkeit und Sicherheit.
- Zu den beliebtesten NoSQL-Datenbanken gehören MongoDB, Cassandra, Couchbase, Redis und Amazon DynamoDB.
- Insgesamt bieten NoSQL-Datenbanken eine flexible und leistungsstarke Lösung für die Verwaltung großer und komplexer Datensätze, aber es ist wichtig, die richtige Datenbank für Ihre Anforderungen sorgfältig zu bewerten und auszuwählen.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema NoSQL
- Die bekanntesten Beispiele von NoSQL-Datenbanken sind Apache Cassandra, MongoDB, Redis oder Neo4j.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.