MongoDB ist eine Open-Source verfügbare, nichtrelationale Datenbanklösung, die zu den NoSQL Datenbanken gezählt wird und für Big Data Anwendungen genutzt werden kann. MongoDB wurde zum ersten Mal 2009 vorgestellt und arbeitet mit sogenannten Sammlungen und Dokumenten, welche wiederum verschiedene Schlüssel-Werte Paare beinhalten, die die Daten speichern.
Was sind NoSQL Datenbanken?
Das Prinzip von NoSQL (“Not only SQL”) kam zum ersten Mal Ende der 2000er Jahre auf und bezeichnet ganz allgemein alle Datenbanken, die Daten nicht in relationalen Tabellen speichern und deren Abfragesprache nicht SQL ist. Die bekanntesten Beispiele von NoSQL-Datenbanken, neben MongoDB, sind Apache Cassandra, Redis oder Neo4j.
NoSQL Datenbanken lassen sich durch ihren Aufbau deutlich höher skalieren als herkömmliche SQL Lösungen, da sie auch über verschiedene Systeme und Rechner verteilt werden können. Darüber hinaus sind die meisten Lösungen Open-Source verfügbar und ermöglichen Datenbankabfragen, die relationale Systeme nicht abdecken könnten.
NoSQL Lösungen lassen sich in eine der vier Kategorien einteilen:
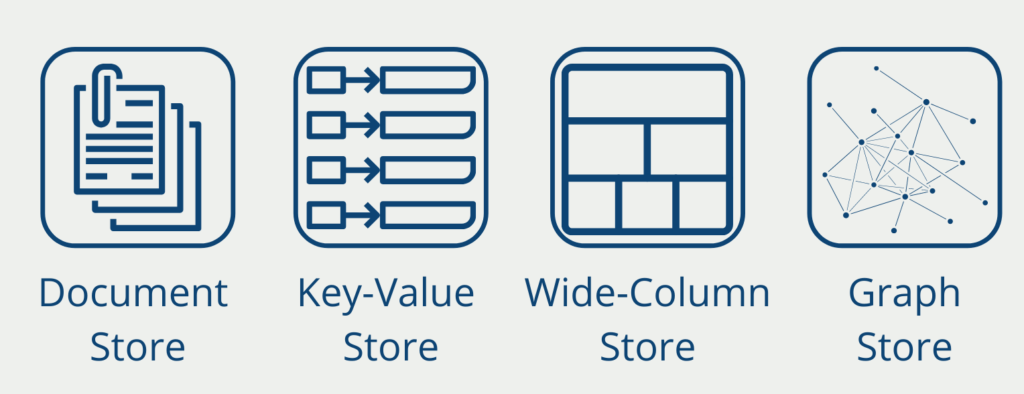
- Document Stores speichern eine Vielzahl von Informationen innerhalb eines Dokumentes. Ein Dokument könnte beispielsweise alle Daten eines Tages enthalten.
- Key-Value Store sind eine sehr einfach Datenstruktur in der jeder Datensatz als Wert mit einem einzigartigen Schlüssel abgespeichert ist. Über diesen Schlüssel können die Informationen gezielt abgefragt werden.
- Wide-Column Store speichern einen Datensatz in einer Spalte ab und nicht wie sonst in einer Zeile. Sie sind dafür optimiert worden schnell Daten in großen Datensätzen zu finden.
- Graphdatenbanken speichern Informationen in sogenannten Knoten und Kanten ab. Dadurch lassen sich beispielsweise soziale Netzwerke sehr gut darstellen, in denen die Personen einzelne Knoten sind und die Beziehung untereinander als Kante dargestellt werden.
Wie sind MongoDB Datenbanken aufgebaut?
MongoDB enthält viele sogenannte Sammlungen, die vergleichbar sind mit den Tabellen aus relationalen Datenbanken. In einer Sammlung kann es mehrere sogenannte Dokumente geben, welche wiederum den Datensätzen in einer Tabelle entsprechen um bei dieser Analogie zu bleiben. Das wirklich spannende und neue passiert in den Dokumenten selbst. Deshalb werfen wir darauf einen genaueren Blick.
Die Dokumente enthalten beliebig viele Key-Value Paare, die die eigentlichen Daten speichern. Die Werte können verschiedene Datentypen (String, Integer, Float, etc.) beinhalten und gleichzeitig kann ein Key in zwei verschiedenen Dokumenten zwei unterschiedliche Datentypen haben. Im Datenmodell der relationalen Datenbank wäre dies in zwei Zeilen einer Spalte nicht möglich.
In der aktuellen Implementierung erlaubt MongoDB nur 8MB pro Dokument. Nach Abzug des Speicherplatzes für den Dateioverhead bleibt nicht mehr allzu viel Speicherplatz für den Datensatz übrig. Jedoch nutzt MongoDB ein binäres Datenformat, das auf JSON aufbaut und dadurch deutlich speicherfreundlicher ist als textbasierte Dateiformate. Beim Namen, BSON, orientiert sich dieses Datenformat an seiner Herkunft (“Binary JSON”).
Was ist das MongoDB File Format?
BSON ist das binäre Dateiformat von JSON und optimiert dieses in einigen Punkten. Ursprüngliche Dateiformate, wie CSV, XML oder auch JSON, sind sogenannte textbasierte Formate. Sie speichern die Daten in Klartext ab. Dies macht sie für uns Menschen gut und einfach verständlich, benötigt aber vergleichsweise viel Speicherplatz. Als in den letzten Jahren Big Data Projekte immer mehr in den Vordergrund gerückt sind, wurden die binären Datenformate immer interessanter. Diese speichern Teile oder sogar alle Daten in binärer Schreibweise, sodass sie für uns Menschen erstmal nicht mehr lesbar sind. Dadurch nimmt das Öffnen und Speichern solcher Dateien etwas mehr Zeit in Anspruch, da die Informationen erst verarbeitet werden müssen, dafür ist aber der Speicherplatz geringer und Abfragen sind teilweise performanter.
BSON Dateien speichern die Keys als binäre Werte ab. Die Werte hingegen werden weiterhin als Text geführt, während die Metadaten binär abgespeichert und somit schneller gelesen werden können als Textschlüssel. Hier ein Beispiel von einem einfachen JSON Dictionary und der entsprechenden BSON Datei:
{"hello": "world"} →
\x16\x00\x00\x00 // total document size
\x02 // 0x02 = type String
hello\x00 // field name
\x06\x00\x00\x00world\x00 // field value
\x00 // 0x00 = type EOO ('end of object')Wie wir sehen, ergänzt die BSON Datei einige zusätzliche Metadaten zu dem ursprünglichen Format hinzu, wie beispielsweise den Datentyp. Das mag bei kleinen Dateien deutlich aufwendiger aussehen, bewährt sich jedoch bei sehr großen Dateien durch eine geringere Lesegeschwindigkeit.
Welcher NoSQL Kategorie gehört MongoDB an?
MongoDB zählt zu den sogenannten Document Stores, welche eine Unterart von NoSQL – Datenbanken ist. Sie sind nicht-relational, da die Daten nicht in Zeilen und Spalten sondern in den Dokumenten gespeichert werden. Die Dokumentenspeicher zählen zu der beliebtesten Unterkategorie von NoSQL im Vergleich zu herkömmlichen relationalen Datenbanken. Zu den Vorteilen in der Anwendung zählen unter anderem:
- Einfache Anwendbarkeit für Entwickler auch aufgrund des verständlichen Datenmodells.
- Flexibles Datenschema, welches auch nach dem initialen Erstellen der Datenbank noch einfach geändert werden kann.
- Horizontale Skalierbarkeit der Datenbank bei steigender Datenmenge oder Zugriffe.
Was sind die Vorteile von MongoDB?
Zusätzlich zu den Vorteilen, die Document Stores schon von Haus aus mitbringen, hat MongoDB noch einige positive Eigenschaften, welche die breite Anwendung dieser Datenbank erklären.
- Load Balancing: Diese Datenbanken können über verschiedene Virtual Machines verteilt werden und bleiben somit auch bei einer großen Anzahl gleichzeitiger Abfragen oder bei großen Datenmengen noch relativ performant. Relationale Datenbanken hingegen können aufgrund ihrer grundlegenden Eigenschaften (ACID) nicht auf mehrere Rechner aufgeteilt werden. Dadurch muss eine Maschine leistungsfähiger gemacht werden, wenn sie viele Anfragen verarbeiten muss. Dies ist in den meisten Fällen teurer und aufwändiger als die Last über mehrere Rechner zu verteilen.
- Flexible Datenformate: Wie wir bereits beleuchtet haben, können in MongoDB deutlich flexiblere Datenschemata gespeichert werden als in relationalen Datenbanken. Jeder Key kann theoretisch ein eigenes Datenformat haben.
- Unterstützung in vielen Programmiersprachen: MongoDB wurde mittlerweile für viele Programmiersprachen, wie beispielsweise Python, PHP, Ruby, Node.js, C++, Scala, JavaScript und viele mehr, entwickelt und unterstützt. Dadurch kann die Datenbank für verschiedenste Anwendungsprojekte und in deren Programmiersprache einfach eingebunden werden, ohne dass in eine andere Sprache gewechselt werden muss.
Wie speichert MongoDB Daten ab?
MongoDB Datenbanken lassen sich eigentlich für so gut wie alle Anwendungsbereiche nutzen, in denen man Daten in einem JSON Format hinterlegen könnte. Diese kann man dann relativ einfach in das BSON Format “übersetzen” und in einer MongoDB speichern. Der Aufbau der BSON Datei gibt dadurch keinerlei Struktur der Daten vor und es können flexible Schemata abgespeichert werden.
Wenn wir die Analogie zu relationalen Datenbanken ziehen wollen, sind die einzelnen Dokumente die Zeilen in einer relationalen Datenbank, also Datensätze. Die Felder innerhalb der BSON Datei enthalten Daten eines bestimmten Datentypes und somit am besten Vergleich mit den Spalten in einer Tabelle. Abschließend werden Dokumente mit ähnlichem Informationsgehalt und einer vergleichbaren Struktur in sogenannten Collections abgespeichert, die man sich wie Tabellen in relationalen Datenbanken vorstellen kann.
Ein klassisches Beispiel hierfür sind Bewegungsdaten von Usern auf einer Website. Jede User Journey unterscheidet sich von der anderen und bietet somit kein festes Datenschema. Ein User auf einer E-Commerce Seite tätigt beispielsweise eine Bestellung und meldet sich dafür im System an. Der nächste User hingegen informiert sich über die neuesten Jobangebote im Karrierebereich des Unternehmens. In einer JSON Datei lässt sich dies relativ einfach über die Keys abbilden und somit dann auch in einer MongoDB abspeichern. In einer relationalen Datenbank wäre derselbe Use Case nicht so einfach abzubilden.
Weitere denkbare Anwendungsbereiche sind beispielsweise Backend Daten aus App Anwendungen, ein Content Management System für Websites oder sogar das komplette Data Warehouse eines Unternehmens.
Eignet sich MongoDB für Big Data Anwendungen?
Der Begriff Big Data ist heutzutage in aller Munde, wenn versucht wird, das Phänomen zu beschreiben, dass vor allem Unternehmen und öffentliche Organisationen eine immer größer werdende Datenmenge zur Verfügung stehen, welche vor allem traditionelle Datenbanken an Grenzen stoßen lässt.
MongoDB ist durchaus ein mögliches System um Big Data Anwendungen zu realisieren. In diesem Zusammenhang besticht es vor allem durch die bereits genannte horizontale Skalierbarkeit und das flexible Datenschema. Darüber hinaus hat es eine Speicherengine, die sehr effizient mit dem Speicher verfährt und beispielsweise die Dokumente komprimiert.
Der Hauptvorteil besteht jedoch darin, dass MongoDB Dynamic Querying unterstützt. In Kurzform bedeutet dies, dass die Statements der Datenabfrage erst erstellt werden, wenn die Abfrage bereits gestartet wurde. Das bietet den Vorteil, dass flexible Programme geschrieben werden können, die auf die aktuelle Situation reagieren. Stell Dir vor, Du betreibst einen Online-Shop und ein Kunde ist gerade dabei sich anzumelden. Erst wenn der Kunde seine Credentials eingegeben und den Login-Button gedrückt hat, kann das Programm entscheiden in welchem Dokument die Informationen zum Kunden gesucht werden müssen.
Somit eignet sich MongoDB im Bereich von Big Data vor allem dann gut, wenn die Daten zwischen Speicherung und Abfrage noch verändert werden müssen, also beispielsweise aggregiert werden müssen.
Das solltest Du mitnehmen
- MongoDB ist eine Anwendung einer NoSQL Datenbank.
- Es speichert sogenannte Sammlungen ab, die wiederum Dokumente mit den eigentlichen Daten als Key-Value Paar enthalten.
- MongoDB bietet sich vor allem für Anwendungen an, die hoch skalierbar sein, ein flexibles Datenschema haben und große Datenmengen speichern sollen.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema MongoDB
- Die Dokumentation von MongoDB findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.