Der Begriff Big Data ist heutzutage in aller Munde, wenn versucht wird, das Phänomen zu beschreiben, dass vor allem Unternehmen und öffentliche Organisationen eine immer größer werdende Datenmenge zur Verfügung stehen, welche vor allem traditionelle Datenbanken an Grenzen stoßen lässt.
Definition Big Data
Das Gartner IT-Wörterbuch definiert Big Data wie folgt:
“Big Data sind hochvolumige, schnelle und/oder variantenreiche Informationsbestände, die kosteneffiziente, innovative Formen der Informationsverarbeitung erfordern, welche verbesserte Einblicke, Entscheidungsfindung und Prozessautomatisierung ermöglichen. “
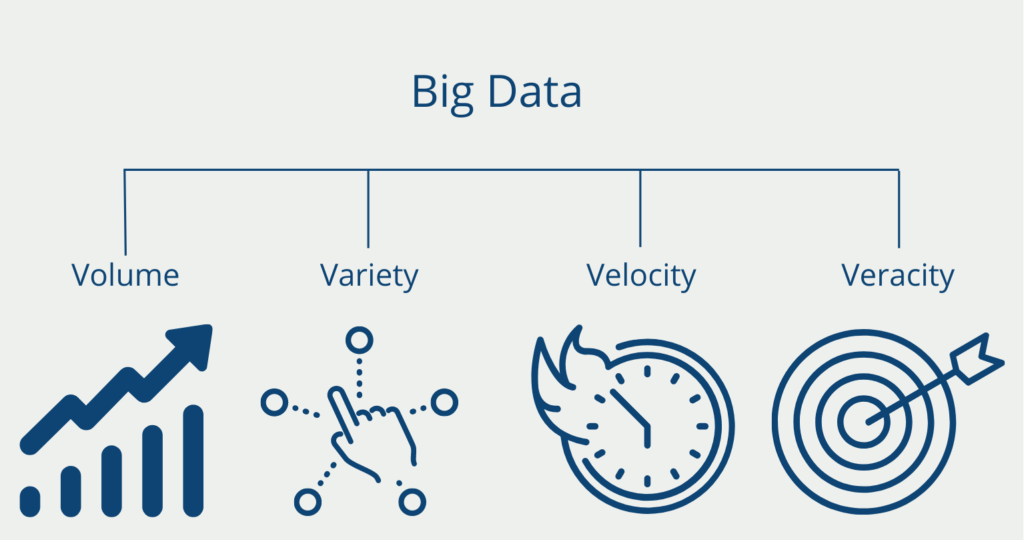
4 V’s der Daten
Obwohl es schwer ist, genau zu erfassen, was ein Big-Data-System “big” macht, werden insgesamt vier Konzepte genutzt, um solche Systeme zu identifizieren. Abgeleitet von deren englischen Bezeichnungen, werden diese auch als die 4 V’s von Big Data bezeichnet:
- Volume: Big Data Anwendungen von Unternehmen, wie Netflix, Amazon oder Facebook, umfassen gewaltige Datenmengen, welche bereits in Größenordnungen von tera- oder sogar zettabytes gemessen werden. Für die Speicherung und Verarbeitung solch großer Datenmengen sind teilweise Tausende von Maschinen notwendig. Zusätzlich kommt hinzu, dass aus Sicherheitsgründen eine Replikation der Daten stattfindet, um bei einem Ausfall darauf zurückgreifen zu können.
- Variety: Die Daten stammen nicht nur aus einer Vielzahl von Datenquellen (bspw. Bilddaten, Audiodaten, etc.), sondern weisen auch unterschiedlichste Datenstrukturen auf. Die Informationen müssen entsprechend in Formate konvertiert werden, sodass sie untereinander nutzbar gemacht werden. Beispielsweise muss sich auf ein einheitliches Schema geeinigt werden für die Angabe von Daten.
- Velocity: Velocity bezieht sich auf die Geschwindigkeit der Datenverarbeitung. Typische Big-Data-Systeme speichern und verwalten große Datenmengen mit immer höheren Geschwindigkeiten. Die Geschwindigkeit, mit der neue Daten erzeugt, verändert und verarbeitet werden, ist eine Herausforderung. Nutzer von sozialen Netzwerken wie Twitter, Facebook oder YouTube produzieren ständig neue Inhalte. Dazu gehören nicht nur Millionen von Tweets, die stündlich gepostet werden, sondern auch Tracking-Informationen, zum Beispiel die Anzahl der Aufrufe oder die GPS-Daten der Nutzer.
- Veracity: Von Menschen produzierte Daten können unzuverlässig sein. Beiträge in sozialen Netzwerken oder Blogs können falsche Informationen, Widersprüche oder schlichtweg Tippfehler enthalten. All dies macht es für Algorithmen schwierig, einen Wert aus den Daten zu extrahieren. Die Herausforderung besteht darin, zu erkennen, welche Daten vertrauenswürdig sind und welche nicht. Algorithmen werden verwendet, um die Datenqualität zu messen und Datenbereinigungsschritte durchzuführen.
Je nach Literatur wird Big Data unter anderem mit nur drei Vs definiert, nämlich Volume, Velocity und Variety. In anderen Definitionen werden sogar noch mehr Vs genannt. Ein Beispiel ist “Value”, was bedeutet, dass Big Data dazu dienen soll, sinnvolle Werte aus Daten zu extrahieren, z.B. durch die Anwendung von Algorithmen für maschinelles Lernen.
Welche Anwendungen verwenden Big Data?
In vielen Branchen und Anwendungsfällen ist die Nutzung von Big Data bereits Alltag. Folgende Beispiel beruhen beispielsweise auf der Auswertung von großen Datenmengen:
- Weiterentwicklung von Produkten: In vielen Branchen können im großen Stile Kundenbewertungen und Vorlieben von Kunden in neue Produkte mit einfließen. Über Bewertungen aus Onlineshops, das Verhalten auf der Website oder Beiträge auf Social Media kann man herausfinden, welche Eigenschaften des Produktes noch verbessert werden sollen.
- Personalisierung von Marketingstrategien: Die große Datenmenge, die für einen einzelnen Kunden vorliegen, werden vor allem im E-Commerce dazu genutzt, um das Marketing noch gezielter zu gestalten und dadurch den Kunden zum Kauf zu bewegen. Die immer weitere Verbreitung von spezifischen Kundenkarten auch im Offline-Handel bestätigen diesen Trend. Dadurch lassen sich Einkäufe gezielt einer Person zuordnen und auswerten. Die Vergünstigungen, die der Kunde im Gegenzug erhält, sind in den meisten Fällen jedoch deutlich geringer als der Profit den das Unternehmen aus den Daten schlagen kann.
- Predictive Maintenance: In vielen Produktionsprozessen sind Teile verbaut, die mit der Zeit verschleißen. Wenn ein starker Verschleiß zu spät erkannt wird, kann es zu sehr teuren Folgeschäden kommen, die sich auch einfach vermeiden lassen. Dazu werden viele Sensoren genutzt, die Verschleißerscheinungen messen sollen und bereits frühzeitig warnen, wenn sich ein Teil dem Ende des Lebenszyklus nähert.
Woher stammen die Daten?
In traditionellen Informationssystemen (wie sie z.B. in Banken oder Versicherungen verwendet werden) wurden die Daten hauptsächlich von den Mitarbeitern des Unternehmens gesammelt. In Big-Data-Anwendungen haben die Daten ihren Ursprung in vielseitigeren Quellen. In der heutigen Zeit fallen in nahezu allen industriellen Branchen und Unternehmensgrößen eine Vielzahl an Daten an. Neben digital agierenden Firmen sammelt auch das produzierende Gewerbe Informationen aus verschiedensten Quellen:
- “Klassische” Daten: Dies sind Daten, die Unternehmen sowieso per Gesetz erheben müssen oder sie aus einem allgemeinen Interesse schon seit längerer Zeit erheben. Dazu zählen beispielsweise alle Informationen zu einem Auftrag, die beispielsweise auf einer Rechnung gefunden werden (Auftragsnummer, Umsatz, Kunde, gekaufte Produkte, etc.).
- Multimedia Quellen: Videos, Musik, Sprachaufnahmen und Multimedia-Dokumente wie Präsentationsfolien sind noch schwieriger zu analysieren als Textbeiträge. Die korrekte Vorverarbeitung dieser Eingabeformate ist einer der wichtigsten Schritte, die für die Speicherung solcher Daten erforderlich sind. Einfache Algorithmen zur Bildvorverarbeitung können verwendet werden, um die Größe oder die Hauptfarbe eines Bildes zu extrahieren. Komplexere Algorithmen, die Techniken des Machine Learnings verwenden, können erkennen, was auf einem Bild zu sehen ist oder wer die Personen auf einem Bild sind.
- Sensordaten und andere Daten zur Überwachung: Server, Smartphones und viele andere Geräte produzieren sogenannte Log-Einträge, die bei der Nutzung entstehen. Ein Webserver protokolliert jede einzelne Anfrage einer Webseite. Ein solcher Logeintrag enthält eine Menge Informationen über den Surfenden: seine IP-Adresse, Land, Stadt, Browser, Betriebssystem, Bildschirmauflösung und vieles mehr. So lässt sich das Klickverhalten analysieren, die Verweildauer auf bestimmten Webseiten und ob ein Besucher ein wiederkehrender oder ein neuer Besucher ist. In Smartphones gibt es Sensoren, um Daten wie die GPS-Position oder den Batteriestatus zu erfassen. Ein Näherungssensor und das Gyroskop können in Kombination verwendet werden, um zu erkennen, ob sich das Telefon in einer Tasche befindet, ob der Benutzer es in der Hand hält oder ob es auf einem Schreibtisch liegt.
Welche Vorteile bringt die Nutzung von Big Data?
Es lässt sich nur schwer definieren, ab wann ein Unternehmen wirklich Big Data nutzt und wann es nur eine Datenauswertung betreibt. Deshalb können die konkreten Vorteile auch von Unternehmen zu Unternehmen variieren. Im Allgemeinen ist Big Data Software auf die Verarbeitung von großen Datenmengen spezialisiert und ermöglicht dadurch schnellere und effizientere Datenabfragen als herkömmliche relationale Datenbanken.
Gleichzeitig wird durch Big Data auch ermöglicht, dass unstrukturierte Daten, wie Bilder oder Videos, verarbeitet werden können. Das war in bisherigen Datenbanksystemen nicht oder nur sehr schwierig möglich.

Auf Unternehmensebene lassen sich durch Big Data große Wettbewerbsvorteile erzielen, indem beispielsweise die Kundenbedürfnisse besser untersucht werden können. Die große Datenmenge können zusätzliche Informationen über das Kaufverhalten und die Präferenzen des Kunden gewonnen werden.
Ein weiterer von vielen Vorteilen von Big Data ist die damit einhergehende Erleichterung des Entscheidungsprozesses. Durch die gezielte Auswertung von Datenmengen ergeben sich konkrete Verbesserungspotenziale oder aber eine anstehende Entscheidung kann datengetrieben belegt oder widerlegt werden. Dadurch können auch strategische Entscheidungen sehr rational begründet werden.
Welche Risiken entstehen durch Big Data?
Die neuen technischen Möglichkeiten, die durch Big Data geschaffen werden, stellen zwar einen echten Fortschritt dar, sind aber auch mit ernsthaften Bedrohungen verbunden. Um sie zu beherrschen, müssen wir wissen, welche potenziellen Bedrohungen von Big Data ausgehen.
Sicherheitsprobleme
Bei der technischen Verarbeitung von solch großen Datenmengen, kann die Einhaltung der Datensicherheit schnell in den Hintergrund treten. Je mehr Daten ein Unternehmen speichert, desto größer ist der Aufwand, diese ausreichend zu schützen, da sie damit auch ein größeres Ziel für Angriffe darstellen. Die deshalb zu treffenden Vorsichtsmaßnahmen verursachen immense Kosten, die aber für das Unternehmen selbst erst einmal keine zusätzlichen Einnahmen bedeuten.
Vor dem Zeitalter von Big Data war nur der Staat in der Lage und berechtigt, umfangreiche Informationen über eine einzelne Person zu speichern. Die Steuerbehörden, das Einwohnermeldeamt, die Führerscheinstelle usw. sammelten viele persönliche Informationen, die ausschließlich der Regierung zur Verfügung standen und durch Datenschutzgesetze geschützt waren. Andererseits sind heute viele größere Unternehmen in der Lage, diese persönlichen Informationen zu sammeln und verfügen möglicherweise sogar über mehr persönliche Daten als die Regierung.
Moralische Bedenken
In der Versicherungsbranche ist es bereits gängige Praxis, dass sich Daten über das Verhalten des Versicherungsnehmers auf den Beitrag auswirken. Verursacht man einen Autounfall, ist es sehr wahrscheinlich, dass sich die Versicherungsprämie erhöht. Fährt man hingegen mehrere Jahre lang unfallfrei, kann dies zu einer Senkung der Prämie führen.
Mit Big Data und der Menge an Daten, die über eine einzelne Person verfügbar sind, ist es nicht ausgeschlossen, dass immer mehr Informationen in solche Berechnungen einfließen und so die Prämie personalisiert wird. Zugegeben, dieser Ansatz der Versicherungsunternehmen ist verständlich. Es ist aber nur ein schmaler Grat, dass solche Maßnahmen auch diskriminierend wirken. Was halten wir zum Beispiel davon, wenn eine Person eine höhere Versicherungsprämie zahlen muss, nur weil Personen aus ihrer Familie oder ihrem unmittelbaren Umfeld statistisch gesehen mehr Unfälle verursachen?
Wie kannst Du unsere Website nutzen, um in Big Data einzusteigen?
Falls Du in diesem Beitrag zum ersten Mal von Big Data erfahren hast oder Dir das Thema noch fremd ist, findest Du auf unserer Seite viele Beiträge, die Dir den Einstieg erleichtern sollen. Dazu findest Du hier eine Auflistung von Themen und Beiträgen, die den Start vereinfachen:
- Herkunft von großen Datenmengen: Einführung in das Webscraping mit Python
- Herkömmlicher Umgang mit Daten: Datenbank, SQL, Data Warehouse, Datentypen, ACID-Eigenschaften
- Neue, skalierbare Datenbankansätze für Big Data: NoSQL, MongoDB, Redis, Data Lake
- Dateiformate zur Übertragung von Daten: XML, JSON, Application Programming Interface
- Big Data Software: Apache MapReduce, Hadoop, HDFS, Kubernetes, Docker
Nach diesen grundlegenden Beiträgen im Bereich Big Data, solltest Du bereits einen Überblick darüber bekommen haben, welche Themen sich rund um den Begriff Big Data sammeln und kannst entscheiden in welchen Aspekt Du tiefer eintauchen willst.
Das solltest Du mitnehmen
- Big Data bezeichnet hochvolumige, schnelle und/oder variantenreiche Informationsbestände. Um diese zu verarbeiten benötigen wir neue Formen der Informationsverarbeitung.
- Big Data lässt sich durch die sogenannten 4 V’s charakterisieren: Volume, Variety, Velocity und Veracity.
- Die Daten stammen in vielen Fällen entweder aus klassischen Datenbeständen, Multimediaquellen oder Überwachungsdaten (Sensordaten).

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Big Data
- Eine ausführliche Definition im Gabler Wirtschaftslexikon findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.