Stemming und Lemmatization sind Algorithmen, die in der natürlichen Sprachverarbeitung (NLP) zur Normalisierung von Text und zur Vorbereitung von Wörtern und Dokumenten für die weitere Verarbeitung im maschinellen Lernen verwendet werden. Sie werden beispielsweise von Suchmaschinen oder Chatbots genutzt, um die Bedeutung von Wörtern herauszufinden.
Im NLP möchte man zum Beispiel die Tatsache anerkennen, dass die Wörter “like” und “liked” dasselbe Wort in verschiedenen Zeitformen sind. Das Ziel ist dann, beide Wörter auf einen gemeinsamen Wortstamm zu reduzieren, was entweder durch Stemmer oder Lemmatisierung geschieht. Auf diese Weise werden beide Wörter ähnlich behandelt, sonst wären “like” und “liked” für das Modell genauso unterschiedlich wie “like” und “car”.
Was ist NLP?
Natural Language Processing ist ein Teilbereich von Computer Science, der sich damit beschäftigt natürliche Sprache, also beispielsweise Texte oder Sprachaufnahmen, verstehen und verarbeiten zu können. Das Ziel ist es, dass eine Maschine in der gleichen Weise mit Menschen kommunizieren kann, wie es Menschen untereinander bereits seit Jahrhunderten tun.
Eine neue Sprache zu erlernen ist auch für uns Menschen nicht einfach und erfordert viel Zeit und Durchhaltevermögen. Wenn eine Maschine natürliche Sprache erlernen will, ist es nicht anders. Deshalb haben sich einige Teilbereiche innerhalb des Natural Language Processings herausgebildet, die notwendig sind, damit Sprache komplett verstanden werden kann.
Diese Unterteilungen können auch unabhängig voneinander genutzt werden, um einzelne Aufgaben zu lösen:
- Speech Recognition versucht aufgezeichnete Sprache zu verstehen und in textuelle Informationen umzuwandeln. Das macht es für nachgeschaltete Algorithmen einfacher die Sprache zu verarbeiten. Speech Recognition kann jedoch auch alleinstehend genutzt werden, beispielsweise um Diktate oder Vorlesungen in Text zu verwandeln.
- Part of Speech Tagging wird genutzt um die grammatikalische Zusammensetzung eines Satzes zu erkennen und die einzelnen Satzbestandteile zu markieren.
- Named Entity Recognition versucht innerhalb eines Textes Wörter und Satzbausteine zu finden, die einer vordefinierten Klasse zugeordnet werden können. So können dann zum Beispiel alle Phrasen in einem Textabschnitt markiert werden, die einen Personennamen enthalten oder eine Zeit ausdrücken.
- Sentiment Analysis klassifiziert das Sentiment, also die Gefühlslage, eines Textes in verschiedene Stufen. Dadurch kann beispielsweise automatisiert erkannt werden, ob eine Produktbewertung eher positiv oder eher negativ ist.
- Natural Language Generation ist eine allgemeine Gruppe von Anwendungen mithilfe derer automatisiert neue Texte generiert werden sollen, die möglichst natürlich klingen. Zum Beispiel können mithilfe von kurzen Produkttexten ganze Marketingbeschreibungen dieses Produkts erstellt werden.
Das Stemming und Lemmatization hilft dabei in vielen dieser Bereichen, indem es die Grundlage dafür bildet, dass die Wörter und deren Bedeutung richtig verstanden wird.
Was ist Stemming?
Beim Stemming werden Suffixe von Wörtern entfernt, so dass ein sogenannter Wortstamm entsteht. Die Wörter “likes”, “likely” und “liked” zum Beispiel ergeben alle den gemeinsamen Wortstamm “like”, der als Synonym für alle drei Wörter verwendet werden kann. Auf diese Weise kann ein NLP-Modell lernen, dass alle drei Wörter irgendwie ähnlich sind und in einem ähnlichen Kontext verwendet werden.
Durch die Stemmer-Methode können wir Wörter unabhängig von ihren Beugungen auf ihren Basisstamm standardisieren, was bei vielen Anwendungen wie dem Clustering oder der Klassifizierung von Text hilfreich ist. Suchmaschinen nutzen diese Techniken ausgiebig, um unabhängig von der Wortform bessere Ergebnisse zu erzielen. Vor der Einführung von Wortstämmen bei Google im Jahr 2003 wurden bei einer Suche nach “Fisch” keine Websites über Fische oder Fischen angezeigt.
Der Porter’s Stemmer Algorithmus ist eine der beliebtesten Stemmer-Methoden und wurde 1980 vorgeschlagen. Er basiert auf der Idee, dass die Suffixe in der englischen Sprache aus einer Kombination kleinerer und einfacherer Suffixe bestehen. Er ist für seine effizienten und einfachen Verfahren bekannt, bringt aber auch einige Nachteile mit sich.
Da er auf vielen, fest kodierten Regeln basiert, die sich aus der englischen Sprache ergeben, kann er nur für englische Wörter verwendet werden. Außerdem kann es Fälle geben, in denen die Ausgabe von Porter’s Stemmer kein englisches Wort ist, sondern nur ein künstlicher Wortstamm.
from nltk.stem.porter import *
porter_stemmer = PorterStemmer()
print(porter_stemmer.stem('alumnus'))
Out:
'alumnu'Die größten Probleme sind jedoch falsch gebildete Wortstämme, die bei den meisten dieser Algorithmen zu den üblichen Mängeln gehören.
Was ist Over- und Understemming?
Wenn unser Algorithmus mehrere Wörter auf denselben Wortstamm zurückführt, obwohl sie nicht miteinander verwandt sind, nennen wir das “Overstemming”. Auch wenn die Wörter “universal”, “university” und “universe” miteinander verwandt sind und vom selben Wortstamm abstammen, sind ihre Bedeutungen weit voneinander entfernt. Wenn wir diese Wörter in eine gute Suchmaschine eingeben, sollten die Suchergebnisse sehr unterschiedlich sein und nicht als Synonyme behandelt werden. Wir bezeichnen einen solchen Fehler als False Positive.

Understemming ist das genaue Gegenteil dieses Verhaltens und umfasst Fälle, in denen mehrere Wörter nicht auf einen gemeinsamen Wortstamm zurückgeführt werden, obwohl sie dies sollten. Das Wort “Alumnus” im Englischen bezeichnet einen ehemaligen Studenten einer Universität und wird meist für männliche Personen verwendet. “Alumnae” ist die weibliche Version davon und “Alumni” sind mehrere ehemalige Studenten einer Universität.

Diese Wörter sollten in einer einfachen Suchmaschine oder anderen NLP-Anwendungen definitiv als Synonyme behandelt werden. Die meisten Stemmer-Algorithmen schneiden sie jedoch nicht auf ihre gemeinsame Wurzel zurück, was zu einem False Negative Fehler führt.
Wie wird Stemming im Bereich der Search Engine Optimization genutzt?
In der Suchmaschinenoptimierung (SEO) bezieht sich Stemming auf eine Technik, die von Suchmaschinen verwendet wird, um Variationen einer Suchanfrage oder eines Schlüsselworts zu identifizieren, indem der gemeinsame Wortstamm verwandter Wörter erkannt und abgeglichen wird.
Wenn ein Nutzer beispielsweise nach “Laufschuhen” sucht, kann eine Suchmaschine, die Stemming verwendet, auch Ergebnisse für verwandte Schlüsselwörter wie “Laufschuhe” oder “Läuferschuhe” liefern, da sie denselben Wortstamm (“laufen”) haben. Auf diese Weise kann sichergestellt werden, dass relevante Ergebnisse angezeigt werden, auch wenn die Suchanfrage des Nutzers nicht exakt mit dem Inhalt einer Webseite übereinstimmt.
Stemming wird von Suchmaschinen verwendet, um die Relevanz und Genauigkeit von Suchergebnissen zu verbessern, da es ihnen ermöglicht, Variationen eines Schlüsselworts oder einer Suchanfrage zu finden, ohne sich ausschließlich auf exakte Übereinstimmungen zu verlassen. Dies kann das Nutzererlebnis verbessern und die Wahrscheinlichkeit erhöhen, dass ein Nutzer die gesuchten Informationen findet.
Im Hinblick auf die Suchmaschinenoptimierung kann die Verwendung von Variationen eines Schlüsselworts im Inhalt auch dazu beitragen, die Sichtbarkeit einer Webseite in den Suchergebnissen zu verbessern. Durch die Aufnahme verwandter Wörter und Ausdrücke, die den gleichen Wortstamm wie das Ziel-Schlüsselwort haben, kann eine Webseite den Suchmaschinen signalisieren, dass sie für ein breiteres Spektrum von Suchanfragen relevant ist, was ihr Ranking und ihre Sichtbarkeit in den Suchergebnissen verbessern kann.
Was ist Lemmatization?
Lemmatisierung ist eine Weiterentwicklung des Stemmings und beschreibt den Prozess der Gruppierung der verschiedenen Formen eines Wortes, damit sie als ein einziges Element analysiert werden können. Die Lemmatisierung ähnelt der Stemmer-Methode, bringt aber den Kontext zu den Wörtern. Sie verbindet also Wörter mit ähnlichen Bedeutungen zu einem Wort. Die Algorithmen verwenden in der Regel auch Positionsargumente als Eingaben, z. B. ob das Wort ein Adjektiv, ein Substantiv oder ein Verb ist.
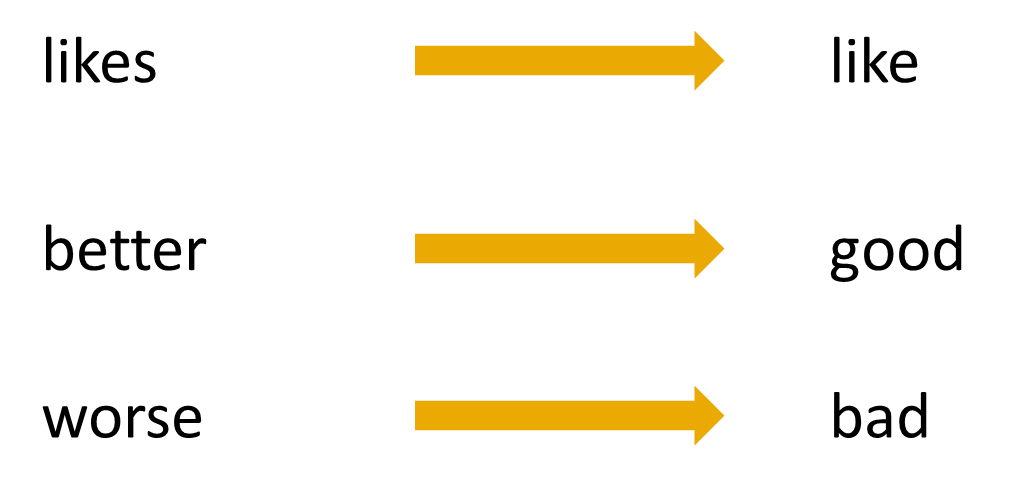
Um die Bedeutung und den Kontext der Wörter zu kennen, werden große Wörterbücher in den einzelnen Sprachen genutzt, um darin die morphologische Bedeutung des Wortes zu finden. Das macht den Algorithmus sehr komplex und zeitaufwendig.
Was ist der Unterschied zwischen Lemmatization und Stemming?
Kurz gesagt ist der Unterschied zwischen diesen Algorithmen, dass lediglich die Lemmatisierung auch die Bedeutung des Wortes mit in die Evaluierung mit aufnimmt. Bei der Stemmer-Methode wird lediglich eine gewisse Anzahl an Buchstaben vom Ende des Wortes abgeschnitten, um einen Wortstamm zu erhalten. Die Bedeutung des Wortes spielt dafür keine Rolle.
Wie im vorherigen Beispiel gesehen, erkennt ein Lemmatization Algorithmus, dass das englische Wort “better” vom Wort “good” abgeleitet ist, da beide eine ähnliche Bedeutung aufweisen. Eine solche Unterscheidung könnte das Stemming hingegen nicht treffen und würde vermutlich “bet” oder “bett” als Wortstamm liefern.
Ist Lemmatisierung besser als Stemming?
Bei der Textvorverarbeitung für NLP benötigen werden sowohl Stemmer-Methoden als auch Lemmatisierung, somit haben beide Algorithmen ihre Daseinsberechtigung. Manchmal findet man sogar Artikel oder Diskussionen, in denen beide Wörter als Synonyme verwendet werden, obwohl sie es nicht sind.
Normalerweise wird die Lemmatisierung dem Stemming vorgezogen, da es sich dabei um eine kontextbezogene Analyse von Wörtern handelt und nicht um die Verwendung einer fest kodierten Regel zum Abschneiden von Suffixen. Diese Kontextualität ist vor allem dann wichtig, wenn Inhalte gezielt verstanden werden müssen, wie dies beispielsweise in einem Chatbot der Fall ist.
Für andere Anwendungen können die Funktionalitäten der Stemmer-Methode auch schon ausreichend sein. Suchmaschinen greifen darauf beispielsweise in großem Stile zurück, um die Suchergebnisse zu verbessern. Indem nicht nur die Suchphrase allein sondern auch die Wortstämme im Index gesucht werden, können verschiedene Wortformen überwunden und die Suche auch stark beschleunigt werden.
In welchen Bereichen werden diese Algorithmen eingesetzt?
Wie bereits erwähnt, sind diese beiden Methoden vor allem im Bereich des Natural Language Processings interessant. Folgende Anwendungen greifen darauf zurück:
- Suchalgorithmen: Die Qualität von Suchergebnissen können deutlich verbessert werden, wenn beispielsweise auf Wortstämme zurückgegriffen wird und dadurch Schreibfehler oder Pluralformen nicht so stark ins Gewicht fallen.
- Wissensgraphen: Beim Aufbau von Wissenstrukturen, wie beispielsweise ein Knowledge Graph, helfen diese Algorithmen bei der Extraktion von Entitäten, wie Personen oder Orten, und deren Verbindung zu anderen Entitäten. Durch diese Knowledge Graphs können auch wiederum Suchalgorithmen verbessert werden.
- Sentimentanalysen: In vielen Anwendungen macht es Sinn, Texte nachdem Sentiment zu klassifizieren, also zum Beispiel positiv oder negativ. Dadurch lassen sich beispielsweise Produktrezensionen sehr schnell einordnen und gezielter bearbeiten. Die Nutzung der vorgestellten Algorithmen kann dem Klassifzierungsmodell helfen, bessere Vorhersagen zu treffen.
Das solltest Du mitnehmen
- Stemming und Lemmatisierung sind Methoden, die uns bei der Textvorverarbeitung für die Verarbeitung natürlicher Sprache helfen.
- Beide helfen dabei, mehrere Wörter auf einen gemeinsamen Wortstamm abzubilden.
- Auf diese Weise werden diese Wörter ähnlich behandelt und das Modell lernt, dass sie in ähnlichen Kontexten verwendet werden können.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Stemming vs. Lemmatization
- Auf dieser Website findest Du ein Online-Tool, mit dem Du verschiedene Stemmer-Algorithmen testen können, indem Du ein Wort direkt online bearbeitest.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.