Stemming and lemmatization are algorithms used in natural language processing (NLP) to normalize text and prepare words and documents for further processing in Machine Learning. They are used, for example, by search engines or chatbots to find out the meaning of words.
In NLP, for example, one wants to recognize the fact that the words “like” and “liked” are the same word in different tenses. The goal is then to reduce both words to a common root, which is done either by stemming or lemmatization. In this way, both words are treated similarly, otherwise “like” and “liked” would be as different for the model as “like” and “car”.
What is NLP?
Natural Language Processing is a branch of Computer Science that deals with the understanding and processing of natural language, e.g. texts or voice recordings. The goal is for a machine to be able to communicate with humans in the same way that humans have been communicating with each other for centuries.
Learning a new language is not easy for us humans either and requires a lot of time and perseverance. When a machine wants to learn a natural language, it is no different. Therefore, some sub-areas have emerged within Natural Language Processing that are necessary for language to be completely understood.
These subdivisions can also be used independently to solve individual tasks:
- Speech Recognition tries to understand recorded speech and convert it into textual information. This makes it easier for downstream algorithms to process it. However, Speech Recognition can also be used on its own, for example, to convert dictations or lectures into text.
- Part of Speech Tagging is used to recognize the grammatical composition of a sentence and to mark the individual sentence components, such as a noun or a verb.
- Named Entity Recognition tries to find words and sentence components within a text that can be assigned to a predefined class. For example, all phrases in a text section that contains a person’s name or express a time can then be marked.
- Sentiment Analysis classifies the sentiment of a text into different levels. This makes it possible, for example, to automatically detect whether a product review is more positive or more negative.
- Natural Language Generation is a general group of applications that are used to automatically generate new texts that sound as natural as possible. For example, short product texts can be used to create entire marketing descriptions of this product.
Stemming and Lemmatization help in many of these areas by providing the foundation for understanding words and their meanings correctly.
What is Stemming?
Stemming is the process of removing suffixes from words to create a so-called root word. For example, the words “likes”, “likely” and “liked” all result in the common root “like”, which can be used as a synonym for all three words. In this way, an NLP model can learn that all three words are somehow similar and are used in a similar context.
Stemming allows us to standardize words to their base stem regardless of their inflections, which is useful in many applications such as clustering or text classification. Search engines use these techniques extensively to produce better results regardless of word form. Before the introduction of the word stems to Google in 2003, a search for “fish” did not bring up websites about fishes.
Porter’s Stemmer Algorithm is one of the most popular Stemming methods and was proposed in 1980. It is based on the idea that the suffixes in the English language are made up of a combination of smaller and simpler suffixes. It is known for its efficient and simple processes, but it also has several disadvantages.
Since it is based on many, hard-coded rules which result from the English language, it can only be used for English words. Also, there may be cases in which the output of Porter’s Stemmer is not an English word but only an artificial word stem.
from nltk.stem.porter import *
porter_stemmer = PorterStemmer()
print(porter_stemmer.stem('alumnus'))
Out:
'alumnu'However, the biggest problems are Over- and Understemming which are common shortcomings of most of these algorithms.
What is Over- and Understemming?
Whenever our algorithm stems multiple words to the same root even though they are not related, we call that Over-Stemming. Even though the words “universal”, “university” and “universe” are related and come from the same root word, their meanings are wide-apart from each other. When we would type these words into a good search engine, the search results should be very different and should not be treated as synonyms. We call such an error a false positive.

Under-Stemming is the exact opposite of that behavior and includes cases in which multiple words are not stemmed to a common root even though they should. The word “alumnus” describes a former student of a university and is mostly used for male persons. “Alumnae” is the female version of it and “alumni” are multiple former students of a university.

These words should definitely be treated as synonyms in a basic search engine or other NLP applications. However, most Stemmer algorithms do not cut it to their common root which is a false negative error.
How is stemming used in Search Engine Optimization?
In search engine optimization (SEO), stemming refers to a technique used by search engines to identify variations of a search query or keyword by recognizing and matching the common root of related words.
For example, if a user searches for “running shoes,” a search engine that uses stemming may also return results for related keywords such as “running shoes” or “runner’s shoes” because they share the same root (“run”). This ensures that relevant results are displayed even if the user’s search query does not exactly match the content of a web page.
Stemming is used by search engines to improve the relevance and accuracy of search results by allowing them to find variations of a keyword or query without relying solely on exact matches. This can improve the user experience and increase the likelihood that a user will find the information they are looking for.
In terms of search engine optimization, using variations of a keyword in content can also help improve a website’s visibility in search results. By including related words and phrases that have the same root as the target keyword, a web page can signal to search engines that it is relevant to a broader range of queries, which can improve its ranking and visibility in search results.
What is Lemmatization?
Lemmatization is a development of Stemmer methods and describes the process of grouping together the different inflected forms of a word so they can be analyzed as a single item. Lemmatizers are similar to Stemmer methods but it brings context to the words. So it links words with similar meanings to one word. Lemmatizer algorithms usually also use positional arguments as inputs, such as whether the word is an adjective, noun, or verb.
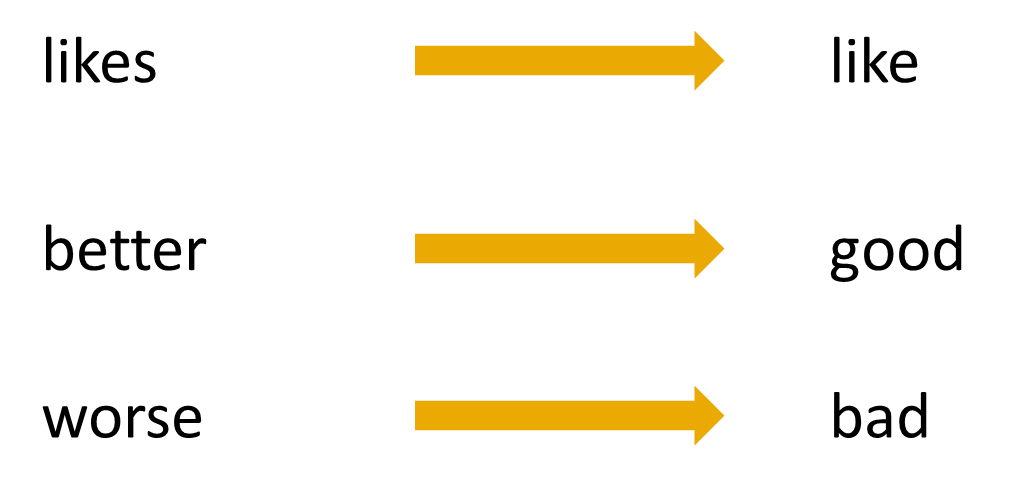
Whenever we do text preprocessing for NLP, we need both Stemming as well as Lemmatization. Sometimes you will even find articles or discussions where both words are used as synonyms even though they aren’t. Usually, Lemmatizers are preferred over Stemmer methods because it is a contextual analysis of words instead of using a hard-coded rule to chop off suffixes. However, if the text documents are very long, then a lemmatizer takes considerably more time which is a severe disadvantage.
What is the difference between Lemmatization and Stemming?
In short, the difference between these algorithms is that only a lemmatizer includes the meaning of the word in the evaluation. In stemming, only a certain number of letters are cut off from the end of the word to obtain a word stem. The meaning of the word does not play a role in it.
As seen in the previous example, a lemmatizer recognizes that the English word “better” is derived from the word “good” because both have similar meanings. Stemming, on the other hand, could not make such a distinction and would probably return “bet” or “bett” as the root word.
Is Lemmatization better than Stemming?
In text preprocessing for NLP, we need both stemming and lemmatizers, so both algorithms have their raison d’être. Sometimes you can even find articles or discussions where both words are used as synonyms, although they are not.
Typically, lemmatizers are preferred to stemmer methods because it is a contextual analysis of words rather than using a hard-coded rule to truncate suffixes. This contextuality is especially important when content needs to be specifically understood, as is the case in a chatbot, for example.
For other applications, Stemming’s functionalities may be sufficient. Search engines, for example, use it on a large scale to improve search results. By searching not only the search phrase alone but also the word stems in the index, different word forms can be overcome and the search can also be greatly accelerated.
In which areas are these Algorithms used?
As mentioned earlier, these two methods are particularly interesting in the area of Natural Language Processing. The following applications make use of them:
- Search algorithms: The quality of search results can be significantly improved if, for example, word stems are used and thus misspellings or plural forms are not as significant.
- Knowledge graphs: When building knowledge structures, such as a Knowledge Graph, these algorithms help extract entities, such as people or places, and connect them to other entities. These knowledge graphs can also, in turn, improve search algorithms.
- Sentiment analysis: In many applications, it makes sense to classify texts according to sentiment, for example, positive or negative. This allows product reviews, for example, to be classified very quickly and processed in a more targeted manner. Using the algorithms presented can help the classification model to make better predictions.
This is what you should take with you
- Stemming and Lemmatization are methods that help us in text preprocessing for Natural Language Processing.
- Both of them help to map multiple words to a common root word.
- That way, these words are treated similarly and the model learns that they can be used in similar contexts.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.

What is the Bivariate Analysis?
Unlock insights with bivariate analysis. Explore types, scatterplots, correlation, and regression. Enhance your data analysis skills.
Other Articles on the Topic of Stemming vs Lemmatization
- On this website, you can an online tool that lets you test different Stemmer algorithms by processing a word directly online.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.