In the rapidly evolving field of artificial intelligence and machine learning, the concept of representation learning has emerged as a fundamental and transformative paradigm. At its essence, representation learning is a sophisticated method that enables machines to autonomously discover and construct meaningful and insightful representations of data.
Unlike traditional machine learning, which often relies on handcrafted features, representation learning allows machines to autonomously uncover relevant features from raw data. By delving into the world of representation learning, we unlock the potential for machines to comprehend, reason, and make decisions akin to human intelligence. This article delves into the depths of representation learning, exploring its principles, methodologies, applications, and the promising future it heralds for AI and machine learning.
What are the fundamental concepts of learning?
Learning, within the context of machine learning and artificial intelligence, encompasses a process through which systems acquire knowledge, patterns, or behaviors based on experiences or data. The fundamental concepts of learning serve as the building blocks for a wide array of machine learning algorithms and models. Here are key concepts that underpin the learning process:
- Data: Data is the foundational element in learning. It comprises information, observations, or experiences that are collected and used to train machine learning models. Diverse and high-quality data is vital for effective learning outcomes.
- Features: Features are specific aspects or properties of the data that are used to represent patterns. These can be extracted or selected to characterize the input data and aid in the learning process.
- Labels: In supervised learning, data often comes with labels or annotations that provide information about the desired output corresponding to each input. These labels guide the model during training.
- Model: The model is a representation of the system that learns from data. It can be a mathematical function or a computational structure that transforms input data into meaningful predictions or decisions.
- Parameters: Parameters are the adjustable elements within the model that are optimized during the learning process. The goal is to find the optimal parameter values that minimize the difference between predicted and actual outcomes.
- Training: Training is the phase where the model learns from the labeled data by adjusting its parameters iteratively. The model refines its understanding of the patterns in the data.
- Loss Function: The loss function measures the disparity between predicted values and true labels. It quantifies the model’s performance and guides the optimization process.
- Optimization: Optimization involves adjusting the model’s parameters to minimize the loss function. Techniques like gradient descent are commonly used for this purpose.
- Generalization: Generalization is the ability of the model to make accurate predictions on unseen or new data. It reflects the model’s capacity to learn patterns that apply beyond the training set.
- Overfitting and Underfitting: Overfitting occurs when a model learns the noise in the training data instead of the actual patterns, leading to poor performance on unseen data. Underfitting, on the other hand, happens when the model is too simplistic to capture the true underlying patterns.
Understanding these fundamental concepts provides a solid foundation for diving deeper into various machine learning algorithms and techniques, ultimately enabling the development of effective and accurate models.
What are the different types of representations?
In the realm of machine learning and artificial intelligence, effective data representation is paramount for the efficiency and success of learning algorithms. Representation learning, a pivotal subfield of machine learning, is centered around the automatic discovery and construction of meaningful data representations. These representations are crucial as they capture essential features, patterns, and relationships inherent in the data. There are several types of data representations that are fundamental to understanding how information is structured and utilized in machine learning.
One of the fundamental types of data representation is the use of raw data, wherein the unprocessed, original data is used as input. While this representation is straightforward, it might not directly capture complex features. On the other hand, handcrafted features involve manual design based on domain expertise and understanding of the data. Experts define specific features to represent relevant aspects, which are then utilized as input for learning algorithms.
Another approach is statistical features, which involve deriving features based on the statistical properties of the data, such as mean, median, variance, or other measures that provide insights into the data’s distribution and characteristics. Transformed representations, on the other hand, involve applying mathematical transformations to the raw data, like Fourier transforms or wavelet transforms, to convert the data into a different, often more informative, domain.
Sparse representations are designed to emphasize specific components of the data, reducing others to zero. These are especially useful for high-dimensional data with many irrelevant features. Distributed representations, often known as embeddings, use vectors or multi-dimensional arrays to represent data elements. Each element in the vector space encodes specific aspects of the data, and these representations are often learned from the data.
In contrast, hierarchical representations organize data features in a hierarchical structure, capturing relationships at various levels of abstraction, aiding in the understanding of complex patterns and concepts. Graphical representations model data as graphs, with nodes representing entities and edges denoting relationships between them. These are particularly useful for representing relational data.
Autoencoders learn a compressed representation of data by training a model to generate output as close as possible to the input. The hidden layers in the autoencoder learn meaningful features. Recurrent Neural Network (RNN) representations process sequential data by considering previous inputs, making them suitable for time series or language-related tasks, with their hidden states acting as representations capturing sequential patterns.
Each type of representation has its strengths and weaknesses, influencing how a model learns and extracts patterns from the data. Representation learning aims to discover the most effective representations automatically, reducing the need for manual feature engineering and enhancing the learning process as a whole.
Traditional Methods vs. Representation Learning
In the domain of machine learning, the choice of how data is represented is a critical factor that significantly impacts the success of learning algorithms. Traditional methods and representation learning represent two distinct approaches in dealing with data representation, each with its own set of advantages and limitations.
Traditional methods for data representation often rely on manual feature engineering. Domain experts design specific features based on their knowledge and understanding of the data. These features are crafted to capture relevant information and patterns that are deemed important for the learning task. However, this process is time-consuming, requires expertise, and might not be exhaustive, potentially missing out on complex, non-intuitive patterns in the data.
On the other hand, representation learning, an approach gaining immense popularity, allows the model to automatically learn meaningful features from the raw data. Instead of handcrafting features, the model extracts and constructs representations through various algorithms and architectures. This eliminates the need for extensive manual feature engineering and can potentially reveal intricate, high-level features that may have been overlooked by human-designed features.
Representation learning algorithms, such as neural networks and deep learning models, can capture complex hierarchical representations of data. They can learn multiple levels of abstraction, where lower layers learn elementary features like edges or textures, and higher layers build upon these to represent more sophisticated concepts. This ability to automatically generate feature representations often leads to better performance and generalization, particularly in tasks where the underlying structure of the data is complex or not well understood.
However, it’s important to note that representation learning, especially with deep neural networks, demands substantial amounts of data and computational resources. Training these models can be computationally intensive and time-consuming. Moreover, understanding the representations learned by complex models can be challenging, making it somewhat of a ‘black box’ in terms of interpretability.
In summary, traditional methods offer transparency and interpretability through handcrafted features but might fall short in capturing complex, nuanced patterns. Representation learning, on the other hand, excels at capturing intricate patterns automatically from raw data, though it can be computationally demanding and less interpretable. The choice between these approaches depends on the specific requirements of the problem at hand, considering factors like data availability, interpretability, and the desired level of automation in feature extraction.
Which models and algorithms are used in Representation Learning?
Representation learning leverages various models and algorithms to automatically discover meaningful patterns and features from raw data. These techniques are fundamental in tasks like computer vision, natural language processing, and more, where the quality of representations directly impacts the performance of downstream tasks.
- Autoencoders: Autoencoders are neural network architectures designed to learn efficient codings or representations of input data. They consist of an encoder that maps the input to a latent space and a decoder that reconstructs the original input from this space. Through the training process, the model aims to minimize the reconstruction error, encouraging the network to learn a compact and informative representation.
- Convolutional Neural Networks (CNNs): CNNs are primarily used in image and video processing. They consist of multiple layers of learnable filters that scan the input, enabling the model to automatically and adaptively learn spatial hierarchies of features from the data. The lower layers usually learn simple features like edges and textures, while higher layers learn more complex and abstract features.
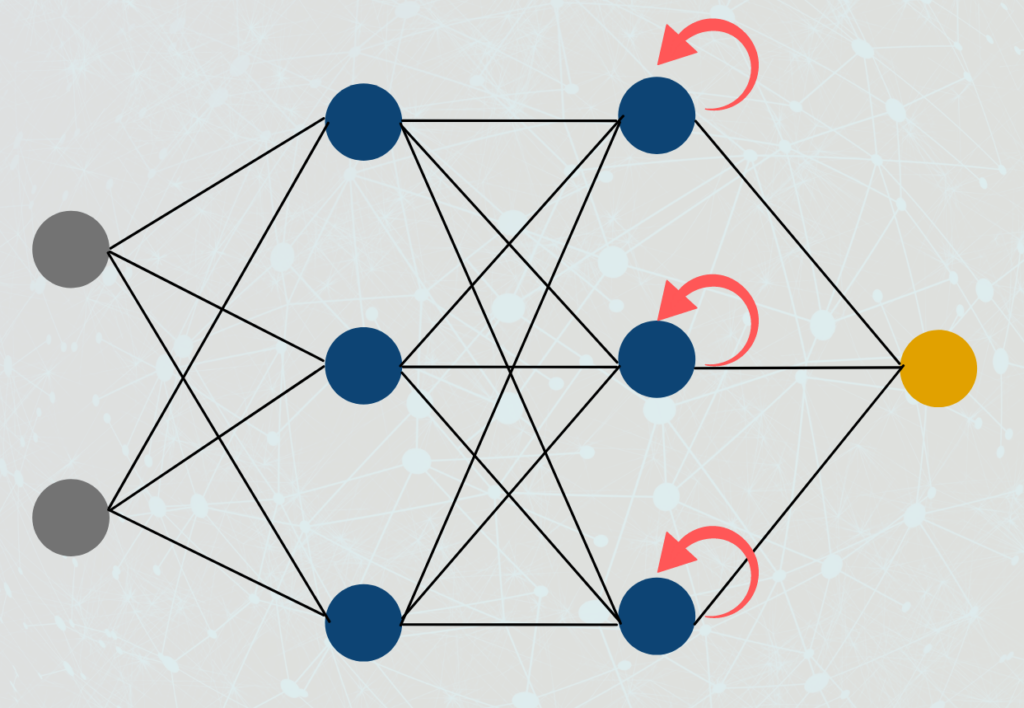
- Recurrent Neural Networks (RNNs): RNNs are crucial for sequential data processing, such as time series and natural language data. They have loops within their architecture, allowing information to be passed from one step of the network to the next. RNNs can capture dependencies and patterns in sequential data, making them effective for representation learning in tasks like sentiment analysis, language modeling, and more.
- Generative Adversarial Networks (GANs): GANs consist of two neural networks, a generator and a discriminator, trained simultaneously through adversarial training. The generator creates data samples to mimic the real data distribution, while the discriminator tries to distinguish between real and generated data. This competition results in the generator producing increasingly realistic data samples, enabling GANs to learn rich data representations.
- Word Embeddings: In natural language processing, word embeddings like Word2Vec, GloVe, and FastText are popular representation learning techniques. These methods map words from a vocabulary to high-dimensional vectors, preserving semantic relationships between words. Word embeddings capture the meaning of words and their contexts, facilitating better understanding and manipulation of textual data.

- Transformers: Transformers have revolutionized natural language processing tasks. They rely on a mechanism called attention to capture dependencies between words in a sentence. Attention allows each word to focus on different parts of the input sequence, enabling the model to learn rich and contextualized representations. Pre-trained transformer models like BERT, GPT, and T5 have achieved state-of-the-art performance across various NLP tasks.
- Variational Autoencoders (VAEs): VAEs are probabilistic autoencoders that learn a probabilistic mapping between the input data and a latent space. They generate new data points by sampling from the learned probability distributions. VAEs are valuable in generating new data and interpolation in the latent space, making them useful in representation learning.
These models and algorithms represent a diverse toolkit for representation learning across different data domains. Researchers and practitioners choose the appropriate technique based on the specific task, data type, and desired quality of representations for achieving optimal performance in subsequent machine learning tasks.
Unsupervised vs. Supervised Learning of Representations
In the realm of representation learning, two main paradigms guide the acquisition of representations: supervised learning and unsupervised learning. Each approach has distinct characteristics and serves different purposes in deriving meaningful features from data.
Supervised Learning Representations:
Supervised learning is a common approach in representation learning where the model learns to map input data to predefined labels or target values. During training, the model is provided with labeled examples, and it adjusts its parameters to minimize the difference between predicted outputs and true labels. In this scenario, the learned representations are guided by the task’s objectives and are tailored to facilitate accurate predictions.
For instance, in a supervised image classification task, a deep neural network learns hierarchical features from raw pixel data to predict the correct classes. The representations at different layers progressively capture more complex and task-relevant features, optimizing the model’s ability to classify images accurately.
Unsupervised Learning Representations:
Unsupervised learning, on the other hand, operates without explicit labels or target values. The model is presented with raw, unlabeled data and tasked with discovering inherent patterns, structures, or relationships within the data. Unsupervised learning aims to derive representations that best capture the underlying data distribution or help uncover meaningful features without external guidance.
Common unsupervised learning techniques for representation learning include autoencoders, clustering algorithms, and dimensionality reduction methods like Principal Component Analysis (PCA) or t-SNE. Autoencoders, for instance, learn to represent data by trying to reconstruct the original input from a compressed, lower-dimensional latent space, effectively learning compact and informative features.
Comparison:
- Supervised learning representations are directly tied to the task at hand, optimizing for predictive accuracy by learning features specific to the task’s labels or outcomes.
- Unsupervised learning representations, being task-agnostic, aim to capture the intrinsic structure of the data itself, often revealing high-level features that might be useful across a range of tasks.
- Supervised learning may suffer from overfitting to the labeled data, resulting in representations biased towards the training set’s characteristics.
- Unsupervised learning often provides more generalizable representations as it learns patterns inherent to the data, potentially leading to better transferability to various tasks.
- Combining both paradigms in semi-supervised learning strikes a balance, utilizing the advantages of both labeled and unlabeled data to create robust representations.
In practice, a blend of supervised and unsupervised learning approaches is often leveraged to develop rich and versatile representations, especially in scenarios where labeled data is limited or expensive to obtain. Balancing between the task-driven guidance of supervised learning and the intrinsic structure discovery of unsupervised learning can yield powerful and adaptive representations.
What are the applications of Representation Learning?
Representation learning is a transformative approach with the ability to automatically discern meaningful patterns and features from raw data. Its applications span across diverse domains, leveraging the learned representations to bolster performance, efficiency, and comprehension in a wide array of tasks.
In the realm of Computer Vision, representation learning holds a pivotal role. It enables the accurate identification of objects, scenes, and patterns within images, enhancing image recognition. Furthermore, it aids in crucial tasks like object detection, segmentation, and image generation, applicable in areas such as autonomous vehicles, robotics, and medical imaging.
Natural Language Processing (NLP) extensively utilizes representation learning. It underpins fundamental language understanding tasks such as machine translation, sentiment analysis, named entity recognition, and part-of-speech tagging. Representations are vital for effective text classification, which finds applications in sentiment analysis, spam detection, and topic modeling. Additionally, they contribute to summarization, paraphrasing, and response generation, enhancing chatbots and automated content creation.
In the domain of Speech and Audio Processing, representation learning is fundamental. It is integral to accurate speech recognition systems, converting audio inputs into textual representations. Moreover, learned representations play a significant role in speaker identification and verification, crucial in security and voice-controlled applications.
Representation learning finds impactful applications in the Healthcare sector. In medical imaging, it improves image analysis, aiding diagnoses through features extraction and pathology detection in various medical scans. In the field of drug discovery, representations play a key role in predicting molecular properties and understanding chemical interactions.
The realm of Recommendation Systems heavily relies on representation learning. It powers recommendation engines, providing personalized suggestions for products, movies, or content based on individual preferences and behavior.
Time Series Analysis benefits significantly from representation learning. It enhances financial forecasting, allowing for accurate predictions in finance by analyzing stock prices, market trends, and optimizing portfolios. Additionally, it is crucial in climate and weather forecasting, capturing patterns and trends in meteorological data.
In Robotics and Autonomous Systems, representation learning contributes to efficient control and navigation of robots in diverse environments, improving their adaptability and decision-making capabilities.
Anomaly detection, an essential area in various domains, benefits from representation learning. It aids in fraud detection by identifying fraudulent activities, anomalies, or deviations from expected patterns in financial transactions and cybersecurity.
Representation learning is also instrumental in Graph Representation Learning, playing a significant role in social network analysis. It enables the analysis of social networks, identifying communities, influencers, and trends.
Finally, representation learning contributes to advancements in Adversarial Attacks and Defense. Understanding representations is crucial for detecting and defending against adversarial attacks in machine learning models.
As representation learning continues to evolve and improve, its applications are expected to expand further, contributing to a deeper understanding of complex data and fostering innovative solutions across diverse domains.
What are the challenges and limitations of Representation Learning?
In the promising landscape of representation learning, there exist inherent challenges and limitations that researchers and practitioners must navigate. Understanding these constraints is crucial for devising effective strategies and advancements in the field.
- Data Quality and Quantity: Representation learning demands a vast amount of high-quality data for optimal performance. In scenarios where data is scarce, noisy, or imbalanced, achieving meaningful representations becomes challenging.
- Curse of Dimensionality: As the dimensionality of the input space increases, the amount of data needed to cover the space adequately increases exponentially. This becomes a significant challenge when working with high-dimensional data, as it leads to increased computational complexity and a greater need for data.
- Overfitting and Generalization: Overfitting is a persistent challenge in representation learning. Models can sometimes learn representations that are too specific to the training data, failing to generalize well to unseen data. Striking a balance between complexity and generalization is crucial.
- Interpretability: The “black-box” nature of some representation learning models presents an interpretability challenge. Understanding and explaining the learned representations in a human-interpretable manner is vital, especially in fields where interpretability is crucial, such as healthcare and finance.
- Transferability: Ensuring that learned representations are transferable across different tasks and domains is a challenge. Representations that are useful in one context may not generalize well to others. Achieving transferability is an ongoing pursuit within representation learning.
- Algorithmic Complexity: Many advanced representation learning algorithms are computationally intensive, making them impractical for real-time or resource-constrained applications. Striking a balance between performance and computational efficiency remains a challenge.
- Biases in Data: Biases present in the training data can be learned by the model and become embedded in the representations, potentially perpetuating and amplifying existing biases present in the data.
- Domain Shift and Drift: Representations learned on a specific dataset may lose effectiveness or relevance when applied to a different domain. Adapting representations to new domains while retaining their informativeness is an ongoing research challenge.
Overcoming these challenges requires interdisciplinary collaboration, innovative algorithm development, and a thorough understanding of the underlying principles of representation learning. Researchers and practitioners are continuously working to address these limitations, fostering advancements that broaden the applicability and effectiveness of representation learning across various domains and applications.
This is what you should take with you
- Representation learning stands as a transformative approach, revolutionizing how data is represented and utilized in various domains.
- By capturing intricate patterns and features within data, representation learning facilitates more efficient information extraction, critical for decision-making and problem-solving.
- The versatility of representation learning is evident in its successful deployment across diverse fields, including natural language processing, computer vision, recommendation systems, and more.
- With its ability to automatically derive meaningful features, representation learning has significantly contributed to the advancements in artificial intelligence, driving breakthroughs and innovations.
- Representation learning is proving instrumental in addressing real-world challenges, such as disease diagnosis, drug discovery, climate modeling, and fraud detection, showcasing its societal impact.
- The field of representation learning is dynamic, continually evolving through ongoing research and advancements. Researchers are consistently striving to enhance algorithms, overcome limitations, and extend applications.
- As artificial intelligence continues to progress, representation learning is poised to play a central role, ensuring AI systems can effectively learn and understand complex data structures.

What is a Boltzmann Machine?
Unlocking the Power of Boltzmann Machines: From Theory to Applications in Deep Learning. Explore their role in AI.

What is the Gini Impurity?
Explore Gini impurity: A crucial metric shaping decision trees in machine learning.

What is the Hessian Matrix?
Explore the Hessian matrix: its math, applications in optimization & machine learning, and real-world significance.

What is Early Stopping?
Master the art of Early Stopping: Prevent overfitting, save resources, and optimize your machine learning models.

What is RMSprop?
Master RMSprop optimization for neural networks. Explore RMSprop, math, applications, and hyperparameters in deep learning.

What is the Conjugate Gradient?
Explore Conjugate Gradient: Algorithm Description, Variants, Applications and Limitations.
Other Articles on the Topic of Representation Learning
Here you can find a Google class on the topic.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.