Das Kreuzvalidierungsverfahren (engl: Cross Validation) wird genutzt, um trainierte Machine Learning Modelle zu testen und deren Performance unabhängig bewerten zu können. Dazu wird der zugrundliegende Datensatz in Trainingsdaten und Testdaten unterteilt. Die Genauigkeit des Modells wird dann jedoch ausschließlich auf dem Testdatensatz berechnet, um beurteilen zu können, wie gut das Modell auf noch nicht gesehene Daten reagiert.
Warum benötigt man Cross Validation?
Um ein allgemeines Machine Learning Modell zu trainieren, benötigt man Datensätze, damit das Modell lernen kann. Ziel ist es, gewisse Strukturen innerhalb der Daten zu erkennen und zu erlernen. Deshalb ist auch die Größe des Datensatzes nicht zu vernachlässigen, da zu wenige Informationen möglicherweise zu falschen Erkenntnissen führen.
Die trainierten Modelle werden dann für echte Anwendungen eingesetzt. Das heißt sie sollen neue Vorhersagen treffen mit Daten, die die KI vorher noch nicht gesehen hat. Beispielsweise wird ein Random Forest trainiert, um Produktionsteile anhand von Messdaten als beschädigt oder unbeschädigt zu klassifizieren. Trainiert wird die KI mit Informationen über ehemalige Produkte, die auch eindeutig als beschädigt oder unbeschädigt klassifiziert sind. Danach soll das fertig trainierte Modell jedoch für neue, unklassifizierte Teile aus der Produktion entscheiden, ob diese einwandfrei sind.
Um dieses Szenario auch bereits im Training zu simulieren, wird ein Teil des Datensatzes bewusst nicht für das eigentliche Training der KI genutzt, sondern stattdessen zum Testen einbehalten, um bewerten zu können, wie das Modell auf neue Daten reagiert.
Was ist Overfitting?
Das gezielte Zurückhalten von Daten, die nicht fürs Training genutzt werden, hat jedoch auch einen anderen konkreten Grund. Es soll nämlich das sogenannte Overfitting vermieden werden. Das bedeutet, dass sich das Modell zu stark den Trainingsdatensatz angepasst hat und somit für diesen Teil der Daten gute Ergebnisse liefert, aber nicht für neue, möglicherweise leicht andere Daten. Das folgende Bild verdeutlicht das ganz gut:

Hierzu ein ehrlicherweise ausgedachtes Beispiel: Angenommen wir wollen ein Modell trainieren, welches die perfekte Matratzenform als Ergebnis liefern soll. Wenn diese KI zu lange auf dem Trainingsdatensatz trainiert wird, kann es dazu kommen, dass Charakteristiken aus dem Trainingssatz zu stark gewichtet werden. Das passiert, da die Backpropagation immernoch versucht den Fehler der Verlustfunktion zu minimieren.
In dem Beispiel könnte es dazu führen, dass im Trainingssatz vor allem Seitenschläfer vorhanden sind und somit das Modell lernt, dass die Matratzenform für Seitenschläfer optimiert sein sollte. Das kann verhindert werden, indem ein Teil des Datensatzes eben nicht zum tatsächlichen trainieren, also zur Anpassung der Gewichte, genutzt wird, sondern nur dafür da ist, dass nach jedem Trainingsdurchlauf das Modell einmal gegen unabhängige Daten getestet wird.
Was macht die Cross Validation?
Allgemein gesprochen bezeichnet Cross Validation (CV) die Möglichkeit schon im Trainingsprozess die Genauigkeit bzw. die Qualität des Modells bei neuen, ungesehenen Daten abzuschätzen. Das heißt bereits während des Lernens kann abgeschätzt werden, wie sich die KI nachher in der Realität schlägt.
Dabei wird der Datensatz in zwei Teile aufgeteilt, nämlich in Trainingsdaten und Testdaten. Die Trainingsdaten werden während des Modelltrainings dazu genutzt, die Gewichtungen des Modells zu erlernen und anzupassen. Die Testdaten wiederum sind dafür da die Genauigkeit des Modells unabhängig zu bewerten und zu validieren wie gut das Modell bereits ist. Abhängig davon wird ein neuer Trainingsschritt gestartet oder das Training gestoppt.
Die Schritte lassen sich wie folgt zusammenfassen:
- Teile den Trainingsdatensatz in Trainingsdaten und Testdaten auf.
- Trainiere das Modell mit den Trainingsdaten.
- Validiere die Performance der KI mithilfe der Testdaten.
- Wiederhole Schritt 1-3 oder beende das Training.
Zur Aufteilung des Datensatzes in die zwei Gruppen gibt es verschiedene Algorithmen, die abhängig von der Menge der Daten gewählt werden. Die berühmtesten sind die Hold-Out und die k-Fold Cross Validation.
Wie funktioniert die Hold-Out Cross Validation?
Die Hold-Out Methode ist die einfachste Methode, um Trainingsdaten und Testdaten zu erhalten. Vielen ist sie nicht unter diesem Namen geläufig, jedoch werden die meisten sie schonmal genutzt haben. Bei dieser Methode werden einfach 80 % des Datensatzes als Trainings- und 20 % des Datensatzes als Testdaten zurückgehalten. Die Aufteilung kann dabei je nach Datensatz variiert werden.

Obwohl das eine sehr einfache und schnelle Methode ist, die auch häufig verwendet wird, hat sie auch einige Probleme. Zum einen kann es passieren, dass die Verteilung der Elemente im Trainingsdatensatz und Testdatensatz sehr unterschiedlich sind. Es könnte beispielsweise vorkommen, dass in den Trainingsdaten sehr viel häufiger Bote vorkommen als in den Testdaten. Dadurch wäre das trainierte Modell sehr gut darin, ein Bot erkennen zu können, würde aber danach bewertet werden wie gut es Häuser erkennt. Das würde zu sehr schlechten Ergebnissen führen.
In Scikit-Learn gibt es bereits definierte Funktionen mit denen sich die Hold-Out Methode in Python umsetzen lässt (Beispiel von Scikit-Learn).
# Import the Modules
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import svm
# Load the Iris Dataset
X, y = datasets.load_iris(return_X_y=True)
Get the Dataset shape
X.shape, y.shape
Out:
((150, 4), (150,))
# Split into train and test set with split 60 % to 40 %
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.4, random_state=0)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
Out:
((90, 4), (90,))
((60, 4), (60,))Ein weiteres Problem bei der Hold-Out Cross Validation ist, dass sie nur bei großen Datensätzen genutzt werden sollte. Ansonsten kann es passieren, dass nicht mehr genug Trainingsdaten übrig sind, um statistisch relevante Zusammenhänge zu finden.
Wie funktioniert die k-Fold Cross Validation?
Die k-Fold Cross Validation schafft bei diesen beiden Nachteilen Abhilfe, indem Datensätze aus den Trainingsdaten auch in Testdaten vorkommen können und andersrum. Dadurch kann die Methode auch für kleinere Datensätze genutzt werden und sie verhindert außerdem eine ungleiche Verteilung von Eigenschaften zwischen Trainings- und Testdaten.
Der Datensatz wird dabei in k gleichgroße Blöcke unterteilt. Einer der Blocks wird zufällig gewählt und dient als Testdatensatz und die anderen Blöcke wiederum sind die Trainingsdaten. Bis hierhin ist es sehr ähnlich zu der Hold-Out Methode. Im zweiten Trainingsschritt jedoch wird ein anderer Block als Testdaten definiert und der Prozess wiederholt sich.
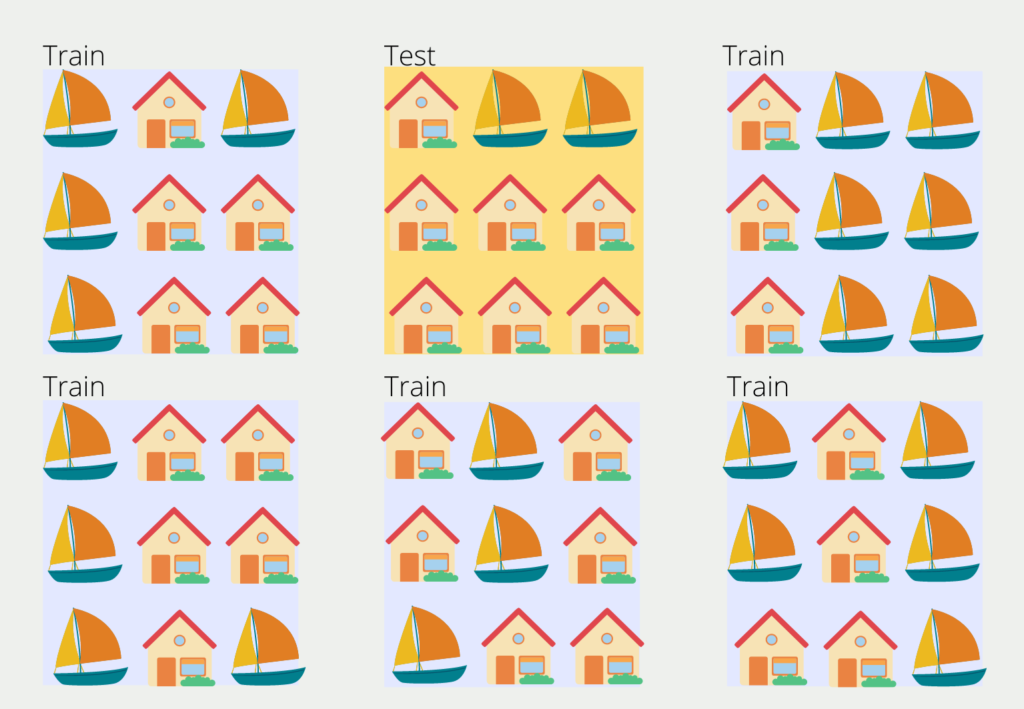
Die Anzahl der Blöcke k lässt sich beliebig wählen und in den meisten Fällen wird ein Wert zwischen 5 und 10 gewählt. Ein zu großer Wert führt zu einem weniger verzerrten Modell, jedoch steigt das Risiko des Overfittings. Ein zu kleiner k Wert führt zu einem stärker verzerrten Modell, da es dann eigentlich der Hold-Out Methode entspricht.
Scikit-Learn bietet auch schon fertige Funktionen, um die k-Fold Cross Validation zu implementieren:
# Import Modules
import numpy as np
from sklearn.model_selection import KFold
# Define the Data
X = ["a", "b", "c", "d"]
Define a KFold with 2 splits
kf = KFold(n_splits=2)
# Print the Folds
for train, test in kf.split(X):
print("%s %s" % (train, test))
Out:
[2 3] [0 1]
[0 1] [2 3]Welche Vor- und Nachteile hat die Cross Validation?
Die Cross Validation ist ein wichtiger Schritt bei der Erstellung eines robusten und aussagekräftigen Modells. Trotzdem sollte sich der Nutzer von der Anwendungen der Vor- und Nachteile dieser Methode bewusst sein, um eine bewusste Entscheidung treffen zu können.
Durch die Cross Validation ist es möglich, robuste Validierungsdaten auch bei kleineren Datensätzen zu erstellen und somit eine belastbare Aussage über die Vorhersagefähigkeit des Modells zu erlangen. Durch die mehrfache Teilung in Trainings- und Testset sind die Ergebnisse deutlich robuster und belastbarer, als wenn nur ein einfacher Split stattgefunden hätte, da das Risiko für Zufallsauswirkungen bei der einfachen Teilung minimiert wird.
Außerdem ermöglicht es das Training mit kleineren Datensätzen, die nicht genug Datenpunkte für einen einfachen Datensplit aufweisen würden. Dadurch kann der gesamte Datensatz für das Training genutzt werden und die Trainingsmenge muss nicht weiter verringert werden.
Ein Hauptnachteil der Kreuzvalidierung ist, dass sie abhängig von der Größe des Datensatzes enorme Rechenleistung in Anspruch nehmen kann und dadurch auch sehr zeitintensiv wird. Je nach genutztem Modell sind dies zwei beschränkende Größen, sodass möglicherweise lieber die Komplexität beim Trainingssplit eingespart wird, um ein komplexeres Modell trainieren zu können.
Neben der Komplexität sollte auch beachtet werden, dass die Cross Validation nicht für alle Datentypen geeignet ist. Zum Beispiel bei der Nutzung von Zeitreihendaten sollte auf die Verwendung verzichtet werden, da die Daten nicht einfach gemischt werden können, ohne dass wichtige Informationen verlieren gehen. Außerdem wird für die Methode vorausgesetzt, dass die Daten aus einer normalverteilten Distribution stammen. Diese Eigenschaft sollte im Detail geprüft werden.
Ein weiterer Nachteil ist die sogenannte Information Leakage, die auftritt, wenn die Daten stark miteinander korreliert sind. Dann kann es passieren, dass Informationen zwischen den Folds vorliegen, die die Modellleistung zu positiv bewerten, obwohl dies in der Realität nicht der Fall ist.
Die Cross Validation bleibt nichtsdestotrotz ein wichtiges Instrument beim Training von Machine Learning Modellen und kommt häufig zum Einsatz. Dabei gewährleistet sie eine robuste Trainingsphase und aussagekräftige Ergebnisse. Es ist trotzdem sinnvoll die Nachteile der Methode zu kennen, um diese bei der Erstellung der Modellarchitektur mit zu berücksichtigen.
Das solltest Du mitnehmen
- Das Kreuzvalidierungsverfahren (engl: Cross Validation) wird genutzt, um trainierte Machine Learning Modelle zu testen und deren Performance unabhängig bewerten zu können.
- Damit kann getestet werden, wie gut die KI auf neue, ungesehene Daten reagiert. Diese Eigenschaft nennt man auch Generalisierung.
- Ohne die Cross Validation kann es zum sogenannten Overfitting kommen, bei dem das Modell zu stark die Trainingsdaten auswendig lernt.
- Die häufigsten genutzten Cross Validation Verfahren sind Hold-Out und k-Folds.

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.

Was ist der Omitted Variable Bias?
Verständnis des Omitted Variable Bias: Ursachen, Konsequenzen und Prävention. Erfahren Sie, wie Sie diese Falle vermeiden.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.

Was ist die Singular Value Decomposition?
Erkenntnisse und Muster freilegen: Lernen Sie die Leistungsfähigkeit der Singular Value Decomposition (SVD) in der Datenanalyse kennen.
Andere Beiträge zum Thema Cross Validation
- Auf der Seite von Scikit-Learn finden sich viele Cross Validation Verfahren und deren Umsetzung in Python.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.