Random Forest ist ein supervised Machine Learning Algorithmus, welcher sich aus einzelnen Decision Trees zusammensetzt. Eine solche Art von Modell wird als Ensemble Modell bezeichnet, da ein “Ensemble” aus unabhängigen Modellen genutzt wird, um ein Ergebnis zu berechnen.
In der Praxis wird dieser Algorithmus für verschiedene Klassifikationsaufgaben oder Regressionsanalysen eingesetzt. Die Vorteile sind die meist kurze Trainingszeit und die Nachvollziehbarkeit des Verfahrens.
Was ist ein Decision Tree?
Die Grundlage für den Random Forest bilden viele einzelne Entscheidungsbäume, sogenannte Decision Trees. Ein Baum besteht aus verschiedenen Entscheidungsebenen und Verzweigungen, die zur Klassifizierung von Daten genutzt werden.
Der Decision Tree Algorithmus versucht die Trainingsdaten in verschiedene Klassen aufzuteilen, sodass die Objekte innerhalb einer Klasse möglichst ähnlich sind und die Objekte verschiedener Klassen möglichst unterschiedlich. Dadurch entstehen mehrere Entscheidungsebenen und Antwortpfade, wie im folgenden Beispiel:
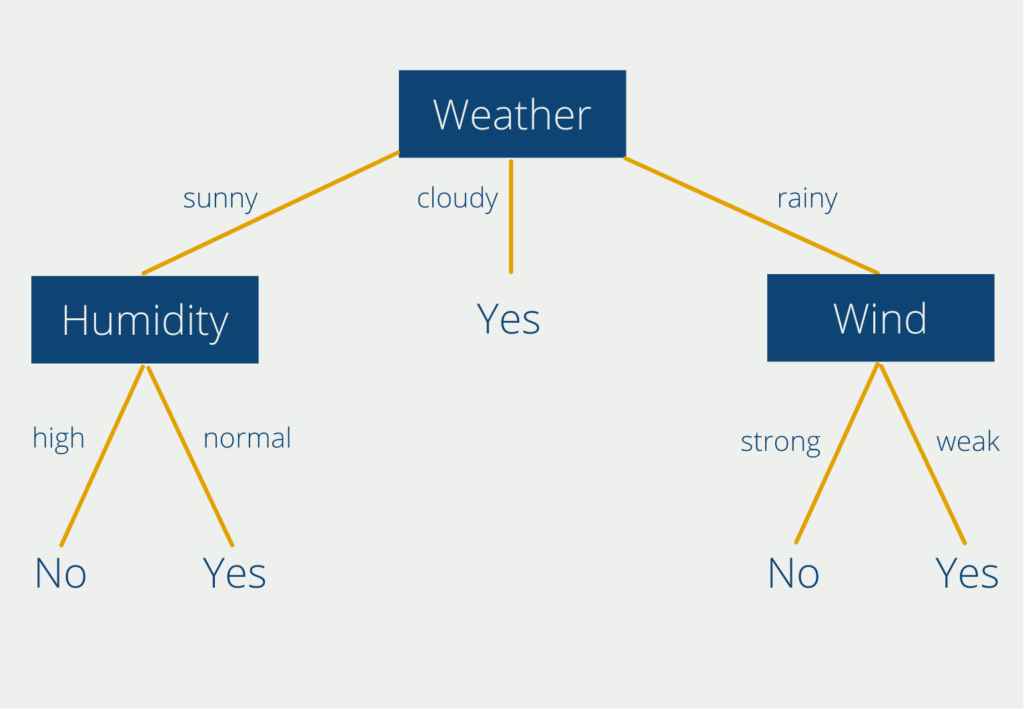
Dieser Baum hilft bei der Entscheidung, ob man draußen Sport machen soll oder nicht, abhängig von den Wettervariablen “Wetter”, “Luftfeuchtigkeit” und “Windstärke”. Der Entscheidungsbaum visualisiert die Klassifizierung der Antworten in “Ja” und “Nein” und verdeutlicht sehr einfach, wann man draußen Sport machen kann und wann nicht. Die ausführliche Erklärung findest Du in unserem eigenen Beitrag zu Decision Trees.
Leider können Decision Trees sehr schnell zum sogenannten Overfitting tendieren. Das heißt, dass sich der Algorithmus zu stark an die Trainingsdaten gewöhnt und sie regelrecht “auswendig” lernt. Dadurch performt er nur sehr schlecht auf neue, ungesehene Daten.
Im Machine Learning ist es eigentlich immer das Ziel, einen Algorithmus zu trainieren, der gewisse Fähigkeiten aus einem Trainingsdatensatz erlernt und diese dann auf neue Daten anwenden kann. Deshalb werden heutzutage nur noch selten Decision Trees genutzt und stattdessen auf die sehr ähnlichen Random Forests zurückgegriffen. Möglich macht das die sogenannte Ensemble Methode.
Wie funktioniert der Random Forest?
Der Random Forest besteht aus einer Vielzahl dieser Decision Trees, welche als ein sogenanntes Ensemble zusammenarbeiten. Jeder einzelne Entscheidungsbaum gibt eine Vorhersage, beispielsweise ein Klassifizierungsergebnis ab, und der Forest nutzt das Ergebnis, das von den meisten Decision Trees unterstützt wird, als Vorhersage des gesamten Ensembles. Warum sind mehrere Entscheidungsbäume so viel besser als ein einzelner?
Das Geheimnis hinter dem Random Forest ist das sogenannte Prinzip der Weisheit von Vielen. Die Grundaussage dahinter ist, dass die Entscheidung von Vielen immer besser ist als die Entscheidung eines einzelnen Individuums oder eben eines einzelnen Decision Trees. Dieses Konzept wurde zum ersten Mal bei der Schätzung einer kontinuierlichen Menge erkannt.
Im Jahr 1906 wurde auf einem Jahrmarkt ein Ochse insgesamt 800 Personen gezeigt. Diese sollten abschätzen, wie schwer dieser Ochse sei, bevor er tatsächlich gewogen wurde. Es stellte sich heraus, dass der Median aus den 800 Schätzungen nur etwa 1 % von dem tatsächlichen Gewicht des Ochsen entfernt war. So nahe war keine einzelne Schätzung dem richtigen Ergebnis gekommen. Die Menschenmenge als Ganzes hatte also besser geschätzt als jede andere, einzelne Person.
Das lässt sich genau so auch auf den Random Forest übertragen. Eine Vielzahl von Entscheidungsbäumen und deren aggregierte Vorhersage wird immer die Leistung eines einzelnen Decision Trees übertreffen.

Das gilt aber nur, wenn die Bäume untereinander nicht korreliert sind und dadurch die Fehler eines einzelnen Baums durch andere Decision Trees ausgeglichen wird. Kommen wir zurück zu unserem Beispiel mit dem Ochsengewicht auf dem Jahrmarkt.
Der Median der Schätzungen aller 800 Personen hat nur dann die Chance besser zu sein als jede einzelne Person, wenn sich die Teilnehmer nicht untereinander absprechen, also unkorreliert sind. Wenn die Teilnehmer jedoch vor der Schätzung zusammen diskutieren und sich dadurch gegenseitig beeinflussen, tritt die Weisheit der Vielen nicht mehr ein.
Was ist Bagging?
Damit der Random Forest gute Ergebnisse liefert, müssen wir also sicherstellen, dass die einzelnen Entscheidungsbäume nicht miteinander korreliert sind. Um das zu gewährleisten nutzen wir das sogenannte Bagging. Es ist eine Methode innerhalb der Ensemble Algorithmen, die gewährleistet, dass verschiedene Modelle auf unterschiedlichen Subsets des Datensatzes trainiert werden.
Decision Trees sind sehr sensitiv gegenüber ihren Trainingsdaten. Eine kleine Änderung in den Trainingsdaten kann bereits zu einer deutlich anderen Baumstruktur führen. Diese Eigenschaft machen wir uns beim Bagging zunutze. Jeder Baum innerhalb des Forests wird deshalb auf einem Sample des Trainingsdatensatzes trainiert, was verhindert, dass die Bäume untereinander korreliert sind.
Jeder Baum wird trotzdem auf einem Trainingsdatensatz mit der Länge des ursprünglichen Datensatzes trainiert, obwohl ein Sample genommen wurde. Dies passiert indem, die fehlenden Werte ersetzt werden. Angenommen unser Ursprungsdatensatz ist die Liste [1,2,3,4,5,6] mit der Länge sechs. Ein mögliches Sample daraus ist [1,2,4,6], welches wir um die 2 und 6 erweitern, sodass wir wieder eine Liste der Länge sechs erhalten: [1,2,2,4,6,6]. Beim Bagging wird also ein Sample des Datensatzes gezogen und mit Elementen aus dem Sample wieder auf die ursprüngliche Größe “ergänzt”.
Wofür können Random Forests verwendet werden?
Random Forest Modelle werden für Klassifikationsaufgaben und Regressionsanalysen genutzt, ähnlich wie Decision Trees auch. Diese finden in vielen Gebieten Anwendung, wie beispielsweise in der Medizin, im E-Commerce oder im Finanzsektor. Konkrete Anwendungen sind beispielsweise:
- Vorhersage von Aktienkursen
- Kreditwürdigkeit eines Bankkunden beurteilen
- Krankheitsdiagnosen aufgrund von Krankenakten
- Konsumentenpräferenzen aufgrund der Kaufhistorie vorhersagen
Was sind die Vorteile von Random Forests?
Es gibt einige gute Gründe, warum man Random Forests bei Klassifizierungsaufgaben einsetzen sollte. Hier sind die häufigsten:
- Bessere Performance: Wie wir zu diesem Zeitpunkt bereits mehrfach erklärt haben, ist die Performance eines Ensemble Algorithmus im Schnitt besser als die eines einzelnen Modells.
- Geringeres Risiko des Overfittings: Entscheidungsbäume tendieren stark dazu, den Trainingsdatensatz auswendig zu lernen, also ins Overfitting zu geraten. Der Median an unkorellierten Decision Trees hingegen ist nicht so anfällig und liefert daher bessere Ergebnisse für neue Daten.
- Nachvollziehbare Entscheidungen: Die Ergebnisfindung in einem Random Forest ist zwar unübersichtlicher als bei einem einzelnen Entscheidungsbaum, jedoch im Kern noch nachvollziehbar. Vergleichbare Algorithmen, wie beispielsweise Neuronale Netzwerke, bieten keine Möglichkeit nachzuvollziehen, wie es zu dem Ergebnis gekommen ist.
- Niedrigere Rechenleistung: Ein Random Forests lässt sich auf heutigen Computern relativ schnell trainieren, da die Anforderungen an die Hardware nicht so hoch sind, wie bei anderen Machine Learning Modellen.
- Niedrige Ansprüche an Datenqualität: In verschiedenen Papern konnte bereits bewiesen werden, dass Random Forests sehr gut mit Ausreißern und ungleich verteilten Daten umgehen können. Somit ist deutlich weniger Aufarbeitung von Datensätzen nötig, als dies bei anderen Algorithmen der Fall ist.
Wann sollte man nicht auf Random Forests zurückgreifen?
Obwohl Random Forests in vielen Anwendungsfällen eine zu berücksichtigende Alternative darstellen, gibt es auch Situationen in denen sie nicht geeignet sind.
Random Forests sollten vor allem für Klassifizierungsaufgaben genutzt werden, bei denen alle Klassen mit ein paar Beispielen im Trainingsdatensatz vorhanden sind. Sie sind jedoch ungeeignet, um neue Klassen oder Werte vorherzusagen, wie wir das beispielsweise von Linearen Regressionen oder Neuronalen Netzen kennen.
Obwohl das Training von Random Forests verhältnismäßig schnell geht, dauert eine einzelne Klassifizierung doch relativ lange. Wenn man also einen Anwendungsfall hat, bei dem Echtzeitvorhersagen getroffen werden sollen, sind möglicherweise andere Algorithmen besser geeignet.
Wenn der Trainingsdatensatz sehr ungleichmäßig besetzt ist, das heißt, dass manche Klassen nur sehr wenige Datensätze haben. Darunter leiden dann die Samples im Bagging Prozess, was wiederum einen negativ Einfluss auf die Modell Performance hat.
Random Forest vs. AdaBoost
Der Random Forest nutzt zwar auch viele Decision Trees, wie AdaBoost, jedoch mit dem Unterschied, dass diese alle dieselben Trainingsdaten bekommen und auch dasselbe Gewicht in der schlussendlichen Vorhersage. Außerdem können die Bäume viele Entscheidungspfade enthalten und sind nicht wie bei AdaBoost lediglich auf eine Stufe limitiert. Zusätzlich wird bei AdaBoost die Gewichtungen einzelner Datenpunkte geändert, wenn diese vom vorherigen Modell nicht richtig klassifiziert wurden. Dadurch werden die einzelnen “Decision Stumps” auf leicht unterschiedlichen Datensätzen trainiert, anders als beim Random Forest.
Diese kleinen Änderungen an der Architektur haben in der Praxis jedoch mitunter große Auswirkungen:
- Trainingsgeschwindigkeit: Dadurch, dass die Decision Trees im Random Forest unabhängig voneinander sind, lässt sich das Training der Bäume parallelisieren und auf verschiedene Server verteilen. Dadurch verringert sich die Trainingszeit. Der AdaBoost Algorithmus hingegen kann aufgrund der sequenziellen Anordnung nicht parallelisiert werden, da der nächste Decision Stump erst trainiert werden kann, wenn der vorherige abgeschlossen wurde.
- Vorhersageschwindigkeit: Wenn es dann jedoch in die tatsächliche Anwendung geht, also wenn die Modelle austrainiert sind und neue Daten klassifizieren sollen, dreht sich das ganze um. Das heißt, für Inference ist AdaBoost schneller als Random Forest, da die Vorhersagen in ausgewachsenen Bäume und das auch noch in der Vielzahl deutlich mehr Zeit in Anspruch nimmt als bei AdaBoost.
- Overfitting: Der Decision Stump im AdaBoost, der wenige Fehler produziert, hat eine hohe Gewichtung für die schlussendliche Vorhersage, während ein anderer Stump, der viele Fehler produziert nur wenig Aussagekraft hat. Beim Random Forest hingegen ist die Aussagekraft aller Bäume identisch, unabhängig davon, wie gut oder schlecht deren Ergebnisse waren. Somit ist die Chance von Overfitting bei Random Forest deutlich geringer als bei einem AdaBoost Modell.
Das solltest Du mitnehmen
- Der Random Forest ist ein supervised Machine Learning Algorithmus, welcher sich aus einzelnen Decision Trees zusammensetzt.
- Er basiert auf dem Prinzip der Weisheit von Vielen, die besagt, dass eine Gemeinschaftsentscheidung von vielen unkorrelierten Komponenten besser ist als die Entscheidung einer einzelnen Komponente.
- Mithilfe des Baggings wird sichergestellt, dass die Entscheidungsbäume nicht zueinander korreliert sind.
- Der Random Forest wird sowohl in der Medizin als auch im Finanz- und Bankensektor eingesetzt.

Was ist die Poisson Regression?
Lernen Sie die Poisson-Regression kennen, ein statistisches Modell für die Analyse von Zähldaten, inkl. einem Beispiel in Python.

Was ist blockchain-based AI?
Entdecken Sie das Potenzial der blockchain-based AI in diesem aufschlussreichen Artikel über Künstliche Intelligenz und Blockchain.

Was ist Boosting im Machine Learning?
Boosting: Eine Ensemble-Technik zur Modellverbesserung. Lernen Sie in unserem Artikel Algorithmen wie AdaBoost, XGBoost, uvm. kennen.

Was ist Feature Engineering?
Meistern Sie die Kunst des Feature Engineering: Steigern Sie die Modellleistung und -genauigkeit mit der Datentransformationen!

Was sind N-grams?
Die Macht des NLP: Erforschen Sie n-Grams in der Textanalyse, Sprachmodellierung und verstehen Sie deren Bedeutung im NLP.

Was ist das No-Free-Lunch Theorem (NFLT)?
Entschlüsselung des No-Free-Lunch-Theorems: Implikationen und Anwendungen in ML und Optimierung.
Andere Beiträge zum Thema Random Forest
- Scikit-Learn bietet eine kurze Erklärung zu Random Forests und eine Beschreibung, wie sie in Python umgesetzt werden können.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.