The cross validation method is used to test trained Machine Learning models and to evaluate their performance independently. For this purpose, the underlying data set is divided into training data and test data. However, the model’s accuracy is then calculated exclusively on the test data set to assess how well the model responds to data that has not yet been seen.
Why do you need Cross Validation?
To train a general machine learning model, one needs data sets so that the model can learn. The goal is to recognize and learn certain structures within the data. Therefore, the size of the dataset should not be neglected, because too little information may lead to wrong insights.
The trained models are then used for real applications. That is, they are supposed to make new predictions with data that the AI has not seen before. For example, a Random Forest is trained to classify production parts as damaged or undamaged based on measurement data. The AI is trained with information about former products that are also uniquely classified as damaged or undamaged. Afterward, however, the fully trained model is to decide for new, unclassified parts from production whether they are flawless.
In order to simulate this scenario already in training, a part of the data set is deliberately not used for the actual training of the AI, but instead retained for testing in order to be able to evaluate how the model reacts to new data.
What is Overfitting?
The targeted withholding of data that is not used for training also has another concrete reason. The aim is to avoid so-called overfitting. This means that the model has adapted too much to the training data set and thus delivers good results for this part of the data, but not for new, possibly slightly different data. The following picture illustrates this quite well:

Here is an honestly made-up example: Let’s assume we want to train a model that is supposed to deliver the perfect mattress shape as a result. If this AI is trained on the training dataset for too long, it may end up overweighting characteristics from the training set. This happens because the backpropagation still tries to minimize the error of the loss function.
In the example, it could lead to the fact that mainly side sleepers are present in the training set and thus the model learns that the mattress shape should be optimized for side sleepers. This can be prevented by not using part of the data set for actual training, i.e. for adjusting the weights, but only for testing the model once against independent data after each training run.
What does Cross Validation do?
Generally speaking, cross validation (CV) refers to the possibility of estimating the accuracy or quality of the model with new, unseen data already during the training process. This means that already during the learning process it is possible to estimate how the AI will perform in reality.
In this process, the data set is divided into two parts, namely training data and test data. The training data is used during model training to learn and adjust the weights of the model. The test data, in turn, is used to independently evaluate the accuracy of the model and validate how good the model already is. Depending on this, a new training step is started or the training is stopped.
The steps can be summarized as follows:
- Split the training data set into training data and test data.
- Train the model using the training data.
- Validate the performance of the AI using the test data.
- Repeat steps 1-3 or stops the training.
To divide the data set into two groups, there are different algorithms that are chosen depending on the amount of data. The most famous ones are the Hold-Out and the k-Fold Cross Validation.
How does Hold-Out Cross Validation work?
The Hold-Out method is the simplest method to obtain training data and test data. Many people are not familiar with it by that name, but most will have used it before. This method simply holds out 80% of the data set as training data and 20% of the data set as test data. The split can be varied depending on the data set.

Although this is a very simple and fast method, which is also frequently used, it also has some problems. For one thing, it can happen that the distribution of elements in the training data set and test data set are very different. For example, it could happen that boats are much more common in the training data than in the test data. As a result, the trained model would be very good at being able to detect a boat but would be evaluated on how well it detects houses. This would lead to very poor results.
In Scikit-Learn there are already defined functions with which the Hold-Out method can be implemented in Python (example of Scikit-Learn).
# Import the Modules
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import svm
# Load the Iris Dataset
X, y = datasets.load_iris(return_X_y=True)
Get the Dataset shape
X.shape, y.shape
Out:
((150, 4), (150,))
# Split into train and test set with split 60 % to 40 %
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.4, random_state=0)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
Out:
((90, 4), (90,))
((60, 4), (60,))Another problem with hold-out cross validation is that it should only be used with large data sets. Otherwise, there may not be enough training data left to find statistically relevant correlations.
How does the k-Fold Cross Validation work?
The k-Fold Cross Validation remedies these two disadvantages by allowing data sets from the training data to also appear in test data and vice versa. This means that the method can also be used for smaller data sets and it also prevents an unequal distribution of properties between training and test data.
The data set is divided into k blocks of equal size. One of the blocks is chosen randomly and serves as the test data set and the other blocks are the training data. Up to this point, it is very similar to the hold-out method. However, in the second training step, another block is defined as the test data, and the process repeats.
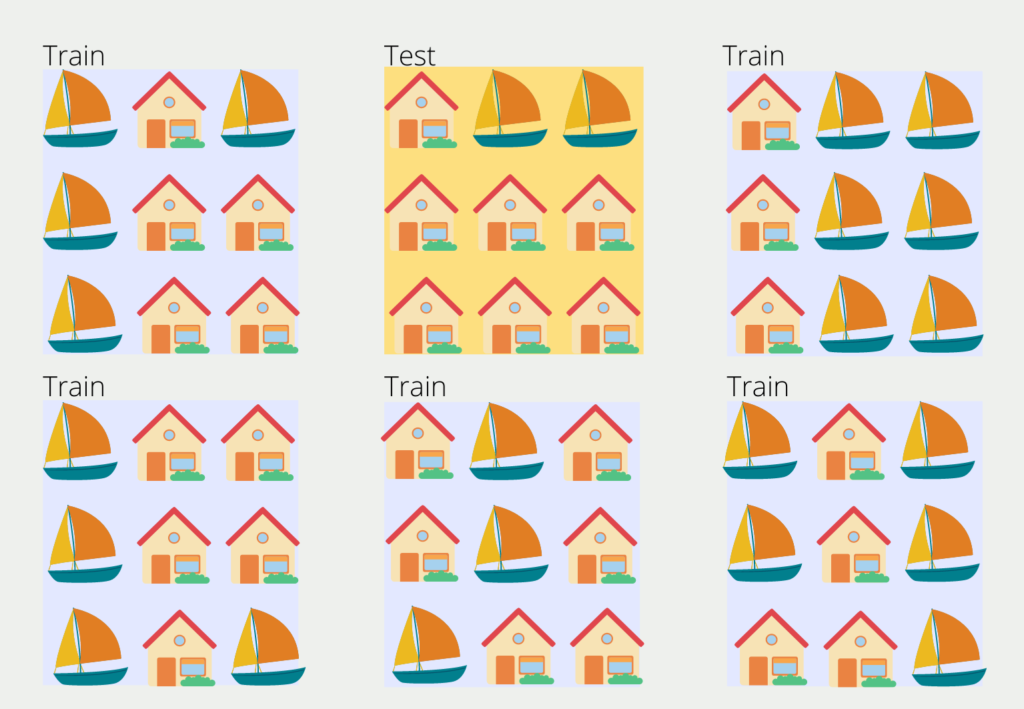
The number of blocks k can be chosen arbitrarily and in most cases, a value between 5 and 10 is chosen. A too large value leads to a less biased model, but the risk of overfitting increases. A too small k value leads to a more biased model, as it then actually corresponds to the hold-out method.
Scikit-Learn also provides ready-made functions to implement k-fold cross validation:
# Import Modules
import numpy as np
from sklearn.model_selection import KFold
# Define the Data
X = ["a", "b", "c", "d"]
Define a KFold with 2 splits
kf = KFold(n_splits=2)
# Print the Folds
for train, test in kf.split(X):
print("%s %s" % (train, test))
Out:
[2 3] [0 1]
[0 1] [2 3]What are the advantages and disadvantages of Cross Validation?
Cross-validation is an important step in the creation of a robust and meaningful model. Nevertheless, the user should be aware of the advantages and disadvantages of this method to be able to make an informed decision.
Cross validation makes it possible to create robust validation data even with smaller data sets and thus obtain a reliable statement about the predictive ability of the model. Due to the multiple split into training and test sets, the results are significantly more robust and reliable than if only a simple split had taken place, as the risk of random effects is minimized with the simple split.
It also enables training with smaller data sets that would not have enough data points for a simple data split. As a result, the entire data set can be used for training and the training set does not need to be further reduced.
One of the main disadvantages of cross-validation is that, depending on the size of the data set, it can require enormous computing power and is therefore very time-consuming. Depending on the model used, these are two limiting variables, so it may be preferable to save on the complexity of the training split to be able to train a more complex model.
In addition to complexity, it should also be noted that cross validation is not suitable for all data types. For example, it should not be used when using time series data, as the data cannot simply be mixed without losing important information. The method also assumes that the data originates from a normally distributed distribution. This property should be checked in detail.
Another disadvantage is information leakage, which occurs when the data is strongly correlated with each other. It can then happen that information is available between the folds that assess the model performance too positively, although this is not the case in reality.
Nevertheless, cross-validation remains an important tool in the training of machine learning models and is frequently used. It ensures a robust training phase and meaningful results. Nevertheless, it is useful to know the disadvantages of the method to take them into account when creating the model architecture.
This is what you should take with you
- Cross validation is used to test trained Machine Learning models and independently evaluate their performance.
- It can be used to test how well the AI reacts to new, unseen data. This feature is also called generalization.
- Without cross validation, so-called overfitting can occur, in which the model over-learns the training data.
- The most commonly used cross validation methods are hold-out and k-folds.

What is the Adam Optimizer?
Unlock the Potential of Adam Optimizer: Get to know the basucs, the algorithm and how to implement it in Python.

What is One-Shot Learning?
Mastering one shot learning: Techniques for rapid knowledge acquisition and adaptation. Boost AI performance with minimal training data.

What is the Bellman Equation?
Mastering the Bellman Equation: Optimal Decision-Making in AI. Learn its applications & limitations. Dive into dynamic programming!

What is the Singular Value Decomposition?
Unlocking insights and patterns: Learn the power of Singular Value Decomposition (SVD) in data analysis. Discover its applications.

What is the Poisson Regression?
Learn about Poisson regression, a statistical model for count data analysis. Implement Poisson regression in Python for accurate predictions.

What is blockchain-based AI?
Discover the potential of Blockchain-Based AI in this insightful article on Artificial Intelligence and Distributed Ledger Technology.
Other Articles on the Topic of Cross-Validation
- On the page of Scikit-Learn you can find many cross validation methods and their implementation in Python.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.