Der Decision Tree ist ein Machine Learning Algorithmus, der seinen Namen von dem baumähnlichen Aufbau hat und dafür genutzt wird mehrere Entscheidungsstufen und die möglichen Antwortpfade darzustellen. Der Entscheidungsbaum liefert gute Ergebnisse für Klassifikationsaufgaben oder Regressionsanalysen.
Wofür nutzen wir Entscheidungsbäume?
Mithilfe der Baumstruktur wird versucht die verschiedenen Entscheidungsebenen nicht nur zu visualisieren, sondern auch in eine gewisse Reihenfolge zu bringen. Für einzelne Datenpunkte lassen sich vorhersagen treffen, beispielsweise eine Klassifizierung, indem die Beobachtungen in den Zweigen entlang zu dem Zielwert gelangt wird.
Die Entscheidungsbäume werden abhängig von der Zielvariablen für Klassifizierungen oder Regressionen genutzt. Wenn der letzte Wert des Baums auf einer kontinuierlichen Skala abbildbar ist, spricht man von einem Regressionsbaum. Wenn die Zielvariable hingegen einer Kategorie angehört, sprechen wir von einem Klassifizierungsbaum.
Durch diese einfache Struktur ist diese Art der Entscheidungsfindung sehr beliebt und wird in verschiedensten Bereichen eingesetzt:
- Betriebswirtschaft: Undurchsichtige Kostenstrukturen können mithilfe einer Baumstruktur veranschaulicht werden und machen deutlich, welche Entscheidungen wie viele Kosten nach sich ziehen.
- Medizin: Für Patienten sind Entscheidungsbäume eine Hilfe, um herauszufinden, ob sie ärztliche Hilfe aufsuchen sollten.
- Machine Learning und Künstliche Intelligenz: In diesem Bereich werden Decision Trees verwendet, um Klassifizierungs- oder Regressionsaufgaben zu erlernen und dann Vorhersagen zu treffen.
Wie ist ein Decision Tree aufgebaut?
Ein Decision Tree besteht im wesentlichen aus drei großen Komponenten: Wurzel, Äste und Knoten. Um diese Bestandteile besser zu verstehen, wollen wir uns einen beispielhaften Decision Tree einmal genauer anschauen, der uns bei der Entscheidung hilft, ob wir heute draußen Sport machen sollen oder nicht.
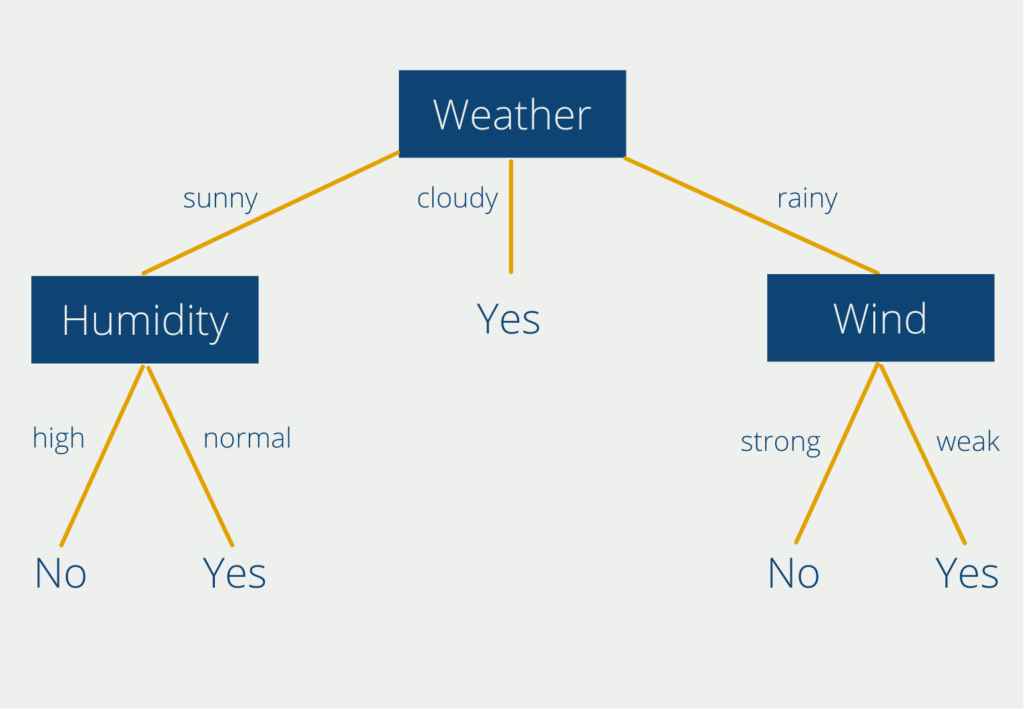
Der oberste Knoten “Weather” ist der sogenannte Wurzelknoten, welcher als Basis für die Entscheidung genutzt wird. Decision Trees haben immer genau einen Wurzelknoten, sodass der Einstieg für alle Entscheidungen dieselbe ist. An diesem Knoten hängen die sogenannten Äste mit den Entscheidungsmöglichkeiten. In unserem Fall kann das Wetter entweder bewölkt, sonnig oder regnerisch sein. An zwei der Äste (“sunny” und “rainy”) hängen sogenannte Knoten. An diesen Stellen muss wieder eine neue Entscheidung getroffen werden. Lediglich der Ast “cloudy” führt direkt zu einem Ergebnis (Blatt). Aus unserem Decision Tree können wir also schon ablesen, dass wir bei wolkigem Wetter immer rausgehen sollten zum Sport machen.
Bei sonnigem oder regnerischem Wetter müssen wir hingegen noch eine zweite Komponente beachten, abhängig von unserem Wetterergebnis. Für den Knoten “Luftfeuchtigkeit” (Englisch: “Humidity”) stehen die Ausprägungen “hoch” und “normal” zur Auswahl. Bei einer hohen Luftfeuchtigkeit enden wir bei dem Blatt “Nein”. Bei sonnigem Wetter gepaart mit einer hohen Luftfeuchtigkeit ist es also nicht ratsam draußen Sport zu machen.
Wenn das Wetter regnerisch ist, befinden wir uns in einem anderen Ast innerhalb unseres Entscheidungsbaums. Dann müssen wir eine Entscheidung am Knoten “Wind” treffen. Die Entscheidungsmöglichkeiten sind hier “stark” oder “schwach”. Auch hier können wir zwei Regeln ablesen: Wenn es regnet, aber der Wind schwach ist, können wir draußen Sport machen. Bei Regen gepaart mit starkem Wind hingegen, sollten wir zu Hause bleiben.
Dieses sehr einfache Beispiel kann natürlich weiter ausgebaut und verfeinert werden. Für die Knoten “Luftfeuchtigkeit” und “Wind” könnte man sich beispielsweise überlegen, ob man die subjektiven Entscheidungsmöglichkeiten durch konkrete Regeln ersetzt (starker Wind = Windgeschwindigkeiten > 10 kmh) oder die Äste noch feiner unterteilt.
Was ist das sogenannte Pruning?
Entscheidungsbäume können in realen Anwendungsfällen sehr schnell komplex und unübersichtlich werden, da in den meisten Szenarien mehr als zwei Entscheidungen benötigt werden, um bei einem Ergebnis zu enden. Um das zu verhindern werden austrainierte Decision Trees oft einem sogenannten Pruning (Deutsch: Kürzung) unterzogen.
Beim Reduced Error Pruning wird ein Bottom-Up Algorithmus verwendet, der an den Blättern startet und sich dann nach und nach zu der Wurzel vorarbeitet. Dabei nimmt man den gesamten Entscheidungsbaum und lässt einen Knoten inklusive der Entscheidungen weg. Dann wird verglichen, ob sich die Genauigkeit der Vorhersage des gekürzten Baums verschlechtert hat. Wenn dies nicht der Fall ist, kürzt man den Entscheidungsbaum, um diesen Knoten und hat dadurch die Komplexität des Decision Trees verringert.
Neben der Möglichkeit den Baum nach dem Training zu kürzen, gibt es auch Methoden, um die Komplexität bereits vor bzw. während dem Training gering zu halten. Ein beliebter Algorithmus hierfür ist die sogenannte Early Stopping Rule. Während des Trainings wird nach jeder erstellten Node entschieden, ob der Baum an dieser Stelle weitergeführt wird, also ein Entscheidungsnode ist, oder ein Ergebnisnode vorliegt. Als Kriterium wird in vielen Fällen die sogenannte Gini Impurity genutzt.
Einfach gesprochen drückt sie die Wahrscheinlichkeit aus, dass an dieser Node ein Label falsch gesetzt wird, wenn man es einfach zufällig, also anhand der Verteilung an dieser Node, zuteilt. Umso kleiner diese Kennzahl, umso höher die Wahrscheinlichkeit, dass wir den Baum an dieser Stelle prunen können, ohne große Einbußen bei der Genauigkeit des Modells befürchten zu müssen.
Was sind die Vor- und Nachteile von Decision Trees?
Der einfache und verständliche Aufbau macht den Entscheidungsbaum zu einer beliebten Wahl in vielen Anwendungsfällen. Jedoch sollten vor der Nutzung dieses Modells die folgenden Vor- und Nachteile abgewägt werden.
| Vorteile | Nachteile |
| Einfach zu verstehen, interpretieren und visualisieren. | Decision Trees können instabil sein und sich mit leichten Änderungen der Trainingsdaten stark ändern. |
| Es können Anwendungen mit kategorischen Werten (sonnig, wolkig, regnerisch) und numerischen Werten (Windgeschwindigkeit = 10 kmh) abgebildet werden. | Bei unausgeglichenen Trainingsdaten (bspw. sehr oft sonniges Wetter) kann dieser sogenannte Bias auch im Baum vorhanden sein. |
| Nicht-lineare Beziehungen zwischen Variablen wirken sich nicht auf die Genauigkeit des Baums aus. | Die Entscheidungsbäume können schnell sehr komplex werden und sich den Trainingsdaten zu stark anpassen. Dadurch generalisieren sie nicht so gut auf vorher ungesehene Daten. |
| Die Anzahl der Entscheidungsebenen ist theoretisch unbegrenzt. | Hohe Trainingszeit |
| Mehrere Entscheidungsbäume lassen sich zu einem sogenannten Random Forest kombinieren. |
Entscheidungsbäume als Bestandteil von Random Forests
Random Forest ist ein supervised Machine Learning Algorithmus, welcher sich aus einzelnen Decision Trees zusammensetzt. Eine solche Art von Modell wird als Ensemble Modell bezeichnet, da ein “Ensemble” aus unabhängigen Modellen genutzt wird, um ein Ergebnis zu berechnen. In der Praxis wird dieser Algorithmus für verschiedene Klassifikationsaufgaben oder Regressionsanalysen eingesetzt. Die Vorteile sind die meist kurze Trainingszeit und die Nachvollziehbarkeit des Verfahrens.
Der Random Forest besteht aus einer Vielzahl dieser Decision Trees, welche als ein sogenanntes Ensemble zusammenarbeiten. Jeder einzelne Entscheidungsbaum gibt eine Vorhersage, beispielsweise ein Klassifizierungsergebnis ab, und der Forest nutzt das Ergebnis, das von den meisten Decision Trees unterstützt wird, als Vorhersage des gesamten Ensembles. Warum sind mehrere Entscheidungsbäume so viel besser als ein einzelner?
Das Geheimnis hinter dem Random Forest ist das sogenannte Prinzip der Weisheit von Vielen. Die Grundaussage dahinter ist, dass die Entscheidung von Vielen immer besser ist als die Entscheidung eines einzelnen Individuums oder eben eines einzelnen Decision Trees. Dieses Konzept wurde zum ersten Mal bei der Schätzung einer kontinuierlichen Menge erkannt.
Im Jahr 1906 wurde auf einem Jahrmarkt ein Ochse insgesamt 800 Personen gezeigt. Diese sollten abschätzen, wie schwer dieser Ochse sei, bevor er tatsächlich gewogen wurde. Es stellte sich heraus, dass der Median aus den 800 Schätzungen nur etwa 1 % von dem tatsächlichen Gewicht des Ochsen entfernt war. So nahe war keine einzelne Schätzung dem richtigen Ergebnis gekommen. Die Menschenmenge als Ganzes hatte also besser geschätzt als jede andere, einzelne Person.
Das lässt sich genau so auch auf den Random Forest übertragen. Eine Vielzahl von Entscheidungsbäumen und deren aggregierte Vorhersage wird immer die Leistung eines einzelnen Decision Trees übertreffen.

Das gilt aber nur, wenn die Bäume untereinander nicht korreliert sind und dadurch die Fehler eines einzelnen Baums durch andere Decision Trees ausgeglichen wird. Kommen wir zurück zu unserem Beispiel mit dem Ochsengewicht auf dem Jahrmarkt.
Der Median der Schätzungen aller 800 Personen hat nur dann die Chance besser zu sein als jede einzelne Person, wenn sich die Teilnehmer nicht untereinander absprechen, also unkorreliert sind. Wenn die Teilnehmer jedoch vor der Schätzung zusammen diskutieren und sich dadurch gegenseitig beeinflussen tritt die Weisheit der Vielen nicht mehr ein.
Wie kann man einen Decision Tree in Python trainieren?
Das Python Modul Skicit-Learn bietet eine Vielzahl von Tools, die für die Datenanalyse benötigt werden, darunter auch der Entscheidungsbaum. Es basiert unter anderem auf den Datenformaten, die aus Numpy bekannt sind. Für die Erstellung eines Decision Trees in Python nutzen wir das Modul und das entsprechende Beispiel aus der Dokumentation.
Das sogenannte Iris Dataset ist ein beliebter Trainingsdatensatz für das Erstellen eines Klassifizierungsalgorithmus. Es ist ein Beispiel aus der Biologie und beschäftigt sich mit der Klassifizierung von sogenannten Iris Pflanzen. Über jede Blume ist die Länge und Breite des Blüttenblattes und des sogenannten Kelchblattes vorhanden. Anhand dieser vier Informationen soll dann erlernt werden, um welchen der drei Iris-Typen es sich bei dieser Blume handelt.
Mithilfe von Skicit-Learn lässt sich in wenigen Zeilen Code bereits ein Decision Tree trainieren:
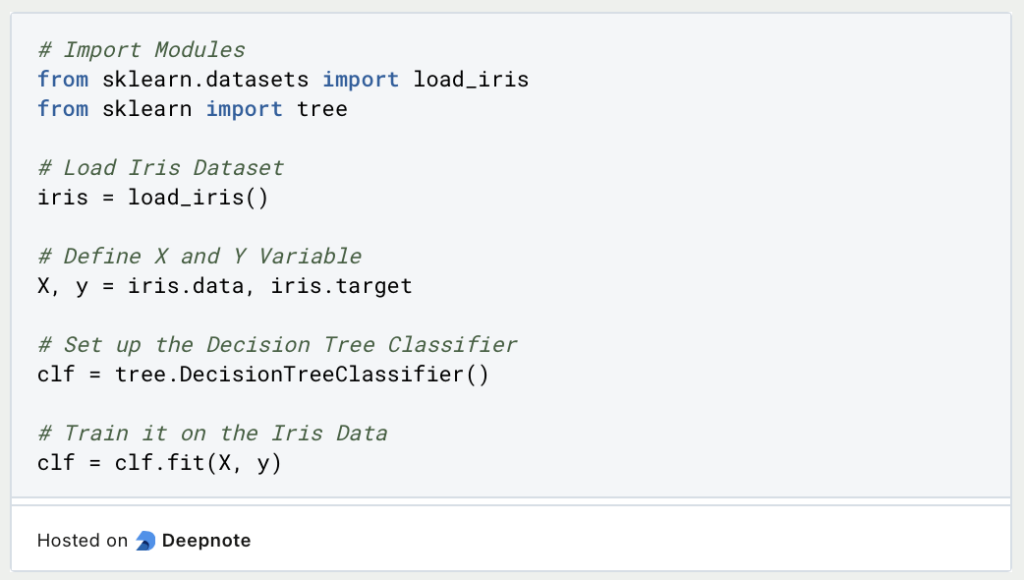
Wir können also einen Entscheidungsbaum relativ einfach dadurch trainieren, dass wir die Inputvariable X und die vorherzusagenden Klassen Y definieren und den Entscheidungsbaum aus Skicit-Learn darauf trainieren. Mit der Funktion “predict_proba” und konkreten Werten, lässt sich dann eine Klassifizierung vornehmen:
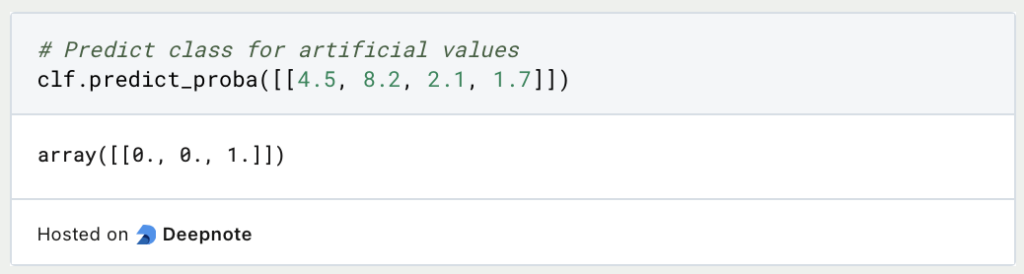
Diese Blume mit den ausgedachten Werten würde also laut unserem Decision Trees der ersten Klasse angehören. Diese Gattung nennt sich “Iris Setosa”.
Wie interpretiert man Decision Trees?
Mithilfe von MatplotLib lässt sich der trainierte Decision Tree zeichnen.
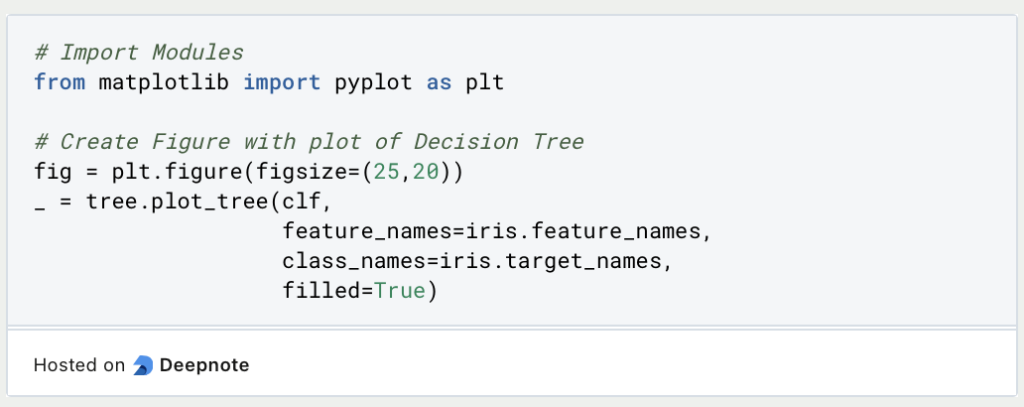
Der optimale Entscheidungsbaum für unsere Daten hat insgesamt fünf Entscheidungsebenen:
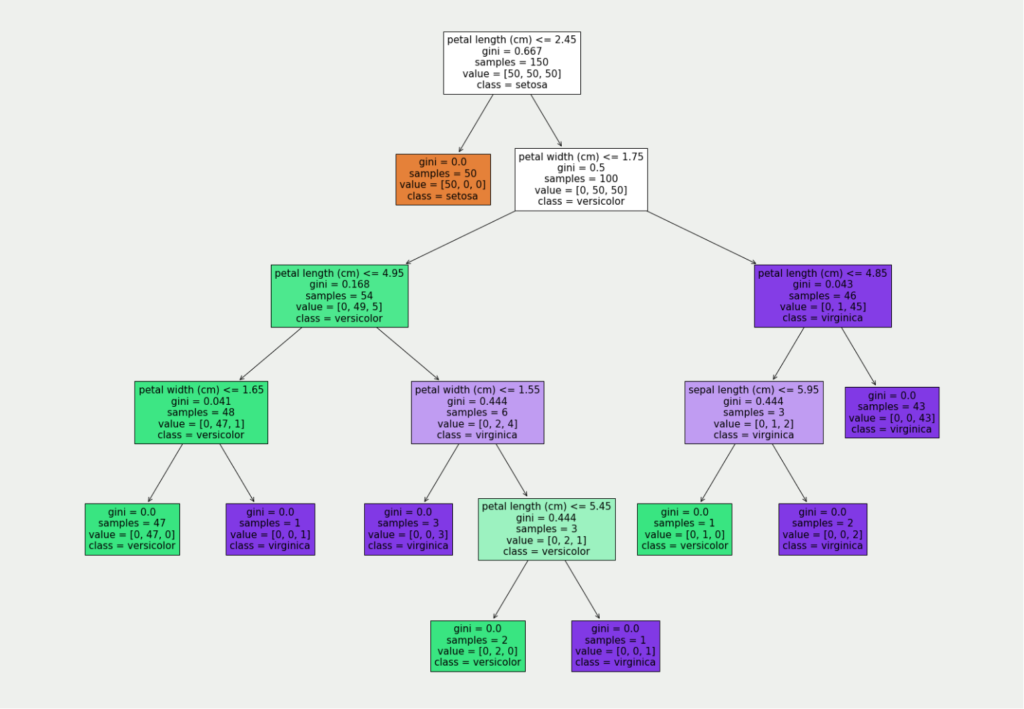
Für die einfache Interpretation dieses Baumes interessieren uns der Wert in der ersten und der letzten Zeile. Der Baum wird von oben nach unten gelesen. Das bedeutet, dass wir in der ersten Entscheidungsebene prüfen, ob die Länge des Blütenblattes (“Petal Length”) kleiner oder gleich 2,45 cm ist. Die Bedingungen sind immer so formuliert, dass es nur “True” im linken Branch und “False” im rechten Branch gibt.
Wenn eine konkrete Blume also ein Blüttenblatt besitzt, das kleiner oder gleich 2,45 cm ist befinden wir uns im linken Branch (in der orangenen Kachel), der gleichzeitig ein Ergebnisblatt ist. Somit wissen wir, dass in diesem Fall die Blume der Klasse “Setosa” angehört.
Wenn das Blütenblatt hingegen länger ist, gehen wir den rechten Branch entlang und stehen vor einer weiteren Entscheidung nämlich, ob das Blütenblatt eine maximale Breite von 1,75 cm besitzt. So arbeitet man sich durch den Baum, bis man an einem Ergebnisblatt angelangt ist, dass dann Auskunft über die Klassifizierung gibt.
Das solltest Du mitnehmen
- Decision Trees sind ein weiterer Machine Learning Algorithmus, der vor allem für Klassifikationen oder Regressionen eingesetzt wird.
- Ein Baum besteht aus dem Startpunkt, der sogenannten Wurzel, den Ästen, die die Entscheidungsmöglichkeiten darstellen und den Knoten mit den Entscheidungsebenen.
- Um die Komplexität und Größe eines Decision Trees zu verringern, wenden wir sogenannte Pruning Methoden an, die die Anzahl der Knoten verringert.
- Decision Trees sind gut geeignet, um Entscheidungsfindungen anschaulich darzustellen und erklärbar zu machen. Beim Training muss man jedoch auf viele Details achten, um ein aussagekräftiges Modell zu erhalten.
Vielen Dank an Deepnote für das Sponsoring dieses Artikels! Deepnote bietet mir die Möglichkeit, Python-Code einfach und schnell auf dieser Website einzubetten und auch die zugehörigen Notebooks in der Cloud zu hosten.

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.

Was ist der Omitted Variable Bias?
Verständnis des Omitted Variable Bias: Ursachen, Konsequenzen und Prävention. Erfahren Sie, wie Sie diese Falle vermeiden.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.

Was ist die Singular Value Decomposition?
Erkenntnisse und Muster freilegen: Lernen Sie die Leistungsfähigkeit der Singular Value Decomposition (SVD) in der Datenanalyse kennen.
Andere Beiträge zum Thema Decision Trees
- Die Dokumentation der Python Library bietet auch ausführliche Erklärungen zu Decision Trees inklusive einiger konkret programmierter Beispiele.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.