Scikit-Learn (kurz auch sklearn) ist eine Python Bibliothek mit der sich Machine Learning Anwendungen einfach umsetzen lassen. Die Bibliothek basiert auf gängigen Datenstrukturen in Python, wie Numpy, und ist somit sehr kompatibel mit anderen Modulen. Der Quellcode dieser Library findet man auf GitHub.
Was ist Scikit-Learn?
Die Software-Bibliothek Scikit-Learn ermöglicht die Nutzung von KI-Modellen in der Programmiersprache und erspart dem Nutzer viel Programmieraufwand, indem gängige Modelle, wie Decision Trees oder K-Mean Clustering, über wenige Zeile Code integriert werden können.
Zu den bekanntesten Voraussetzung für die Verwendung von sklearn zählen Numpy und SciPy, auf denen die Bibliothek in großen Teilen beruht. Darüber hinaus gibt es auch Abhängigkeiten zu joblib und threadpoolctl. Das Projekt entstand im Jahr 2007 und ist seitdem unter der “3-Clause BSD” Lizenz auf GitHub einsehbar.
Welche Anwendungen können mit der Bibliothek umgesetzt werden?
Mit Scikit-Learn können verschiedenste KI-Modelle umgesetzt werden, sowohl aus dem des Supervised wie auch dem Unsupervised Learning. Im Allgemeinen können die Modelle in die folgenden Gruppen untergliedert werden:
- Klassifizierung
- Regressionen
- Dimensionsreduktion
- Datenpreprocessing und -visualisierung
Im Umfeld von Künstlicher Intelligenz hat die Bibliothek nur deshalb ein bisschen an Popularität verloren, da Neuronale Netzwerke immer interessanter wurden. Diese können mithilfe von Scikit-Learn nur sehr rudimentär aufgebaut werden, weshalb viele Nutzer auf Tensorflow umsteigen, bzw. diese Bibliothek auch immer relevanter wird. Zusätzlich haben Neuronale Netze die Performance von gängigen KI-Modellen weit übertroffen, sondern nur selten auf vorherige Modelle zurückgegriffen wird.
Welche Supervised Learning Algorithmen können umgesetzt werden?
Scikit-learn ist eine Python-Bibliothek, die eine breite Palette von überwachten Lernmodellen für maschinelle Lernaufgaben bietet. Einige der unterstützten Modelle sind:
- Lineare Regression: Ein Modell, das eine lineare Gleichung an die Daten anpasst.
- Logistische Regression: Ein Modell, das eine logistische Funktion verwendet, um die Wahrscheinlichkeit eines binären Ergebnisses zu schätzen.
- Entscheidungsbäume: Ein Modell, das die Daten rekursiv in Teilmengen auf der Grundlage der unterscheidungskräftigsten Merkmale unterteilt.
- Random Forest: Ein Ensemble-Modell, das mehrere Entscheidungsbäume kombiniert, um eine Überanpassung zu vermeiden.

- Support Vector Machines (SVM): Ein Modell, das die Hyperebene findet, die die Daten am besten in verschiedene Klassen unterteilt.
- Naive Bayes-Klassifikatoren: Eine Familie probabilistischer Modelle, die das Bayes-Theorem zur Vorhersage von Klassenwahrscheinlichkeiten verwenden.
- k-Nächste Nachbarn (k-NN): Ein Modell, das die Klasse einer Probe auf der Grundlage der Klassen ihrer k nächsten Nachbarn in den Trainingsdaten vorhersagt.
- Neuronale Netze (einschließlich Multi-Layer Perceptron): Eine Familie von Modellen, die von der Struktur und Funktion des menschlichen Gehirns inspiriert sind und komplexe Muster in den Daten lernen können.
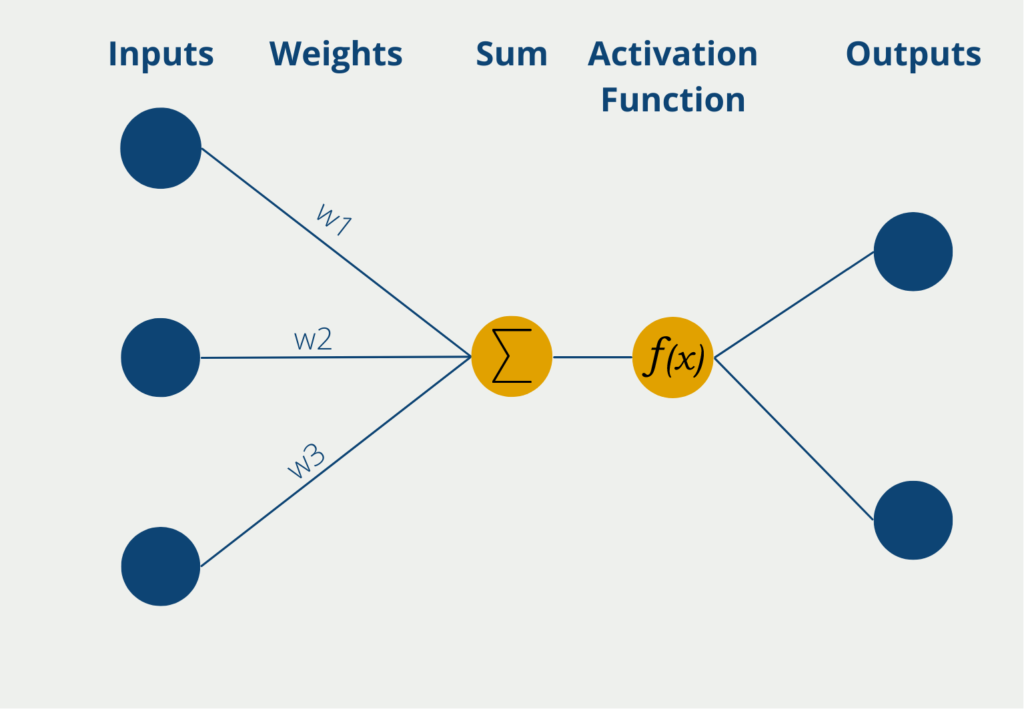
- Gradient Boosting Machines (GBM): Ein Ensemble-Modell, das nacheinander schwache Modelle an die Residuen des vorherigen Modells anpasst, um die Genauigkeit zu verbessern.
- AdaBoost: Ein Ensemble-Modell, das mehrere schwache Modelle kombiniert, um ein starkes Modell zu erstellen.
- Bagging: Ein Ensemble-Modell, das mehrere Modelle auf Bootstrap-Stichproben der Daten anpasst, um die Varianz zu verringern.
- Gradient Descent: Ein Optimierungsalgorithmus, der die Modellparameter iterativ aktualisiert, um eine Verlustfunktion zu minimieren.
- Ridge- und Lasso-Regression: Regularisierte lineare Regressionsmodelle, die der Verlustfunktion einen Strafterm hinzufügen, um eine Überanpassung zu verhindern.
- Elastic Net: Ein Hybridmodell, das die L1- und L2-Strafen der Ridge- und Lasso-Regression kombiniert, um Verzerrungen und Varianz auszugleichen.
Jedes Modell hat seine eigenen Stärken und Schwächen, so dass es wichtig ist, das geeignete Modell für die jeweilige Aufgabe zu wählen. Scikit-learn bietet auch Dienstprogramme für die Vorverarbeitung, Modellauswahl und Bewertung, um den Arbeitsablauf beim maschinellen Lernen zu optimieren.
Welche Unsupervised Learning Algorithmen werden unterstützt?
Scikit-learn unterstützt mehrere unüberwachte Lernmodelle, darunter:
- Clustering: Hierbei werden ähnliche Instanzen auf der Grundlage einer bestimmten Abstandsmetrik gruppiert. Scikit-learn bietet verschiedene Clustering-Algorithmen, darunter KMeans, DBSCAN und hierarchisches Clustering.
- Dimensionalitätsreduktion: Hierbei wird die Anzahl der Merkmale in einem Datensatz reduziert, wobei die wesentlichen Informationen erhalten bleiben. Scikit-learn bietet die Hauptkomponentenanalyse (PCA), t-distributed Stochastic Neighbor Embedding (t-SNE) und Non-negative Matrix Factorization (NMF) zur Dimensionalitätsreduktion.
- Erkennung von Anomalien: Dies beinhaltet die Identifizierung von Instanzen, die signifikant von der Norm in einem Datensatz abweichen. Scikit-learn bietet One-Class SVM und Local Outlier Factor (LOF) für die Anomalieerkennung.
- Dichteschätzung: Dies beinhaltet die Schätzung der Wahrscheinlichkeitsdichtefunktion eines Datensatzes. Scikit-learn bietet Gaussian Mixture Models (GMM) und Kernel Density Estimation (KDE) für die Dichteschätzung.
Jedes dieser unüberwachten Lernmodelle hat seine eigenen Stärken und Schwächen und kann auf verschiedene Arten von Datenanalyseproblemen angewendet werden.
Welche Vorteile bietet Scikit-Learn?
Zu den Vorteilen der Bibliothek zählen unter anderem:
- vereinfachte Anwendung von Machine Learning Tools, Datenanalytik und Datenvisualisierung
- kommerzielle Nutzung ohne Lizenzgebühren
- Hohes Maß an Flexibilität beim Fine-Tuning der Modelle
- basierend auf gängigen und leistungsstarken Datenstrukturen aus Numpy
- Nutzbar in verschiedenen Kontexten
Neben den ganzen Vorteilen sollte jedoch bei solchen Bibliotheken beachtet werden, dass die Nutzung von Machine Learning Modellen ein solides Vorwissen voraussetzen und bei unbedachter Anwendung auch schlichtweg zu falschen Aussagen führen können.
Sklearn macht die Nutzung dieser Modelle besonders einfach und somit für viele Nutzer zugänglich. Jedoch sollte man sich genau im klaren sein, welche Modelle eingesetzt werden können und ob die genutzten Daten belastbar sind.
Wie kann man die Bibliothek in Python nutzen?
Das sogenannte Iris Dataset ist ein beliebter Trainingsdatensatz für das Erstellen eines Klassifizierungsalgorithmus. Es ist ein Beispiel aus der Biologie und beschäftigt sich mit der Klassifizierung von sogenannten Iris Pflanzen. Über jede Blume ist die Länge und Breite des Blüttenblattes und des sogenannten Kelchblattes vorhanden. Anhand dieser vier Informationen soll dann erlernt werden, um welchen der drei Iris-Typen es sich bei dieser Blume handelt.
Mithilfe von Skicit-Learn lässt sich in wenigen Zeilen Code bereits ein Decision Tree trainieren:
# Import Modules
from sklearn.datasets import load_iris
from sklearn import tree
# Load Iris Dataset
iris = load_iris()
# Define X and Y Variable
X, y = iris.data, iris.target
# Set up the Decision Tree Classifier
clf = tree.DecisionTreeClassifier()
# Train it on the Iris Data
clf = clf.fit(X, y)Wir können also einen Entscheidungsbaum relativ einfach dadurch trainieren, dass wir die Inputvariable X und die vorherzusagenden Klassen Y definieren und den Entscheidungsbaum aus Skicit-Learn darauf trainieren. Mit der Funktion “predict_proba” und konkreten Werten, lässt sich dann eine Klassifizierung vornehmen:
# Predict class for artificial values
clf.predict_proba([[4.5, 8.2, 2.1, 1.7]])
Out:
array([[1., 0., 0.]])Diese Blume mit den ausgedachten Werten würde also laut unserem Decision Trees der ersten Klasse angehören. Diese Gattung nennt sich “Iris Setosa”.
Was ist die Zukunft von Scikit-Learn?
Scikit-learn hat sich in der Community für maschinelles Lernen aufgrund seiner benutzerfreundlichen Oberfläche, der großen Auswahl an Algorithmen und der umfassenden Dokumentation durchgesetzt. Das Projekt hat sich im Laufe der Jahre ständig weiterentwickelt, wobei neue Versionen neue Funktionen hinzufügen und die Leistung verbessern.
Da der Bereich des maschinellen Lernens weiter wächst, wird scikit-learn wahrscheinlich eine immer wichtigere Rolle dabei spielen, diese Methoden für Forscher, Entwickler und Unternehmen zugänglicher zu machen. Hier sind einige mögliche Bereiche, in denen scikit-learn in Zukunft weiterentwickelt werden könnte:
- Integration von Deep Learning: Während scikit-learn bereits eine Vielzahl leistungsstarker Algorithmen bietet, sind Deep-Learning-Methoden in den letzten Jahren aufgrund ihrer Fähigkeit, komplexe Daten zu verarbeiten, immer beliebter geworden. Scikit-learn könnte einige dieser Methoden, wie z. B. neuronale Netze und neuronale Faltungsnetze, integrieren, um den Praktikern des maschinellen Lernens ein umfassenderes Instrumentarium zu bieten.
- Interpretierbarkeit: Da Modelle des maschinellen Lernens zunehmend in anspruchsvollen Anwendungen wie dem Gesundheits- und Finanzwesen eingesetzt werden, wird die Fähigkeit, ihre Entscheidungen zu interpretieren und zu verstehen, immer wichtiger. Scikit-learn könnte Methoden enthalten, die erklären, wie ein Modell Entscheidungen trifft, z. B. die Bedeutung von Merkmalen und partielle Abhängigkeitsdiagramme.
- Verteiltes Rechnen: Da die Datensätze immer größer werden, können traditionelle Algorithmen für maschinelles Lernen langsam und speicherintensiv werden. Scikit-learn könnte möglicherweise verteilte Computing-Frameworks wie Apache Spark einbeziehen, um eine schnellere und skalierbarere Verarbeitung zu ermöglichen.
- Automatisiertes maschinelles Lernen: Automatisiertes maschinelles Lernen (AutoML) ist ein schnell wachsender Bereich, der darauf abzielt, viele der beim maschinellen Lernen anfallenden Schritte zu automatisieren, z. B. die Auswahl von Merkmalen und die Abstimmung von Hyperparametern. Scikit-learn könnte einige dieser Methoden integrieren, um maschinelles Lernen auch für Nicht-Experten zugänglich zu machen.
- Maschinelles Lernen unter Wahrung der Privatsphäre: Mit zunehmender Besorgnis über den Datenschutz werden Methoden für die Durchführung von maschinellem Lernen auf sensiblen Daten immer wichtiger, ohne diese preiszugeben. Scikit-learn könnte möglicherweise datenschutzfreundliche Methoden des maschinellen Lernens, wie z.B. föderiertes Lernen, einbinden, um mehr Optionen für die Arbeit mit sensiblen Daten zu bieten.
Insgesamt ist Scikit-Learn gut positioniert, um auch in den kommenden Jahren eine wichtige Rolle im Ökosystem des maschinellen Lernens zu spielen. Da sich das Feld weiter entwickelt, wird scikit-learn wahrscheinlich weiterhin neue Methoden und Techniken anpassen und integrieren, um ein umfassendes Set von Werkzeugen für Machine-Learning-Anwender bereitzustellen.
Das solltest Du mitnehmen
- Scikit-Learn (kurz auch sklearn) ist eine Python Bibliothek mit der sich Machine Learning Anwendungen in wenigen Zeilen Code umsetzen lassen.
- Die Bibliothek ist für verschiedenste Anwendungen aus den Bereichen Klassifizierung, Dimensionsreduktion oder Regression einsetzbar.
- Sklearn erfreut sich großer Beliebtheit, da es unter anderem auf Numpy aufsetzt, einfach nutzbar ist und ein hohes Maß an Flexibiltät bietet.

Was ist Jenkins?
Jenkins beherrschen: Rationalisieren Sie DevOps mit leistungsstarker Automatisierung. Lernen Sie CI/CD-Konzepte und deren Umsetzung.

Python-Tutorial: Bedingte Anweisungen und If/Else Blöcke
Lernen Sie, wie man bedingte Anweisungen in Python verwendet. Verstehen Sie if-else und verschachtelte if- und elif-Anweisungen.

Was ist XOR?
Entdecken Sie XOR: Die Rolle des Exklusiv-Oder-Operators in Logik, Verschlüsselung, Mathematik, KI und Technologie.

Wie kannst Du die Ausnahmebehandlung in Python umsetzen?
Die Kunst der Ausnahmebehandlung in Python: Best Practices, Tipps und die wichtigsten Unterschiede zwischen Python 2 und Python 3.

Was sind Python Module?
Erforschen Sie Python Module: Verstehen Sie ihre Rolle, verbessern Sie die Funktionalität und rationalisieren Sie die Programmierung.

Was sind Python Vergleichsoperatoren?
Beherrschen Sie die Python Vergleichsoperatoren für präzise Logik und Entscheidungsfindung beim Programmieren in Python.
Andere Beiträge zum Thema Scikit-Learn
- In diesem GitHub Repository befindet sich der Source Code von Scikit-Learn.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.